前回作成したWatson関連の記事の続きみたいな位置付けです。きちんとしたAndroid用SpeechToTextライブラリを使った話です。
Watsonについての説明は前回書いた記事を参考にしてください。
今回使ったライブラリ
「speech-android-sdk」というAndroid用のライブラリを使いました。前回紹介したSDKだと種々のAPIを呼び出せたのですが、今回はSpeechToText, TextToSpeechに特化したものになります(その代わり、Androidとの親和性はバッチリです!)
さらにこのライブラリの大きなメリットは、何よりこれを使えば「Androidのマイクから音を拾って音声認識を行うことができる」ということです。
https://github.com/watson-developer-cloud/speech-android-sdk
このライブラリはIBM Watsonの公式リポジトリに登録されています。
使い方
- ライブラリの導入
https://github.com/watson-developer-cloud/speech-android-sdk#installation
を参考にしてみてください。ここで日本語に訳したものを記述するよりはわかりやすいと思います。 - AndroidManifest.xmlの追記
以下のコードをAndroidManifest.xmlに記載してください。(マイクと通信使うから当たり前っちゃ当たり前だが・・・)
<uses-permission android:name="android.permission.RECORD_AUDIO"></uses-permission>
<uses-permission android:name="android.permission.INTERNET"></uses-permission>
- ISpeechDelegateの実装
ISpeechDelegateはSpeechToTextを呼び出した後のイベントを拾うためのインターフェイスです。後に書く初期化処理のさいに使いますので、その前に実装しといたほうがスムーズにいくと思います。
ISpeechDelegateは以下のようなAPIになっています。
public interface ISpeechDelegate {
/**
* SpeechToTextのサーバとの接続が成功した時に呼ばれます。
*/
void onOpen();
/**
* SpeechToTextサービスとのやり取りの間でエラーが発生した時に呼ばれます。
*/
void onError(String error);
/**
* SpeechToTextのサーバとの接続解除がされた時に呼ばれます。
*/
void onClose(int code, String reason, boolean remote);
/**
* SpeechToTextサービスからの解釈結果を受け取ります。認識処理モード中の間にマイクが音を拾うたびに呼ばれます。
*/
void onMessage(String message);
/**
* 音量と振幅のデータを受け取ります。オシロスコープ的なのを作るのに使える???
*/
void onAmplitude(double amplitude, double volume);
}
4.初期化処理
音声認識を始める前に以下の初期化処理を実行させます。
SpeechToText.sharedInstance().initWithContext(
URI.create("wss://stream.watsonplatform.net/speech-to-text/api"),
context,
new SpeechConfiguration()); SpeechToText.sharedInstance().setCredentials("YOUR_ACCOUNT", "YOUR_PASSWORD");
SpeechToText.sharedInstance().setDelegate([ISpeechDelegateの実装]);
SpeechToText.sharedInstance().setModel("ja-JP_BroadbandModel");
// 上記モデルの引数で言語を指定することが可能。
個人的なおすすめはinitWIthContextをApplication#onCreate内で実装して、状況に応じて2行目以降をActivityのどこかに実装するというのがいいと思います。(特にsetModelのあたりはアプリによっては言語を変えて試したいというニーズもあるはず)
5. 認識開始
SpeechToText.sharedInstance().recognize()を実行します。Java版SDKと違い、ワーカスレッド上で動かす、といった処理を書かなくてもOKです。
6. 認識終了
SpeechToText.sharedInstance().stopRecognize()を実行します。
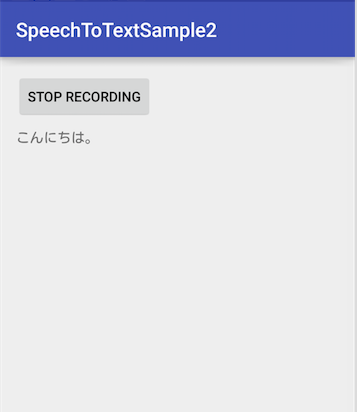
実際作ったアプリ
このSDKを使って「Androidのマイクから音声を拾って文字を起こす」アプリを作りました。
アプリケーションのソースはGithubにアップロードしてますので、気軽にDLして試してみてください。
所感
正直、前回紹介したSDKよりはAPI的に使いやすい印象でした。今回紹介したような機能をさくっと実現したい人にとってはとても重宝すべきものだと思います。(もう少し高度なことをしたい場合は・・・もう自分でSDK書くしかないかな、って気はしますが。。。)