はじめに
この文書では、OAuth 2.0 + OpenID Connect サーバーをゼロから一人で実装した開発者(私)が、得られた知見について書いていきます。基本的には「実装時に考慮すべき点」を延々と述べることになります。 そのため、この文書は、「素早く OAuth 2.0 + OpenID Connect サーバーを立てる方法」を探している方が読む類のものではありません。そのような情報をお求めの方は、「Authlete を使って超高速で OAuth 2.0 & Web API サーバーを立てる」を参照してください。そちらには、「何もない状態から認可サーバーとリソースサーバーを立て、アクセストークンの発行を受けて Web API をたたいて結果を得る」という作業を、所要時間 5 ~ 10 分でおこなう方法が紹介されています。
文書のバイアスについて
私は、OAuth 2.0 + OpenID Connect の実装をクラウドで提供する会社 Authlete, Inc. (オースリート) の創業者です。そのため、本文書内の見解にはそのような立場からのバイアスがかかっている可能性がありますので、その点は適宜割り引いてお読みください。しかしながら、基本的には純粋な技術者としての視点で書いています。
そもそも OAuth は必要なのか
「自社の Web サイトで○○したいのだが、OAuth でやるべきなのか?」という質問は、意外とよくされます。この質問は実質的に「OAuth とは何なのか?」を問うています。
私がよく使う、一文での OAuth の説明は次のようなものです。
OAuth 2.0 とは、サービスのユーザーが、サービス上にホストされている自分のデータへのアクセスを、自分のクレデンシャルズ (ID & パスワード) を渡すことなく、第三者のアプリケーションに許可するためのフレームワークである。
OAuth 2.0 is a framework where a user of a service can allow a third-party application to access his/her data hosted in the service without revealing his/her credentials (ID & password) to the application.
重要なのは「第三者のアプリケーションにユーザーの ID & パスワードを渡さない」という点です。これを実現したいがために OAuth があります。この点を理解しておけば、自社サービス用の OAuth サーバーを用意すべきか否かは、次の条件が成り立つかどうかで判断可能ということが分かると思います。
- 自社サービスでは、ユーザーのデータを管理している。
- 自社サービスのユーザーが使うアプリケーションを、第三者に作成してもらいたい。
- 第三者が作成するアプリケーションには、ユーザーの ID とパスワードを教えたくない。
上記の条件を満たしておらず、「自社サービス用アプリケーションは自社製のみである」という場合でも、「将来的には第三者にアプリケーションを作成させる可能性がある」のであれば、また、「Web API 開発のベストプラクティスがあればそれに倣いたい」というのであれば、OAuth サーバーを実装するのがよいでしょう。
ここまでは良いとしても、それでも混乱することがあります。それは、「自社のサイトにユーザーをログインさせる際、Facebook や Twitter などの外部サービスのアカウントも使えるようにしたい」、という話が出てきたときです。このとき「OAuth 認証」という言葉が出てくることが多いため、「やはりうちのサイトでも OAuth を実装しなければならないのでは?」と勘違いしてしまうことがあります。しかしこのケースでは、自社サービスは、外部サービスが実装した OAuth を利用する側ですので、自社サービス自体は OAuth を実装する必要はないのです。正確に言うと、他社の OAuth を利用するためのコード (すなわち OAuth クライアント) を書く必要はありますが、自社サービス用の OAuth サーバーを実装する必要はないのです。
認証と認可
ここで、最も混乱を招いている「OAuth 認証」という言葉について説明します。
どの説明文書を読んでも、「OAuth は 認可 (authorization) の仕様であり、認証 (authentication) の仕様ではない」と書かれています。というのも、RFC 6749 (The OAuth 2.0 Authorization Framework) の 3.1. Authorization Endpoint に、認証方法については「この仕様の範囲外である」と明確に書いてあるからです。
The authorization endpoint is used to interact with the resource owner and obtain an authorization grant. The authorization server MUST first verify the identity of the resource owner. The way in which the authorization server authenticates the resource owner (e.g., username and password login, session cookies) is beyond the scope of this specification.
にもかかわらず、世の中には「OAuth 認証」という言葉が氾濫しているため、混乱している人が多いです。この混乱はビジネスサイドの人々だけに見られるものではなく、エンジニアリングサイドにも理解していない人は少なからずいて、Stack Overflow にも「OAuth Authorization vs Authentication」という類の質問が投稿されることがあります。 (ちなみにこの質問に対する私の回答はこちら)
ここで、認証と認可という用語がそれぞれどのような情報を扱うのかを簡潔に示します。
| 用語 | 扱う情報 |
|---|---|
| 認証 Authentication |
誰であるか Who one is. |
| 認可 Authorization |
誰が誰に何の権限を与えるか Who grants what permissions to whom. |
認証は単純な概念で、別の言葉で言えば本人確認です。Web サイトにおける本人確認の最も一般的な方法は ID とパスワードの組を提示してもらうことですが、指紋や虹彩などの生体情報を用いた本人確認方法もありえます。どのような確認方法だとしても (ワンタイムパスワードを使ったり、2-way 認証だったりしても)、認証とは、誰なのかを特定するための処理です。開発者の言葉でこれを表現すると、「認証とは、ユーザーの一意識別子を特定する処理」と言えます。
一方、認可のほうは、「誰が」、「誰に」、「何の権限を」、という三つの要素が出てくるため、複雑になります。加えて、話をややこしくしているのは、この三つの要素のうち、「誰が」を決める処理が「認証処理」であるという点です。すなわち、認可処理にはその一部として認証処理が含まれているため、話がややこしくなっているのです。
認可の三要素をもう少し現場に近い言葉で表現すると、「誰が」の部分は「ユーザーが」に、「誰に」の部分は「クライアントアプリケーションに」に置き換えることができます。ですので、OAuth の文脈でいうところの認可とは、「ユーザーがクライアントアプリケーションに権限を与える」処理だと言うことができます。
ここまで理解できたところで、次の図を見てください。
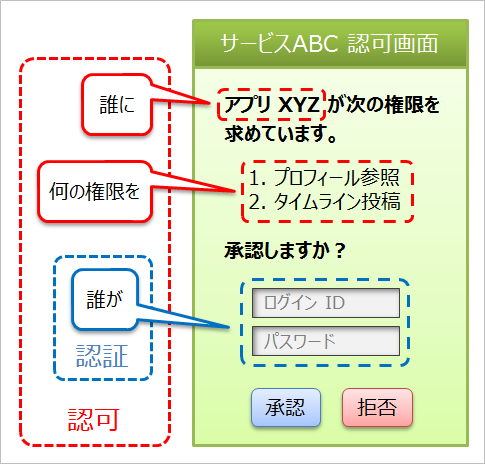
この図は、認可画面 (ユーザーがクライアントアプリケーションに権限を与えるための画面) の構成要素のどの部分が認証にあたり、どの部分が認可にあたるのかを示しています。これですっきりしました。認証と認可の違いが明確になったことと思います。
さて、やっと本題の「OAuth 認証」の話です。
認可処理には認証処理が含まれているので、認可されたということは、ユーザーが認証された、ということを意味します。このため、「OAuth を認証に流用してしまおう」という人々が現れました。これが「OAuth 認証」です。「ユーザーの ID とパスワードの管理を外部サービスに任せることができる (= 自社サービスでやる必要がない)」、「ユーザー登録作業を省略できるため、自社サービス利用開始の敷居が下がる (= 登録作業の煩雑さに起因するユーザー離脱を回避できる)」、といった利点があったため、OAuth 認証は一気に広まりました。
この状況を見て面白くなかったのは、OpenID 界隈の方々です。いや、実際に面白くなかったどうかは知りませんが、彼等の基準からすると、OAuth 認証による認証はレベルが低く、彼等が今までに策定してきた OpenID 2.0 や SAML といった仕様群が目指してきたレベルには程遠いと感じていたことでしょう。しかしながら、彼等が策定した仕様はあまり普及しなかったこと、世の中の開発者達が OAuth 認証の手軽さのほうを選んだことは事実でした。そこで彼等は、認証のための新しい仕様である OpenID Connect を、OAuth 上に乗せる形で策定しました。OpenID Connect の FAQ には、次のような式が書いてあります。
