NVIDIAのサーバー用(旧NVIDIA Tesla)
単位はTFLOPS(全て密行列の行列積)。
密行列の行列積の理論上のパフォーマンスで統一しています。最近NVIDIAは疎行列のパフォーマンスで表示しているのですが(with sparsityと書いてあります)、このページは僕が間違えていない限り密行列で統一しています。
あくまで積和演算の装置がどれくらい載っているかという理論値であり、実際はこの性能は100%は出ないですし、ディープラーニングの性能と強い相関関係はありますが、ディープラーニングのベンチマークも見るべきです。
2019年よりサーバー用はTeslaという名称は消えました。NVIDIA Tesla V100 → NVIDIA V100。
Feynman
Rubin Ultra の後継。2028年発表予定。
Rubin Ultra
| 型番不明 | |
|---|---|
| FP4 | 100,000 (疎行列?) |
| メモリ | 1TB |
| 発表日 | 2027年予定 |
Rubin
| 型番不明 | |
|---|---|
| FP4 | 50,000 (疎行列?) |
| メモリ | 288GB |
| 発表日 | 2026年予定 |
CPUの名称はVeraで、88コア176スレッド。ムーアの法則から考えてFP4の密行列は25,000TFLOPSではないかと思われます。GeForce RTX 60シリーズに使用されると予想されます
出典
Blackwell Ultra
| GB300 | B300 | GB300A | B300A | |
|---|---|---|---|---|
| FP4 | 15,000*4 | 13,500? | ||
| FP6 FP8 INT8 |
||||
| FP16 BF16 |
||||
| TF32 | ||||
| FP32 | ||||
| FP64 | ||||
| メモリ | 288GB*4 | 288GB | 144GB | 144GB |
| メモリ帯域 | 12TB/s? | |||
| 発表日 | 2025年3月 | 2025年3月 | 2025年予定 | 2025年予定 |
GB300はGPU4個・CPU2個を1セットにラックに18個搭載。CPUは72コア。
B300はB200の計算速度およびメモリ量が1.5倍。
出典
- Designed for AI Reasoning Performance & Efficiency | NVIDIA GB300 NVL72
- NVIDIAのBlackwell Ultraが「B300シリーズ」に名称を変更、TrendForce報道 | TECH+(テックプラス)
- NVIDIA GB300 "Blackwell Ultra" Will Feature 288 GB HBM3E Memory, 1400 W TDP | TechPowerUp
Blackwell
| GB200 | B200 | B100 | GeForce RTX 5090 |
|
|---|---|---|---|---|
| FP4 | 10,000*2 | 9,000 | 7,000 | 1,676 |
| FP6 FP8 INT8 |
5,000*2 | 4,500 | 3,500 | 838 |
| FP16 BF16 |
2,500*2 | 2,250 | 1,750 | 419 |
| TF32 | 1,250*2 | 1,125 | 875 | 105 |
| FP32 | 45*2 | 40 | 30 | 105 |
| FP64 | 45*2 | 40 | 30 | 1.637 |
| メモリ | 192GB*2 | 192GB | 192GB | 32GB |
| メモリ帯域 | 8TB/s*2 | 8TB/s | 8TB/s | 1.792TB/s |
| 発表日 | 2024年3月 | 2024年3月 | 2024年3月 | 2025年1月 |
新たに FP4 と FP6 に対応。疎行列は密行列の倍の性能で動作します。
GB200 は GPU B200 2つと CPU 1つ搭載。
GB200の対応クラウド
- EC2
- Azure
- Oracle Cloud Infrastructure
- Lambda
B200の対応クラウド
- EC2
- Google A4
- Azure
- Oracle Cloud Infrastructure
- Applied Digital
- CoreWeave
- Crusoe
- IBM Cloud
- Lambda
- さくらのクラウド
B100の対応クラウド
- Lambda
出典
- https://nvidianews.nvidia.com/news/nvidia-blackwell-platform-arrives-to-power-a-new-era-of-computing
- https://www.tomshardware.com/pc-components/gpus/nvidias-next-gen-ai-gpu-revealed-blackwell-b200-gpu-delivers-up-to-20-petaflops-of-compute-and-massive-improvements-over-hopper-h100
- https://www.theregister.com/2024/03/18/nvidia_turns_up_the_ai/
