前回 TensorFlowによる将棋ソフトの開発日誌(ゆっけさんの場合) #3
目次 TensorFlow将棋ソフト開発日誌 目次
将棋の盤面を見て勝敗を予測するマンを作ろう その3
引き続き勝敗予測モデルを作っていく。ようやくネットワークモデルと実験結果を載せられる。
繰り返しになるが言っておく。「すべては勘でできている」。
将棋の盤面を見て勝敗を予測するマン、とは
盤面の状況から先手と後手のどちらが勝つかを判別する判別器である。将棋の盤面を見て勝敗を予測するマンでは呼びにくいので勝敗予測モデルと呼ぶことにする。入力は前回説明したテンソルである。
実際は「自分の手番において自分の手を指した直後の盤面を入力に勝敗の判別を行う」という用途を想定している。この使い方で「自分の価値が判定される手」を選択していけば価値に近づくというわけだ。
ただし画像分類のタスクで見るような正答率95%みたいな性能は出せない。序盤も含めた全ての局面においてそのような成績が出る判別器が作れるのであればそれに従って指せば良いわけで苦労はない。せいぜいが正答率50%よりもやや大きい程度のいわゆる弱判別器で良い。勝敗予測モデルとは別に指す手を決定する指し手モデルを作るがこの指し手モデルの学習の初期においてランダムよりは意味のある手を学習させるために使用する。
勝敗予測モデルの構造
以下のようなモデルになる。パラメータは記事の末尾に添付するyamlを参照されたい。出力は [先手の勝利, 後手の勝利] の2要素ベクトルである。1要素で表現しても良かったがなんとなくそうした。
ロスは実際の勝敗ベクトルとの二乗誤差。学習においては sqrt(手番/総手番) で重み付けしている。序盤のほうが勝敗予測の難易度が高い(ランダム性が高い)ため学習の量を少なくしたかったためである。オプティマイザはAdam。
構造もパラメータも Google の inception の論文を見ながら適当に決めた。本当は inception レイヤーも作りたかったがとりあえず動かしたかったのである。
繰り返すが「勘で作っている」

実験と経過
前々回に説明した 2chkifu からランダムに盤面を取得してきて勝敗を学習させた。コーディングがめんどくさかったので先手のみ学習させている。そのうち後手視点の盤面も実装する。メモリ容量の関係からバッチ学習は行っていない。本当はやるべきだと思う。CPUはCore i7のちょっと古めのやつ。ホストメモリは32GB、GPUはGTX 1080。ほとんどのノードはGPUで処理している。
まずは正答率。学習時の出力の正解数の過去1000件の移動平均でログをとっている。薄い線が実際の出力。濃い線はtensorboardのスムージング。
概ね52%付近で推移していて要件は満たしている。しかし110k件学習しても安定せず有意なものなのかよくわからない。ぶっちゃけサンプルの勝敗割合に従ってランダムに勝敗を出力してもそれっぽくなるわけだし。

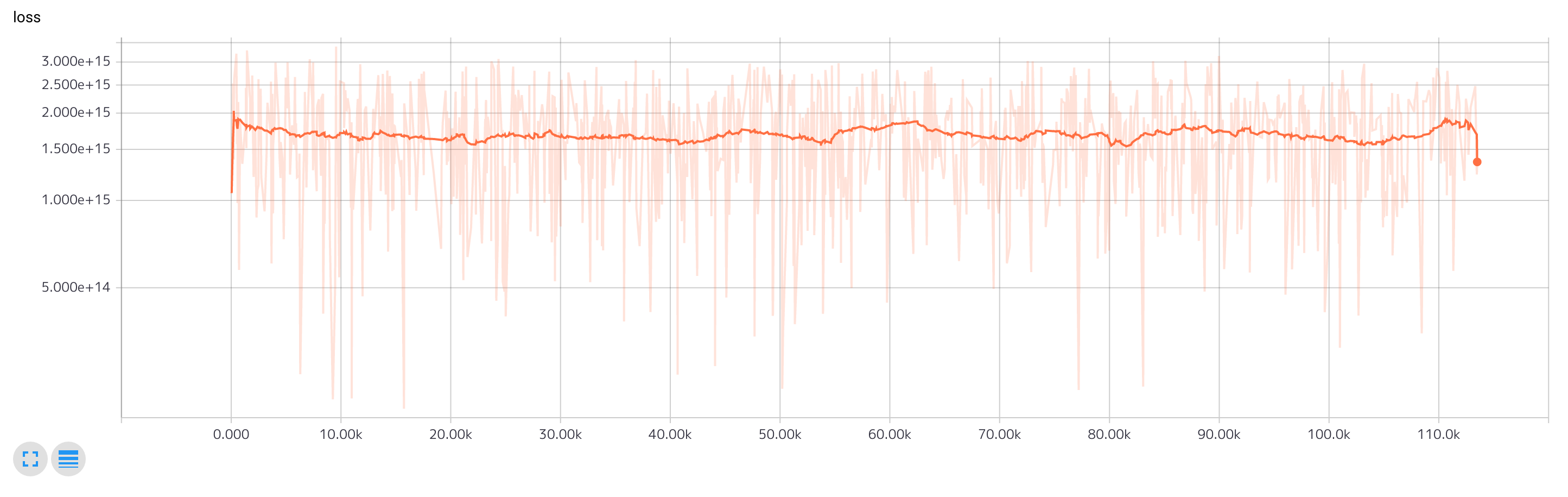
ロスの推移。手番による重み付け後なのであまり参考にならない。重み付け前の値を出力するべきだった。それにしたって収束しなさすぎな感じがある。何か間違っているのか・・・。
課題や疑問点
疑問点
- 110kサンプルを学習するのに10時間ほどかかっている。5mサンプルほど学習させたいのだがなんとかならんだろうか。札束か?札束なのか?