(Identity, Authentication) + OAuth 2.0 = OpenID Connect
これにより、OAuth による認可と同時に、OpenID Connect による認証もできるようになりました。
OpenID Connect は、業界大手が仕様策定作業に参画している上※1、実装も積極的になされているので、普及することは間違いないでしょう。結果、OAuth 認証はフェードアウトしていくことになります。OmniAuth などの OAuth 認証ライブラリは徐々に役目を終えていくことになるでしょう。
※1: AOL, Deutsche Telekom, Facebook, Google, Microsoft, Mitre Corporation, mixi, Nomura Research Institute, Orange, PayPal, Ping Identity, Salesforce, Yahoo! Japan and other individuals and organizations. (from FAQ)
しかしながら、認可のための OAuth の上に、認証のための OpenID Connect を乗せたことで、人々がさらに混乱することは必至です。説明する方も大変です。私などは、「認可に特化しており、(OpenID Connect をサポートしているが) 認証はやらない」という自社プロダクトの性質上、プロダクトの説明に先立って、毎回「認証と認可の違い」から説明を始めないといけません。あまりに毎回同じことを説明しているので、Qiita に書いて公開しよう、と思った結果がこれまでの説明です。
[2016/02/24] コメント欄で tienlen 様から情報をいただきましたので加筆します。
4年ほど前、ジョン・ブラッドレー氏の記事を紹介する形で、OpenID Foundation Chairman の崎村さん (Leadership) が「単なる OAuth 2.0 を認証に使うと、車が通れるほどのどでかいセキュリティー・ホールができる」という記事を公開されています。OAuth 認証の危険性を示し、
ちゃんと治してくださいね、皆さん。治すってことは、OpenID Connect 対応するってことですよ!
とおっしゃっています。サーバー側の実装はともかく、クライアント側の OAuth 認証を OpenID Connect に置き換えることは比較的工数がかからないので、みなさん OpenID Connect に対応しましょう!
余談ですが、以前崎村さんにお会いしたときに「OpenID Connect の仕様の複雑さに発狂しそうになりました」とお伝えしたところ、「それでも(過去の関連仕様と比べて)だいぶ簡単にしたんですけどね」というような感じのお返事をもらいました。そのときに思ったのは、「あの仕様を簡単と言うとは、この方はどれだけ頭いいんだ・・・」でした。OpenID Connect のサイトには、OpenID Connect のことを「simple identity layer」と紹介していて、おそらく OpenID Foundation の頭のいい方々は嘘偽りなく simple だと思っているのでしょうが、良い意味であまり真に受けず、OpenID Connect にはしっかりした体制で取り組むことをお勧めします。
OAuth 2.0 と OpenID Connect
ここに至るまでにだいぶ文章を書きましたが、これまでのものは全て前置きです。技術的な話はここからです。まずは、OAuth 2.0 と OpenID Connect の関係から。
私が OpenID Connect の存在を知ったのは、RFC 6749 (The OAuth 2.0 Authorization Framework) を一通り実装し終わった後でした。OpenID Connect の情報を集めるにつれ、「この機能はサポートすべき」と思い、OpenID Connect Core 1.0 を始めとする関連仕様を読みました。そして至った結論が、全て作り直しでした。
OpenID Connect のウェブサイトには、"OpenID Connect 1.0 is a simple identity layer on top of the OAuth 2.0 protocol." と書いてあり、あたかも既存の OAuth 2.0 の実装上に綺麗に乗せられるような印象を与えていますが、実際は全くそんなことはないです。私見では、OpenID Connect は実質的に OAuth 3.0 です。
なお、OpenID Connect の関連仕様は大量にあり、パズルのようで、読み解くのはかなり大変です。私も発狂しかけましたが、読み直し三回目でやっと全体像を把握できました。OpenID Connect の仕様に比べると、RFC 6749 は簡単な部類に入ります。
[2016/06/01] **「OAuth & OpenID Connect 関連仕様まとめ」**を書きました。RFC 群や OIDC 仕様群の紹介のほか、認証コンテキストクラスやリクエストオブジェクトなどの話もありますので、是非ご覧ください。
応答タイプ (response_type)
特に既存の実装と大きくぶつかるのは、認可リクエストパラメーター response_type の処理です。 RFC 6749 では一応、response_type は複数の値を取りうることになっていますが、それは将来的な拡張可能性の話であって、RFC 6749 を素直に読めば、response_type が取りうる値は code と token の二者択一です。これらが同時に response_type に含まれるということを想像するのはまず不可能です。というのは、このパラメーターはクライアントアプリケーションからのリクエストを処理するフローを決めるために使われるからです。具体的には、response_type が code であれば認可コードフローを、token であればインプリシットフローを使ってリクエストを処理します。これらのフローが混ぜ合わされるなどと、誰が想像できるでしょうか? 仮に想像できたとして、これらのフロー間に生じうる矛盾点をどのように解決すればいいのでしょうか? 例えば、認可コードフローには応答パラメーターをリダイレクト URI のクエリー部に入れるという要求仕様 (4.1.2. Authorization Response) がある一方、インプリシットフローにはフラグメント部に入れるという要求仕様 (4.2.2. Access Token Response) があり、これらは同時には成り立たないのです。
ところが、OpenID Connect では、response_type が取りうる値に id_token を追加した上で、code、token、id_token を任意の組み合わせで指定できるようにしました。加えて、単独で none を指定することも可能としました。詳細は、OpenID Connect Core 1.0 の 3. Authentication と OAuth 2.0 Multiple Response Type Encoding Practices に記述されています。
二者択一前提で書かれていたコードを任意の組み合わせに対応するように変更するのは、しかもリクエスト処理フローが混ざるというのは、大変な改造が必要です。ですので、OAuth 関連のライブラリは、将来 OpenID Connect をサポートする可能性があるのならば、最初から OpenID Connect を考慮して書かれるべきです。逆に、既存の OAuth ライブラリは、大規模な改造なくして OpenID Connect には対応できないのです。
例えば Spring Security OAuth。このライブラリは OpenID Connect にまだ対応していませんが (2016 年 2 月現在)、対応するにはまず、response_type で code と token 以外の値も取れるようにしなければなりません。それに関する要望が「Issue #619 Handling additional response_types」として上がっています。しかし、いまだ未解決のままで、"this turned out to be (as I predicted) a large refactor exercise." (大規模なリファクタリングが必要なことは分かった) というコメントで止まっています。該当する箇所のソースコードを見てみましたが、やはり大きな設計変更なくして OpenID Connect 対応は無理そうです。もしも Spring Security OAuth プロジェクトが、純粋なボランティアベースのプロジェクトだとしたら、この規模の設計・実装変更はほぼ無理でしょう。なので、Spring Security OAuth が OpenID Connect をサポートするのを期待して待っている人がいるとしたら、それは諦めたほうがいいです。
