PythonによるWebスクレイピングの実践入門を書きたいと思います。
概論的なところは除いて、フィーリングで理解していくスタイルで行きたいと思います。
※追記
本記事は少し難しいやり方をとっていますが、学習すると言う意味ではとても価値あるものだと思います。
本記事を読み終えた後はこちらのテクニック編をご覧になるとサクッと出来たりします。
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応
やること
最終的には「1時間ごとに日本経済新聞にアクセスを行いその時の日経平均株価をcsvに記録する」
プログラムを組んでみたいと思います。
注意
注意事項です。よく読みましょう。
岡崎市立中央図書館事件(Librahack事件) - Wikipedia
Webスクレイピングの注意事項一覧
何を使うの?
言語:Python 2.7.12
ライブラリ:urllib2、BeautifulSoup、csv、datetime、time
urllib2はURLにアクセスするために必要です。
BeautifulSoupはアクセスして取得したファイルを開くxmlパーサー的なものです
csvファイルを操作する時に必要なライブラリです。
datetimeは時間を取得するためのライブラリです
ライブラリインストール
urllib2はPythonをインストールするとインストールされてまいす。
BeautifulSoupをインストールするにはpipコマンドを使います
$ pip install beautifulsoup4
手始めに日本経済新聞のページタイトルを取得してみよう!
まず手始めに日本経済新聞にPythonにてアクセスを行い、そのHTMLを取得します。
そのあとにBeautifulSoupで扱える形にし、
その扱える形からページタイトルを取得し、出力します。
また、今回はページのタイトルだけを取得するとイメージがわきにくいかもしれないので、title要素を入手し、タイトル要素の中からタイトルを取得したいと思います。
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# アクセスするURL
url = "http://www.nikkei.com/"
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(url)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# タイトル要素を取得する → <title>経済、株価、ビジネス、政治のニュース:日経電子版</title>
title_tag = soup.title
# 要素の文字列を取得する → 経済、株価、ビジネス、政治のニュース:日経電子版
title = title_tag.string
# タイトル要素を出力
print title_tag
# タイトルを文字列を出力
print title
これを実行すると下記の結果が返ってきます。
$ python getNikkeiWebPageTitle.py
<title>経済、株価、ビジネス、政治のニュース:日経電子版</title>
