はじめに
突然ですが、このようにヌルヌル動くグラフを最近YouTubeでかなり頻繁に見かけませんか?
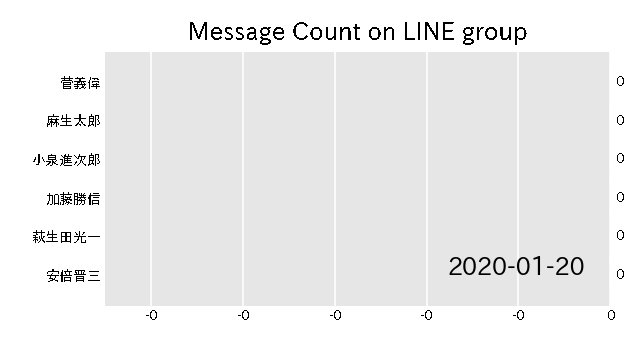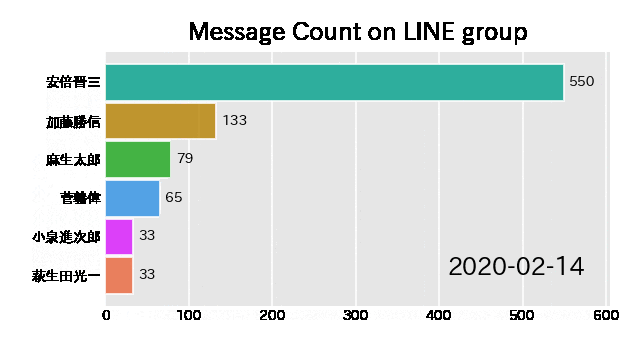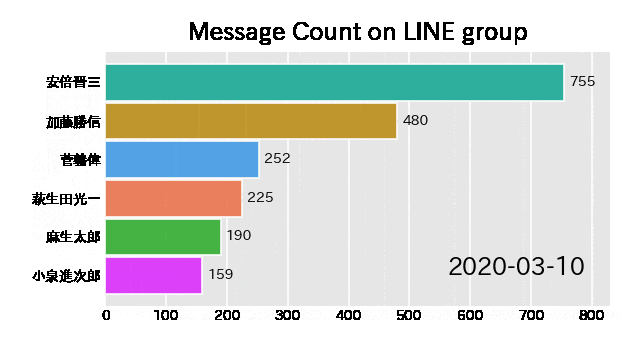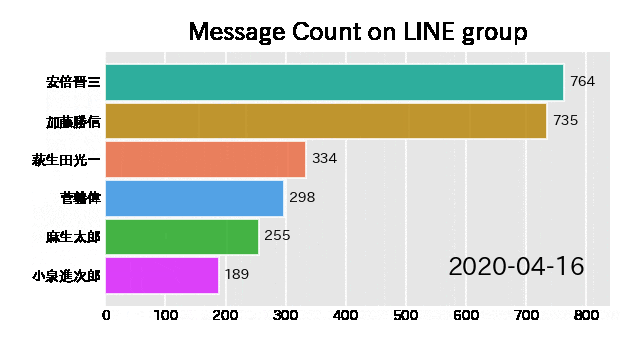
このグラフの名前は**バーチャートレース(Bar Chart Race)**といいます。
各項目の競争に見応えがあって思わず応援したくなりますよね。
プレゼンの資料に使えば観衆を惹きつけること間違いなしです。
実はこのバーチャートレース、Pythonの定番ライブラリMatplotlibで簡単に描けてしまいます。
とはいえ、「コードを書くのはちょっと…。」と思う人も当然いるはずなので、**関心度別に4つのコース**をご用意しました。
- 【今すぐ動かしたい人向け】Webアプリ利用コース
- 【手元で動かしたい人向け】パッケージ活用コース
- 【動く仕組みが気になる人向け】Matplotlib完全コース
- 【アプリまでデプロイしたい人向け】Streamlit開発コース
なお、この記事では時系列データ(時間とともに変化するデータ)としてLINEのグループトーク履歴を使うことをオススメします。なぜなら、「国別人口推移」や「新型コロナウイルスの国別死者数」に挙げられるような "wide" なデータセットを用意するのは手間がかかるからです。
オススメ通り、LINEのグループトーク履歴を使う人は、ド派手なグラフを作って友達を驚かせてあげましょう!
0. 作業に取り組む前に
LINEのトーク履歴をtxtファイルで保存する方法は☟以下のサイト☟に説明があります。
LINEのトーク履歴をメールで送信する方法【iPhone/Android/PC】
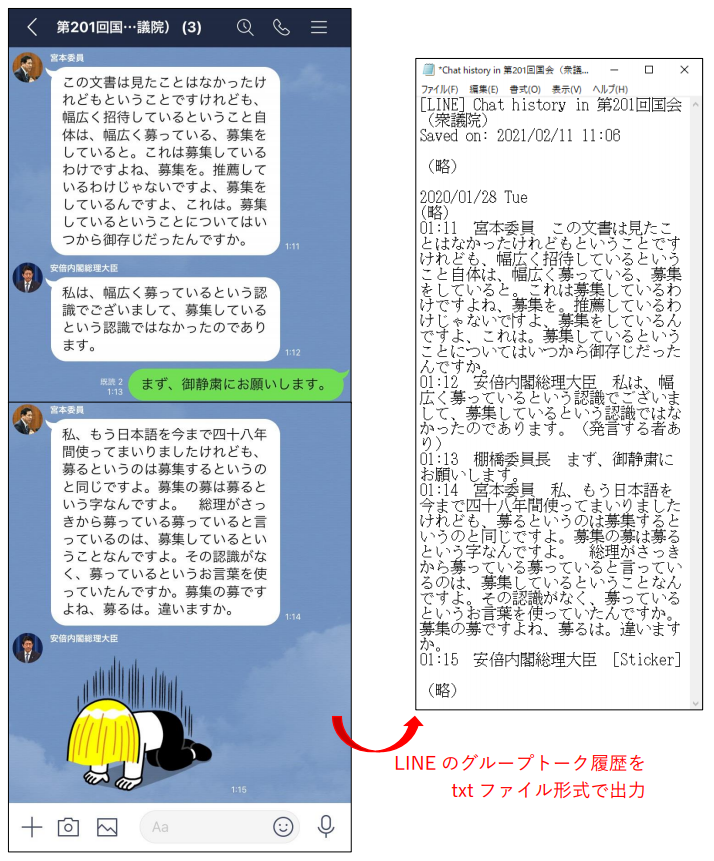
30秒ほどで保存作業が終わります。
ここで**「WebアプリにLINEのトーク履歴をアップロードするのは心配だ」**と言う方もいらっしゃると思います。
今回はLINEのトーク履歴を模倣して、国会会議録検索システムの会議録データをスクレイピング&編集したものを用意しました。
☟以下のGitHubのURLから、既成の軽量版トーク履歴(./ready-made/chat_log_lite.txt)をダウンロードしてご自由にご利用ください!