ついでに Apache Oltu にも言及しておきます。 Apache Oltu は OpenID Connect をサポートしているとのことですが、おそらく元々は OAuth 2.0 のみがサポートされていて、そこに後から OpenID Connect を追加したのだと思います。 OAuth 用のパッケージ org.apache.oltu.oauth2 と OpenID Connect のパッケージ org.apache.oltu.openidconnect が別々になっているからです。しかし、このようなことをすると、設計に歪みが出てきます。 例えば OpenIdConnectResponse というクラスが、継承ツリー上OAuthAccessTokenResponseの子孫にあたるというのは不適切です。なぜなら、ID トークンを含むレスポンス (OpenIDConnectResponse は getIdToken() というメソッドを持っている) は必ずしもアクセストークンを含むとは限らないからです。その他、Apache Oltu には、OAuthClientRequest.AuthenticationRequestBuilder という名前のクラスがあったり (Authorization ではなく Authentication という名前になっている)、何故だか GitHubTokenResponse という GitHub 固有のクラスが定義されていたりと、その設計には多くの疑問符が付きます。このプロジェクトの詳細は知りませんが、私見では、消えゆく運命にあるプロジェクトです。
クライアントアプリケーションのメタ情報
RFC 6749 の 2. Client Registration に明示的に書いてありますが、認可リクエストに先立ち、クライアントアプリケーションを事前に認可サーバーに登録しておく必要があります。そのため、認可サーバの実装者は通常、クライアントアプリケーションの属性情報を格納するデータベーステーブルを定義することになります。
そのテーブルにどのようなカラムを持たせるかは、仕様を読んでリストアップしていくことになります。例えば、RFC 6749 を読んでいくと、少なくとも次のような項目が必要であろうことは分かります。
- クライアント ID
- クライアントシークレット
- クライアントタイプ
- リダイレクト URI
これに、実装者の考えでカラムを追加していきます。例えば「クライアントアプリケーション名」などです。
RFC 6749 をくまなく読んでも、クライアントアプリケーションの属性数は大したことにはなりません。そのため、クライアントアプリケーションの属性情報を格納するテーブルのカラム数も大したことにはなりません。・・・という時代は OpenID Connect の登場とともに終わりました。 OpenID Connect Dynamic Client Registration 1.0 の 2. Client Metadata には、クライアントアプリケーションが持っておくべきメタ情報が大量にリストされています。
| 項目名 | 説明 |
|---|---|
redirect_uris |
リダイレクト URI 群 |
response_types |
使用宣言している応答タイプ群 |
grant_types |
使用宣言している認可タイプ群 |
application_type |
アプリケーションタイプ。 |
contacts |
コンタクト先のメールアドレス群 |
client_name |
クライアントアプリ名 |
logo_uri |
ロゴ画像の URL |
client_uri |
ホームページの URL |
policy_uri |
プロフィールデータ利用方針の URL |
tos_uri |
利用規約の URL |
jwks_uri |
JWK Set ドキュメントの URL |
jwks |
JWK Set ドキュメントの内容 |
sector_identifier_uri |
セクター識別情報への URL |
subject_type |
要求するサブジェクトタイプ |
id_token_signed_response_alg |
ID トークンの署名アルゴリズム |
id_token_encrypted_response_alg |
ID トークンのキー暗号アルゴリズム |
id_token_encrypted_response_enc |
ID トークンの本文暗号アルゴリズム |
userinfo_signed_response_alg |
ユーザー情報の署名アルゴリズム |
userinfo_encrypted_response_alg |
ユーザー情報のキー暗号アルゴリズム |
userinfo_encrypted_response_enc |
ユーザー情報の本文暗号アルゴリズム |
request_object_signing_response_alg |
ユーザー情報の署名アルゴリズム |
request_object_encryption_alg |
ユーザー情報のキー暗号アルゴリズム |
request_object_encryption_enc |
ユーザー情報の本文暗号アルゴリズム |
token_endpoint_auth_method |
トークンエンドポイントでのクライアント認証方式 |
token_endpoint_auth_signing_alg |
トークンエンドポイントでのクライアント認証用 JWT の署名アルゴリズム |
default_max_age |
最大認証有効期間 |
require_auth_time |
認証時刻情報要求 |
default_acr_values |
認証コンテキストのデフォルト値群 |
initiate_login_uri |
ログイン開始エンドポイントの URI |
request_uris |
事前登録された request_uri パラメータの値群 |
そういうわけで、これらの情報を格納するテーブルを用意することになります。なお、幾つかの項目 (client_name, tos_uri, policy_uri, logo_uri, client_uri など) は多言語対応をしてもよいことになっているので (2.1. Metadata Languages and Scripts)、対応するのであれば、それを考慮したテーブル設計が必要です。
以下、クライアントアプリケーションの属性情報について幾つか私見を述べます。
クライアントタイプ
OpenID Connect Dynamic Client Registration 1.0 の 2. Client Metadata に「クライアントタイプ」が含まれていないのは、仕様策定ミスだと思っています。RFC 6749 の 2.1. Client Types にはクライアントタイプとしてconfidential と public の二つが示されていますが、実装上、クライアントアプリケーションのクライアントタイプがどちらなのかという情報は、必ず必要になるからです。それに、RFC 6749 の 2. Client Registration の第二段落に次のように書いてあるからです (登録する属性の例としてクライアントタイプが挙げられている)。
...registration can rely on other means for establishing trust and obtaining the required client properties (e.g., redirection URI, client type).
仕様策定ミスでないとしたら、Dynamic Client Registration で登録されるクライアントアプリケーションは必ずどちらかのクライアントタイプになるという暗黙の合意があるのでしょう。しかし私は、関連仕様からその合意を読み解くことはできませんでした。
いずれにしても、クライアントアプリケーション用のテーブルを定義するときは、クライアントタイプの情報を格納するカラムが必要です。
アプリケーションタイプ
仕様によれば、application_type はオプショナルの属性です。省略されたときのデフォルト値は web です。定義済みの値は native と web です。
これだけ読めば、必然的にクライアントアプリケーションのアプリケーションタイプは native か web のどちらかになります。そのため、application_type の値を格納するカラムに NOT NULL をつけたくなりますが、Authlete の実装ではあえて NOT NULL を付けず、NULL を許容しています。
というのは、OpenID Connect Dynamic Client Registration 1.0 の仕様は application_type の値によってリダイレクト URI に次のような制限をかけているのですが、
Web Clients using the OAuth Implicit Grant Type MUST only register URLs using the https scheme as redirect_uris; they MUST NOT use localhost as the hostname. Native Clients MUST only register redirect_uris using custom URI schemes or URLs using the http: scheme with localhost as the hostname.
