はじめに
本記事は「OAuth 2.0 + OpenID Connect のフルスクラッチ実装者が知見を語る」の続編となります。保護リソースエンドポイント (protected resource endpoint)、いわゆる世の中でいうところの (狭義の) Web API の実装に関する話題がメインとなります。
1. もう一つの認可
1.1. アカウント属性文脈での認可
混乱を避けるため前記事では敢えて言及しませんでしたが、認可という言葉は別の文脈で使われることがあります。その文脈では、「誰が何の権限を持っているか (who has what permissions)」という情報を扱うために認可という言葉を使います。これは、OAuth の文脈での認可「誰が誰に何の権限を与えるか (who grants what permissions to whom)」とは異なります。厄介なことに、このどちらも認可と呼ばれ、英語でも両方とも authorization という単語が使われます。
あるウェブサイトにログインする際、一般ユーザーアカウントでログインするのか、それとも管理者アカウントでログインするのかの違いにより、ログイン後に実行可能な操作に変化を持たせることはよくありますが、この文脈で認可という言葉が出てきた場合、それは、「誰が何の権限を持っているか」という情報を扱っています。これは、OAuth の文脈でいうところの認可とは異なります。ですので、「一般ユーザーアカウントと管理者アカウントを区別したいのだけど、これを実現するには OAuth が必要なのか?」と尋ねられたら、その答えは「いいえ」ということになります。
OAuth でない方の文脈における認可については、「アカウントに、権限を表す属性が紐付いている」と考えると分かりやすいと思います。この文脈を「アカウント属性文脈」と表現するとすれば、アカウント属性文脈における認可と OAuth 文脈における認可は、次の表のように比較することができます。
| 文脈 | 認可が扱う情報 |
|---|---|
| アカウント属性 | 誰が何の権限を持っているか Who has what permissions. |
| OAuth | 誰が誰に何の権限を与えるか Who grants what permissions to whom. |
1.2. データベーステーブルでの表現
抽象的な文章が続いてしまいましたが、これをデータベーステーブルで表現すると違いがはっきり見えてきます。
アカウント属性文脈での認可は次のような表現となり、テーブルの意味は「アカウントテーブル」となります。
| 一意識別子 (user ID) |
名前 (name) |
持っている権限 (permissions) |
|---|---|---|
user001 |
John |
view |
user002 |
Jane |
view, edit
|
一方、OAuth 文脈での認可は次のような表現となり、テーブルの意味は「アクセストークンテーブル」となります。
| 一意識別子 (access token) |
誰が (user ID) |
誰に (client ID) |
何の権限を (scopes) |
|---|---|---|---|
fde0dke3d |
user001 |
client001 |
profile |
abbv3Dedg |
user002 |
client002 |
profile, post
|
1.3. Apache Shiro から学ぶ
ところで、Apache Shiro というプロジェクトをご存知でしょうか? 私は、ウェブサイトにおけるログインの仕組みを実現する手段を探していたときに、Apache Shiro を知りました。Java 系のソリューションとしては Spring Security が有名ですが、Stack Overflow の「Shiro vs. SpringSecurity」にある通り、Spring Security は複雑過ぎます。一方、Apache Shiro は設計が洗練されていて、簡単に使えるのです。
Apache Shiro は認証を扱いますが、それと併せて、認証されたユーザーの権限も取り扱うことができます。これは、先に述べた「アカウント属性文脈における認可」を指しており、Apache Shiro のドキュメントにおいても、この機能は authorization という単語で説明されています。
ここで Apache Shiro を持ち出したのは、そのドキュメントの一つである「Apache Shiro Authorization」が良く書けていて、考え方に汎用性があるからです。また、Apache Shiro プロジェクトの PMC (Project Management Committee) Chair である Les Hazlewood 氏が Stormpath 社のウェブサイトに載せている文書「The New RBAC: Resource-Based Access Control」もまた、よく書けていて非常に参考になるからです。
これらの文書からエッセンスを抜き出します。
1.3.1. 認可の構成要素
アカウント属性文脈での認可を構成する要素 (Elements of Authorization) には、パーミッション (permission)、ロール (role)、ユーザー (user)、の三つがあり、それぞれ次のような定義となります。
| 要素 | 説明 |
|---|---|
| パーミッション | どのリソースに対してどのアクションを実行できるか |
| ロール | パーミッションの集合 |
| ユーザー | パーミッションやロールの割当先 |
パーミッションは、セキュリティーポリシーの最小構成要素となります。ロールは単なる「パーミッションの集合」に過ぎず、パーミッショングループと同義です。個人的には「ロール=パーミッションの集合」という割り切り方にハッとさせられました。
パーミッションの例として、次のようなものを挙げることができます。
| リソース | アクション |
|---|---|
| ファイルを | オープンする |
| ページを | 閲覧する |
| ドキュメントを | 印刷する |
ユーザー jsmith を |
削除する |
上記表中の最後の例では、アクションの対象となるリソースをインスタンスレベルで限定しています。つまり、ユーザーの中でも、特に jsmith というインスタンスに限定したパーミッションとなっています。
これらのリソース指定の方法を汎用的にとらえ直すと、リソースは、(1) リソースタイプだけで指定される場合と、(2) リソースタイプ及びインスタンスの組で指定される場合の二つがあると言えると思います。このことから、パーミッションの構成パターンもまた、次の二つに集約できます。
