はじめに
Bluemixから利用できるWatson APIのひとつであるVisual Recognition(VR)が5月20日でV3になりGAになった。
V2では遅れをとったので、今回は一番乗りを目指し、早速使ってみた。
V3になって変わったこと
まずはドキュメントを見て欲しい。
V3になって一番の変化は、AlchemyVisionとの統合だろう。AlchemyVisionの持っていた「顔認識」「文字認識」の機能が統合され、「Detect faces」「Recognize text」というAPIとして提供された。
今までAlchemyとVRで棲み分けはどうするのだろうという疑問があったが、それにひとつの答えが示されたようである。
ただし、顔認識や文字認識のクラスの学習は残念ながらまだできないようだ。今後に期待である。
今までのイメージ判別の部分も地味にだけど大きく変わった。
今まではPositiveイメージ群1つとNegativeイメージ群1つで学習させていたが、今度はPositiveイメージ群が複数種類一度に学習させることができるようになった。1つの分類器で複数クラスに分類が可能というわけだ。(もっともこれは、ユーザーから見てひとつに見えるだけで、実は裏では今までと同じように分類器が複数いるだけかもしれないが、中の人じゃないとそこまではわからないだろう。)
用意するデータは「You must supply at least two compressed files, either two positive example files or one positive and one negative example file.」とのことなので、Positiveだけでもいいし、PositiveとNegativeの組み合わせでもいいので、最低2つあればいい。
そしてファイルサイズ。「There is no limit on the number of positive example files you can upload in a single call.」ということで無制限に指定できる。V2ではPositiveとNegativeで各1000枚、合計100MBまでという制約があったが、それが解除されたわけでかなりの太っ腹である。
MNISTの手書き数字で試してみる
ということで、以前試したMNISTの手書き数字の例を使ってみようと思う。(実はちょっとした事故でMNISTのVRインスタンスを消してしまっていたのだ・・・)
画像データは前回のデータを使って、次のコマンドを実行するのだが、学習にかかった時間がわかるように前後をdateコマンドではさんでみた。
curl -k -X POST
-F "Number0_positive_examples=@number0.zip"
-F "Number1_positive_examples=@number1.zip"
-F "Number2_positive_examples=@number2.zip"
-F "Number3_positive_examples=@number3.zip"
-F "Number4_positive_examples=@number4.zip"
-F "Number5_positive_examples=@number5.zip"
-F "Number6_positive_examples=@number6.zip"
-F "Number7_positive_examples=@number7.zip"
-F "Number8_positive_examples=@number8.zip"
-F "Number9_positive_examples=@number9.zip"
-F "name=MNIST"
"https://gateway-a.watsonplatform.net/visual-recognition/api/v3/classifiers?api_key={api-key}&version=2016-05-20"
結果はこのようなものが1分と待たずに返ってきた。
{
"classifier_id": "MNIST_1432699714",
"name": "MNIST",
"owner": "<オーナーID>",
"status": "training",
"created": "2016-05-23T09:52:20.698Z",
"classes": [
{"class": "Number3"},
{"class": "Number2"},
{"class": "Number1"},
{"class": "Number0"},
{"class": "Number7"},
{"class": "Number6"},
{"class": "Number5"},
{"class": "Number4"},
{"class": "Number9"},
{"class": "Number8"}
]
こんなに早くトレーニング完了か!?と思ったら「status」は「training」。つまり、VRとしてはリクエストを受け付けたよ、こういう分類器作るよーっていうのを返してくれているだけだった。NLCと同じような方式ってことだ。V2のように応答が返ってこなくなるよりナンボかまし。いい修正だと思う。
ということで、待つ。
あちらの昼間時間帯だからか、2時間経っても終わらなかった。結局3~4時間くらいかかったようだ。(諦めて帰宅したら、帰ったころには終わっていた。)
{
"classifier_id": "MNIST_1432699714",
"name": "MNIST",
"owner": "<オーナーID>",
"status": "ready",
"created": "2016-05-23T09:52:20.698Z",
"classes": [
{"class": "Number3"},
{"class": "Number2"},
{"class": "Number1"},
{"class": "Number0"},
{"class": "Number7"},
{"class": "Number6"},
{"class": "Number5"},
{"class": "Number4"},
{"class": "Number9"},
{"class": "Number8"}
]
完了すると「status」が「ready」になった。
ということで、試しに1つ投げてみた。リクエストを出す際に、V3ではparametersという引数でJSON形式のパラメーターを渡す必要がある。ドキュメントのサンプルを参考に以下のようにしたら動いた。urlは空欄でも大丈夫だった。Ownersはme以外でも大丈夫だった。この指定に意味はあるのだろうか・・・?