全ての OAuth 2.0 クライアントがこの制限に従うべきだという考えに同意できないからです。
昔、クライアントタイプとアプリケーションタイプについて Stack Overflow に「Does Application Type (OpenID Connect) correspond to Client Type (OAuth 2.0)?」という質問を投げました。しかし、誰も回答してくれなかったので、自分で調べて自己回答したという経緯があります。興味があればそちらも読んでみてください。
クライアントシークレット
クライアントシークレットの長さはどれくらいにすればよいでしょうか?
例えば、ForgeRock 社の Open AM というオープンソース製品の OpenAM Administration Guide では、クライアントアプリケーション登録時に設定するクライアントシークレットの値として、password という文字列を例として挙げています。以下は彼等のドキュメントの 12.4.1. Configuring OpenAM as Authorization Server & Client からのスクリーンショットです。

これをみる限り、OpenAM では短い文字列でもクライアントシークレットとして設定可能なようです。
一方 Authlete の実装では、クライアントシークレットは自動生成され、しかも次のようなとても長い文字列になります。
GBAyfVL7YWtP6gudLIjbRZV_N0dW4f3xETiIxqtokEAZ6FAsBtgyIq0MpU1uQ7J08xOTO2zwP0OuO3pMVAUTid
なぜここまで長くしているのかというと、対称鍵系の署名・暗号アルゴリズムとして 512 ビットまでサポートしたかったからです。例えば JWS の署名アルゴリズムとして HS512 までサポートしたかったからです。HS512 をサポートするには、クライアントシークレットが 512 ビット以上のエントロピーを持っていなければならないので、結果、上記のように 86 文字のクライアントシークレットとなりました (512 bits のデータを base64url エンコードすると 86 文字)。
対称鍵のエントロピーについては、OpenID Connect Core 1.0 の 16.19 Symmetric Key Entropy に次のように書かれています。
In Section 10.1 and Section 10.2, keys are derived from the client_secret value. Thus, when used with symmetric signing or encryption operations, client_secret values MUST contain sufficient entropy to generate cryptographically strong keys. Also, client_secret values MUST also contain at least the minimum of number of octets required for MAC keys for the particular algorithm used. So for instance, for HS256, the client_secret value MUST contain at least 32 octets (and almost certainly SHOULD contain more, since client_secret values are likely to use a restricted alphabet).
そして、RFC 7518 - JSON Web Algorithms の 3.1. "alg" (Algorithm) Header Parameter Values for JWS で、JWS の署名アルゴリズムとして HS256 (HMAC using SHA-256) のサポートは Required とされています。この結果、OpenID Connect 準拠を謳う実装であれば、必然的にクライアントシークレットは 256 ビット以上のエントロピーが必要となります。
署名アルゴリズム
OpenID Connect Dynamic Client Registration 1.0 の 2. Client Metadta に挙げられている id_token_signed_response_alg は、クライアントアプリケーションが認可サーバーに対して要求する、ID トークンの署名アルゴリズムです。有効な値は前述の通り RFC 7518 に列挙されていますが、none を指定することは許されていません。また、クライアントアプリケーション登録時に値が省略されたときは、アルゴリズムとして RS256 が使われることになっています。
userinfo_signed_response_alg もクライアントアプリケーションが認可サーバーに対して要求する署名アルゴリズムですが、こちらは、ユーザー情報エンドポイント (OpenID Connect Core 1.0, 5.3. UserInfo Endpoint) から返される情報に署名をおこなう場合に使われるアルゴリズムです。こちらは none でもよく、その場合は Unsecured JWS (署名がない JWS) が返されます。加えて、userinfo_signed_response_alg を指定しないという選択肢もありで、その場合は素の JSON が返されます。
上記を踏まえると、id_token_signed_response_alg の値を格納するカラムは NOT NULL 属性をつけてもいいですが、userinfo_signed_response_alg のほうは、「指定されていない」ということを表現可能とするため、NOT NULL 属性を付けずに NULL を許容したほうがよいでしょう。もちろん、「指定されていない」を表す特別な値を定義して NULL のかわりにその値を格納すれば、NOT NULL 属性をつけることはできます。そこらへんは実装者の判断によります。
幾つかある JWT ライブラリ のうち、私は Nimbus JOSE+JWT を選択しました。しかし、使っているうちに、アルゴリズム none で署名できないことに気が付きました。これだと userinfo_signed_response_alg=none をサポートできません。そのため、none でも署名できるようにするための Pull Request を送りました。しかし、リジェクトされました。何故かと言うと、none で署名できないようになっているのは、彼等のポリシーであえてそうしているからです。彼等の考えは、alg=none での署名・検証を可能にしてしまうと、「他のアルゴリズムで署名することと同様の安全性を持つと開発者が勘違いしてしまうという重大なセキュリティー上のリスクがある」というものです。そして、「NoneSigner や NoneVerifier を作るのではなく、alg=none を特別なケースとして扱うことをお勧めします。これは、まさに実際に我々が Connect2id サーバーでやったことです。」というアドバイスをもらいました。
・・・全くもって余計なお世話だ・・・
意見の分かれるところでしょうが、開発者の未熟さを機能制限でカバーするのは筋が良くないと私は思います。現実問題として、RFC 7515 に例として載っている Unsecured JWS を Nimbus JOSE+JWT ライブラリでは生成できないのです。おかげで、手作業で Unsecured JWS を作成しなければならなくなりました。 (とはいえ、RFC 7518 に挙がっているアルゴリズムを全てサポートしていることもあり、Nimbus JOSE+JWT は良いライブラリだと思います。)
少し脱線しますが、私が GitHub で公開している nv-websocket-client (日本語情報) という Java 用 WebSocket クライアントライブラリに、とある Issue が報告されました。「間違えて setSSLContext() メソッドと setSSLSocketFactory() メソッドの両方を呼んでしまったため、意図した動作にならなかった。両方を呼んでしまったときにそのミスに気付けるよう、ライブラリに手を入れたらどうだろうか」という改善提案でした。私の返事は、「両方呼んだときにどちらの設定が優先されるかは JavaDoc にしっかり書いてある。また、そのような『余計なお世話』チェックをいれたら、WebSocketFactory クラスの使い勝手が悪くなる。」というものでした。すると、「両方のメソッドを呼ぶ前にドキュメントを読まなかったのは自分が悪かった。でも、同じ間違いを犯す前に、どれほどの数の開発者がドキュメントを詳細に読むと思う? ![]() 」という返事が来ました。
」という返事が来ました。
もうね、ドキュメントを読まずに不具合を出して時間を無駄にしている奴は、ただの自業自得なので、救う価値など無いのですよ。
また、救おうとしてもキリが無いのです。こういうタイプのエンジニアは、たとえ alg=none での署名・検証ができないようにライブラリで防いだとしても、予想の斜め上をいって、JWK Set エンドポイントから公開する認可サーバーの JWK Set に秘密鍵を含めたりします。だってそうですよね。ドキュメントを読まない人が、(Nimbus JOSE+JWT に含まれる) JWKSet クラスの toPublicJWKSet() メソッドの存在とその意味に気がつけますかね? おそらく、「JWKSet インスタンスが作れた。わーい、公開っ!JWK Set エンドポイントの実装終了っ!」、となりますよね。
RFC 等の一次ソースを参照しないエンジニアは、見つけた答えに誤りがあっても気付けずに信じてしまいます。しかし、真のエンジニアになりたければ、RFC を読むことを避けてはいけません。 技術ブログや Stack Overflow の答えをあさっているだけでは決して正しい場所には辿りつけないのです。
To become a true engineer, don't avoid reading RFCs. Only searching technical blogs and StackOverflow for answers will never bring you to the right place.