- リソースタイプ、アクション
- リソースタイプ、アクション、インスタンス
1.3.2. パーミッションの表現
パーミッションをコードに近い形で表現してみることにします。
パーミッションの構成要素である、リソースタイプ、アクション、そしてオプショナルのインスタンス指定を、コロンで区切って並べる「リソースタイプ:アクション[:インスタンス]」という形式を基本としましょう。そして、それぞれのフィールド内で複数の要素が存在する場合はカンマ区切りで列挙します。また、「全て」を表現する方法として * を用いることにします。
下記の表は、このルールを用いて表現したパーミッションの例です。
| 表現 | 意味 |
|---|---|
printer:print |
プリンターで印刷する権限 |
printer:manage |
プリンターを管理する権限 |
printer:print,manage |
プリンターに対する印刷権限と管理権限 |
printer:* |
プリンターに関する全ての権限 |
*:view |
全てのリソースを閲覧する権限 |
printer:query:lp7200 |
プリンター LP7200 の状態を調べる権限 |
printer:print:epsoncolor |
プリンター Epson Color で印刷する権限 |
ここでは、「リソースタイプ:アクション[:インスタンス]」という形式を採用しましたが、もちろん、パーミッションを表現するときにこれ以外の方法を用いてもかまいません。表現方法はどのようなものだとしても、リソースタイプ、アクション、インスタンス、を指定できるのであれば、Apache Shiro と同じ概念でパーミッションを表現することができます。なお、ワイルドカード指定 (*) を含む「リソースタイプ:アクション:インスタンス」形式のパーミッションの実装として、Apache Shiro は WildCardPermission というクラスを提供しています。
1.3.3. アクセス制御時の注意点
パーミッションやロールの概念とその表現方法が定まれば、それらに基づいてアクセス制御をおこなえますが、それについて、先ほども紹介した「The New RBAC: Resource-Based Access Control」という文書に注意が書かれています。要約すると次のとおりです。
ロール名に基づくアクセス制御は、ソースコードの維持管理が難しくなる傾向にある。例えば、「ロールがプロジェクトマネージャーの場合は、プロジェクト一覧を表示する」というコーディングをしていた場合、後から「部門長もプロジェクト一覧を見られるように」という要求仕様が追加されると、ソースコード内の条件文を「ロールが、プロジェクトマネージャーもしくは部門⻑の場合」というように変更しなければならない。このようなコーディングはすぐに破綻する。このため、**アクセス制御はロール基準ではなくリソース基準でおこなうのがよい。**例えば、「プロジェクトを一覧表示する権限があるか」という具合のコードを書く。
少し長くなりましたが、Apache Shiro から、アカウント属性文脈における認可について多くを学べたことと思います。
1.3.4. 補足
私が Apache Shiro を知った当時、日本語情報が少なかったので (今も少ないですが)、幾つかドキュメントを日本語訳しておきました。参考にしてみてください。
余談ですが、Apache Shiro のドキュメントを読んでいるだけで、いかに Apache Shiro の実装者がセキュリティーに詳しいかが分かります。パスワード情報をデータベースに保存する際、パスワードそのものではなくハッシュ値を保存することは常識だとしても、ソルトに加え、ハッシュ値計算を相当回数繰り返すべきことの重要性については、私は Apache Shiro の HashedCredentialsMatcher クラスの JavaDoc から学びました。
さらに余談で、また、突然の告白ですが、私がなぜ Apache Shiro を評価する一方で Spring Framework を嫌うかというと、あのフレームワークは、プログラミングの複雑さを解消しているのではなく、プログラミングの複雑さを Java コードから XML 設定ファイルに移動させているだけだからです。むしろ、コンパイル時にエラー検出できていたものが、実行してみないとエラーに気付けない状態となり、悪化ですらあります。ライブラリやフレームワークを作るときは、複雑さを軽減するために他の複雑さを導入するという愚を犯していないか、自ら問うべきだと思います。
2. 保護リソースエンドポイント
2.1. 認可をめぐる混乱
前章で「誰が何の権限を持っているか」という意味での認可について説明し、それなりの文章量となりましたが、全てこの章のための前置きです。ここからは、OAuth に話を戻し、保護リソースエンドポイント (protected resource endpoint) について書いていこうと思います。
あるエンドポイントを、(1) アクセストークンで保護し、さらに (2) ユーザーが持つ権限に基づいて機能制限をおこないたいと思った時、(1) では OAuth 文脈の認可を、(2) ではアカウント属性文脈の認可を扱うことになります。両方とも認可 (authorization) という言葉を使うため、両者の認可の違いを理解していないと混乱してしまいます。
さらに、アクセストークンと ID トークンに対する無理解も掛け合わさると、「アクセストークンにはユーザーのクレーム (ユーザーの属性情報) が入っているから、そのクレームに基づいてアクセス制御ができるのではないか?」という、さらに深い混乱へと陥ってしまいます。
このような混乱を抱えている人は、保護リソースエンドポイントをどのように実装していいのか分からず、途方に暮れて Stack Overflow にやってきます。 そして、そのような人による一発目の質問がこちらの「OAuth 2.0 Authorization Server and Access Tokens」です。この質問者は真面目で、質問自体は丁寧に書いていますが、「The Authorization Server issues the access token containing the user's claims.」 (認可サーバーはユーザークレームを含むアクセストークンを発行する) という間違った理解を前提に質問してきているので、そこはさらっと「An access token does NOT contain a user's claims, but an ID token does.」 (アクセストークンはユーザークレームを含まないけど、ID トークンには含まれているよ。) と回答し、質問の前提条件を修正してあげます。すると、いよいよ、OAuth 文脈の認可とアカウント属性文脈の認可の混乱に起因する質問がやってきます。その質問がこちらの「How to verify which resources each user can access with OAuth and OpenID Connect?」です。