{
"url": "",
"classifier_ids": ["MNIST_1432699714"],
"owners": ["vegasato"],
"threshold": 0.2
}
で、リクエストは次のように出す。
curl -k -X POST -H "Accept-Language: ja" -F "imagesfile=@images_test/0_0000.jpg" -F "parameters=@myparms.json" "https://gateway-a.watsonplatform.net/visual-recognition/api/v3/classify?api_key={api-key}&version=2016-05-20"
結果はこうなった。閾値を0.2にしたので確立20%以上のものが返るわけだが、0の確率が99.6%、6の確率が37.5%ということでほぼ0で間違いないと判断している。なるほど、素晴らしい。
{
"images": [
{
"classifiers": [
{
"classes": [
{
"class": "Number0",
"score": 0.996482
},
{
"class": "Number6",
"score": 0.37466
}
],
"classifier_id": "MNIST_1432699714",
"name": "MNIST"
}
],
"image": "0_0000.jpg"
}
],
"images_processed": 0
}
気になるMNISTのAccuracy
ということで、あとは前回よろしく、MNISTのテストデータを全て食わせてAccuracyを出してみた。
その結果は・・・
| テストイメージ数 | 10,000 |
|---|---|
| 予測できたもの(>0.2) | 9,951 |
| 正解 | 9,819 |
| 不正解 | 132 |
| 予測できなかったもの | 49 |
ということで、Accuracy=0.9819でした。
こっちの結果とあわせてみたら次のようなグラフになった。(どうも前回は横軸スケールが合ってなかったらしく、今回はスケールを合わせてみた。)
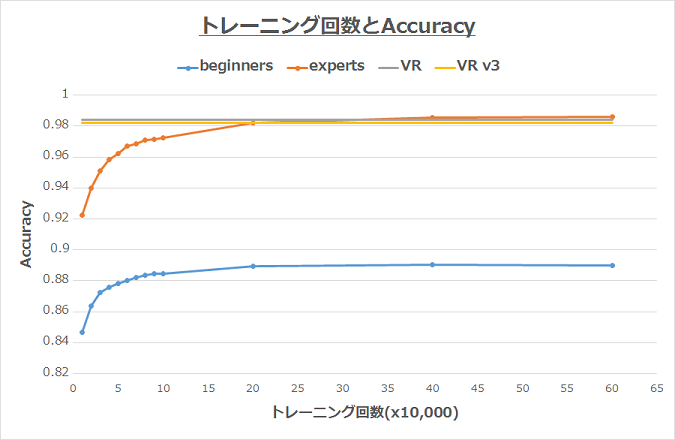
どうだろうか。V2のVR(=0.9840)と比べるとV3の方が若干低い値だが誤差といえば誤差に思える。それよりも、Negativeイメージをいちいち用意しなくてもいい点、学習が1発コマンド叩けばOKな点などを考慮すると、使い勝手はよくなったけど精度はほぼ変わらず、と言えるのではないか。
おわりに
ということで、GAになったVisual Recognitionは、学習はより簡単になったけど精度は犠牲になっていない。素晴らしいの一言。あとは学習時間だけどなぁ・・・こればっかりはサーバー側のパフォーマンスだからなぁ・・・裏で何やってるかわからないからなぁ・・・。