Kitsuya0828/Make-LINE-Chat-History-with-the-Diet-Record
それでは、早速コース別にバーチャートレースを作っていきましょう!
1. 【今すぐ動かしたい人向け】Webアプリ利用コース
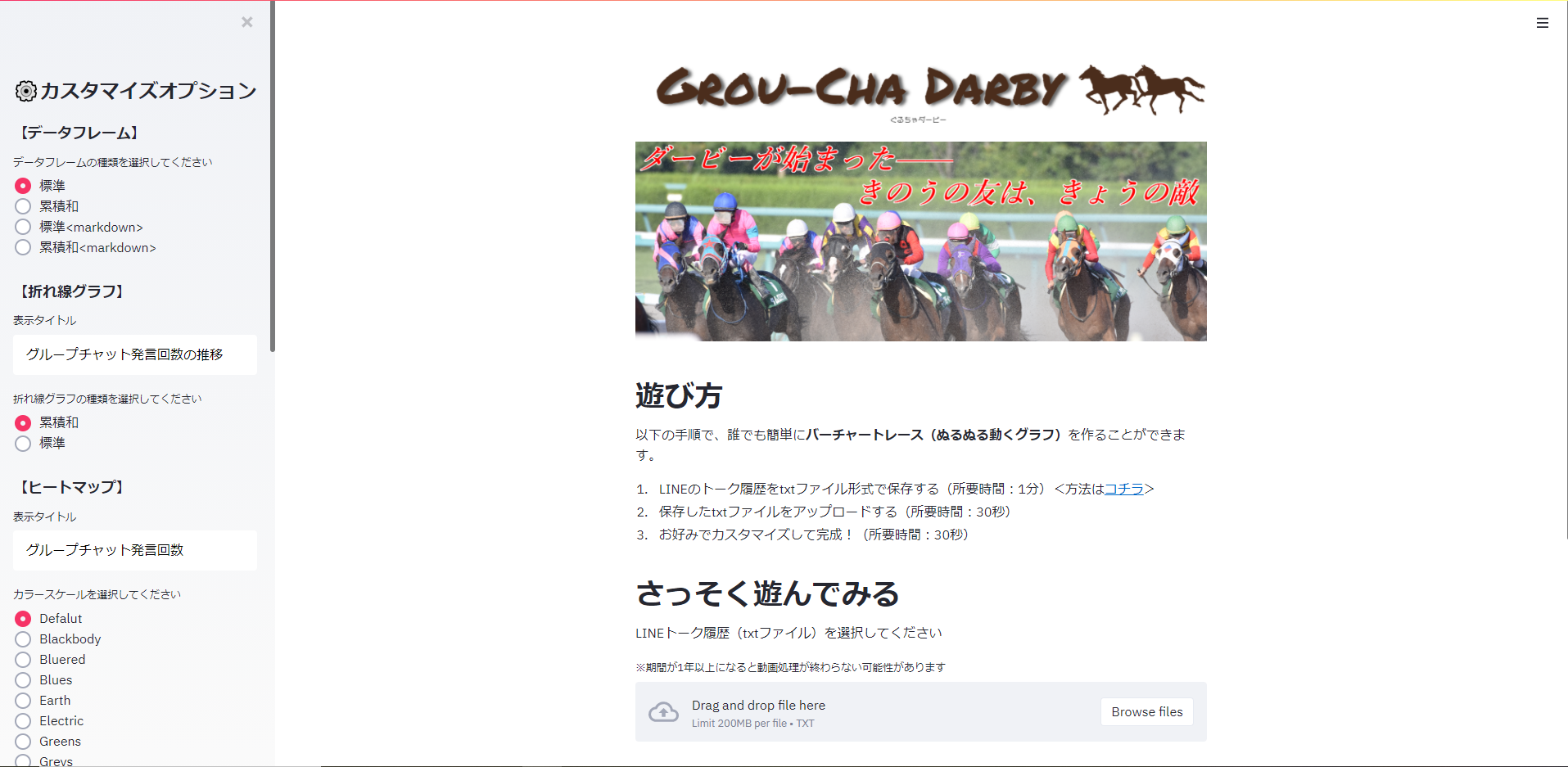
LINEのトーク履歴をアップロードするだけで、バーチャートレース(とその他諸々)を描画してくれるWebアプリを開発しました。
どんなものが完成するのか気になる人はぜひご覧ください。
app · Streamlit | GROU-CHA-DARBY ぐるちゃダービー
 |
 |
※ Herokuでデプロイしているので起動時間が長くなることがあります。ご容赦ください
Webアプリの作り方は、4. Streamlit開発コースで紹介しているのでそちらもぜひご覧ください。
2. 【手元で動かしたい人向け】パッケージ活用コース
このコースでは、Google Colaboratory の利用をオススメします。
記事とほとんど同じ内容の Colabファイル を用意したのでぜひ「ドライブにコピーを保存」してご利用ください。
以下の説明はローカル実行の人向けに書きました。
① テキストファイルをデータフレームに変換
用意したtxtファイルをDataFrame(Excelのような表形式)に変換します。
ごちゃごちゃしているので折りたたみましたが、{your_text_file_path}の部分だけ txt ファイルのパスに変更してもらえれば、他の部分は気にしなくて大丈夫です。
Pythonコード
import numpy as np
import pandas as pd
from collections import defaultdict
########## ここだけ変える ##########
f = open('{your_text_file_path}', 'r', encoding='UTF-8',errors='ignore')
########## ここだけ変える ##########
tmp_names = defaultdict(int) # グループメンバーの名前を格納するリスト
stringio_list = []
# グループの人数をカウント
for i,data in enumerate(f):
data_list = list(map(str,data.split())) # txtファイルの各行のデータをリスト化
stringio_list.append(data_list)
if i < 2: #2行目までのタイトルと保存日時はスキップ
continue
if len(data_list) <= 2: # 空白行&日付行はスキップ
continue
name = data_list[1]
if not data_list[0][0].isdigit() or name in ['Group','You','☎']: # システムメッセージ等を除外する
continue
tmp_names[name] += 1 # メンバーリストに追加
# 発言回数5回以上のメンバーだけ残す。条件を指定すれば任意のメンバーだけ選ぶことも可能
names = [key for key in tmp_names.keys() if tmp_names[key] >= 5]
chat_count = [] # 日付ごとの発言カウントを格納するリスト
daily_data = [] # 1日のデータを格納するリスト
# 開始日時と終了日時は制限してカスタマイズすることも可能
from_date = '2000-01-01'