この質問に対しては、私も懇切丁寧に回答しましたが、要点は、保護リソースエンドポイントのコードの開始部分で次の処理をおこないましょう、ということです。
| 処理 | |
|---|---|
| 1 | リクエストからアクセストークンを取り出す。 (RFC 6750) |
| 2 | アクセストークンの詳細情報を認可サーバーに問い合わせる。 (RFC 7662) |
| 3 | アクセストークンが有効かどうかを調べる。 (a) 期限切れしていないか、(b) 当該保護リソースエンドポイントにアクセスするのに必要な権限 (scope) をカバーしているか、(c) 取り消されていないか、など。 |
| 4 | アクセストークンから、そのアクセストークンに紐づいたユーザー一意識別子を取り出す。 |
| 5 | データベースから、そのユーザーの属性情報を取り出す。 |
| 6 | ユーザーの属性情報に基づいて機能制限をかける。 |
上記リストのうち、1 ~ 3 までが、OAuth 文脈における認可の処理で、クライアントアプリケーションに対するアクセス制御となります。一方、4 ~ 6 までは、アカウント属性文脈における認可の処理で、ユーザーに対するアクセス制御となります。
2.2. アクセストークンの受け取り方
保護リソースエンドポイントは、クライアントアプリケーションから提示されるアクセストークンをどのように受け取るべきでしょうか? 方法については幾らでも考案することは可能ですが、車輪を再発明する必要はないでしょう。 既に RFC 6750 (The OAuth 2.0 Authorization Framework: Bearer Token Usage) に、アクセストークンを受け取る方法が三つ定義されています。
-
Authorizationヘッダー (2.1. Authorization Request Header Field) -
access_tokenフォームパラメーター (2.2. Form-Encoded Body Parameter) -
access_tokenクエリーパラメーター (2.3. URI Query Parameter)
これら三つのうちで最も望ましい方法は一番目のもので、RFC 6750 ではこの方法について "Resource servers MUST support this method." (リソースサーバーはこの方法をサポートしなければならない) と言っています。
Authorization ヘッダーによる方法を用いる場合、スキームは Bearer という約束ですので、
Authorization: Bearer {access-token}
という HTTP ヘッダーを含むリクエストが、クライアントアプリケーションから保護リソースエンドポイントに届くことになります。
2.2.1. {access-token} の値
上記の {access-token} の部分には認可サーバーから事前に発行を受けていたアクセストークンをそのままセットすればいいのですが、ここにはちょっとした罠があります。余談ではありますが、どういう罠かと言うと、まず、RFC 6750 では Authorization ヘッダーの値のフォーマットを次のように定めています。
b64token = 1*( ALPHA / DIGIT /
"-" / "." / "_" / "~" / "+" / "/" ) *"="
credentials = "Bearer" 1*SP b64token
つまり、アクセストークンの表現として使える文字を Base64 系の文字のみに限定しています。 b64token という表記を用いていることや、この前段でベーシック認証に言及していることもあり (ベーシック認証では Authorization ヘッダーの値を生成する際に Base64 エンコーディング処理が入ります。) 、読者には Base64 が刷り込まれます。
一方、RFC 6749 では、アクセストークンについては「文字列である」としか書いていません。
ここで、{access-token} にセットする値について、二つの選択肢が出てきます。 (1) {access-token} に認可サーバーから受け取ったアクセストークンをそのままセットするのか、それとも、(2) 認可サーバーから受け取ったアクセストークンに Base64 エンコーディングを施したものをセットするのか、の二つの選択肢です。もし (1) だとすると、RFC 6750 の要求事項により、アクセストークンに使える文字種に RFC 6749 よりも厳しい制限がかかることになります。つまり、**RFC 6750 はアクセストークンの受け取り方を規定すると同時に、認可サーバーの実装方法 (アクセストークンの表現方法) についても暗黙的に要求仕様を追加していることになります。**一方、(2) であれば、認可サーバーが発行するアクセストークンにはどんな文字を使ってもよくなります。
正解は (1) なのですが、(2) と考える人が出てきてもやむを得ないと思います。事実、OAuth ワーキンググループのメーリングリストにも下記のような投稿 (question about the b64token syntax in draft-ietf-oauth-v2-bearer) がされていて、それによれば、投稿者自身を含め複数人が (2) だと誤解していたそうなのです。
On casual reading of "The OAuth 2.0 Authorization Protocol: Bearer Tokens"* I've encountered several people (including myself) who have made the assumption that the name b64token implies that some kind of base64 encoding/decoding on the access token is taking place between the client and RS.