経済、株価、ビジネス、政治のニュース:日経電子版
ちなみに
print soup.title.string
この場合でも同様の結果を得られます。
これで大体のイメージをつかめたと思います。
実践!
今回の目標は「1時間ごとに日本経済新聞にアクセスを行いその時の日経平均株価をcsvに記録する」と言うことです。
フログラム手順を確認すると
1.日本経済新聞の日経平均株価ページにアクセスし、HTMLを取得する
3.BeautifulSoupを使い日経平均株価を取得する
4.csvに日付と時間と日経平均株価の値を1レコードで記述する
csvに関してはHeaderは使用しません。
ではではやってみましょう。
日経平均株価ページへアクセス
まず始めに日経平均株価のページへアクセスします。
URLはあらかじめブラウザから自分で調べるのがセオリーですね
調べると「日本経済新聞→マーケット→株」のページにありますね
先ほどのプラグラムを流用します
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# アクセスするURL
url = "http://www.nikkei.com/markets/kabu/"
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(url)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# タイトルを文字列を出力
print soup.title.string
これによりタイトルが出力されます。
$ python getNikkiHeikin.py
>>株式 :マーケット :日経電子版
日経平均株価取得
次に日経平均株価を取得します。
ブラウザで日本経済新聞>マーケット>株を開いてみましょう
このページの一番上から少し下のほうに日経平均株価が載っています。
これを取得するには、このデータのHTML上での位置を探る必要があります。
日経平均株価を右クリックして、「検証」を押しましょう。
するとこのような画面になると思います
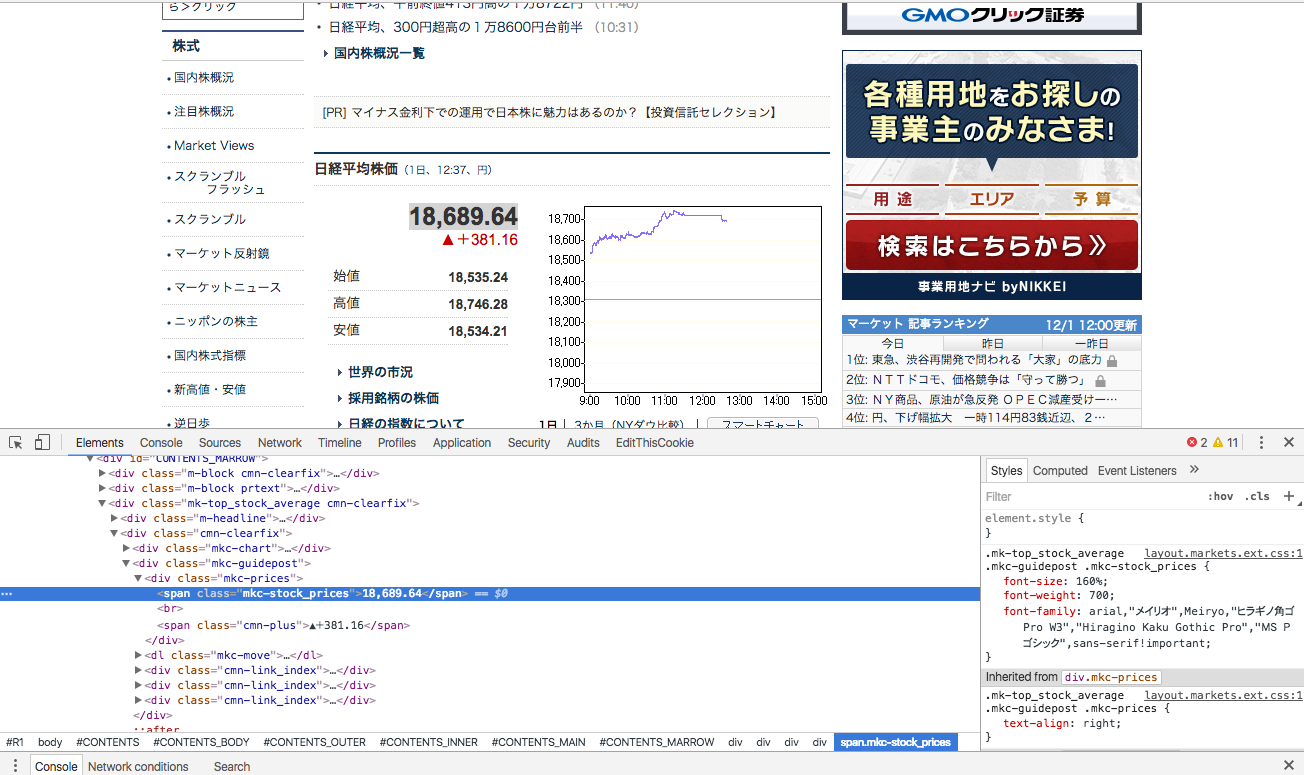
span要素でClass="mkc-stock_prices"となっています。
これで位置がわかりました。
では実際にBeautifulSoupでprintしてみましょう。
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
# アクセスするURL
url = "http://www.nikkei.com/markets/kabu/"
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(url)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# span要素全てを摘出する→全てのspan要素が配列に入ってかえされます→[<span class="m-wficon triDown"></span>, <span class="l-h...
