前書き
Tensorflowが発表されて、7ヶ月が立ちました。さすがGoogleのブランド力が強いだけあって、一気に世に広まって、ディープラーニングブームの火付け役となりました。
Tensorflowの影響でディープラーニングに興味を持ったプログラマーが大勢います。筆者もその一人です。プログラマーだから、最初はソースコードを読めばわかるだろうと思って、word2vec等のソースコードをひたすら読みました。だが、背後にある理論がまったくわかっていないので、理解できませんでした。
幸い、今はオープンな時代。arXiv.orgから論文を無料でダウンロードできるから、その気になればいくらでも読めます。しかし、根はプログラマーだから、作りたくなります。作ったら語りたくなります。
この記事は、皆さんお馴染みのTensorFlowチュートリアル - 熟練者のためのディープMNIST(原文)を改良していく記事です。より良い方法見つけ次第、更新します。
ディープMNISTの正体
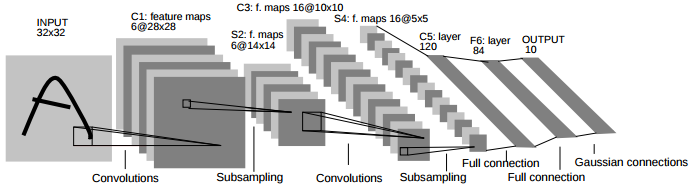
ディープMNISTの正体はLeNet(英語)です。DropoutやReLu等新しい技術を使っているが、基本構成がLeNetであることは変わりありません。LeはYann LeCunのLeです。Yann LeCunは、畳み込みニューラルネットワーク(Convolutional Neural Network, CNN)の父であり、今はFacebook AI Research(FAIR)のディレクターを務めている人物です。
LeNetの原型は1989年の論文で発表されました。チュートリアルの形(LeNet-5)に進化したのは1998年の論文です。LeNet-5の特徴は、畳み込み(5×5のカーネル)とプーリングの処理を2回繰り返し、全結合層を経て出力する構造です。
畳み込み等概念の説明は人気の記事があるので割愛します。
ディープMNISTの実行:99.2%~99.3%
まず、GitHubからソースコードをダウンロードする必要があります。リンク
https://github.com/jiapengjp/vggmnist
下記コマンドでディープMNISTを実行します。初回は、MNISTデータをダウンロードする必要があります。
python 1_mnist_exp.py
基本チュートリアルをそのままコピーして作ったコードなので、実行環境に問題がなければ、チュートリアル同じ99.2%~99.3%の結果が得られます。下記は出力の例ですが、初期値がランダムなので毎回違う結果になります。
step 18000, training accuracy 1, test accuracy 0.9924
step 18100, training accuracy 1, test accuracy 0.9931
step 18200, training accuracy 1, test accuracy 0.992
step 18300, training accuracy 1, test accuracy 0.9925
step 18400, training accuracy 1, test accuracy 0.9934
step 18500, training accuracy 1, test accuracy 0.9933
model_expフォルダにmodel_精度-stepナンバーの名前で上位3位のモデルを保存するので、モデルを再利用できます。
最小限の修正:VGGシンプル
まず、ディープMNISTのソースコードをできるだけ流用し、最小限の修正で正解率を上げたいと思います。思いついたのはVGGモデルです。VGGモデルとは、2014にImageNetで優勝したオックスフォード大学のVGGチーム(Visual Geometry Group)が使ったモデルです。
余談だが、作者の一人Karen Simonyanは、李世ドルを破ったAlphaGoで一躍有名になったGoogle DeepMindに入社しました。EU離脱で揺らぐイギリスですが、AIの人材争奪戦では意外な健闘ぶりを見せました。