Digging a bit deeper in to "HTTP/1.1, part 7: Authentication"**, however, I see that b64token is just an ABNF syntax definition allowing for characters typically used in base64, base64url, etc.. So the b64token doesn't define any encoding or decoding but rather just defines what characters can be used in the part of the Authorization header that will contain the access token.
Do I read this correctly?
If so, I feel like some additional clarifying text in the Bearer Tokens draft might help avoid what is (based on my small sample) a common point of misunderstanding.
Also, does the use of b64token implicitly limit the allowed characters that an AS can use to construct a bearer access token?
Thanks,
Brian
かくいう私も誤解していました。「アクセストークンの受け取り方の話をしている最中に、さらりと認可サーバーの実装方法に要求仕様を追加するなんてありえる? ないでしょw」と考えたからです。
2.2.2. 実際のコード例
RFC 6750 で定義されている三つの方法を全てサポートするコードは、Sinatra (Ruby) では次のようになると思います。
# リクエストからアクセストークンを取り出すメソッド
def extract_access_token(request)
# Authorization ヘッダーの値
header = request.env["HTTP_AUTHORIZATION"]
# "Bearer {access-token}" というフォーマットであれば
if /^Bearer[ ]+(.+)/i =~ header
# Authorization ヘッダーから取り出した値を返す。
return $1
end
# リクエストパラメーター access_token の値を返す。
return request["access_token"]
end
# GET メソッドの例
get '/hello' do
# リクエストからアクセストークンを取り出す。
access_token = extract_access_token(request)
end
PHP だと下記のようなコードになるでしょう。なお、Stack Overflow の「Getting response as 'Unauthorized' while sending access token via URI Query Parameter」という質問によると、Yii という PHP 系のフレームワークでは、Authorization ヘッダー以外の方法でアクセストークンを受け取れないようです。(下記のコードはその質問に対する私の回答に含めたコードです。)
/**
* リクエストからアクセストークンを取り出す関数
*/
function extract_access_token()
{
// Authorization ヘッダーの値
$header = $_SERVER['HTTP_AUTHORIZATION'];
// "Bearer {access-token}" というフォーマットであれば
if ($header != null && preg_match('/^Bearer[ ]+(.+)/i', $header, $captured))
{
// Authorization ヘッダーから取り出した値を返す。
return $captured;
}
if ($_SERVER['REQUEST_METHOD'] == 'GET')
{
// クエリーパラメーター access_token の値を返す。
return $_GET['access_token'];
}
else
{
// フォームパラメーター access_token の値を返す。
return $_POST['access_token'];
}
}
JAX-RS (Java) (JSR-339) では次のようになります。
private static final Pattern CHALLENGE_PATTERN
= Pattern.compile("^Bearer *([^ ]+) *$", Pattern.CASE_INSENSITIVE);
/**
* GET メソッドの例
*/
@GET
public Response get(
@HeaderParam(HttpHeaders.AUTHORIZATION) String authorization,
@QueryParam("access_token") String accessToken)
{
// Authorization ヘッダーからアクセストークンを取り出すか、
// または、クエリーパラメーター access_token の値を使う。
accessToken = extractAccessToken(authorization, accessToken);
}
/**
* Authorization ヘッダーからアクセストークンを取り出すか、
* もしくは access_token リクエストパラメーターの値を返す。
*/
private static String extractAccessToken(
String authorization, String accessToken)
{
// リクエストに Authorization ヘッダーが含まれていない場合
if (authorization == null)
{
// リクエストパラメーター access_token の値を返す。
return accessToken;
}
