前回はフルスクラッチで多層パーセプトロンを実装し、CAPTCHA画像の認識を試みた。
今回は「Chainer」を使って同じことをやってみる。
なお、「scikit-neuralnetwork」でも多層パーセプトロンを実装できるが、この検証はまたの機会とする。
アジェンダ
0.実装コード
1.やってみる
2.まとめ
3.参考文献
0.実装コード
以下1つのpythonコードのみ使用。
前回と比べて非常にコード量が少なくなっている。
mlp.py
# !/usr/bin/env python
# coding:utf-8
import os
import gzip, pickle
import pylab
import numpy as np
from chainer import Variable, FunctionSet, optimizers
import chainer.functions as F
# 学習データのロード
def train_data_read(file_path):
# 学習データ(MNISTの手書き文字)のロード
f = gzip.open(file_path, 'rb')
train, valid, test = pickle.load(f)
f.close()
return (train[0], train[1], train[0].shape[0])
# ニューラルネットワーク(多層パーセプトロン)の処理
def forward(x_data, y_data, train=True):
x = Variable(x_data)
t = Variable(y_data)
# 活性化関数に正規化線形関数(ReLU)を使用
# 汎化性能向上のためにドロップアウトを使用
h1 = F.dropout(F.relu(model.l1(x)), train=train)
h2 = F.dropout(F.relu(model.l2(h1)), train=train)
y = model.l3(h2)
# 誤差関数に交差エントロピーを使用
return F.softmax_cross_entropy(y, t)
# データの予測
def predict(x_test):
x = Variable(x_test)
# 活性化関数に正規化線形関数(ReLU)を使用
# 汎化性能向上のためにドロップアウトを使用
h1 = F.dropout(F.relu(model.l1(x)))
h2 = F.dropout(F.relu(model.l2(h1)))
y = model.l3(h2)
return np.argmax(y.data)
if __name__ == "__main__":
# 識別対象のCAPTCHA画像が格納されているファイルパスを定義
captcha_path = 'C:\MNIST\captcha\captcha0'
# 訓練用データ(MNIST)のファイルパスを定義
train_data_path = os.path.join('C:\\MNIST', 'mnist.pkl.gz')
# 正解ラベルの定義(結果表示用)
answerLabel = [0, 1, 4, 6, 7, 9]
# 予測対象データ(CAPTCHA画像)の取得
# 画像データを784次元のベクトルに変換
# RGB毎の配列からR要素のみを抽出(次元削減)
img_captcha = []
analize_data = []
captcha_files = os.listdir(captcha_path)
for file in captcha_files:
img_captcha = pylab.imread(os.path.join(captcha_path,file))
img_captcha_r = img_captcha[:, :, 0]
#img_captcha_r = img_captcha[:, :]
img_captcha_Array = np.asarray(img_captcha_r)
d_captcha = img_captcha_Array.shape[0] * img_captcha_Array.shape[1]
img_captcha_wide = img_captcha_Array.reshape(1, d_captcha)
analize_data.append(img_captcha_wide)
# 訓練データの取得
x_train, y_train, length = train_data_read(train_data_path)
x_train = x_train.astype(np.float32)
y_train = y_train.astype(np.int32)
# ニューラルネットワークの構築
# 入力層=784(28*28)、中間層=300、出力層=10(0~9)
model = FunctionSet(l1=F.Linear(784, 300),
l2=F.Linear(300, 300),
l3=F.Linear(300, 10))
# 確率的勾配降下法(SGD)で学習する際のバッチサイズ
# 10~100程度とすることが多いが、最も結果が良かった100とした。
batchsize = 100
# 学習の繰り返し回数
# 5回の学習で精度が95%を超えたため、5回とした。
learning_loop = 5
# SGDの設定
optimizer = optimizers.Adam()
optimizer.setup(model.collect_parameters())
# 学習
N = 50000
for epoch in range(1, learning_loop+1):
# 学習データの順番をランダムにする
perm = np.random.permutation(N)
# 0〜Nまでのデータをバッチサイズに区切って学習する
for i in range(0, N, batchsize):
x_batch = x_train[perm[i:i+batchsize]]
y_batch = y_train[perm[i:i+batchsize]]
# 重みの初期化
optimizer.zero_grads()
# フィードフォワードさせて誤差を算出
error = forward(x_batch, y_batch)
# バックプロパゲーションで勾配を算出
error.backward()
# 重みを更新
optimizer.update()
# CAPTCHAデータの予測
ok = 0
for i in range(len(analize_data)):
# 認識対象データを1個ずつ読み込む
x = analize_data[i].astype(np.float32)
# 認識対象の正解データを1個ずつ読み込む
y = answerLabel[i]
# CAPTCHAデータの予測
answer = predict(x)
# 予測値と正解データを標準出力する
print("No.{0:d} : predict => {1:d} , answer = > {2:d}".format(i, answer, int(y)))
# 予測値と正解データが一致している場合、ok(正解)を1インクリメントする
if int(y) == answer:
ok += 1
# ok(正解)の数と認識対象データ数を基に正解率を標準出力する
print("{0:05d} / {1:05d} = {2:3.2f}%".format(ok, len(analize_data), 100*ok/len(analize_data)))
フィードフォワードやバックプロパゲーション、確率的勾配降下法(SGD)やドロップアウトなどのテクニックが非常に簡易なコードで実現できる。
なんて素晴らしいライブラリなんだ!
1.やってみる
早速これを使ってCAPTCHAの認識を行ってみる。
先ずは1番目のこれから。
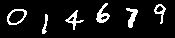
1番目の予測結果
No.0 : predict => 0 , answer = > 0
No.1 : predict => 1 , answer = > 1
No.2 : predict => 4 , answer = > 4
No.3 : predict => 6 , answer = > 6
No.4 : predict => 7 , answer = > 7
No.5 : predict => 9 , answer = > 9
00006 / 00006 = 100.00%
正解率は100%。
これは前回と変わりない。
次は2番目のこれだ。
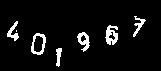
2番目の予測結果
No.0 : predict => 0 , answer = > 0
No.1 : predict => 1 , answer = > 1
No.2 : predict => 6 , answer = > 4
No.3 : predict => 8 , answer = > 6
No.4 : predict => 8 , answer = > 7
No.5 : predict => 9 , answer = > 9
00003 / 00006 = 50.00%
正解率は50%。
前回は33.33%だったので、改善されていることが分かる。
2.まとめ
Chainerを使用して数字画像の認識をやってみた。
前回より正解率が改善されている。
学習回数を増やせば更に正解率は上がると思われるが、前回も書いたように学習データを工夫しないことには根本解決にはならない。
むしろ今回の検証で特筆すべきは、非常に簡易なコードで多層パーセプトロンが実装でき、しかも正解率が改善できたことだろう。
今後、ChainerやDeapを使用してNeuroevolutionを実装し、Webアプリケーションの自動クローラーの開発を試みる。
3.参考文献
以上