クライアントアプリケーション開発者
オープンソースの認可サーバーの実装によっては、クライアントアプリケーションを動的に登録するため、HTML フォームを提供したり (ForgeRock 社 の Open AM)、Web API を提供したり (MITRE 社の MITREid Connect) するものがあります。ただ、その場合でも、登録作業ができるのは認可サーバーの管理者に限られます。しかしながら、あるべき姿は、Twitter のアプリ管理コンソール同等のものを作り、そこに開発者をログインさせ、個々の開発者がそれぞれのクライアントアプリケーションを登録管理できる環境を提供することでしょう。これを実現するには、少なくとも開発者の識別子を保持するカラムを、クライアントアプリケーションを表すテーブルに追加しておく必要があります。
認可サーバーを実装するだけでも面倒なので、往々にして忘れられてしまいますが、OAuth を実装して Web API を公開するためには、クライアントアプリケーションを管理するための仕組みも用意しなければなりません。Web API の公開先が、自社及び協力会社に対してのみという、非常に閉じた世界であれば、クライアントアプリケーションの登録作業を毎回認可サーバーの管理者がやってもよいですが (その都度 SQL を手打ちしている会社も実在します)、不特定多数に Web API を公開したければ、それなりのクライアントアプリケーション管理コンソールを実装しなければなりません。認可サーバー開発と Web API 開発の予算は確保したものの、クライアントアプリケーション管理コンソール開発の予算を確保し忘れてしまうと、「Web API を実装したが不特定多数に公開できない」、という状態になるので注意してください。
なお、Authlete は上記のようなユースケースに対応するため、デベロッパーコンソール を提供しています。Authlete 自体は開発者アカウントを管理しないものの、開発者認証コールバックという仕組みを通じて、Authlete 利用者の管理下にある開発者アカウントでデベロッパーコンソールを利用できるようになっています。そのため、Authlete を利用するとクライアントアプリケーション管理コンソールを実装する必要がなくなります。
アクセストークン
クライアントアプリケーションに渡すアクセストークンをどのように表現するか。これには大きく分けて二つの方法が考えられます。
- 無意味な文字列とし、アクセストークンに紐づく情報自体は認可サーバー内に保持する。
- アクセストークンに紐づく情報を base64url などでエンコードしてアクセストークンとする。
この二つの方法のどちらを選ぶかで、次のような違いが出てきます。
| 「無意味な文字列」方式 | 「情報エンコーディング」方式 | |
|---|---|---|
| アクセストークンの文字列長 | 固定長 | 変動する。スコープ数が多いなどの理由でアクセストークンに紐づく情報量が増えれば、それに従って長くなる。 |
| アクセストークンの情報の保存場所 | 認可サーバーのデータベース内 | クライアントアプリケーション内 |
| アクセストークンの情報の抽出方法 | 認可サーバーに逐一問い合わせる。 | その場でデコードすればよい。 |
| アクセストークン取り消し処理 | 認可サーバー内から当該アクセストークンを消す。 | 認可サーバーに「取り消した」という情報を追加する。 |
| 取り消されたかどうかの確認方法 | 認可サーバーに逐一問い合わせるが、これは情報抽出の時点で分かる。 | 認可サーバーに問い合わせる。 |
| 発行したアクセストークンの一覧取得 | 可能 | 不可 |
無意味な文字列方式では、アクセストークンに紐づく情報を調べるために、逐一認可サーバーに問い合わせにいかなければなりません。一方、情報エンコーディング方式では、その場でデコードすればよいため、認可サーバーに問い合わせに行く必要がありません。これだけみると、情報エンコーディング方式のほうが有利に見えますが、アクセストークンが取り消されたかどうかは認可サーバーに尋ねないと分からないので、結局、情報エンコーディング方式を採用したとしても、クライアントアプリケーションからアクセストークンの提示を受けるたびに逐一認可サーバーと通信することに変わりはありません。
情報エンコーディング方式が厄介なのは、アクセストークンの取り消し処理をするたびに、認可サーバーに「取り消した」というレコードを増やしていかなければならない点です。そしてこのレコードは、取り消したアクセストークンの有効期限が切れるまではずっと保持しておかなければなりません。なぜなら、レコードを消してしまうと、一度は無効になったはずのアクセストークンが (元々の有効期限が切れてなければ) 再度有効になってしまうからです。一方、無意味な文字列方式の場合は、アクセストークンを取り消す際はアクセストークンそのもののレコードを削除することになるので、当該アクセストークンが何かの拍子で復活することはありません。また、情報エンコーディング方式のような、「取り消したらレコードが増える」という後ろ向きなことは発生しません。
なお、情報エンコーディング方式のアクセストークンを取り消し可能とするには、情報エンコーディング方式だとしても、アクセストークンに一意識別子を付与しなければなりません。そうしなければ、「取り消した」という情報を記録する際に、どのアクセストークンを取り消したのかが分からないからです。逆に言うと、情報エンコーディング方式を採用しているのに一意識別子を付与しない認可サーバーは、アクセストークンの取り消しができない認可サーバーです。それも割り切り方の一つですが、こういう認可サーバーでは、アクセストークンの有効期限を短くしないとダメです。また、リフレッシュトークンを発行すべきではないでしょう。
「アクセストークンを取り消せない認可サーバーなんて・・・」と思うかもしれませんが、実際にそういう認可サーバーが実在するようです。 某大手 SI 企業が、買収した企業のプロダクトを使って、某社のために認可サーバーを実装しているものの、「アクセストークンを取り消せない」という事実が発覚した、という話を最近教えてもらいました。 おそらくその認可サーバーは、情報エンコーディング方式のアクセストークンを発行しているものの、アクセストークンに一意識別子を付与していないのでしょう。
「情報抽出のためにいちいち認可サーバーに問い合わせなくて良い」、「認可サーバー側にアクセストークンのレコードを持つ必要がない」という特長があるので、情報エンコーディング方式は一見良さそうに思えるのですが、取り消しのことを考えると、あまり良い方式とは言えません。
アクセストークンの削除
データベース内のデータ量が無限に増え続けることを避けるため、有効期限をむかえたアクセストークンをデータベースから削除する処理を定期的に実行する必要があります。
厄介なのは、無駄にアクセストークンの発行を要求してくるクライアントアプリケーションです。まだ有効期間内のアクセストークンを持っているのに、それを捨て、新しいアクセストークンの発行を要求する、という動作を繰り返すクライアントアプリケーションです。これをやられると、使われていないが有効期間内であるため消すに消せないアクセストークンがデータベース内にたまっていってしまいます。
この状況をなんとかしたい場合は、有効期間終了時刻に加えて、最後にアクセストークンが使用された時刻もデータベースに記録しておき、未使用期間が長いアクセストークンを削除する処理を定期的に実行すればよいです。もちろん、使用されていないからといって有効期間内のアクセストークンを削除してもよいかどうかは、それぞれのサービスの性質によって判断が分かれます。
以前、「某国内大手企業に勤めていたときに OAuth 実装プロジェクトに携わっていた」というエンジニアの方にお会いしたことがありました。その方は、「でもあのシステムはアクセストークンの消し込みのことをちゃんと考えていないので、おそらく今頃はデータベース内のアクセストークンの数が数億個になっていると思います」、とおっしゃっていました。怖い、怖い。何かを生成するときは、それをどの契機で消すのかも同時に検討しましょう。
リダイレクト URI
2014 年 5 月初め、シンガポールの大学院生が公開したサイトを発端として、「OAuth 2.0 に脆弱性?」と話題になりました。いわゆる Covert Redirect の話です。しかし、OAuth 2.0 をちゃんと理解していた人は、「それは仕様の脆弱性ではなくて、Facebook の実装が腐っているだけのこと」、とすぐに分かりました。しかし、あまりに「OAuth 2.0 に脆弱性?」が話題になってしまったため、誤解を解くために OAuth 界隈の人々が解説記事を書かざるをえなくなりました。
リダイレクト URI を正しく扱わないと、セキュリティー上問題が起こります。どのように扱うべきかは仕様に書かれていますが、RFC 6749 と OpenID Connect で要求事項が異なることや、クライアントアプリケーションの application_type の値にも影響を受けたりするなど、考慮しなければならないことが多いので、正確に実装するのは難しいです。
実装がどこまで正しく行われるかは、認可サーバーの実装者がどれだけ関連仕様を読み込んでいるかに左右されます。ですので、その部分の実装をみると、認可サーバー全体のコード品質もある程度推測できるというものです。そういうわけで、みなさん、頑張って実装してください!