// Authorization ヘッダーの値に対してパターンマッチングをおこなう。
Matcher matcher = CHALLENGE_PATTERN.matcher(authorization);
// Authorization ヘッダーの値が "Bearer {access-token}" という
// フォーマットであれば
if (matcher.matches())
{
// Authorization ヘッダーから取り出した値を返す。
return matcher.group(1);
}
else
{
// リクエストパラメーター access_token の値を返す。
return accessToken;
}
}
2.3. アクセストークン情報の取得方法
アクセストークンに紐付く情報を取得する方法ですが、アクセストークンが情報エンコーディング方式であれば、それをデコードするだけで済みます (前記事参照)。ここでは、アクセストークンそのものは無意味な文字列で、情報は認可サーバーのデータベース内に格納されているケースについてのみ考えます。
あなたの保護リソースエンドポイントでは、アクセストークンをリクエストから取り出した後、それに紐付く情報をどのように取得しているでしょうか? もし、データベースクエリーを発行しているのであれば、それは、認可サーバーとリソースサーバーが密結合していることを示しています。しかし、OAuth の仕様上は認可サーバーとリソースサーバーは別々のものなので、これら二つのサーバーを、データベースを共有しないように実装することも可能です。
データベースを共有しない実装とした場合、アクセストークンの情報を得るため、リソースサーバーは認可サーバーに問い合わせをしなければなりません。そして、その問い合わせ方法は、しばらく認可サーバー実装依存でしたが、2015 年 10 月にリリースされた RFC 7662 (OAuth 2.0 Token Introspection) によって標準化されました。
RFC 7662 をサポートする認可サーバーは、イントロスペクションエンドポイント (Introspection Endpoint) を実装します。このエンドポイントに token パラメーター (必須) と token_type_hint パラメーター (オプショナル) を付けて HTTP POST リクエストを投げると、情報が JSON 形式で返ってきます。下記は、RFC 7662 から抜粋したリクエストとレスポンスの例です。
POST /introspect HTTP/1.1
Host: server.example.com
Accept: application/json
Content-Type: application/x-www-form-urlencoded
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
token=mF_9.B5f-4.1JqM&token_type_hint=access_token
HTTP/1.1 200 OK
Content-Type: application/json
{
"active": true,
"client_id": "l238j323ds-23ij4",
"username": "jdoe",
"scope": "read write dolphin",
"sub": "Z5O3upPC88QrAjx00dis",
"aud": "https://protected.example.net/resource",
"iss": "https://server.example.com/",
"exp": 1419356238,
"iat": 1419350238,
"extension_field": "twenty-seven"
}
イントロスペクションエンドポイントからの応答に含まれる sub プロパティーの値が、アクセストークンに紐付けられたユーザーの一意識別子です。ただし、このプロパティーは仕様上オプショナルとなっています。特に、クライアントクレデンシャルズフローで発行されたアクセストークンについては、紐付くユーザーがいないので、値は null になるはずです。
2.4. アクセストークンのバリデーション
2.4.1. 確認項目
アクセストークン情報の取得後、バリデーションを行います。基本的には次の項目を確認します。
| 確認項目 | |
|---|---|
| 1 | 有効期限が切れていないこと |
| 2 | 保護リソースエンドポイントへのアクセスに必要な権限 (scope) をカバーしていること |
| 3 | 取り消されていないこと |
また、保護リソースエンドポイントの要件によっては、
| 確認項目 | |
|---|---|
| 4 | 特定のユーザーに紐付いていること |
を追加で確認したいケースもあると思います。
2.4.2. Amazon API Gateway Custom Authorization
アクセストークンのバリデーションに関連して、時事ネタを一つ。
2016 年 2 月 11 日に AWS Compute Blog の「Introducing custom authorizers in Amazon API Gateway」という記事で、Amazon API Gateway に Custom Authorizer という仕組みが導入されたことがアナウンスされました。
これにより、Amazon API Gateway で構築された API にクライアントアプリケーションが (OAuth や SAML 等の) Bearer トークンを提示してきたとき、そのトークンのバリデーションを外部の authorizer (認可者) に委譲することができるようになりました。下図はオンラインドキュメント「Enable Amazon API Gateway Custom Authorization」からの転載で、図中の上部にある「Lambda Auth function」というものが authorizer にあたります。この authorizer と API Gateway がやりとりすることにより、トークンのバリデーションをおこないます。
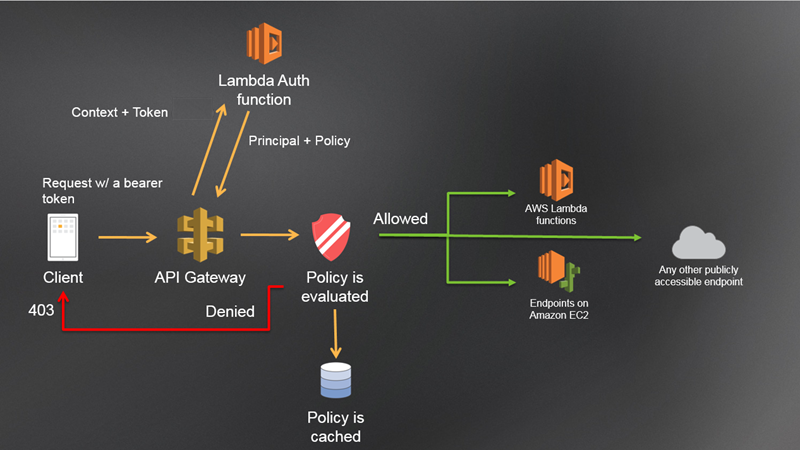
Amazon API Gateway 本体が OAuth サーバー機能を提供していない点に変わりはありませんが、この仕組みを使えば、Amazon API Gateway 上に構築された API を OAuth アクセストークンで保護することが可能となります。