- 勝敗予測モデルは上に書いた通りそれほど性能は必要としていない。しかし十分にサンプルは学習させたい。ロスが収束しない(判別がしづらい)場合にそうはいっても学習を十分にしたという判断のための指標はなんなのか。言い換えるとモデルが表現できる空間の許容量をどれだけ満たしたのかの判断基準があるのかどうか。ちょっと深い問題かも知れない。
- conv層の活性的なことは一切していないのだけれどReLUあたりを入れたほうが良いのだろうか。試してみたい。
ToDo
- バッチ学習、メモリの許す限りやりたい
- モデルの複雑化、これもメモリが許す限りやりたい
- GPUの使用率があがらない問題の調査。データ生成、ロギングなどが原因だと思う。スレッド化などTensorFlowをもっと使いこなさないといけない。
- 後手視点での学習。盤面データを加工して後手を下側にして学習させる。
- 盤面の左右反転(将棋は左右反転しても勝敗の結果は変わらない)
- いっそはじめの10手くらいは学習しないほうがよいかも知れないので試してみる
- 金を稼いで札束で殴る
- あと指し手モデルにも着手しないと
次回
楽しい週末はもう終わり。また、暇ができたらね。指し手モデルに取り掛かりたいね。
付録 モデルのyaml
これが何なのかは An attempt to be able to design TensorFlow model with YAML を参照。一部ストライドなどデフォルトのパラメータを使っているので見えないけれど雰囲気が伝わればということで。
# input: [9,9,148]
root: !root
nodes_required: ['root']
nodes:
- !with
device_scope: '/gpu:0'
nodes:
- !with
variable_scope: conv1
nodes:
- !conv2d
# todo: set stride
{ nid: c1, source: root, width: 9, height: 9, kernels_num: 300, b_init: 1e-5 }
- !with
variable_scope: conv2
nodes:
- !conv2d
{ nid: c2, source: c1, width: 7, height: 7, kernels_num: 600, b_init: 1e-5 }
- !with
variable_scope: conv3
nodes:
- !conv2d
{ nid: c3, source: c2, width: 5, height: 5, kernels_num: 900, b_init: 1e-5 }
- !with
variable_scope: maxpool1
nodes:
- !max_pool_2x2
{nid: mp1, source: c3}
- !with
variable_scope: conv4
nodes:
- !conv2d
{ nid: c4, source: mp1, width: 3, height: 3, kernels_num: 1200, b_init: 1e-5 }
- !with
variable_scope: conv5
nodes:
- !conv2d
{ nid: c5, source: c4, width: 3, height: 3, kernels_num: 1200, b_init: 1e-5 }
- !with
variable_scope: maxpool2
nodes:
- !max_pool_2x2
{nid: mp2, source: c5}
- !with
variable_scope: conv6
nodes:
- !conv2d
{ nid: c6, source: mp2, width: 3, height: 3, kernels_num: 1200, b_init: 1e-5 }
- !with
variable_scope: conv7
nodes:
- !conv2d
{ nid: c7, source: c6, width: 3, height: 3, kernels_num: 900, b_init: 1e-5 }
- !with
variable_scope: conv8
nodes:
- !conv2d
{ nid: c8, source: c7, width: 3, height: 3, kernels_num: 600, b_init: 1e-5 }
- !with
variable_scope: avgpool1
nodes:
- !avg_pool
{ nid: t_ap1, value: c8, width: 3, height: 3}
- !dropout
{ nid: ap1, x: t_ap1, keep_prob: 5e-1 }
- !with
variable_scope: linear1
nodes:
- !linear
{ nid: l1, name: l1, source: ap1, b_init: 1e-5, length: 300}
- !with
variable_scope: linear2
nodes:
- !linear
{ nid: l2, name: out, source: l1, b_init: 1e-5, length: 2}
- !with
variable_scope: train
device_scope: '/gpu:0'
tags: [train]
nodes:
- !placeholder
{ nid: label, name: label, tag: train, dtype: tf.float32, shape: [2]}
- !placeholder
{ nid: turn_weight, name: turn_weight,
tag: train, dtype: tf.float32, shape: [1]}
- !prophet_loss
{ nid: p_loss, tag: train,
source1: l2, source2: label, source3: turn_weight }
- !adam_optimizer {tag: train, name: optimizer, source: p_loss, val: 1e-4}
- !with
variable_scope: log
device_scope: '/cpu:0'
tags: [train, log]
nodes:
- !reduce_mean
{nid: loss_mean, source: p_loss, dims: [1]}
- !scalar_summary
{summary_tag: 'loss', source: loss_mean}