はじめに
ボケるRNNを学習したい (Chainer meetup 01)がすごく面白かったので,自分もChainerで実装をしました.それと,訓練したモデルをブラウザから直接確認できるアプリを作りました.
はじめに断っておくと,僕のやったことは基本的には元スライドの二番煎じで,差分と言えば学習データを増やして実験してみたこと(うまく学習されなかった)と,Webアプリを作ったこと程度です.
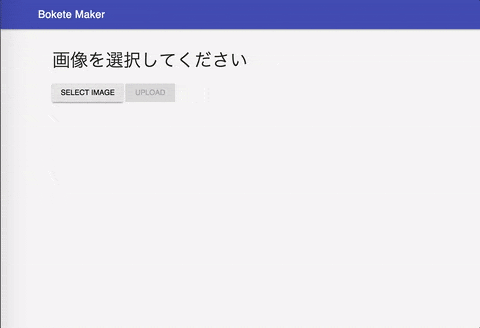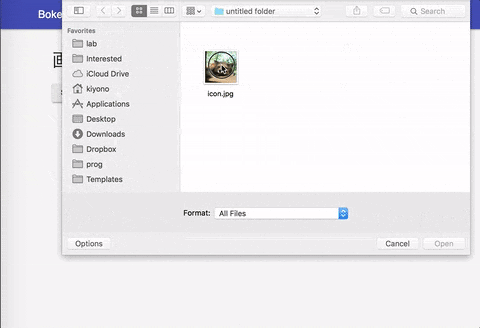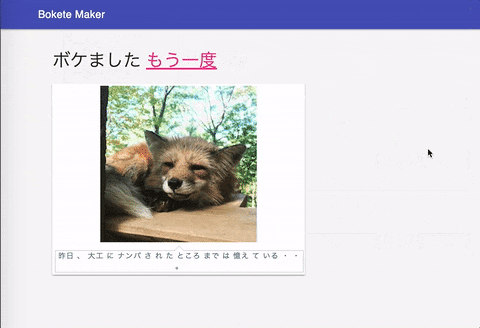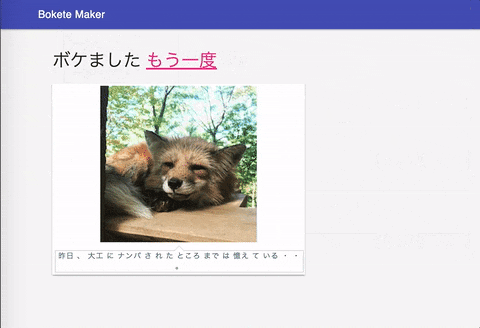
作ったWebアプリはこんな感じ.