[2016/03/02]
「Amazon API Gateway の Custom Authorizer を使い、OAuth アクセストークンで API を保護する」という記事を書きましたので、ご参照ください。
なお、この仕組みができるまでは、Amazon API Gateway + AWS Lambda で OAuth をやろうとすると、Lambda Function の実装内でアクセストークンの情報取得とバリデーションをやらなければならず、試みる人はほとんどいませんでした。そのため、私が昨年 10 月末に Authlete を使って実装したときにはちょっとした話題になり、AWS チーフエバンジェリストの Jeff Barr さんにも Wow と言っていただけました。
2.5. エラー応答
RFC 6750 では、保護リソースエンドポイントのエラー応答についても定めています。特徴的なのは、エラーに関する情報を WWW-Authenticate ヘッダーに埋め込むことです (3. The WWW-Authenticate Response Header Field)。下記は、オプショナルの項目をすべて含むエラー応答の例です。
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Bearer realm="example",
error="invalid_token",
error_description="The access token expired",
error_uri="https://example.com/error/E001",
scope="openid profile email"
エラー応答内の error が取りうる値として、RFC 6750 の 3.1. Error Codes に次の三つがリストされており、エラーの原因によって使い分けることになります。
| 説明 | |
|---|---|
invalid_request |
必要なパラメーターが含まれていない等 |
invalid_token |
アクセストークンが無効 |
insufficient_scope |
アクセストークンが十分な権限を持っていない |
error_description と error_uri は、それぞれ、エラーに関する説明と、エラーに関する情報を含むページへの URL です。また、scope は、その保護リソースエンドポイントにアクセスするために必要な権限群のリストです。
2.6. 情報取得 + バリデーション
イントロスペクションエンドポイントからアクセストークンの情報を取得したあとのバリデーション作業は保護リソースエンドポイントの実装内でおこないますが、有効期限のチェックや必要な権限がカバーされているかどうかのチェックなどは、決まりきった処理です。ですので、いっそのこと、アクセストークンに加えて、呼び出し元の保護リソースエンドポイントが要求するスコープのリストもイントロスペクションエンドポイントに渡し、認可サーバー側でバリデーションをやってもらうことにすれば、保護リソースエンドポイントの実装は楽になります。さらに、アクセストークンが無効であった場合に用意しなければならないエラー情報 (= クライアントアプリケーションに返すエラー応答に含める WWW-Authenticate ヘッダーの値) の生成まで認可サーバー側でやってくれれば、保護リソースエンドポイントの実装はもっと楽になります。
つまり、イントロスペクションエンドポイントの仕事の範囲が、
- アクセストークン情報の提供
だけではなく、
- アクセストークン情報の提供、バリデーション、RFC 6750 に準拠するエラーメッセージの生成
まで広がってくれれば、保護リソースエンドポイントの実装はかなり楽になるはずです。
例えば Authlete のイントロスペクションエンドポイント(/api/auth/introspection)は、RFC 7662 に準拠していないかわりに※、アクセストークン情報の提供に加えて、バリデーションや RFC 6750 に準拠するエラーメッセージの生成も行います。このおかげで、「Amazon API Gateway + AWS Lambda + OAuth」を実現したときの Lambda 関数の実装である index.js や、「Amazon API Gateway の Custom Authorizer を使い、OAuth アクセストークンで API を保護する」を実現したときの index.js、リソースサーバーのリファレンス実装 java-resource-server に含まれる保護リソースエンドポイントの例である CountryEndpoint.java では、アクセストークンを処理するコードが非常に短くなっています。
※:RFC 7662 に準拠するイントロスペクションエンドポイントを実装するための API である /api/auth/introspeciton/standard、および、RFC 7662 を直接実装したエンドポイントである /api/auth/introspection/standard/direct が別途存在します。
2.7. アクセストークン情報のキャッシュ
クライアントアプリケーションからアクセストークンを受け取るたびに認可サーバーと通信することを避けるため、アクセストークンの情報をリソースサーバー側でキャッシュしておくのも手です。ただし、キャッシュとして持っておく時間の長さの分だけ、アクセストークンの取り消し (revocation) を把握するのが最大でキャッシュ時間分遅れる、というトレードオフがあります。しかしながら、逆に言うと、アクセストークンの取り消しイベントをリソースサーバーのキャッシュシステムが完全に捕捉できるのであれば、効率的にキャッシュすることができます。
前出の Amazon API Gateway Custom Authorization では、authorizer による処理結果を API Gateway 側でキャッシュすることができます。キャッシュを保持する時間は、設定で 0 秒 (キャッシュしない) ~ 3,600 秒の間で選ぶことができます。デフォルト値は 300 秒 (5 分) です。キャッシュが有効な間は authorizer は呼ばれません。
