人工知能を気軽に試せる「IBM Watson」というAPIがあります。その中で今回はSpeechToTextと呼ばれる音声認識のAPIについて紹介します。そして、それを使った簡単なサンプルアプリを作ってみました。
SpeechToTextとは?
IBM Watsonと呼ばれる人工知能が持つ機能の一つです。これは文字通り「人が話した内容を受信してテキスト起こしを行う」ための機能です。読み込み対象はwavファイルなどの非圧縮なデータに限ります(mp3とかを突っ込んだらエラーがでた。。)
IBM Watson
http://www.ibm.com/smarterplanet/jp/ja/ibmwatson/
SpeechToTextの紹介
http://www.ibm.com/smarterplanet/us/en/ibmwatson/developercloud/speech-to-text.html
SpeechToTextを試してみる
早速SpeechToTextがどんなものかを試してみましょう。
(1) IBM Watsonを使うためにIBM Bluemixのアカウントを取得します。
アカウントはこちらから取得できます。
https://console.au-syd.bluemix.net/
登録して30日間は無料で使えるのでこの30日間はどんどん使っちゃいましょう。その間にクレジットカードの情報を登録すると、いろいろ制限がかかるが無料で使い続けることができます。(制限を超えた使い方をすると容赦なく課金されますので注意!)
(2) IBM Bluemixにログインします。
(3) IBM BlueMixのダッシュボードが開きますので、「サービス&API」の「サービスまたはAPIの使用」をクリックします。
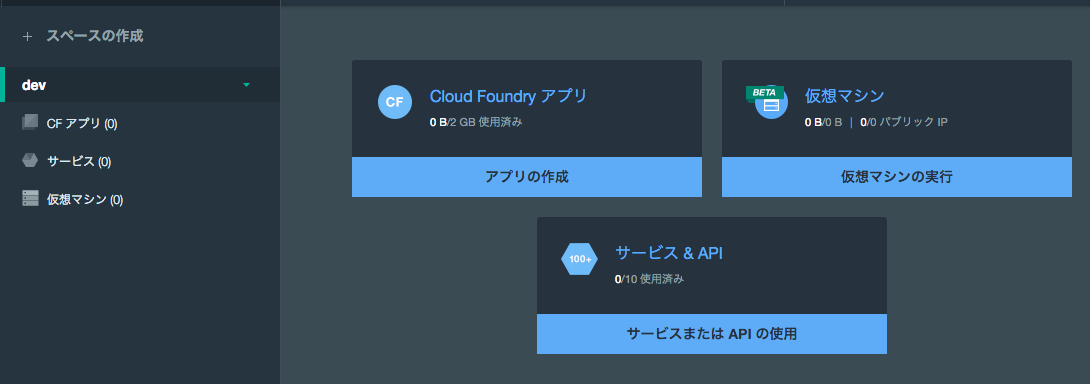
(4) Watsonで使えるAPI一覧が表示されるので、その中から「SpeechToText」を選択。
(5) サービス名、資格情報名を入力し、作成ボタンをクリック(そうするとSpeechToTextを使うためのサービスが作成されます)

(6) ダッシュボード左部分の[dev]-[サービス]-[(5)で作成したサービス名]をクリック

(7) SpeechToTextのページが現れます。ここでは機能を試したいのでデモのリンクをクリック。
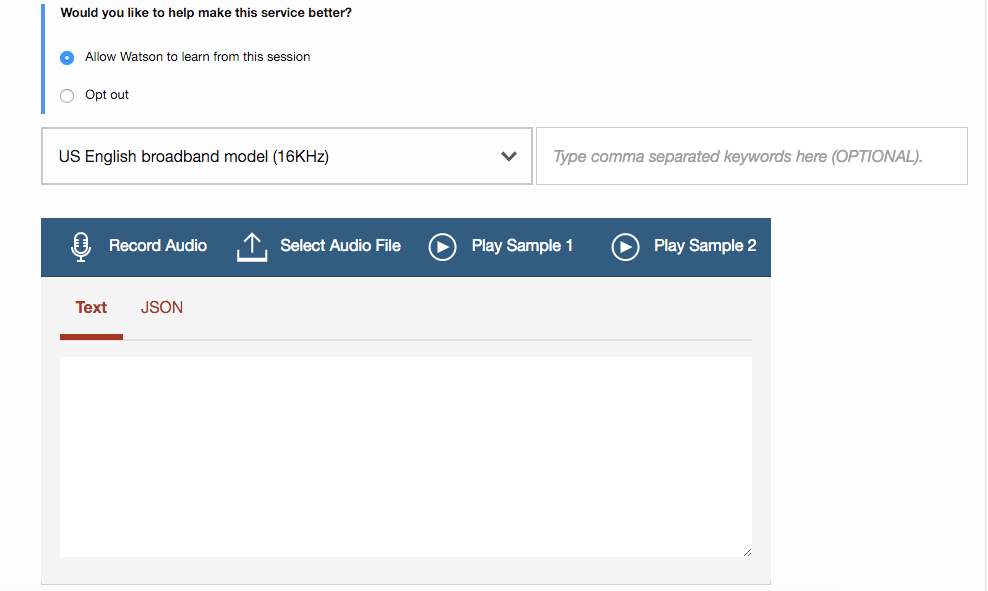
(8) 画面の下の方にSpeechToTextを試すためのフォームが出てくるのでそこでいろいろ試してみましょう。
真ん中のコンボボックスで対応言語を選択できます(日本人の場合は日本語の方がいいかな)
PlaySample1, PlaySample2で参考音源をSpeechToTextに突っ込んだときの結果を試すことができます。
Record Audioを使うとマイクを介して自分の声をSpeechToTextに突っ込むことができます。
SpeechToTextを使ったAndroidアプリを作ってみる。
今回はこのJava用SDKを使ってみました。
https://github.com/watson-developer-cloud/java-sdk
作成したアプリはこちらになります。このアプリではストレージないのwavファイルをダウンロードしてSpeechToText APIに放り投げて結果を取得し表示することができます。
https://github.com/LyricalMaestro/SpeechToTextSample
アプリで使うusername,passowordを取得
SpeechToTextサービスのページの「サービス資格情報」をクリックします。
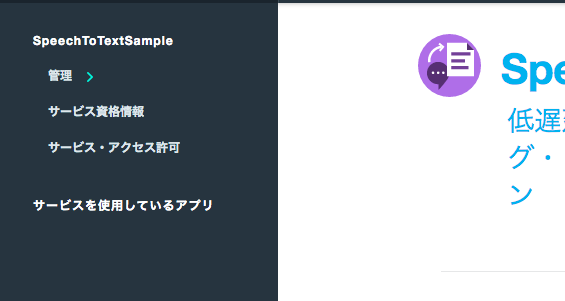
クリックすると資格情報がJSON形式で出てくるので、そこに出てくるusername,passwordを控えておきます。
Java用SDKを使用
今回は指定のwavファイルをWatson APIに突っ込んで結果を得るというものを実装します。
サンプルコードは以下に掲載します。
SpeechToText stt = new SpeechToText();
stt.setUsernameAndPassword(username, password);
stt.setEndPoint("https://stream.watsonplatform.net/speech-to-text/api");