to_date = '2999-12-31'
for i,data_list in enumerate(stringio_list):
if i < 2: #2行目までのタイトルと保存日時はスキップ
continue
if len(data_list) < 1: # 空白行はスキップ
continue
if len(data_list[0])>=10 and data_list[0][4]=='/' and data_list[0][7]=='/': # 日付の行
if daily_data:
if daily_data[0] <= to_date: # 表示期間以内
chat_count.append(daily_data) # 日付の行が来たタイミングで先日の発言回数をchat_countリストに追加
else: # 表示期間外
break
date = data_list[0].replace('/','-')[:10] # 2020/01/01 ---> 2020-01-01 (日付表示を変更)
if from_date <= date: # 表示期間内
daily_data = [date]+[0]*(len(names)) # その日のデータを格納するリストを用意 ['2020-01-01',0,0,0,...]
continue
else:
daily_data = None
if len(data_list) >= 3:
name = data_list[1]
if name in names and daily_data: # 発言表示の行の場合
daily_data[names.index(name)+1] += 1 # 発言者ごとの発言数をインクリメントする
if daily_data and daily_data[0] <= to_date:
chat_count.append(daily_data)
chat_count = np.array(chat_count) # 発言カウントリストをnumpy配列に変換
chat_count[:,1:len(names)+1] = np.cumsum(np.array(chat_count[:,1:len(names)+1],dtype=int),axis=0) # 日付以外の列に関して、縦方向に累積和を取る
df = pd.DataFrame(chat_count)
df.columns = ['日付'] + names # 列インデックスに氏名を指定
df = df.set_index('日付') # 行インデックスに日付を指定
df = df.astype(dict(zip(names,['int64']*len(names)))) # カウントした発言数を整数(int64)型に変換
print(df)
② パッケージを活用して描画
① でデータフレームが上手く表示されたら、あとはパッケージを活用するだけです。
その前に、使用するモジュールをインストールします。
pip install bar-chart-race
pip install japanize-matplotlib
ありがたいことに、既に Bar Chart Race というパッケージが公開されています。
PypIページ:bar-chart-race · PyPI
公式ドキュメント:Bar Chart Race
開発者に感謝しながら、以下のコードを実行しましょう。
import bar_chart_race as bcr
import japanize_matplotlib
html = bcr.bar_chart_race (