2.8. 図解:認可コードフロー
ただでさえ登場人物の多い OAuth の世界で、さらに認可サーバーとリソースサーバーの実装を分割し、イントロスペクションエンドポイント云々を言い始めると、全体像の把握が難しくなります。そこで、フローが一番複雑になる認可コードフローを図にしてみました。適宜ご活用ください。
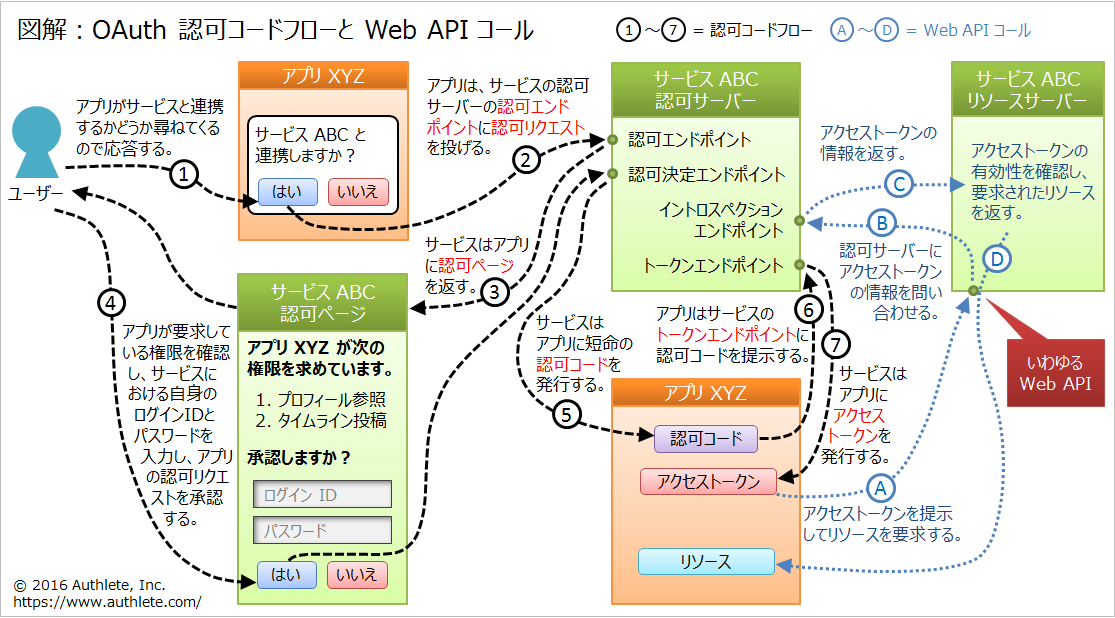
3. Authlete (オースリート)
前記事「OAuth 2.0 + OpenID Connect のフルスクラッチ実装者が知見を語る」を公開後、「必要最小限の機能だけであれば OpenID Connect の実装は言うほど難しくはない」という意見を幾つか拝見しました。
言われてみれば、そうかもしれません。単に、オプショナル機能群の実装と Authlete そのものの設計・実装が大変だっただけなのかもしれません。
仕様書を読み込むのが大変だったのも、今思えば、「できる限り全部実装する」という気持ちで読んでいたから大変だったのであって、「MUST 以外は読まない」という態度だったのであれば楽だったことでしょう。 特に、OpenID Provider Metadata の request_parameter_supported と request_uri_parameter_supported に false を設定し、OpenID Connect Core 1.0 の 6. Passing Request Parameters as JWTs を丸ごと無視していたら、かなり楽できたに違いありません。リクエストオブジェクトをサポートしようとすると、request_uri パラメーターで指定された場所からリクエストオブジェクトをフェッチし、それが非対称鍵系のアルゴリズムで署名・暗号化されていたら、加えてクライアントアプリケーションの jwks_uri から JWK Set ドキュメントをフェッチして、それを用いてリクエストオブジェクトの復号化と署名検証をしなければなりません。もちろん、毎回フェッチするのはよろしくないので、RFC 2616, 13.2.4 Expiration Calculations の計算式に基づいて有効期間を計算し、適宜データベースにキャッシュすることも必要です。しかしながら、ここまで頑張っておいてなんですが、正直リクエストオブジェクトを使う人はいないと思っています。
また、オプショナル機能群の話を脇に置いたとしても、単純に IdP を1セット実装することと Authlete のようなものを実装することとでは、難易度が異なります。せっかくですので、Authlete 固有の話をさせていただこうと思います。世の中に幾つも存在する OAuth 2.0 + OpenID Connect サーバー実装の一例に過ぎませんが、参考になる部分もあることと思います。
2017 年 10 月 11 日:『OAuth 2.0 / OIDC 実装の新アーキテクチャー』もご参照ください。
3.1. 全てが Web API
Authlete は OAuth 2.0 と OpenID Connect の実装をクラウドで提供するサービスです。しかしこれは、単にクラウド上のマシンで OpenAM のようなソフトウェアが動いているという単純な話ではないのです。
Authlete が他の実装と異なっているのは、まず、OAuth 2.0 + OpenID Connect サーバーを実装するのに必要な機能を全て Web API として設計・実装した点です。クライアントアプリケーションの登録管理や認可サーバーのメタ情報更新機能を Web API で提供している、というだけにとどまりません。それだけではなく、認可エンドポイント (RFC 6749, 3.1)、トークンエンドポイント (RFC 6749, 3.2)、ユーザー情報エンドポイント (OIDC Core 1.0, 5.3)、JWK Set エンドポイント (RFC 7517)、Revocation エンドポイント (RFC 7009)、コンフィギュレーションエンドポイント (OIDC Discovery, 4) などの、エンドポイント群の実装に必要な機能も全て Web API 化したのです。
例えば、認可エンドポイントを実装するための Web API として、Authlete は次の三つの Web API を提供しています。これらを組み合わせて用いることで、OAuth 2.0 と OpenID Connect をサポートする認可エンドポイントを実装することができます。
| API パス | 役割 | |
|---|---|---|
| 1 | /api/auth/authorization |
認可要求処理と認可画面生成に必要な情報の準備 |
| 2 | /api/auth/authorization/issue |
トークン群を含むリダイレクト情報を生成 |
| 3 | /api/auth/authorization/fail |
エラー情報を含むリダイレクト情報の生成 |
OAuth 2.0 と OpenID Connect の実装本体と認可関連データは全てクラウド上にあるため、Authlete を BaaS (Backend-as-a-Service) として利用する認可サーバーの実装、例えば java-oauth-server は、コードが非常に短くなり、また、手元にデータベースを持つ必要がなくなります。つまり、DB-less 認可サーバーになります。
どれくらい実装が短くなるかというと、例えばコンフィギュレーションエンドポイント (OpenID Connect Discovery 1.0) の実装 (ConfigurationEndpoint.java) は、authlete-java-common や authlete-java-jaxrs といったライブラリが頑張っているおかげでもありますが、下記のコードが全てです。これだけで、クラウド上のデータベース内にある情報をかき集めて要求仕様通りの JSON を返す、という動作が実現されます。
@Path("/.well-known/openid-configuration")
public class ConfigurationEndpoint extends BaseConfigurationEndpoint
{
/**
* OpenID Provider configuration endpoint.