final RecognizeOptions options = new RecognizeOptions().
contentType("audio/wav").
continuous(true).
interimResults(true).
model("ja-JP_BroadbandModel");
mStt = stt;
mSttHandler.post(new Runnable() {
@Override
public void run() {
try {
speechToTextInBackground(uri, options);
} catch (Exception ex) {
Log.e(SpeechToTextFragment.class.getName(), ex.getMessage(), ex);
}
mUiHandler.post(new Runnable() {
@Override
public void run() {
mStt = null;
}
});
}
});
private void speechToTextInBackground(final Uri uri, RecognizeOptions options) throws IOException{
File target = downloadWavFile(uri);
mUiHandler.post(new Runnable() {
@Override
public void run() {
if (mListener != null) {
mListener.onStartTextToSpeech(getTag());
}
}
});
final SpeechResults speechResults = mStt.recognize(target, options);
mUiHandler.post(new Runnable() {
@Override
public void run() {
if (mListener != null) {
mListener.onReceiveResult(getTag(), speechResults);
}
}
});
}
まず、SpeechToTextオブジェクトを作成し、setUsernameAndPassword でusername,password(上記セクションで控えたもの)を指定。そしてhttps://stream.watsonplatform.net/speech-to-text/apiをセットします。
そして、RecognizeOptions オブジェクトを生成し、音声認識のパラメータを設定します(ここで日本語モードにするかどうかも指定)
そのあと、SpeechToText#recognizeメソッドを実行します。ここで注意すべきなのはUIスレッドで実行するともれなくExceptionが出るのでワーカースレッドで実行スレッドで実行するようにしましょう。
認識結果としてSpeechResultsを取得することができます。これを使ってどのようにテキスト起こし出来たかを確認することができます。下記のようなコードを書くと認識結果を一つの文章としてつなげることができます。
StringBuilder sb = new StringBuilder();
for(Transcript transcript : speechResults.getResults()){
String word = transcript.getAlternatives().get(0).getTranscript();
sb.append(word);
}
まとめ
IBM Watsonの登録が少したるいですが、手軽にしかもただで音声認識を試すことができました。そして、それを使ったアプリも作れることもわかりました。
SpeechToTextの精度自体は・・・まわりにノイズがあったりとか二人同時に話したりするとかなり低いですが、比較的静かな場所で一人で話している分にはわりかし認識度が高いと思われます。
このSpeechToTextにはみんなから放り込まれた音声データをもとに裏側でどんどん精度を上げるための学習が行われているため、時が経てばもう少し精度があがることでしょう。
P.S. このサンプルアプリを書いたあとでAndroid用の公式SDK(Speech系のみ)がでていることがわかった・・・。あー!俺の苦労はいったい何だったんだー!!
https://github.com/watson-developer-cloud/speech-android-sdk