VGGモデルのアイディアは驚くほどシンプルなものであり、3×3の小さいカーネルを採用することです。下記の図で示したように、3×3のカーネルを2つ重ねると、5×5のカーネルと同じ範囲をカバーできます。同様、3つ重ねると7×7のカーネルと同じ範囲をカバーできます。
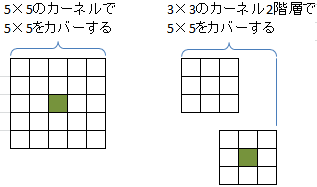
同じ範囲であれば、なぜわざわざ3×3の小さいカーネルを使うかと疑問を感じます。VGG論文によると、カーネルが1階層増えるから、非線形のReLu層も1階層増えます。これでネットワークの弁別力が高くなります。
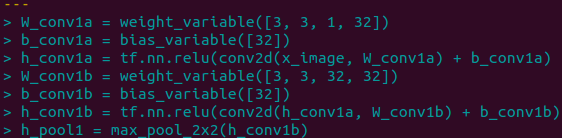
主な変更点は下記のようになります。詳細は2_mnist_vgg_simple.pyをご参照ください。単純に5×5のカーネルを3×3のカーネルに変更し、1つの畳み込み層を2つに拡張するだけです。要注意は、プーリング層を増やさないことです。

VGGシンプルの実行:0.01%改善
下記コマンドでVGGシンプルを実行します。
python 2_mnist_vgg_simple.py
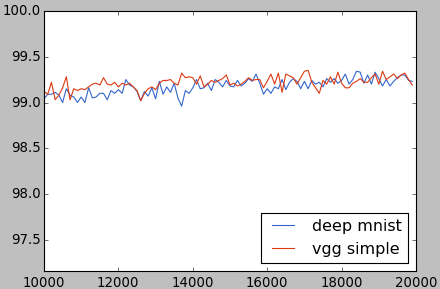
正解率を描画してみると、ディープMNISTとほぼ同じです。
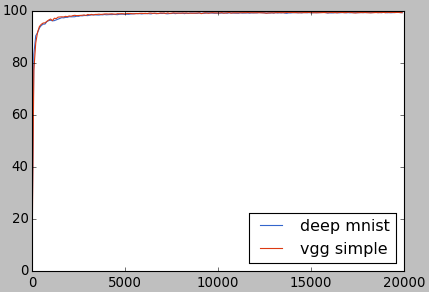
1万回以降の部分を拡大すると、大部分はディープMNISTのちょっと上にいることがわかります。
深くする:VGGシングル
VGGモデルの3×3カーネルを試した結果、ほんの少しですが改善されました。なので、本格的なVGGモデルに近づけば近づくほど、大幅な改善が期待できます。
VGGモデルのもう1つの特徴は、カーネルの数が多いことです。カーネルの数は、学習できる特徴の種類を決めるものです。分かりやすく言えば、カーネル1が角を検出し、カーネル2が輪郭を検出し、カーネル3が… カーネルの数が多ければ、入力画像をいろいろな角度から見ることができます。その結果、弁別力が高くなります。
ディープMNISTでは、第1層32カーネルと第2層64カーネル、合計96カーネルを使ってます。VGGモデルの一番シンプルな構成でも、第1層64カーネル、第2層カーネル128カーネル、第3層カーネル256カーネル、第4層カーネル512カーネル、合計960カーネルとなります。ディープMNISTの10倍です。
下記の例ように、ディープMNISTのカーネルのサイズと数を修正します。単純さを保つことを考えて、VGGシンプルのように3×3カーネルを複数重ねることをしなかったので、VGGシングルという名前にしました。
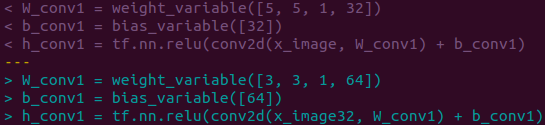
下記の例ように、ディープMNISTにない畳み込み層3と4を追加します。

1つ問題が残っています。プーリング層が4つになるので、入力画像が最終的に1/16になります。MNISTの画像は28×28なので、32×32に拡張する必要があります。下記のように、tensorflowのpad関数を使って、入力画像の上下左右に2ピクセルずつを追加し、32×32に拡張してからネットワークに投入するように修正します。

VGGシングルの実行:89.4%改悪
下記コマンドでVGGシングルを実行します。
python 3_mnist_vgg_single.py
下記のような思わぬ結果になって、失敗しました。
step 0, training accuracy 0.12, test accuracy 0.1059
step 100, training accuracy 0.12, test accuracy 0.098
step 200, training accuracy 0.1, test accuracy 0.098
step 300, training accuracy 0.06, test accuracy 0.098
step 400, training accuracy 0.08, test accuracy 0.098
step 500, training accuracy 0.08, test accuracy 0.098