df, # 使用するデータフレーム
title='グループチャット発言回数ランキング', # 表示するタイトル
filename='group_chat_darby.gif', # 保存するファイル名(.gifでも.mp4でも)
n_bars=6, # ランキング上位表示人数
figsize=(5,3), # 横(インチ)×縦(インチ)のサイズ
steps_per_period=10, # 1ピリオド(表の行間)のステップ数 ⇒ なめらかさ
period_length=500, # 1ピリオドの長さ(ミリ秒)⇒ 動画の長さに影響
)
よく使うオプション引数のみを指定しましたが、公式ドキュメントには他にもたくさんのカスタマイズ方法が載っているので色々試してみてください。
3. 【動く仕組みが気になる人向け】Matplotlib完全コース
非常にたくさんのステップを踏んで丁寧に解説しているので、Google Colaboratory 上の .ipynb ファイルにまとめさせていただきました。
【動く仕組みが気になる人向け】Matplotlib完全コース - Colaboratory
 |
 |
 |
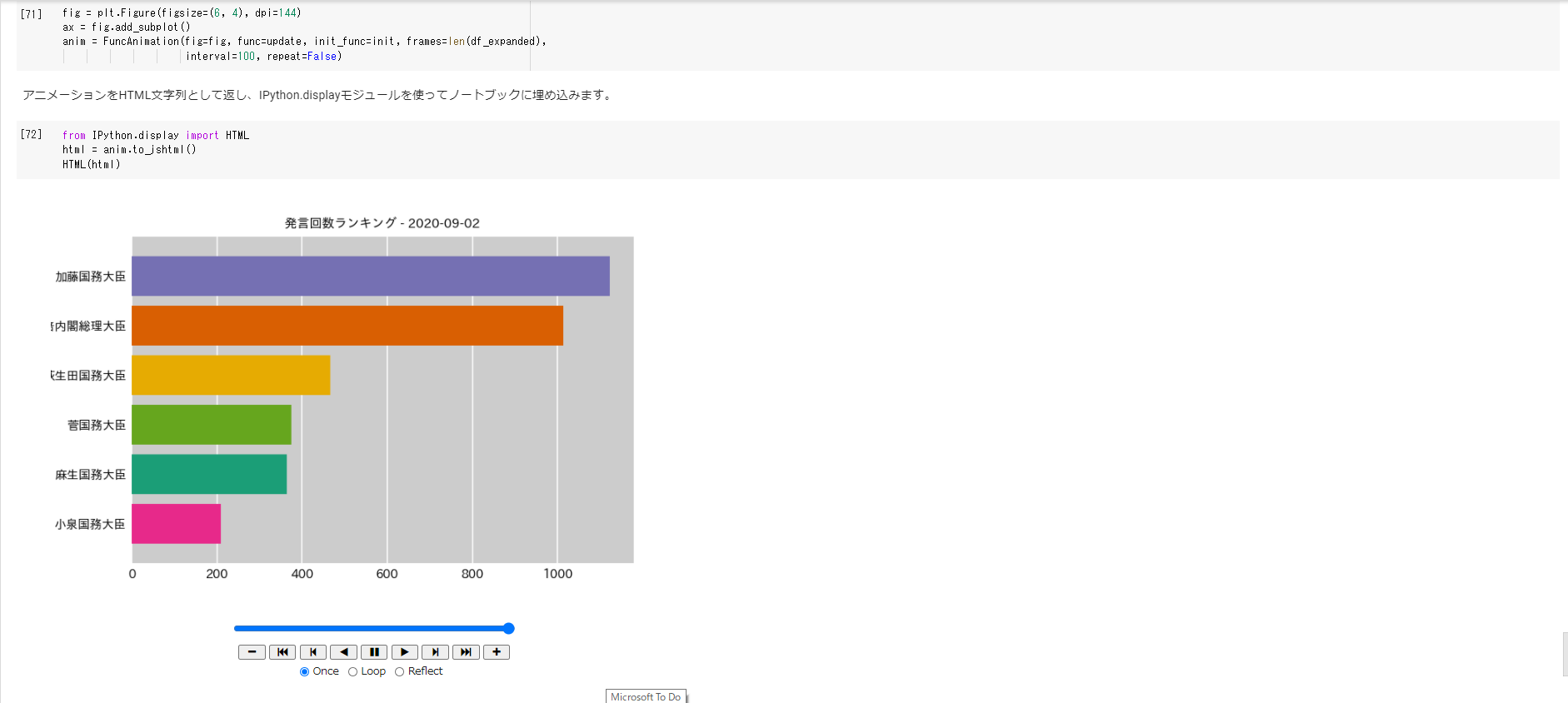 |
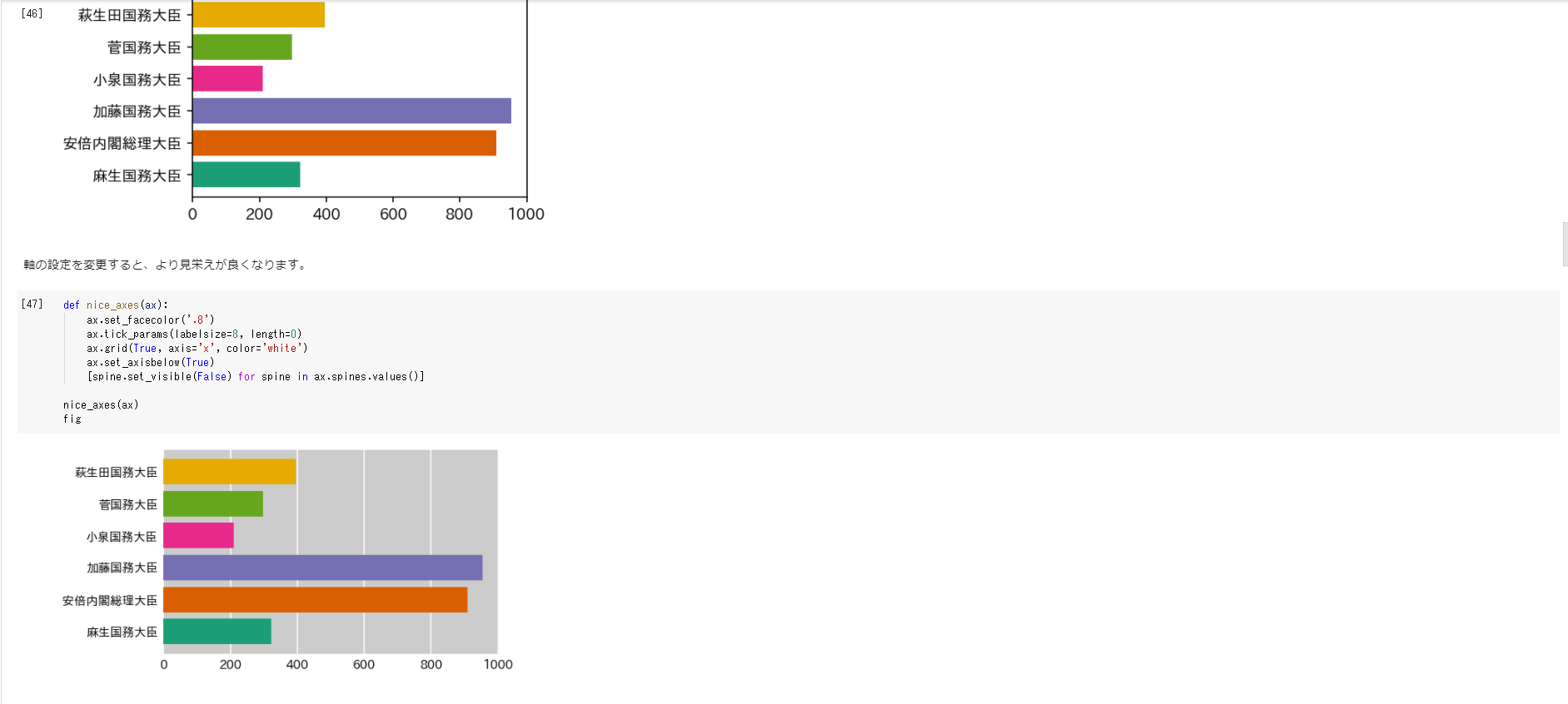
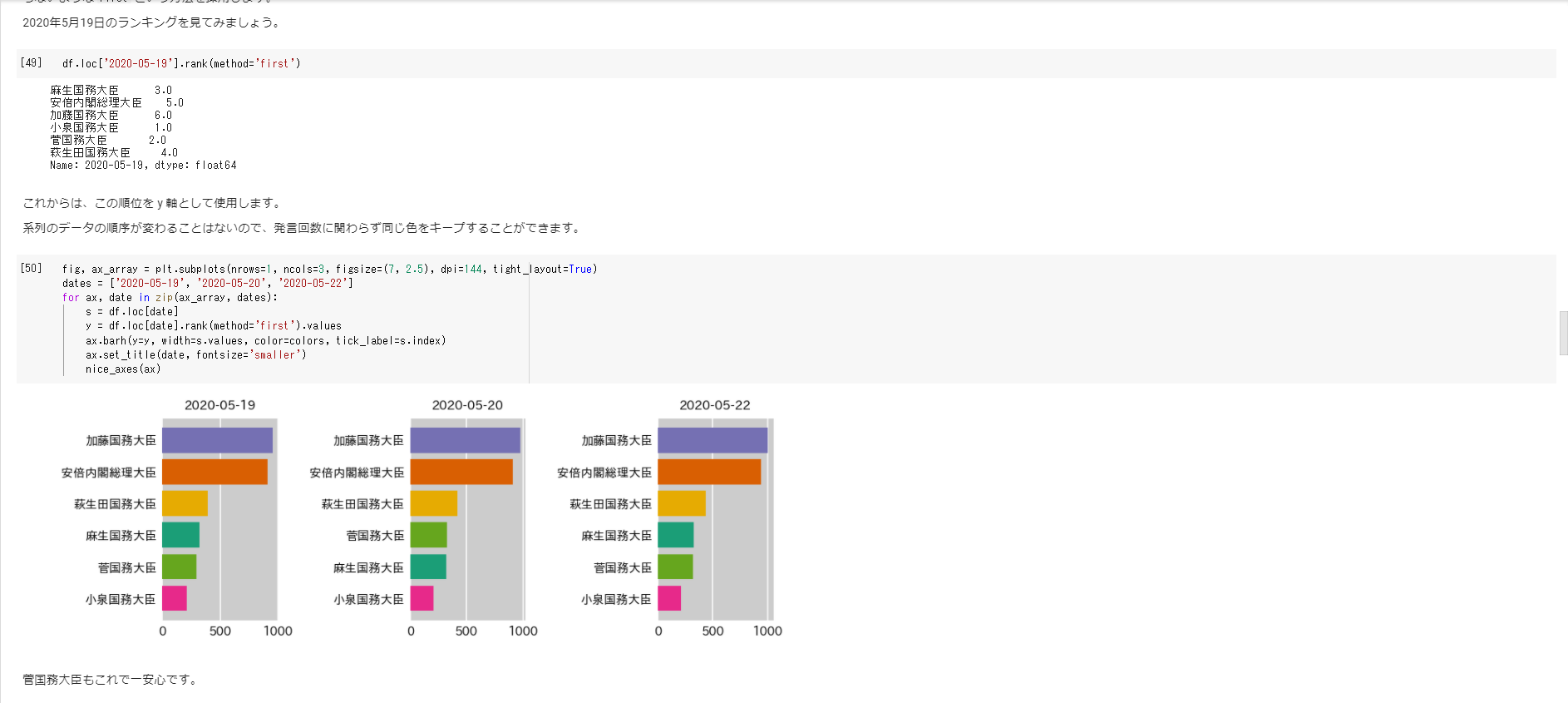
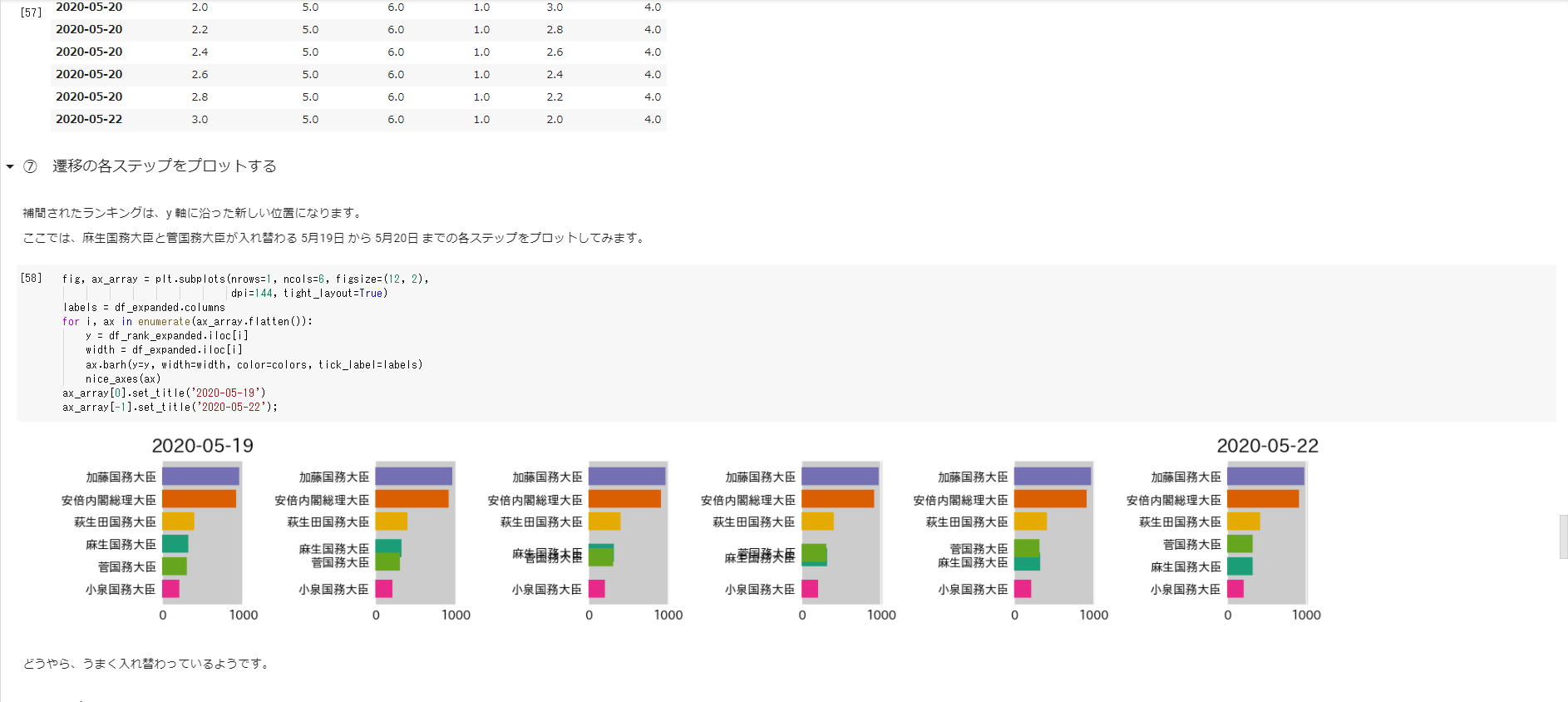
特定の日付の静止棒グラフをプロットするところから始まり、順位と色の関係を維持するためのランク付けや、スムーズな遷移を行うための補間、アニメーション作成までサポートしています。
解説を読みながらその場ですぐに実行できる形式になっているので、「ドライブにコピーを保存」してぜひ試してみてください。
4. 【アプリまでデプロイしたい人向け】Streamlit開発コース
Streamlitとは、**「データサイエンティストのためのフロントエンド」**として最近注目を集めているPythonフレームワークのことです。
「Pythonでプログラムを作ったけど、Webアプリ製作の途中で挫折した…」
という経験がある人には特にオススメしたい、Python完結の仕様になっています。
☟ Streamlitの魅力が非常に伝わってきた記事 ☟
Streamlit: データサイエンティストのためのフロントエンド|NAVITIME_Tech|note
それでは、早速バーチャートレースを描画するWebアプリをPython「のみ」で作っていきましょう。
まずは、必要なパッケージをインストールしておきます。
pip install bar-chart-race
pip install ffmpeg
pip install ffmpeg-python
pip install japanize-matplotlib
pip install matplotlib
pip install numpy
pip install pandas
pip install Pillow
pip install plotly
pip install streamlit
最後に以下のPythonコード
app.py
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import streamlit as st
import streamlit.components.v1 as components
import bar_chart_race as bcr