- 【特集】GeForce RTX 5090と4090のスペック詳細を比較 - PC Watch
Ada Lovelace
| L40S | L40 | L4 | GeForce RTX 4090 |
|
|---|---|---|---|---|
| INT8 FP8 |
733 | 362 | 243 | 660.6 |
| FP16 BF16 |
362.05 | 181.05 | 121 | 165.2 |
| TF32 | 183 | 90.5 | 60 | 82.6 |
| FP32 | 91.6 | 90.5 | 30.3 | 82.6 |
| メモリ | 48GB | 48GB | 24GB | 24GB |
| メモリ帯域 | 864GB/s | 864GB/s | 300GB/s | 1008GB/s |
| 発表日 | 2023年8月 | 2022年10月 | 2023年3月 | 2022年9月 |
L40Sの対応クラウド
- EC2 g6e
- Oracle Cloud Infrastructure
- Vultr
L4の対応クラウド
- EC2 g6
- Google g2
- ConoHa VPS
廉価なGPUの系列はT4→A10→L4になっています。
出典
- https://images.nvidia.com/content/Solutions/data-center/vgpu-L40-datasheet.pdf
- https://nvdam.widen.net/s/rvq98gbwsw/l4-datasheet-2595652
- https://images.nvidia.com/aem-dam/Solutions/geforce/ada/nvidia-ada-gpu-architecture.pdf
- https://cloud.google.com/blog/products/compute/introducing-g2-vms-with-nvidia-l4-gpus
Hopper
| H200 SXM |
H100 SXM |
H100 PCIe |
H800 SXM |
H20 | |
|---|---|---|---|---|---|
| INT8 FP8 |
1,979 | 1,979 | 1,513 | 1,979 | 148 |
| FP16 BF16 |
989 | 989 | 756 | 989 | 74 |
| TF32 | 495 | 495 | 378 | 495 | 37 |
| FP32 | 67 | 67 | 51 | 67 | 44 |
| FP64 | 67 | 67 | 51 | 1 | 1 |
| メモリ | 141GB | 80GB | 80GB | 80GB | 96GB |
| メモリ帯域 | 4.8TB/s | 3.35TB/s | 2TB/s | 3.35TB/s | 4TB/s |
| 発売日 | 2024年 Q2 |
2022年 Q3 |
2022年 Q3 |
2023年 3月 |
2023年 11月 |
新たに FP8 に対応。E5M2(指数部5ビット、仮数部2ビット)、E4M3(指数部4ビット、仮数部3ビット)に対応。Ampere 同様、疎行列は密行列の倍の性能で動作します。
A100→H100が2年半で3倍の性能向上なので、10年で100倍のムーアの法則は2022年でも健在ですね。
GH200の対応クラウド
- Lambda Labs
- Vultr
H100・H200の対応クラウド(下記、概ねH100とH200の両方に対応予定)
- EC2 p5e (H200), p5 (H100)
- Google A3 Ultra (H200), A3 (H100)
- Azure ND H200 v5, ND H100 v5
- Oracle Cloud
- CoreWeave
- Lambda Labs
- Vultr
- さくらのクラウド
- GMO GPU クラウド、ConoHa VPS
- RUTILEA
Google が1台に16GPU、AWS と Azure ND が1台に8GPU。マシン間の通信回線帯域は AWS と Azure ND が 3.2 Tbps、Google が 0.2 Tbpsで、AWS と Azure ND は低遅延回線。各社ともマシン内の GPU 間通信は NVLink 。
また、Grace CPU と Hopper GPU を一体化した Grace Hopper も発売。CPU と GPU 間の通信速度が900GB/sになり、PCIe Gen5x16 より7倍高速。CPU は ARM Neoverse V2 を72コア。
H800とH20は中国専用で、H800はH100のFP64を1TFLOPSに変えたもののようです。米国政府の輸出規制の回避用です。H800を米国政府が禁止して、H20が作られ、H20も2024年9月に米国政府が禁止すると圧力をかけて受注を止めたみたいですが、米、NVIDIA半導体の対中規制強化検討 DeepSeek問題で - 日本経済新聞によると2025年1月29日の時点では完全な禁止はこれからのようです。2024 NVIDIA Corporation Annual Review p.79によると、2021年度は台湾と中国が最大の出荷相手国でした。
出典
Ampere