VGGシングルの改良
失敗の原因はさっぱりわかりませんでした。いろいろ調べた結果、Bengio先生の論文にたどり着きました。結論から言うと、ランダムな初期値の問題です。
畳み込みニューラルネットワークの基本的な考え方は、カーネルで特徴を検出し、それらの特徴で入力を分類します。分類が間違った場合は、カーネルのパラメータを調整します。ランダムな値で初期化したカーネルは、分類に役に立たないとネットワークが判断するので、0にプッシュする傾向があります(具体的にWを0にbだけで検出)。
3層以内であれば、完全に0にならないので、ランダムな初期値でもいけました。VGGシングルの場合は4つの畳み込み層があるので、カーネルのパラメータが猛スピードで0になって、学習能力を失ってしまいました。
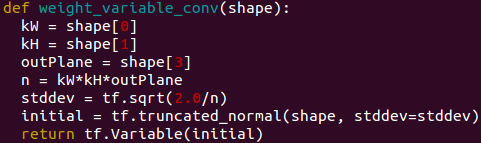
Bengio先生の教えに従って、bを0に、Wを下記のように初期化するように修正します。
VGGシングル改良版の実行:99.3%~99.4%, 0.1%改良
下記コマンドでVGGシングル改良版を実行します。Bengio先生がすごい!かんな簡単な修正でスムーズに動きました。
python 4_mnist_vgg_single.py
正解率のチャートです。左上を注目すると、ランダムな初期化より早く学習していたことがわかります。
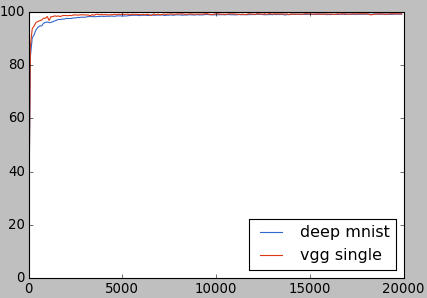
1万回以降の部分を拡大してみると、ディープMNISTを超えたことを確認できます。
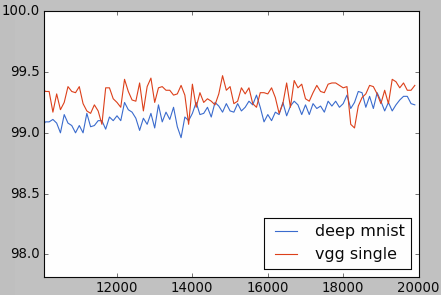
もっと深くする:VGGフル
VGGシングルがうまくいったので、モデルをもっと深くすれば、更に改良できるでしょう。VGG論文のVGG16を参考に、畳み込み層を追加していきます。要注意は、プーリング層を増やさないことです。プーリング層が変わらないので、入力画像のサイズをさらに調整する必要がありません。
- VGGシングル:
- conv64-pool1
- conv128-pool2
- conv256-pool3
- conv512-pool4
- VGGフル:
- conv64-conv64-pool1
- conv128-conv128-pool2
- conv256-conv256-conv256-pool3
- conv512-conv512-conv512-pool4
VGGフルの実行:0%改善(VGGシングルと比べる)
下記コマンドでVGGフルを実行します。
python 5_mnist_vgg_full.py
18000回まで順調でしたが、急にVGGシングルの初期バージョンと似たような現象が発生してしまいました。
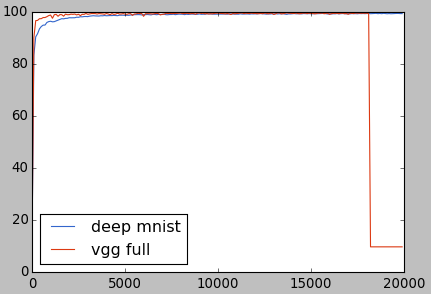
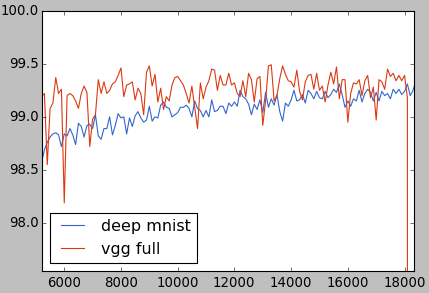
VGGフルの改良
VGGフルは安定して2万回まで学習できれば、もっといい数値が出るでしょう。18000回で急にカーネルのパラメータがゼロになったのは、おそらくAdamOptimizerの問題だと考えられます。もっとシンプルなMomentumOptimizerに切り替えたらうまく行く可能性があります。
モデルがデープになったので、2万回の学習が足りない可能性もあって、4万回に増やしました。
VGGフル改良版の実行:99.5%達成。
下記コマンドでVGGフルを実行します。
python 6_mnist_vgg_full.py
正解率は下記のチャートとなります。ディープMNISTのデータは2万回までしかないので、青い線がちょっと短いです。
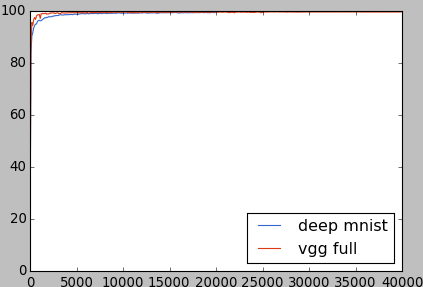
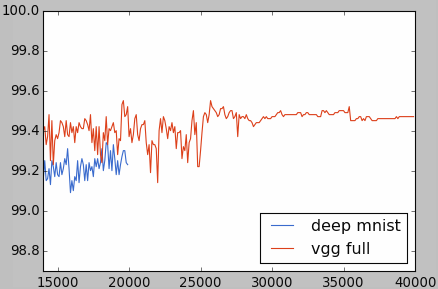
最高99.55%に達しました(19600と30600回)。エラー率で言えば、0.45%となるので、MNISTランキングのTop20に入ります。データ拡張、アンサンブルなど使っていないので、悪くない成績ですね。