from PIL import Image
from io import StringIO
from datetime import datetime
from collections import defaultdict
import japanize_matplotlib
import plotly.graph_objects as go
# ロゴ
logo_image = Image.open('logo.png')
st.image(logo_image)
# メイン画像
main_image = Image.open('mainimg.png')
st.image(main_image)
"""
# 遊び方
以下の手順で、誰でも簡単に**バーチャートレース(ぬるぬる動くグラフ)**を作ることができます。
1. LINEのトーク履歴をtxtファイル形式で保存する(所要時間:1分)<方法は[コチラ]("https://appllio.com/line-talk-history-send-mail")>
2. 保存したtxtファイルをアップロードする(所要時間:30秒)
3. お好みでカスタマイズして完成!(所要時間:30秒)
# さっそく遊んでみる
LINEトーク履歴(txtファイル)を選択してください
"""
uploaded_file = st.file_uploader("""※期間が1年以上になると動画処理が終わらない可能性があります""",type="txt",)
st.markdown("**(画面左上からサイドバーを開くと自由にカスタマイズできます)**")
"""
---
"""
##### サイドバー#####
st.sidebar.markdown("# ⚙️カスタマイズオプション")
st.sidebar.markdown("### 【データフレーム】")
df_category = st.sidebar.radio("データフレームの種類を選択してください", ('標準', '累積和','標準<markdown>', '累積和<markdown>'))
st.sidebar.markdown("### 【折れ線グラフ】")
line_title = st.sidebar.text_input('表示タイトル', 'グループチャット発言回数の推移')
line_category = st.sidebar.radio("折れ線グラフの種類を選択してください", ('累積和','標準'))
st.sidebar.markdown("### 【ヒートマップ】")
heat_title = st.sidebar.text_input('表示タイトル', 'グループチャット発言回数')
heat_colorscale = st.sidebar.radio("カラースケールを選択してください", ('Defalut','Blackbody','Bluered','Blues','Earth','Electric','Greens','Greys','Hot','Jet','Picnic','Portland','Rainbow','RdBu','Reds','Viridis','YlGnBu','YlOrRd'))
st.sidebar.markdown("### 【バーチャートレース】")
bcr_title = st.sidebar.text_input('表示タイトル', 'グループチャット発言回数ランキング')
n_bars = st.sidebar.slider('ランキング上位表示人数', min_value=1,max_value=20,value=2)