| A100 | A40 | A30 | A16 | A10 | A2 | GeForce RTX 3090 |
|
|---|---|---|---|---|---|---|---|
| INT4 | 1248 | 599 | 660 | 71.8 * 4 | 500 | 72 | 570 |
| INT8 | 624 | 299.3 | 330 | 35.9 * 4 | 250 | 36 | 285 |
| FP16 BF16 |
312 | 149.7 | 165 | 17.9 * 4 | 125 | 18 | 142 |
| TF32 | 156 | 74.8 | 82 | 9 * 4 | 62.5 | 9 | 71 |
| FP32 | 19.5 | 37.4 | 10.3 | 4.5 * 4 | 31.2 | 4.5 | 36 |
| FP64 | 19.5 | 10.3 | 1.1 | ||||
| CUDA コア数 |
6912 | 10752 | 3584 | 1280 * 4 | 9216 | 1280 | 10496 |
| Tensor コア数 |
432 | 336 | 224 | 40 * 4 | 288 | 40 | 328 |
| MHz | 1410 | 1740 | 1440 | 1695 | 1695 | 1770 | 1695 |
| メモリ | 40GB 80GB |
48GB | 24GB | 16GB * 4 | 24GB | 16GB | 24GB |
| メモリ帯域 GB/s |
1555 2039 |
696 | 933 | 200 * 4 | 600 | 200 | 936 |
| 発表年 | 2020/5 | 2020/10 | 2021/4 | 2021/4 | 2021/4 | 2021/11 | 2020/9 |
大規模言語モデルがブームとなり、搭載メモリ量が16GB→80GBと増えました。
TF32という19ビットで表現する浮動小数点数を新設。指数部はFP32やbfloat16と同じ8ビットで、仮数部はFP16と同じ10ビット。https://blogs.nvidia.com/blog/2020/05/14/tensorfloat-32-precision-format/ 。bfloat16もサポート。INT4もINT8の倍の性能で対応。疎行列の高速化にも対応し、密行列の倍の性能で動作します。
A100の対応クラウド
- EC2 p4d
- Google A2
- Azure NC A100 v4
- Azure ND A100 v4
- Azure NDm A100 v4
- Oracle Cloud Infrastructure
- CoreWeave
- Lambda Labs
- Vultr
- Alibaba gn7
- Alibaba gn7e
- GPUSOROBAN(代理店のWebARENA IndigoGPUやraytrek cloudなど)
クラウドは Google が1台に16GPU、AWS と Azure ND が1台に8GPU。マシン間の通信回線帯域は AWS が 0.4 Tbps、Google が 0.1 Tbps、Azure ND が 1.6 Tbps で、AWS と Azure ND は低遅延回線。各社ともマシン内の GPU 間通信は NVLink 。
A40の対応クラウド
- CoreWeave
- Vultr
A30の対応クラウド
- Alibaba gn7s
A16の対応クラウド
- Vultr
A10の対応クラウド
- EC2 g5
- Azure NVads A10 v5
- Oracle Cloud Infrastructure
- Lambda Labs
- Alibaba gn7i
- Alibaba vgn7i-vws
- Alibaba sgn7i-vws
出典
Turing
| T4 | GeForce RTX 2080 Ti |
|
|---|---|---|
| INT4 | 260 | 432 |
| INT8 | 130 | 215 |
| FP16 | 65 | 108 |
| FP32 | 8.1 | 11.8 |
| CUDA コア数 |
2560 | 4352 |
| Tensor コア数 |
320 | 544 |
| MHz | 1582 | 1350 |
| メモリ | 16GB | 11GB |
| メモリ帯域 GB/s |
320 | 616 |
| 発表年 | 2018/9 | 2018/8 |
INT4もINT8の倍の性能で対応。
T4 の対応クラウド
- EC2 g4dn
- Google T4
- Azure NCasT4 v3
- Alibaba gn6i
- Alibaba vgn6i
出典
Volta
| V100 (NVLink) |
V100 (PCIe) |
|
|---|---|---|
| FP16 | 119.19 | 112.23 |
| FP32 INT32 |
14.90 | 14.02 |
| FP64 | 7.45 | 7.01 |
| CUDA コア数 |
5120 | 5120 |
| Tensor コア数 |
640 | 640 |
| MHz | 1455 | 1370 |
| メモリ | 16GB | 16GB |
| メモリ帯域 GB/s |
900 | 900 |
| 発表年 | 2017/5 | 2017/7 |