今回作ったものはGitHubで公開しています.ドキュメントはそのうち書くかもしれません.
"ボケ"るためのモデル
Convolutional Neural Network (CNN)を使って抽出した画像の特徴を,Recurrent Neural Network(RNN)への入力にすることで画像の説明文(キャプション)生成ができる,という研究があります.有名なところでは[Karpathy+ 2015]や[Vinyals+ 2014]などが挙げられます.
 ([Vinyals+ 2014]より)
([Vinyals+ 2014]より)
この図では,画像(image)を入力として,多層のCNNを経由した後,LSTM(RNNの一種)へ入力し,説明文を1単語ごとに生成しています.簡単なモデルですが,驚くほど上手くいくことが知られていて,実際の生成例はここで見られます(これはKarpathyの方)
ところで入力した画像を"説明文"に翻訳することができるなら,入力した画像を"ボケ"に翻訳することも可能なのではないでしょうか?
つまり,**ニューラルネットで"ボケる"**こともできるのでは?
という直観のもと,これらのモデルをChainerで実装することにより,「全自動でボケるニューラルネット」を作りました.
使ったデータ・リソース
- CNNの学習済みモデル
- 画像に対するボケが付与されたデータ
1についてはCaffe用に提供されている学習済みモデルを使うのが楽でした.今回僕はCaffeNetを使いましたが,別に他のネットワークでも良いと思います.ただ,画像からの特徴抽出のためにはfc7レイヤー(全結合層)の出力が必要なので,GoogleNetのような軽めのモデルは(多分)使えません.
2についてはボケて(bokete) - 写真で一言ボケるウェブサービスという素晴らしいWebサービスがあるので,ここからクローリングして気合で集めます.元スライド著者の方も述べられていますが,ボケての各ページは「1画像+1テキスト」という簡単な構造をしているため,データを集めるのはそこまで難しくないと思います.
環境
- Chainer (ver. 1.17.0)
- Python 2.7系
ボケ元画像からの特徴抽出
ChainerはCaffeの学習済みモデルを読み込むことができるので,非常に便利です.
モデルクラスの中に以下のようなメソッドを定義して,その出力を使いました.
def encode_image(self, img_array):
batchsize = img_array.shape[0]
if self.config["use_caffenet"]:
img_x = chainer.Variable(img_array, volatile='on')
y = self.enc_img(
inputs={"data": img_x},
outputs={"fc7"})[0]
else:
x = self.xp.random.rand(batchsize, 4096).astype(np.float32)
y = chainer.Variable(x)
y.volatile = 'off'
return self.img2x(y)
img_arrayにはPILなどでベクトル化した画像ファイルが入ります.
このへんはChainerでcaffemodelを読み込んで画像を分類する - Qiitaなどを参考にしました.
ボケ元画像をLSTMへ入力する
抽出した画像の特徴をLSTMへと入力します.
これもモデルクラスに定義した通りです.
def __call__(self, x, img_vec=None):
if img_vec is not None:
h0 = self.embed_mat(x) + img_vec
else:
h0 = self.embed_mat(x)
h1 = self.dec_lstm(h0)
y = self.l1(h1)
return y
実際には時刻t=0のときのみ特徴を入力したいので,計算過程でn=0のときのみ画像ベクトルを与えています.
def _calc_loss(self, batch):
boke, img = batch
boke = self.xp.asarray(boke, dtype=np.int32)
img = self.xp.asarray(img, dtype=np.float32)
# 1. ベクトル化してある画像をCNNに入れて特徴ベクトルにする
img_vec = self.model.predictor.encode_image(img)
# 2. bokeをデコードするように学習
accum_loss = 0
n = 0
for curr_words, next_words in zip(boke.T, boke[:, 1:].T):
if n == 0:
accum_loss += self.model(curr_words, img_vec, next_words)
else:
accum_loss += self.model(curr_words, next_words)
n += 1
return accum_loss
「画像の特徴は毎時刻入力しないの?」と思われるかもしれませんが,これについては[Karpathy+ 2015]が
Note that we provide the image context vector b v to the RNN only at the first iteration, which we found to work better than at each time step.
と言っていまして,t=0のときのみ入力する方が良い出力が得られるそうです(実際に試してはいません).
ボケを学習させる: 大規模データ
先駆者であるボケるRNNを学習したい (Chainer meetup 01)の方が500サンプルで学習し,次は2万サンプルで試したいと書かれていたので,僕もそれくらいのスケールでやりたいと思い,約3万サンプルでの学習をしてみました.
(単語Embedding,LSTMの隠れ層ともに100次元,バッチサイズ16 Dropoutなどなし)
しかし,lossがうまく減っていかず.
"average_loss":[
10.557335326276828,
9.724091438064605,
9.051927699901125,
8.728849313754363,
8.36422316245738,
8.1049892753394,
7.999240087562069,
7.78314874008182,
7.821357278519156,
7.629313596859783
]
(ちなみに訓練データのlossです)
…と30エポックほど回した段階でlossが減らなくない状況になってしまいました.
ちなみに手元の画像でボケさせてみましたが,まとな出力は得られず….
これについては恐らくボケ3万に対してボケ元の画像が2000枚程度しかなかったのが原因です.
(「ボケて」からデータを取得してくる都合上,1枚の画像に対して複数のボケが付与されている)
一枚の画像に対して恐らくは10以上の正解(翻訳先)があるため,モデルのパラメータが一意の方向に調整されないのでは?と考えています.
ボケを学習させる: 小規模データ
「lossが減っていくことだけでも確認したい」ということで,画像1枚に対して1つのボケが対応するように配慮し,小規模データ(300ボケ程度)で実験をしたところ:
"average_loss": [
6.765932078588577,
1.7259380289486477,
0.7160143222127642,
0.3597904167004994,
0.1992428061507997
]
と確かにlossが減っていきました.(合計100エポックまで回しました)
このことから,大規模データの場合でも"画像-ボケ間に1対1の対応をもたせれば"lossは減っていく(=学習できる)と期待できます.
学習結果
手元の画像で試したところ,こんな出力が出ました.

(これボケてんのか…?)
Webアプリの作成
折角学習したんだし,ブラウザから確認できないとつまらないよね,ということでWebアプリも作りました.(コード公開してます)
 様子です.
様子です.
 学習に使ったデータの統計が見られます.
学習に使ったデータの統計が見られます.
 Generateボタンを押すことで訓練・開発データに対してのボケを見ることができます.
Generateボタンを押すことで訓練・開発データに対してのボケを見ることができます.
Webアプリの裏ではChainerの訓練済みモデルが読み込まれていて,ブラウザ側でボタンを押すとボケ生成メソッドが発火するようになっています.
おわりに
今回は[Karpathy+ 2015]や[Vinyals+ 2014]らの画像の説明文生成モデルを流用してボケの学習・生成をしたわけですが,ボケを扱うためにこのモデルが最適とは思いません.このモデルは,画像の説明文にただ1つの正解があることを仮定してモデルの設計・評価を行っているため,「画像に対するボケ」のような「任意の正解(=面白いボケ)が考えられる」データに対して適しているとは思えないからです.
現に,1枚の画像に対して複数の正解データ(ボケ)を与えて学習を試みた結果,lossが減らない現象に苦しめられました.
また,仮に訓練データに対してlossが減っていったとしても,恐らく開発データ上でのlossが減ることはないでしょう.(確実にもっと入力・出力のドメインを削る必要があるはずです e.g. 入力画像をオッサンに絞る,穴埋めお題を入れない,などなど)
そもそも,「入力画像に対してボケを生成」しようとするアプローチは妥当でしょうか?もっと素直なアプローチはないでしょうか?
例えば,入力画像に対し意図的に全く別の画像の説明文を付与すれば,それは面白いボケになるのではないでしょうか.
例えばこのように

(イメージです)
面白いボケのために果たしてニューラルネットは必要なのか…非常に悩ましいところですね.