ベイズ最適化のKeras DNNモデルへの適用
ディープラーニングに限らず、機械学習モデルを作るときに大変なのがパラメータの調整です。
機械学習モデルの精度はパラメータに左右されますが、パラメータは数も範囲も広く、最適解を見つけることが難しいのが現状です。
例えば隠れ層3のニューラルネットワークモデルを考えるとき、各層のアウトプットとなるニューロン数やドロップアウト率、バッチサイズやエポック数等々、決めなければならない要素が多く、範囲も広いです。
各パラメータの決め方は色々ありますが、可能な数値の例は大体以下になります。
- ニューロン数:1以上の整数
- ドロップアウト率:0以上1より小さい小数
- バッチサイズ:入力データ以下の整数
- エポック数:1以上の整数
ニューラルネットワークによって適当な数値はあったりしますが、データとニューラルネットワークモデル次第で適不適があるため、正直パラメータ調整は面倒です。
しかもそのパラメータが良いか悪いかは、やってみないとわかりません。
以前、パラメータをGridSearchCVで探索する方法を紹介しました。
http://qiita.com/cvusk/items/285e2b02b0950537b65e
この方法では、自分で設定したパラメータの選択肢の全組み合わせを試すことで、最適なパラメータを見つけるものでした。
この方法の難点は、パラメータ数が増えると試す組み合わせが掛け算で増えることです。
今回はより強力なパラメータ調整方法として、ベイズ最適化を紹介します。
今回やること
ベイズ最適化を使ってKerasで書いたモデルの最適化方法を紹介します。
例として使うモデルはMNISTです。
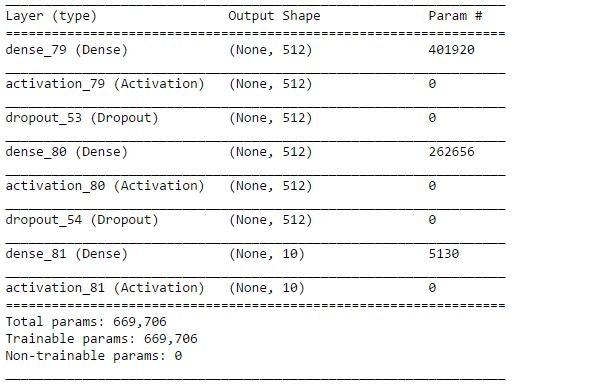
入力層、隠れ層、出力層が各1層の3層モデルで、以下のパラメータを最適化していきたいと思います。
- 入力層のアウトプット数
- 入力層のドロップアウト率
- 隠れ層のアウトプット数
- 隠れ層のドロップアウト率
- バッチサイズ
- エポック数
- 検証データ率
ベイズ最適化について
ベイズ最適化の説明はこのあたりが詳しいです。
- ベイズ最適化入門
- 機械学習のハイパーパラメータ探索 : ベイズ最適化の活用
- 深層学習(Deep Learning)とベイズ的最適化(Bayesian Optimization)による医用画像読影支援の試み
ベイズ最適化ではパラメータを入力とし、モデル検証の精度(損失関数や適合率等々)を出力として、その間の関数(モデル)をブラックボックスとします。
ブラックボックス関数がガウス過程に従うと仮定して、検証を重ねることで事後分布を探索してパラメータの最適化を行っていくものです。
ツール
PythonではGPyOptというツールでベイズ最適化を行うことができます。
詳しい使い方はこちらを参照ください。
Pythonでベイズ最適化を行うパッケージ GPyOpt
コードと使い方
今回書いたコードはこちらにあります。
https://github.com/shibuiwilliam/keras_gpyopt
中身を解説していきます。
まずはMNISTのモデルを定義します。
# Import libraries
import GPy, GPyOpt
import numpy as np
import pandas as pds
import random
from keras.layers import Activation, Dropout, BatchNormalization, Dense
from keras.models import Sequential
from keras.datasets import mnist
from keras.metrics import categorical_crossentropy
from keras.utils import np_utils
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
# MNIST class
class MNIST():
def __init__(self, first_input=784, last_output=10,
l1_out=512,
l2_out=512,
l1_drop=0.2,
l2_drop=0.2,
batch_size=100,
epochs=10,
validation_split=0.1):
self.__first_input = first_input
self.__last_output = last_output
self.l1_out = l1_out
self.l2_out = l2_out
self.l1_drop = l1_drop
self.l2_drop = l2_drop
self.batch_size = batch_size
self.epochs = epochs
self.validation_split = validation_split
self.__x_train, self.__x_test, self.__y_train, self.__y_test = self.mnist_data()
self.__model = self.mnist_model()
# load mnist data from keras dataset
def mnist_data(self):
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
return X_train, X_test, Y_train, Y_test
# mnist model
def mnist_model(self):
model = Sequential()
model.add(Dense(self.l1_out, input_shape=(self.__first_input,)))
model.add(Activation('relu'))
model.add(Dropout(self.l1_drop))
model.add(Dense(self.l2_out))
model.add(Activation('relu'))
model.add(Dropout(self.l2_drop))
model.add(Dense(self.__last_output))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