st.sidebar.write('↪',n_bars, '人')
from_date = str(st.sidebar.date_input('表示期間(開始)',value=datetime(2000,1,1)))
to_date = str(st.sidebar.date_input('表示期間(終了)',value=datetime(2100,12,31)))
steps_per_period = st.sidebar.slider('ピリオド毎のステップ数', min_value=1,max_value=50,value=10)
st.sidebar.write('↪',steps_per_period)
period_length = st.sidebar.slider('1ピリオドの長さ', min_value=100,max_value=1000,value=500)
st.sidebar.write('↪',period_length)
##### サイドバー#####
if uploaded_file is not None: # ファイルがアップロードされた場合
bytes_data = uploaded_file.getvalue()
stringio = StringIO(uploaded_file.getvalue().decode("utf-8"))
tmp_names = defaultdict(int) # グループメンバーの名前を格納するリスト
stringio_list = []
# グループの人数をカウント
for i,data in enumerate(stringio):
data_list = list(map(str,data.split())) # txtファイルの各行のデータをリスト化
stringio_list.append(data_list)
if i < 2: #2行目までのタイトルと保存日時はスキップ
continue
if len(data_list) <= 2: # 空白行&日付行はスキップ
continue
name = data_list[1]
if not data_list[0][0].isdigit() or name in ['Group','You','☎']: # システムメッセージ等を除外する
continue
tmp_names[name] += 1 # メンバーリストに追加
names = [key for key in tmp_names.keys() if tmp_names[key] >= 5] # 発言回数5回以上のメンバーだけ残す
chat_count = [] # 日付ごとの発言カウントを格納するリスト
daily_data = [] # 1日のデータを格納するリスト
for i,data_list in enumerate(stringio_list):
if i < 2: #2行目までのタイトルと保存日時はスキップ
continue
if len(data_list) < 1: # 空白行はスキップ
continue
if len(data_list[0])>=10 and data_list[0][4]=='/' and data_list[0][7]=='/': # 日付の行
if daily_data:
if daily_data[0] <= to_date: # 表示期間以内
chat_count.append(daily_data) # 日付の行が来たタイミングで先日の発言回数をchat_countリストに追加
else: # 表示期間外
break