Tensor Core を搭載し、入力FP16・出力FP32の4行4列の行列積が出来るようになり、かつ、高速化。INT32対応。
V100 (NVLink) の対応クラウド
- EC2 p3
- Google V100
- Azure NCv3
- Azure NDv2
- Oracle Cloud Infrastructure
- CoreWeave
- Lambda Labs
- Alibaba gn6v
- Alibaba gn6e
- さくらのクラウド
出典
Pascal
| P100 (NVLink) |
P100 (PCIe) |
P40 | P4 | GeForce GTX 1080 Ti |
|
|---|---|---|---|---|---|
| INT8 | x | x | 47.032 | 21.770 | x |
| FP16 | 21.205 | 18.636 | x | x | 0.177 |
| FP32 | 10.609 | 9.318 | 11.758 | 5.443 | 11.340 |
| FP64 | 5.304 | 4.659 | 0.367 | 0.170 | 0.354 |
| コア数 | 3584 | 3584 | 3840 | 2560 | 3584 |
| MHz | 1480 | 1300 | 1531 | 1063 | 1582 |
| メモリ | 16GB | 16GB | 24GB | 8GB | 11GB |
| メモリ帯域 GB/s |
720 | 720 | 345.6 | 192 | 484 |
| 発表年 | 2016/4 | 2016/4 | 2016/9 | 2016/9 | 2017/3 |
一部 INT8 対応。
P100 (PCIe) の対応クラウド
- Google P100
- Azure NCv2
- Oracle Cloud Infrastructure
- Alibaba gn5
- さくらのクラウド
P40 の対応クラウド
- Azure ND
- さくらのクラウド
P4 の対応クラウド
- Google P4
- Alibaba gn5i
Maxwell
| M60 | M40 | M10 | M6 | M4 | GeForce GTX 980 Ti |
|
|---|---|---|---|---|---|---|
| FP16 | 9.667 * 2 | 13.689 | 2.644 * 4 | 6.457 | 4.391 | x |
| FP32 | 4.833 * 2 | 6.844 | 1.322 * 4 | 3.229 | 2.195 | 6.060 |
| FP64 | 0.156 * 2 | 0.219 | 0.041 * 4 | 0.100 | 0.069 | 0.189 |
| コア数 | 2048 * 2 | 3072 | 640 * 4 | 1536 | 1024 | 2816 |
| MHz | 1180 | 1114 | 1033 | 1051 | 1072 | 1076 |
| メモリ | 8GB * 2 | 24GB | 8GB * 4 | 8GB | 4GB | 6GB |
| メモリ帯域 GB/s |
160 * 2 | 288 | 83 * 4 | 147.2 | 88 | 336 |
| 発表年 | 2015/8 | 2015/11 | 2016/5 | 2015/8 | 2015/11 | 2015/6 |
FP16 対応。
M60 対応クラウド
- EC2 g3
- Azure NV
M40 対応クラウド
- Alibaba gn4
Kepler
| K80 | K40 | GRID K520 |
GRID K340 |
K20 | K10 | |
|---|---|---|---|---|---|---|
| FP32 | 4.368 * 2 | 5.040 | 2.458 * 2 | 0.730 * 4 | 3.524 | 2.289 * 2 |
| FP64 | 1.456 * 2 | 1.680 | 0.096 * 2 | 1.175 | 0.763 * 2 | |
| コア数 | 2496 * 2 | 2880 | 1536 * 2 | 384 * 4 | 2496 | 1536 * 2 |
| MHz | 875 | 875 | 800 | 950 | 706 | 745 |
| メモリ | 12GB * 2 | 12GB | 4GB * 2 | 1GB * 4 | 5GB | 4GB * 2 |
| メモリ帯域 GB/s |
240 * 2 | 288 | 160 * 2 | 28.8 * 4 | 208 | 160 * 2 |
| 発表年 | 2014/11 | 2013/10 | 2013/7 | 2013/7 | 2012/11 | 2012/5 |
2012年からディープラーニングのブームが始まります。
K80 対応クラウド
- EC2 p2
- Azure NC
- Google K80
- Oracle OCSG
GRID K520 対応クラウド
- EC2 g2
Fermi
| M2090 | M2070 M2050 |
|
|---|---|---|
| FP32 | 1.331 | 1.030 |
| FP64 | 0.665 | 0.515 |
| コア数 | 512 | 448 |
| MHz | 1300 | 1150 |
