前回は「Chainer」を使って多層パーセプトロンを実装し、CAPTCHA画像の認識を試みた。
今回はGoogleの画像分析API「Cloud Vision API」を使って同じことをやってみる。
アジェンダ
0.実装コード
1.やってみる
2.まとめ
3.参考文献
0.実装コード
今回は検証用にシンプルな画像分析用のクラスを作成した。
見て分かる通り、Cloud Vision APIで定義されたJSON形式のリクエストをPOSTするだけだ。
# !/usr/bin/python
# coding:utf-8
import base64
import json
from requests import Request, Session
# Cloud Vision APIで画像を分析
class RecognizeImage():
def __init__(self):
return
# CAPTCHAの分析
def recognize_captcha(self, str_image_path):
# CAPTCHA画像の読み込み
bin_captcha = open(str_image_path, 'rb').read()
# base64でCAPTCHA画像をエンコード
str_encode_file = base64.b64encode(bin_captcha)
# APIのURLを指定
str_url = "https://vision.googleapis.com/v1/images:annotate?key="
# 事前に取得したAPIキー
str_api_key = "XXXXXXXXX"
# Content-TypeをJSONに設定
str_headers = {'Content-Type': 'application/json'}
# Cloud Vision APIの仕様に沿ってJSONのペイロードを定義。
# CAPTCHA画像からテキストを抽出するため、typeは「TEXT_DETECTION」にする。
str_json_data = {
'requests': [
{
'image': {
'content': str_encode_file
},
'features': [
{
'type': "TEXT_DETECTION",
'maxResults': 10
}
]
}
]
}
# リクエスト送信
obj_session = Session()
obj_request = Request("POST",
str_url + str_api_key,
data=json.dumps(str_json_data),
headers=str_headers
)
obj_prepped = obj_session.prepare_request(obj_request)
obj_response = obj_session.send(obj_prepped,
verify=True,
timeout=60
)
# 分析結果の取得
if obj_response.status_code == 200:
print obj_response.text
return obj_response.text
else:
return "error"
APIを使う際に注意するのは以下3点。
- 分析対象の画像は必ずBase64エンコードする。
- APIを使うために、事前にAPIキーを取得しておく。
- 分析の用途に合わせて適切な「type」を指定する。
上記コードを実行すると、以下のようなリクエストがPOSTされる。
POST /v1/images:annotate?key=XXXXXXXXX HTTP/1.1
User-Agent: python-requests/2.8.1
Host: vision.googleapis.com
Accept: */*
Content-Type: application/json
Content-Length: 939
{
"requests":[
{
"image":{
"content": "iVBORw0KGgoAAAANSUhEUgA・・・(省略)・・・/EV4ihonpXVAAAAAElFTkSuQmCC"
},
"features":[
{
"type":"TEXT_DETECTION",
"maxResults":10
}
]
}
]
}
「content」にBase64エンコードした画像データを指定し、「type」に実行させたい分析内容を指定する。
今回はCAPTCHAの認識を行いたいので、テキスト抽出「TEXT_DETECTION」を指定する。
なお、テキスト抽出以外にも以下の分析が行えるとのことだ。
- 画像に映るものを理解
- 不適切なコンテンツを検知
- 画像の意味を分析
例えば、東京駅の画像をPOSTすれば「東京駅」と認識したり、喜んでいる画像をPOSTすれば「喜んでいる」と認識できるらしい。
これらは今後試してみたいと思う。
画像分析はかなり強力なマシンパワーを要するため、趣味で取り組むにはハードルが高かった。
しかし、このAPIを使えば、誰でも簡単に画像分析を行うことができる。
なんて素晴らしいAPIなんだ!
1.やってみる
早速これを使ってCAPTCHAの認識を行ってみる。
先ずは1番目のこれから。
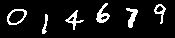
抽出したテキストは「description」に出力される。
{
"responses": [
{
"textAnnotations": [
{
"locale": "en",
"description": "O l 4.67 9\n",
"boundingPoly": {
"vertices": [
{
"x": 6,
"y": 1
},
{
"x": 165,
"y": 1
},
{
"x": 165,
"y": 35
},
{
"x": 6,
"y": 35
}
]
}
}
]
}
]
}
結果は「O l 4.67 9」だ。
0(ゼロ)を英大文字のオー「O」、1(イチ)を英小文字のエル「l」、変なドットが入っているが、概ね正しく認識できていることが分かる。
正解率は100%と言っても良いだろう。
次は2番目のこれだ。
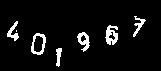
これは過去の検証では散々な結果になっていたが、果たしてCloud Vision APIではどうなるか?
{
"responses": [
{
"textAnnotations": [
{
"locale": "en",
"description": "496'0,\n",
"boundingPoly": {
"vertices": [
{
"x": 6,
"y": 10
},
{
"x": 148,
"y": 10
},
{
"x": 148,
"y": 70
},
{
"x": 6,
"y": 70
}
]
}
}
]
}
]
}
微妙にテキストの出力順が入れ替わっているが、「4」「0」「9」「6」は認識できている。
前回は50%の認識率だったので、改善されていることが分かる。
最後はこれだ。

{
"responses": [
{
"textAnnotations": [
{
"locale": "en",
"description": "425970\n",
"boundingPoly": {
"vertices": [
{
"x": 5,
"y": 7
},
{
"x": 97,
"y": 7
},
{
"x": 97,
"y": 33
},
{
"x": 5,
"y": 33
}
]
}
}
]
}
]
}
お見事!!
全て正確に認識できていることが分かる。
Googleが保持する膨大な画像データを基に学習を行っているのか、かなり高い精度でテキスト抽出ができる。
これならCAPTCHA認識に使用できるかもしれない。
ちなみに、Googleが開発した新型CAPTCHAの「reCAPTCHA」では、以下のように同じ動物・物を複数の画像から選択させることで、人間とbotの区別をしているらしい。

※出典:Gigazine(一部省略しています)
この例では、一番上の画像(猫)と同じ画像を全て選択する必要があるので、上段左から1番目と、下段左から2番目、3番目を選択するのが正解だ。
ちなみに、Cloud Vision APIを使うと、正確に猫と犬の区別ができることを確認した。
※単に「猫」「犬」だけの区別ではなく、種類(american shorthairやgerman shepherd dogなど)まで、ほぼ正確に区別することができる。
興味のある方は是非実行してみることをお勧めする。
※typeは「LABEL_DETECTION」にすること。
2.まとめ
Cloud Vision APIを使用してCAPTCHAの認識をやってみた。
多少改善点はあるが、CAPTCHA認識に使用できるほどの結果が出た。
また、単純なCAPTCHA(数字画像など)だけでなく、reCAPTCHAのような高度なものまで突破できる可能性があることが分かった。
本APIはトライアル期間が過ぎると課金されるが、自作でコードを書いたり、高スペックのマシンを用意することを考えれば、コストパフォーマンスは高いと考える。
今後、検証を重ねた上で、Webアプリケーションの自動クローラーのCAPTCHA認識エンジンに利用したいと思う。
3.参考文献
以上