return model
# fit mnist model
def mnist_fit(self):
early_stopping = EarlyStopping(patience=0, verbose=1)
self.__model.fit(self.__x_train, self.__y_train,
batch_size=self.batch_size,
epochs=self.epochs,
verbose=0,
validation_split=self.validation_split,
callbacks=[early_stopping])
# evaluate mnist model
def mnist_evaluate(self):
self.mnist_fit()
evaluation = self.__model.evaluate(self.__x_test, self.__y_test, batch_size=self.batch_size, verbose=0)
return evaluation
# function to run mnist class
def run_mnist(first_input=784, last_output=10,
l1_out=512, l2_out=512,
l1_drop=0.2, l2_drop=0.2,
batch_size=100, epochs=10, validation_split=0.1):
_mnist = MNIST(first_input=first_input, last_output=last_output,
l1_out=l1_out, l2_out=l2_out,
l1_drop=l1_drop, l2_drop=l2_drop,
batch_size=batch_size, epochs=epochs,
validation_split=validation_split)
mnist_evaluation = _mnist.mnist_evaluate()
return mnist_evaluation
続いて上記のMNISTモデルを使ってベイズ最適化を行います。
# Bayesian Optimization
# 各パラメータの選択肢、範囲を定義します。
# 注意点:パラメータはtype: continuous、type: discreteの順に書く必要があります。
# そうしないと、後工程でエラーになりました。
bounds = [{'name': 'validation_split', 'type': 'continuous', 'domain': (0.0, 0.3)},
{'name': 'l1_drop', 'type': 'continuous', 'domain': (0.0, 0.3)},
{'name': 'l2_drop', 'type': 'continuous', 'domain': (0.0, 0.3)},
{'name': 'l1_out', 'type': 'discrete', 'domain': (64, 128, 256, 512, 1024)},
{'name': 'l2_out', 'type': 'discrete', 'domain': (64, 128, 256, 512, 1024)},
{'name': 'batch_size', 'type': 'discrete', 'domain': (10, 100, 500)},
{'name': 'epochs', 'type': 'discrete', 'domain': (5, 10, 20)}]
# ベイズ最適化する関数(上記で書いたブラックボックス)を定義します。
# xが入力で、出力はreturnされます。
def f(x):
print(x)
evaluation = run_mnist(
l1_drop = float(x[:,1]),
l2_drop = float(x[:,2]),
l1_out = int(x[:,3]),
l2_out = int(x[:,4]),
batch_size = int(x[:,5]),
epochs = int(x[:,6]),
validation_split = float(x[:,0]))
print("loss:{0} \t\t accuracy:{1}".format(evaluation[0], evaluation[1]))
print(evaluation)
return evaluation[0]
# 事前探索を行います。
opt_mnist = GPyOpt.methods.BayesianOptimization(f=f, domain=bounds)
# 最適なパラメータを探索します。
opt_mnist.run_optimization(max_iter=10)
print("optimized parameters: {0}".format(opt_mnist.x_opt))
print("optimized loss: {0}".format(opt_mnist.fx_opt))
GPyOpt.methods.BayesianOptimizationでベイズ最適化を行うメソッドが定義されています。
これを使うと、定義したパラメータの選択肢、範囲内(bounds)で最適な損失関数を得るパラメータを探索するのですが、注意点があります。
パラメータの選択肢、範囲内はdictで書き、type: continuousとtype: discreteで連続値か選択肢かを定義します。
ここでcontinuous、discreteの順番に書かないと、opt_mnist = GPyOpt.methods.BayesianOptimization(f=f, domain=bounds)でエラーになりました。
この書き方を知らず、2日くらいはまってました。
opt_mnist.run_optimization(max_iter=10)で最適なパラメータを探索します。
max_iterで探索のための学習実行回数の上限を指定します。
ここでは10回まで探索を行いますが、早めに収束するようであれば、より少ない回数で完了します。
プログラムの実行結果は以下のようになります。
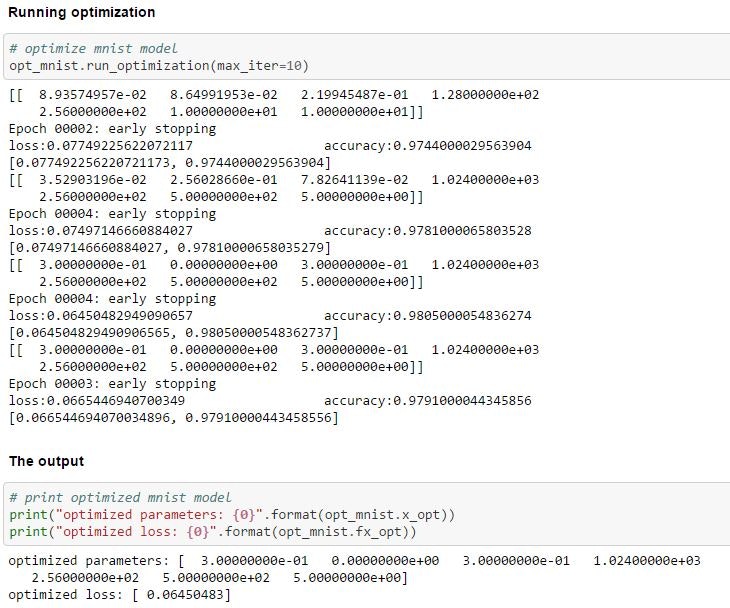
ここでは探索が4回で完了していることがわかります。
ベイズ最適化を使うことで、パラメータチューニングを自動化し、手間を削減することができます。