| メモリ | 6GB | 6GB 3GB |
| 発表年 | 2011/5 | 2011/5 |
M2050 対応クラウド
- EC2 cg1
FP32 : FP64
- Ampere(CUDAコア) = 2 : 1
- Volta = 2 : 1
- Pascal(P100) = 2 : 1
- Pascal(P100以外) = 16 : 1
- Maxwell = 32 : 1
- Kepler = 3 : 1
- Fermi = 2 : 1
NVIDIA DGX Spark
NVIDIA DGX Spark は NVIDIA Jetson の派生のように見えます。内蔵GPU方式。
Blackwell
| 項目 | 値 |
|---|---|
| CPU | ARM 20コア 10 Cortex-X925 + 10 Cortex-A725 |
| GPU INT8 密行列 | 250 TOPS |
| NPU | 非搭載のようです |
| メモリ | 128 GB LPDDR5X-8533 4チャンネル |
| メモリ帯域 | 273 GB/s |
| ストレージ | 4 TB |
| 電力 | 170 W |
| 発表日 | 2025年1月6日 |
| 価格 | $3,999 |
性能は GeForce RTX 5070 相当です。ただし、GeForce RTX 5090 ですらメモリ32GBなのに対して、内蔵GPU方式なので、メモリが128GBもあるので、大規模言語モデルにおいて、パラメータ数が多いモデルを実行可能である、という考えのようです。
IntelのCPUはパソコン用のメモリが2チャンネル、サーバー用は最大12チャンネルですが、4チャンネルとパソコン用よりはメモリ帯域が大きいですが、GeForce RTX 5070のメモリ帯域は672 GB/sなので、それよりは少ないです。Intel Xeon 6503P-Bが12コア24スレッド・メモリ4チャンネル・TDP 110 Wなので、このあたりに対応するのでしょう。
NVIDIA DGX Sparkの当初の名称はNVIDIA Project DIGITS。
出典:
- A Grace Blackwell AI supercomputer on your desk | NVIDIA DGX Spark
- 米NVIDIA、“AIネイティブ”なデスクトップPC「DGX」発売 予約受付も開始 2999ドルから - ITmedia NEWS
NVIDIA Jetson
NVIDIA Jetson は車載以外の組み込み用です。GPUとNPU内蔵方式です。
Jetson Orin
| コア数 | MHz | INT8 | FP16 | FP32 | メモリ 帯域 |
電力 (W) |
||
|---|---|---|---|---|---|---|---|---|
| Jetson AGX Orin 64GB |
GPU DLA |
2048+64 2 |
1300 1600 |
85 52 |
43 26 |
5.3 x |
204 | 15-60 |
| Jetson AGX Orin 32GB |
GPU DLA |
1792+56 2 |
930 1400 |
54 46 |
27 23 |
3.8 x |
204 | 15-40 |
| Jetson Orin NX 16GB |
GPU DLA |
1024+32 2 |
1173 1230 |
38 40 |
19 20 |
2.4 x |
102 | 10-40 |
| Jetson Orin NX 8GB |
GPU DLA |
1024+32 1 |
1173 1230 |
38 20 |
19 10 |
2.4 x |
102 | 10-40 |
| Jetson Orin Nano 8GB |
GPU | 1024+32 | 1020 | 33 | 17 | 2.1 | 68 | 7-25 |
| Jetson Orin Nano 4GB |
GPU | 512+16 | 1020 | 17 | 8 | 1.0 | 34 | 7-25 |
Jetson Orin は Ampere マイクロアーキテクチャ。Ampereなので疎行列が扱えるようになり、疎行列は密行列の2倍の性能です。上記の表は密行列です。ホームページの「詳細を見る」をクリックすると出てきます。
Jetson AGX Orin 開発者キットは2022年3月販売開始。Jetson Orin Nano 開発者キットは2023年4月販売開始で、25Wを可能にして半額にした後継のJetson Orin Nano Super 開発者キットは2024年12月販売開始。
出典
- 次世代ロボティクス向け Jetson AGX Orin | NVIDIA
- NVIDIA Jetson Orin Nano Developer Kit Gets a “Super” Boost | NVIDIA Technical Blog
Jetson Xavier
| コア数 | MHz | INT8 | FP16 | FP32 | メモリ 帯域 |
発表年 | ||
|---|---|---|---|---|---|---|---|---|
| Jetson AGX Xavier |
GPU DLA |
512+64 2 |
1377 1400 |
22 10 |
11 5 |
1.4 x |
137 | 2018/6 |