*/
@GET
public Response get()
{
// Handle the configuration request.
return handle(AuthleteApiFactory.getDefaultApi());
}
}
3.2. 複数インスタンス
Authlete のユーザーは、クラウド上に**複数の OAuth 2.0 + OpenID Connect 実装インスタンスを持つことができます。**そのため、Authlete が提供する管理コンソール (サービスオーナーコンソール) は、複数インスタンスを管理する前提で作られています。その管理コンソールを使えば、IdP を 1 セット追加する作業は、デフォルト設定でよければ、たかだかボタン 2 クリックで終わってしまいます (Create Service)。 以下、ジャン=ピエール・ポルナレフ氏からのコメントです。
あ・・・ありのまま 今 起こった事を話すぜ!
「おれは MySQL をセットアップして create table 文を流し込もうと思ったら いつのまにか IdP ができていた」
な・・・何を言っているのかわからねーと思うが、おれも 何をされたのかわからなかった!
頭がどうにかなりそうだった・・・
必要最小限機能だとかオンメモリ仮実装だとか そんなチャチなもんじゃあ 断じてねぇ
もっと恐ろしいものの片鱗を味わったぜ・・・
複数の OAuth 2.0 + OpenID Connect 実装インスタンスを簡単に生成できるのであれば、開発作業やシステム設計も変わってきます。開発者毎に認可サーバーを持ったり、public クライアント用と confidential クライアント用の認可サーバーを分けたり、一般ユーザー用の認可サーバーと管理者用の認可サーバーを用意して scope セットに差を持たせたり、などなど。
3.3. 認可に特化している
Authlete は**認可に特化しており、ユーザー認証をおこないません。**OpenID Connect をサポートしているにも関わらず、です。Authlete がユーザーアカウントデータベースを抱え込むことはないので、ユーザー認証とユーザークレーム情報管理は、全て Authlete の利用者がおこなうことになります。
慎重な設計により、認証との密結合を避けたことで、Authlete はどのような認証ソリューションとも組み合わせることができます。ユーザー認証の方法が、ログイン ID & パスワードによるものなのか、指紋や虹彩などの生体情報に基づく認証なのか、ワンタイムパスワードを使うのか、2-way 認証なのかは、Authlete は全く関知しないのです。Authlete が認可の仕組みを実現する上で必要なのは、認証が終わった後に定まるユーザー一意識別子 (subject) だけなのです。認証と認可を分けるということは、突き詰めると、そこに辿りつきます。
辿りついてしまえば単純な概念ですが、その概念に沿うソフトウェアの設計と実装は、必ずしも簡単だとは限りません。例えば、某上場企業は、認証・認可・リソースが密結合していた OAuth 実装を疎結合にする必要に迫られ、社内プロジェクトを立ち上げてリファクタリングを試みたものの、認可とリソースがそれぞれ、どうしても認証に依存してしまう形から脱することができませんでした。これは、あるエンジニアの方から聞いた話です。
Authlete がシリコンバレーの IoT 企業に採択されたのも、認証を切り離していたからです。認証の対象が人間ではなく、シリアルナンバーと PIN コードで特定される IoT 機器だったとしても、対象の一意識別子が定まるのであれば、Authlete によってそこに認可の仕組みを追加することができるからです。
余談ですが、海の向こうの IoT は、認証の先の認可にまで話が進んでいます。また、人と IoT 機器との間の認可のみにとどまらず、異なるメーカーが生産した機器間の認可についても議論されています。
3.4. 動的生成および設定変更
Authlete では、OAuth 2.0 + OpenID Connect 実装インスタンスの生成と設定変更、および、クライアントアプリケーションの生成と設定変更は、全て動的に実行することができます。
動的変更可能とするかどうかにより、サーバーの実装はいろいろと変わってきます。例えば、OpenID Connect Discovery 1.0 で定義されているコンフィギュレーションエンドポイント (/.well-known/openid-configuration) の実装は、サーバーの設定を動的に変更しないのであれば、起動時に静的な設定ファイルを読み込んで一度だけ JSON を生成し、エンドポイントの実装はその JSON を返すだけ、とすることができます。極端な話、JSON を予めファイルとして生成しておいて、それを返すだけの実装とすることもできます。
Authlete では、OAuth 2.0 + OpenID Connect 実装を管理するために**サービスオーナーコンソールを、クライアントアプリケーションを管理するためにデベロッパーコンソール**を、それぞれ用意しています。また、/api/service/* API や /api/client/* API を使うことにより、これらの Web コンソール群を全く使わずに管理を行うことも可能となっています。
さいごに
今回は、前置き (「もう一つの認可」) が長かったものの、保護リソースエンドポイントの話がメインでした。保護リソースエンドポイント、いわゆる世の中でいうところの (狭義の) Web API を実装する際に参考にしていただければと思います。
最後まで読んでいただき、ありがとうございました!