date = data_list[0].replace('/','-')[:10] # 2020/01/01 ---> 2020-01-01 (日付表示を変更)
if from_date <= date: # 表示期間内
daily_data = [date]+[0]*(len(names)) # その日のデータを格納するリストを用意 ['2020-01-01',0,0,0,...]
continue
else:
daily_data = None
if len(data_list) >= 3:
name = data_list[1]
if name in names and daily_data: # 発言表示の行の場合
daily_data[names.index(name)+1] += 1 # 発言者ごとの発言数をインクリメントする
if daily_data and daily_data[0] <= to_date:
chat_count.append(daily_data)
chat_count = np.array(chat_count) # 発言カウントリストをnumpy配列に変換
original_df = pd.DataFrame(chat_count)
original_df.columns = ['日付'] + names # 列インデックスに氏名を指定
original_df = original_df.set_index('日付') # 行インデックスに日付を指定
original_df = original_df.astype(dict(zip(names,['int64']*len(names)))) # カウントした発言数を整数(int64)型に変換
chat_count[:,1:len(names)+1] = np.cumsum(np.array(chat_count[:,1:len(names)+1],dtype=int),axis=0) # 日付以外の列に関して、縦方向に累積和を取る
df = pd.DataFrame(chat_count)
df.columns = ['日付'] + names # 列インデックスに氏名を指定
df = df.set_index('日付') # 行インデックスに日付を指定
df = df.astype(dict(zip(names,['int64']*len(names)))) # カウントした発言数を整数(int64)型に変換
# データフレーム
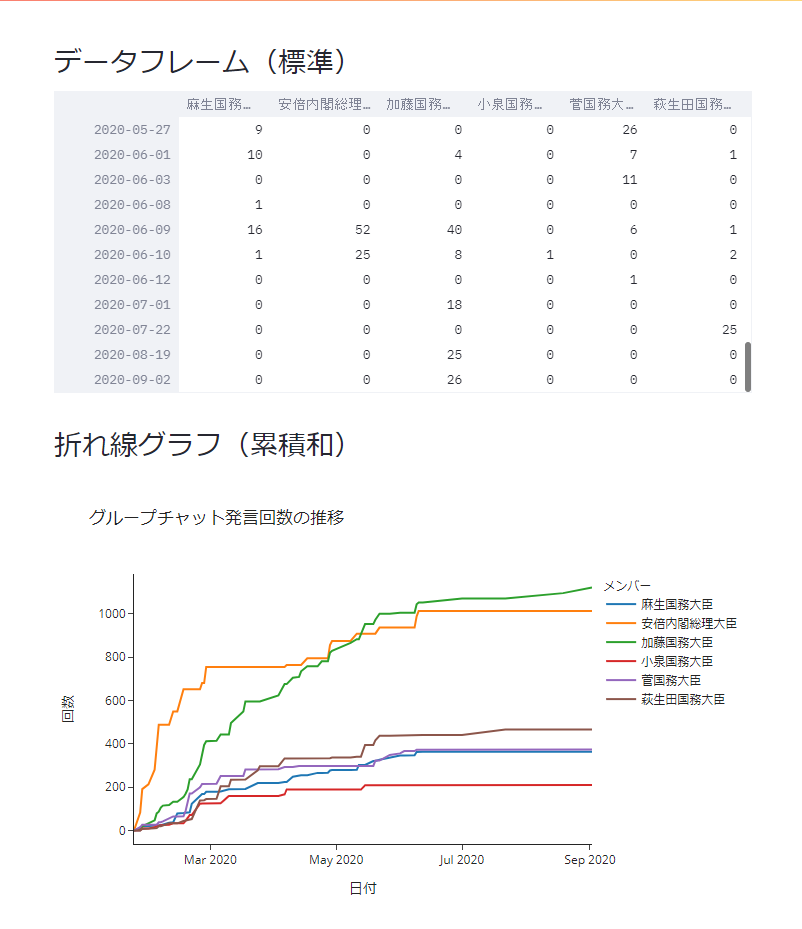
st.write(f'## データフレーム({df_category})')
if df_category == '標準':
st.write(original_df)
elif df_category == '累積和':
st.write(df)
elif df_category == '標準<markdown>':
st.markdown(original_df.to_markdown())
else:
st.markdown(df.to_markdown())
# 折れ線グラフ
st.write(f'## 折れ線グラフ({line_category})')
pd.options.plotting.backend = "plotly"
if line_category == "標準":
fig_line = original_df.plot(title=line_title, template="simple_white",
labels=dict(index="日付", value="回数", variable="メンバー"))