・・・と突き放してしまっては、ここまで読んで下さった方に申し訳ないので、Authlete の実装ノウハウをご紹介します(本邦初)。下記は、認可リクエストに含まれる redirect_uri パラメーターを処理する仮想コードです。なお、一覧性をよくするためにあえてメソッド分割せずに書いていますが、Authlete の実際のコードは細かくメソッド分割しており、それに伴って、また効率上の理由により、実際の処理フローは下記のものとは異なります。 (実コードでこんなに if や for がネストするコードを書いたら恥です。)
// 認可リクエストに含まれる redirect_uri パラメーターの値を取り出す。
redirectUri = ...
// 「明示的にリダイレクト URI が指定された」ことを覚えておく。というのは、
// 「認可リクエスト時に明示的にリダイレクト URI を指定した場合、対応するトークン
// リクエストにも明示的に同じリダイレクト URI を指定しなければならない」という
// 要求仕様があるため。あとでそのチェックをトークンエンドポイントでおこなう。
explicit = (redirectUri != null);
// 登録済みのリダイレクト URI のリストをデータベースから取り出す。
registeredRedirectUris = ...
// RFC 6749 (OAuth 2.0) と OpenID Connect 1.0 の要求事項は異なるので、
// まず、リクエストが OpenID Connect リクエストかどうかに基づいて分岐する。
// これは、scope リクエストパラメーターに openid が含まれているかどうかで判断する。
if ( "scope に openid が含まれている" )
{
// OpenID Connect の要求事項に基づいてチェックする。
// リクエストに redirect_uri パラメーターが含まれていない場合
if ( redirectUri == null )
{
// RFC 6749 とは異なり、OpenID Connect では redirect_uri は必須。
throw new 例外( "redirect_uri が指定されていない。" );
}
// 登録済みのリダイレクト URI を順次チェックしていく。
for ( registeredRedirectUri : registeredRedirectUris )
{
// 仕様に従い、Simple String Comparison で比較する。
if ( registeredRedirectUri.equals(redirectUri) )
{
// OK。リクエストで指定されたリダイレクト URI は登録されている。
registered = true;
break;
}
}
// 登録済みのリダイレクト URI のいずれにもマッチしなかった場合
if ( registered == false )
{
throw new 例外( "指定されたリダイレクト URI は登録されていない。" );
}
}
else
{
// RFC 6749 の要求事項に基づいてチェックする。
// リダイレクト URI が一つも登録されていない場合
if ( registeredRedirectUris.size() == 0 )
{
// RFC 6749, 3.1.2.2. Registration Requirements には、次の
// クライアントアプリケーションはリダイレクト URI を登録しなければ
// ならないと書いてある。
//
// * Public クライアント
// * インプリシットフローを使用する confidential クライアント
// リクエストを投げてきたのが Public クライアントの場合
if ( client.getClientType() == PUBLIC )
{
throw new 例外( "リダイレクト URI が登録されていない。" );
}
// Confidential クライアントで、インプリシットフローの場合。 response_type に
// token もしくは id_token が含まれていればインプリシットフロー。
else if ( responseType.requiresImplicitFlow() )
{
throw new 例外( "リダイレクト URI が登録されていない。" );
}
}
// リクエストに redirect_uri が含まれていない場合
if ( redirectUri == null )
{
// リダイレクト URI が一つも登録されていないか、もしくは複数登録されている場合
if ( registeredRedirectUris.size() != 1 )
{
// redirect_uri パラメーターで明示的にリダイレクト URI を指定する必要がある。
throw new 例外( "redirect_uri が指定されていない。" );
}
// 一つだけ登録されているリダイレクト URI をデフォルト値として使う。
redirectUri = registeredRedirectUris[0];
}
// リクエストに redirect_uri が含まれているが、リダイレクト URI が一つも登録されていない。
else if ( registeredRedirectUris.size() == 0 )
{
// Confidential クライアントで、インプリシットフローではない場合のみここにくる。
// リクエストで指定された未登録のリダイレクト URI を使う。 ただし RFC 6749,
// 3.1.2. Redirection Endpoint の要求事項はチェックする。
// 指定されたリダイレクト URI が絶対 URI ではない場合
if ( redirectUri.isAbsolute() == false )
{
throw new 例外( "redirect_uri で指定された URI が絶対 URI ではない。" );
}
// 指定されたリダイレクト URI がフラグメント部を含む場合
if ( redirectUri.getFragment() != null )
{
throw new 例外( "redirect_uri で指定された URI がフラグメント部を含む。" );
}
}
else
{
// 指定されたリダイレクト URI が絶対 URI ではない場合
if ( redirectUri.isAbsolute() == false )
{
throw new 例外( "redirect_uri で指定された URI が絶対 URI ではない。" );
}
// 指定されたリダイレクト URI がフラグメント部を含む場合
if ( redirectUri.getFragment() != null )
{
throw new 例外( "redirect_uri で指定された URI がフラグメント部を含む。" );
}
// 登録済みのリダイレクト URI を順次チェックしていく。
for ( registeredRedirectUri : registeredRedirectUris )
{
// 登録されている URI が full URI の場合
if ( registeredRedirectUri.getQuery() != null )
{
// Simple String Comparison で比較する。
if ( registeredRedirectUri.equals( redirectUri ) )
{
// 指定されたリダイレクト URI は登録されている。
registered = true;
break;
}
// この登録済み URI とはマッチしない。
continue;
}
// スキーム部を比較する。
if ( registeredRedirectUri.getScheme().equals( redirectUri.getScheme() ) == false )
{
// この登録済み URI とはマッチしない。
continue;
}
// ユーザー情報部を比較する。 仮想コードとはいえ処理が長くなり過ぎるので、文字列比較のために
// equalsSafely() という架空のメソッドを利用。 equalsSafely() は、引数が null の場合でも
// 例外を投げずに文字列比較をおこなう。
if ( equalsSafely( registeredRedirectUri.getUserInfo(), redirectUri.getUserInfo() ) == false )
{
// この登録済み URI とはマッチしない。
continue;
}
// ホスト部を比較する。大文字小文字の違いは無視する。
if ( registeredRedirectUri.getHost().equalsIgnoreCase( redirectUri.getHost() ) == false )
{
// この登録済み URI とはマッチしない。
continue;
}
// ポート部を比較する。 仮想コードとはいえ処理が長くなり過ぎるので、ポート番号抽出のために
// getPortOrDefaultPort() という架空のメソッドを利用。 getPortOrDefaultPort() は
// getPort() が -1 を返したときにスキーム部からデフォルトポート番号を推定する。 最終手段は
// URI.toURL().getDefaultPort()。 URI.toURL().getDefaultPort() が例外を投げたら -1。
if ( getPortOrDefaultPort( registeredRedirectUri ) != getPortOrDefaultPort( redirectUri ) )
{