span = soup.find_all("span")
# print時のエラーとならないように最初に宣言しておきます。
nikkei_heikin = ""
# for分で全てのspan要素の中からClass="mkc-stock_prices"となっている物を探します
for tag in span:
# classの設定がされていない要素は、tag.get("class").pop(0)を行うことのできないでエラーとなるため、tryでエラーを回避する
try:
# tagの中からclass="n"のnの文字列を摘出します。複数classが設定されている場合があるので
# get関数では配列で帰ってくる。そのため配列の関数pop(0)により、配列の一番最初を摘出する
# <span class="hoge" class="foo"> → ["hoge","foo"] → hoge
string_ = tag.get("class").pop(0)
# 摘出したclassの文字列にmkc-stock_pricesと設定されているかを調べます
if string_ in "mkc-stock_prices":
# mkc-stock_pricesが設定されているのでtagで囲まれた文字列を.stringであぶり出します
nikkei_heikin = tag.string
# 摘出が完了したのでfor分を抜けます
break
except:
# パス→何も処理を行わない
pass
# 摘出した日経平均株価を出力します。
print nikkei_heikin
結果
$ python getNikeiHeikin.py
>>18,513.12
コードの解説は基本的にコメントにて挿入しています
流れを簡単に表すと
1.日本経済新聞>マーケット>株にアクセスをし、HTMLを拾ってくる
2.日経平均株価はspan要素で囲ってあるので、HTML内部全てのspan要素を摘出する
3.span要素に一つ一つをfor分で"mkc-stock_prices"がclassに設定されているかを確かめます
4.設定されているclass見つかったら.stringで値を取得し、for分を終了
5.取得した値をプリントする
って流れです。
このプログラムの流れはだいたいの場面で使用することができます
メリットとしては、そこまで難しくはなく、だいたいの場面で応用が利くことです
注意点としはspan要素から別の要素に変わったり、classの内容が変わってしまうと出力することができません。
繰り返しとcsv出力
この結果をcsvに出力し、一時間ごとに繰り返していきます
# coding: UTF-8
import urllib2
from bs4 import BeautifulSoup
from datetime import datetime
import csv
import time
time_flag = True
# 永久に実行させます
while True:
# 時間が59分以外の場合は58秒間時間を待機する
if datetime.now().minute != 59:
# 59分ではないので1分(58秒)間待機します(誤差がないとは言い切れないので58秒です)
time.sleep(58)
continue
# csvを追記モードで開きます→ここでcsvを開くのはファイルが大きくなった時にcsvを開くのに時間がかかるためです
f = open('nikkei_heikin.csv', 'a')
writer = csv.writer(f, lineterminator='\n')
# 59分になりましたが正確な時間に測定をするために秒間隔で59秒になるまで抜け出せません
while datetime.now().second != 59:
# 00秒ではないので1秒待機
time.sleep(1)
# 処理が早く終わり二回繰り返してしまうのでここで一秒間待機します
time.sleep(1)
# csvに記述するレコードを作成します
csv_list = []
# 現在の時刻を年、月、日、時、分、秒で取得します
time_ = datetime.now().strftime("%Y/%m/%d %H:%M:%S")
# 1カラム目に時間を挿入します
csv_list.append(time_)
# アクセスするURL
url = "http://www.nikkei.com/markets/kabu/"
# URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
html = urllib2.urlopen(url)
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# span要素全てを摘出する→全てのspan要素が配列に入ってかえされます→[<span class="m-wficon triDown"></span>, <span class="l-h...
span = soup.find_all("span")
# print時のエラーとならないように最初に宣言しておきます。
nikkei_heikin = ""
# for分で全てのspan要素の中からClass="mkc-stock_prices"となっている物を探します
for tag in span:
# classの設定がされていない要素は、tag.get("class").pop(0)を行うことのできないでエラーとなるため、tryでエラーを回避する
try:
# tagの中からclass="n"のnの文字列を摘出します。複数classが設定されている場合があるので
# get関数では配列で帰ってくる。そのため配列の関数pop(0)により、配列の一番最初を摘出する
# <span class="hoge" class="foo"> → ["hoge","foo"] → hoge
string_ = tag.get("class").pop(0)
# 摘出したclassの文字列にmkc-stock_pricesと設定されているかを調べます
if string_ in "mkc-stock_prices":
# mkc-stock_pricesが設定されているのでtagで囲まれた文字列を.stringであぶり出します
nikkei_heikin = tag.string
# 摘出が完了したのでfor分を抜けます
break
except:
# パス→何も処理を行わない
pass
# 摘出した日経平均株価を時間とともに出力します。
print time_, nikkei_heikin
# 2カラム目に日経平均を記録します
csv_list.append(nikkei_heikin)
# csvに追記します
writer.writerow(csv_list)
# ファイル破損防止のために閉じます
f.close()
流れ的に言えば
1.n時00秒になるまで待機
2.csvをオープン
3.レコードを作成
4.日経平均株価を取得
5.レコードに追加
6.レコードをcsvに書き込み
ってなわけです
これを実行し続けると一時間に一回アクセスを行い日経平均を取得し、記録してくれます。
これを応用すればなんだってできます
たとえば、某南米の長い川でのセール時でのカート高速追加(俗に言うスクリプト勢)なんてできたり。。。
あまりお勧めはしませんが
では!
こちらもどうぞ
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応
【毎秒1万リクエスト!?】Go言語で始める爆速Webスクレイピング【Golang】
【初心者向け】Re:ゼロから始める遺伝的アルゴリズム【人工知能】