else:
fig_line = df.plot(title=line_title, template="simple_white",
labels=dict(index="日付", value="回数", variable="メンバー"))
st.write(fig_line)
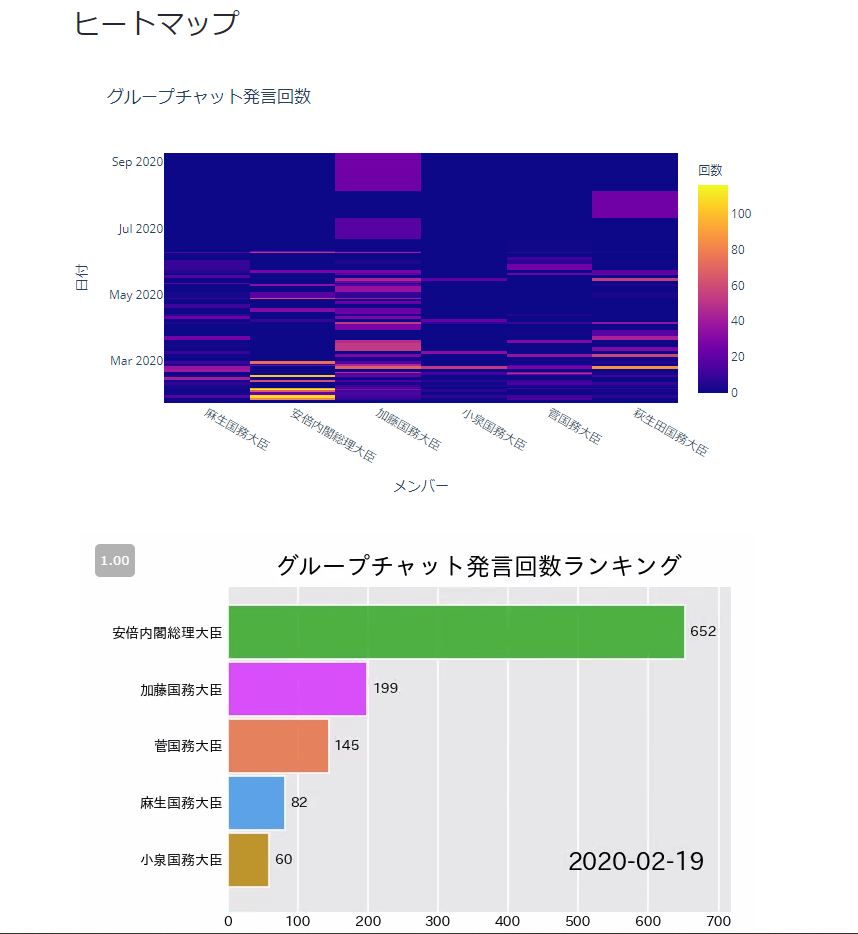
# ヒートマップ
st.write('## ヒートマップ')
if heat_colorscale == 'Defalut':
heat_colorscale = None
fig_heat = go.Figure(data=go.Heatmap(
z=original_df,
x=names,
y=list(df.index),
colorbar=dict(title='回数'),
colorscale=heat_colorscale,
hoverongaps = True)
)
fig_heat.update_xaxes(title="メンバー")
fig_heat.update_yaxes(title="日付")
fig_heat.update_layout(title=heat_title)
st.write(fig_heat)
# バーチャートレース
st.write('## バーチャートレース')
html = bcr.bar_chart_race(df,title=bcr_title,n_bars=n_bars,figsize=(4,3),steps_per_period=steps_per_period,period_length=period_length)
components.html(html._repr_html_(),width=10000,height=7500)
# 注意事項
st.markdown("※本サービスは、アップロードされたLINEトーク履歴(個人情報を含む)を使用して処理を行います。アップロードされた情報は保存されることなく処理が終了した時点で破棄されますが、心配な方は利用を控えてください。")
を用意して、コマンドで
streamlit run app.py
と実行するだけでブラウザが起動し、Webページが表示されます。
本当にあっという間です。
アプリをHerokuにデプロイしたい場合は、以下の記事を参考にしてください。
【簡単爆速第2弾】Streamlitをherokuにデプロイ - Qiita
今回用いたソースコードは、Herokuへのデプロイ方法と一緒に私のGitHub
Kitsuya0828/Grou-Cha-Darby
にアップロードしました。ご活用ください。
おわりに
4つのコースを通して、バーチャートレースを好きになっていただけたでしょうか。
ぜひ、完成したバーチャートレースを友達にも見せてあげてください!
また、最後に紹介したStreamlitというPythonフレームワークを使えば、本当に一瞬で自分の好きなWebアプリをデプロイできるので個人開発にオススメできます。
それでは、楽しいプログラミング人生をお過ごしください!
参考文献
- Creating a Bar Chart Race Animation in Python with Matplotlib | by Ted Petrou | Dunder Data | Medium ☞ 英語で書かれていますが、MatplotlibによるBar Chart Raceチュートリアルの中で1番仕組みが分かりやすいです。Matplotlib完全コースで大変参考にさせていただきました。