// この登録済み URI とはマッチしない。
continue;
}
// パス部を比較する。 仮想コードとはいえ処理が長くなり過ぎるので、文字列比較のために
// equalsSafely() という架空のメソッドを利用。 equalsSafely() は、引数が null の
// 場合でも例外を投げずに文字列比較をおこなう。
if ( equalsSafely( registeredRedirectUri.getPath(), redirectUri.getPath() ) == false )
{
// この登録済み URI とはマッチしない。
continue;
}
// 指定されたリダイレクト URI は登録されている。
registered = true;
break;
}
// 登録済みのリダイレクト URI のいずれにもマッチしなかった場合
if ( registered == false )
{
throw new 例外( "指定されたリダイレクト URI は登録されていない。" );
}
}
}
// 以下、クライアントアプリケーションの application_type に基づいてチェックする。
// application_type が 'web' の場合
if ( client.getApplicationType() == WEB )
{
// インプリシットフローの場合。 response_type に token もしくは id_token が
// 含まれていればインプリシットフロー。
if ( responseType.requiresImplicitFlow() )
{
// リダイレクト URI のスキームが "https" ではない場合
if ( "https".equals( redirectUri.getScheme() ) == false )
{
// application_type が web のクライアントがインプリシットフローを
// 使うときは、リダイレクト URI のスキームは https である必要がある。
throw new 例外( "リダイレクト URI のスキームが https ではない。" );
}
// リダイレクト URI のホストが "localhost" の場合
if ( "localhost".equals( redirectUri.getHost() ) )
{
// application_type が web のクライアントがインプリシットフローを
// 使うときは、リダイレクト URI のホストは localhost であってはならない。
throw new 例外( "リダイレクト URI のホストが localhost である。" );
}
}
}
// application_type が 'native' の場合
else if ( client.getApplicationType() == NATIVE )
{
// リダイレクト URI のスキームが "https" の場合
if ( "https".equals( redirectUri.getScheme() ) )
{
// application_type が native のクライアントが使うリダイレクト URI の
// スキームは、https であってはならない。
throw new 例外( "リダイレクト URI のスキームが https である。" );
}
// リダイレクト URI のスキームが "http" の場合
if ( "http".equals( redirectUri.getScheme() ) )
{
// リダイレクト URI のホストが "localhost" ではない場合
if ( "localhost".equals( redirectUri.getHost() ) == false )
{
// application_type が native のクライアントが使うリダイレクト URI の
// スキームが http の場合、そのホスト部は localhost でなければならない。
throw new 例外( "リダイレクト URI のホストが localhost ではない。" );
}
}
}
// application_type がそれ以外の場合
else
{
// 先に述べたとおり、Authlete では、クライアントアプリケーションの
// application_type の値として「指定しない」を許容している。
}
他の実装はどうなっているか
OpenID Connect では redirect_uri パラメーターが必須になっており、指定されたリダイレクト URI が登録されているかどうかのチェックも Simple String Comparison でいいと書いてあるので、OpenID Connect だけを考えるとシンプルに実装できます。例えば、2016 年 2 月時点で約 1,300 のスターが付いており、OpenID Certification プログラムでの認証も受けている IdentityServer3 では、リダイレクト URI のチェックは次のようになっています (DefaultRedirectUriValidator.cs より抜粋)。
public virtual Task<bool> IsRedirectUriValidAsync(string requestedUri, Client client)
{
return Task.FromResult(StringCollectionContainsString(client.RedirectUris, requestedUri));
}
しかし、OpenID Connect だけを対象としているということは、逆に言うと、従来の (= scope パラメーターに openid を含まない) 認可コードフローやインプリシットフローを受け付けない認可サーバーということになります。つまりは既存の OAuth 2.0 クライアントアプリケーションからのリクエストには全く対応できない認可サーバーということです。
では、IdentityServer3 は従来の形式の認可リクエストを拒否するのか否か? そこで、AuthorizeRequestValidator.cs を覗いてみると、該当箇所は次のようになっています。
if (request.RequestedScopes.Contains(Constants.StandardScopes.OpenId))
{
request.IsOpenIdRequest = true;
}
//////////////////////////////////////////////////////////
// check scope vs response_type plausability
//////////////////////////////////////////////////////////
var requirement = Constants.ResponseTypeToScopeRequirement[request.ResponseType];
if (requirement == Constants.ScopeRequirement.Identity ||
requirement == Constants.ScopeRequirement.IdentityOnly)
{
if (request.IsOpenIdRequest == false)
{
LogError("response_type requires the openid scope", request);
return Invalid(request, ErrorTypes.Client);
}
}
ポイントは、「scope パラメーターに openid を含まなくても大丈夫なパスがある」ということで、つまりは従来の認可リクエストを受け付けるということです。 であるならば、IdentityServer3 のリダイレクト URI チェック方法は不適切、ということになります。が、一方で、AuthorizeRequestValidator.cs 内の別の箇所では、次のように redirect_uri パラメーターを含まない認可リクエストを全部拒否しているので、
//////////////////////////////////////////////////////////
// redirect_uri must be present, and a valid uri
//////////////////////////////////////////////////////////
var redirectUri = request.Raw.Get(Constants.AuthorizeRequest.RedirectUri);
if (redirectUri.IsMissingOrTooLong(_options.InputLengthRestrictions.RedirectUri))
{
LogError("redirect_uri is missing or too long", request);
return Invalid(request);
}
「redirect_uri パラメーターが省略された場合の処理」を書かなくていいわけです。ただ、RFC 6749 では redirect_uri パラメーターはオプショナルなので、「従来の形式の認可リクエストを受け付けておきながら、redirect_uri が指定されていない場合は無条件にエラー」というこの動作は、仕様違反なのです。ついでに言っておくと、IdentityServer3 のリダイレクト URI チェックには、クライアントアプリケーションの application_type 属性に基づくチェックが入っていません。そもそも、クライアントアプリケーションを表すモデルクラスである Client に、application_type 属性を表すプロパティーが存在しないのです (Client.cs)。
実装によるこのような微妙な仕様違反のことを、「方言」と呼ぶことがあります。方言というと、なんとなく許容される雰囲気がありますが、私に言わせると仕様違反は仕様違反。方言を許容するから、本来は OAuth 2.0 / OpenID Connect クライアントライブラリは言語毎に汎用のものが一つあれば十分なはずなのに、対象とする認可サーバーごとにクライアントライブラリを用意しなければならなくなるのです。
Facebook の OAuth 処理が Facebook 専用クライアントライブラリでないと動かないのは、Facebook の OAuth 実装が仕様違反しまくっているからです。 (1) scope パラメーターに列挙するスコープ名群の区切文字がスペースではなくカンマだとか、(2) トークンエンドポイントからの応答が JSON ではなく application/x-www-form-urlencoded だとか、(3) アクセストークンの有効期間秒数を表すパラメーターの名前が expires_in ではなく expires だとか。 Salesforce の OAuth 実装にも、トークンエンドポイントからの応答に必須パラメーター ※2token_type が含まれないという仕様違反があり、「そのせいで OAuth クライアントライブラリが例外を投げる」という報告があがっています (OAuth Access Token Response Missing token_type)。なお、この報告スレッドの末尾は「to bad sf doesn't comply to the standard when it claims so. (原文ママ)」 (Salesforce は標準準拠を謳っておきながら準拠していないというのはヒド過ぎる) というメッセージで終わっています。
[2016/05/12] 「OAuth & OpenID Connect の不適切実装まとめ」という記事を投稿しました。
[2016/05/15] ※2 本不具合は修正済みとの情報をいただきました。ありがとうございました。
自力実装するのであれば、それなりの心構えで
二ヶ月ほどコンサルティングをした後に、「やっぱり自社内で実装するから Authlete を使わない」と言われて、ほぼ決まったと思っていた案件を失注した経験があります。 まぁ、それがキッカケとなり、日本を出てシリコンバレーにいくことになって現地の客を得ることができたので、結果オーライなのですが、OAuth / OpenID Connect の実装を安易に考えるのはいかがなものか、と思うわけです。
紹介したように、Facebook や Salesforce などの資金が潤沢な大手企業でも実装をミスすることがあります。Apache プロジェクトの名を関した Apache Oltu や、有名な Spring Security ですら、それぞれ問題を抱えています。ですので、OAuth / OpenID Connect を自力実装するのであれば、安易に考えることなく、それなりの開発体制を敷いたほうがよいです。「お前ら、一ヶ月で実装しろ」などと言って現場に無理をさせると、なんとなく動くものは出来上がるかもしれませんが、Facebook の実装のようにセキュリティー上の問題を抱え込む恐れが高まります。
RFC 6749 だけであればそんなに苦労はしませんが、OpenID Connect をフルスクラッチ実装するのは正気の沙汰ではないので、何らかの既存の実装をベースにして開発するのがよいでしょう。 OpenID Connect のサイトの Libraries, Products, and Tools には OAuth 2.0 / OpenID Connect 関連のライブラリ・製品・ツール群がリストアップされているので、まずはそこを探してみてください。 (ちなみに Authlete はリストされていません。)
なお、RFC 7636 (図解) などのように、重要な仕様が追加されることもよくあるので、**OAuth / OpenID Connect ワーキンググループ**のメーリングリストに参加し、自力実装完了後も OAuth の最新状況をウォッチしておくことをお勧めします。
Resource Owner Password Credentials Grant について
[2016/02/24] ashiina 様よりご質問いただきましたので、Resource Owner Password Credentials Grant (以下パスワードフロー) について加筆します。
パスワードフローにおいて、username と password を用いてユーザーを特定する部分は「認証」にあたります。とはいえ、パスワードフロー全体が「認証の仕様」ということではなく、あくまで「認証の仕様まで含む、認可の仕様」となります。パスワードフローに関してだけは、他のフローと異なり、特別に認証方法にまで言及していますが、あくまで認可フローの一種となります。
RFC 6749 の 1.3.3. Resource Owner Password Credentials と 4.3. Resource Owner Password Credentials Grant にそれぞれ次のように書いており、
(1.3.3. Resource Owner Password Credentials より抜粋)
The credentials should only be used ... , and when other authorization grant types are not available (such as an authorization code).
(4.3. Resource Owner Password Credentials Grant より抜粋)
The authorization server should take special care when enabling this grant type and only allow it when other flows are not viable.
その意図が「パスワードフローの使用は、他の認可フローを使用できないときのみに限るべき」であることを考えると、パスワードフローは4つの認可フローの中では次善策という位置付けであると考えるのが自然と思います。また、パスワードフローの用途として次のような例が挙げられているところも見れば、
It is also used to migrate existing clients using direct authentication schemes such as HTTP Basic or Digest authentication to OAuth by converting the stored credentials to an access token.
(ベーシック認証やダイジェスト認証等の直接的な認証方法を用いている既存のクライアントを OAuth へと移行させるため)
パスワードフローが OAuth の本流ではないと推察できると思います。 ここまで言及しなくとも、パスワードフローでは、ID とパスワードをクライアントアプリケーションが受け取ることが前提となっているので、OAuth 本来の目的から外れています。
上記を踏まえると、次善策であるパスワードフローの一部に認証に関する仕様が含まれるからといって、それをことさらに大きく取り上げて、「OAuth は認可の仕様であり認証の仕様ではない」という表現をやめて「OAuth は認可の仕様であるが認証の仕様も含む」という表現にしてしまうと、それはそれで逆に語弊が大きいかと思います。
移行期のパスワードフロー
私個人的には、パスワードフローは、あくまで移行期のみに使われるものだと考えています。例えば、、、
現在、ほとんどの金融機関は OAuth に基づく Web API を提供していません。そのため、金融機関との連携を謳っているオンライン帳簿管理サービスは、「金融機関サイトにログインするための」ID とパスワードをユーザーから預かり、その ID とパスワードを使って金融機関のサイトにログインしてスクレイピングにより情報収集しています。これは企業秘密でも何でもなく、周知の事実で、経済産業省のウェブサイトにあがっている資料にも言及があります。しかし、この手法は様々な問題があるため、金融機関が OAuth ベースの Web API を提供することが強く求められています。また、その動きが今まさに起きているところです。この動きは、FinTech 最先端のイギリスでも「今まさにこれから」なのです (参考: The Open Banking Standard)。2016 年の FinTech は、金融機関 Web API に要注目です。
ここで、金融機関が Web API を提供するにあたり、移行期の対応として、認可コードフローだけではなくパスワードフローもサポートすれば、オンライン帳簿管理サービスを利用する既存のユーザーもスムーズに金融機関 Web API の恩恵を受けることができます。金融機関 Web API が充実してくれば、スクレイピングに頼らずとも全ての情報を Web API 経由で取得することが可能となり、やがては、オンライン帳簿管理サービス業者も、ユーザーから金融機関の ID とパスワードを預からなくてもよくなるでしょう。そういった世界が実現されたとき、パスワードフローは不要となり、移行期の役目を終えることになります。
さいごに
長い文章を読んでくださり、ありがとうございました!
[2016/02/27]
**「【第二弾】OAuth 2.0 + OpenID Connect のフルスクラッチ実装者が知見を語る」**を公開しましたので、そちらもお楽しみください。
[2016/06/01]
**「OAuth & OpenID Connect 関連仕様まとめ」**もお楽しみください。