| Jetson Xavier NX |
GPU DLA |
384+48 2 |
1100 1100 |
13 8 |
6 4 |
0.8 x |
51 | 2019/11 |
Jetson Xavier は Volta マイクロアーキテクチャ。DLA は Deep Learning Accelerator の略。
Jetson AGX Xavier は Tesla V100 の 1/10 サイズの GPU。Tensor Core は FP16 に加えて INT8 も対応。DLA を搭載。今までは Tegra は Tesla のムーアの法則7年遅れだったが30Wにして6年遅れにターゲット変更。組み込みレベルからノートパソコンレベルへ変更。ただし10Wや15Wモードも搭載。NVIDIA Jetson AGX Xavier Delivers 32 TeraOps for New Era of AI in Robotics | NVIDIA Technical Blog
Jetson Xavier NX は 10W と 15W があり、上記は15W版。NVIDIA Jetson Xavier NX Developer Kit では Raspberry Pi 用のカメラが2つ接続できる。M.2 NVMe SSD が搭載可能。10W の方はファンレスで動きそう(推測)。Introducing Jetson Xavier NX, the World’s Smallest AI Supercomputer | NVIDIA Technical Blog
古い世代
| コア数 | MHz | INT8 | FP16 | FP32 | メモリ 帯域 |
発表年 | ||
|---|---|---|---|---|---|---|---|---|
| Jetson TX2 | GPU | 256 | 1302 | x | 1.333 | 0.666 | 58.3 | 2016/8 |
| Jetson TX1 | GPU | 256 | 998 | x | 1.024 | 0.512 | 25.6 | 2015/1 |
| Jetson Nano | GPU | 128 | 921 | x | 0.472 | 0.236 | 25.6 | 2019/3 |
| Jetson TK1 | GPU | 192 | 950 | x | x | 0.327 | 14.9 | 2014/1 |
Jetson TX2 は Pascal マイクロアーキテクチャ。
Jetson TX1 と Nano は Maxwell マイクロアーキテクチャ。Jetson Nano は NVIDIA はリアルタイム画像認識が出来る最低ラインだとしています。Jetson Nano Brings AI Computing to Everyone | NVIDIA Technical Blog
Jetson TK1 は Kepler マイクロアーキテクチャ。
NVIDIA DRIVE
NVIDIA DRIVEは自動運転車用です。DLA (Deep Learning Accelerator) とはNPUの事です。
NVIDIA DRIVEを触ったことが無い人間の感想ですが、運転中の自動車はコンセントにつながっていなく、本当に"モバイル"ですし、限られた電力で大量の計算をこなさないといけないです。エネルギー効率の面では、dGPU < iGPU < NPUですが、NVIDIAの売上のほとんどはdGPUであり、NVIDIAのiGPUとNPUはあまり使われていません。NVIDIA DRIVEの歴史を見ると、dGPUを使おうとしたけど、電力不足でiGPUになっていった経緯を感じます。NPUが広く使われているのは同じ"モバイル"のスマートフォンですが、スマートフォン用のSoCメーカーのNPUの方が自動運転には有利なのではないかと思いました。ただし、NPUは出来ることを制限することでエネルギー効率を高めていますが、結果として、動かしたいモデルが動くのかどうかという問題も抱えています。
Blackwell
| INT8 | 発売日 | |
|---|---|---|
| DRIVE AGX Thor | 合計500 | 2025年予定 |
NVIDIAの発表は疎行列ですが、上記の表は密行列です。当初は1000TOPSと言っていたのですが、500TOPSに変更になっています。詳細は未発表ですが、NVIDIA DGX SparkのBlackwell版の250TOPSの内蔵GPUを2つ搭載すると500TOPSになります。
出典
Ampere
| INT8 (iGPU) |
INT8 (DLA) |
電力 | 発売日 | |
|---|---|---|---|---|
| DRIVE AGX Orin | 83.5 | 43.5 | 100W | 2022年 |
NVIDIAの発表は疎行列ですが、上記の表は密行列です。DRIVE AGX OrinはJetson AGX Orinを1つ搭載。
出典
VoltaとTuring
| INT8 (dGPU) |
INT8 (iGPU) |
INT8 (DLA) |
電力 | 発表日 | |
|---|---|---|---|---|---|
| DRIVE AGX Xavier | x | 20 | 10 | 30W | 2017年 |
| DRIVE AGX Pegasus | 130 * 2 | 20 * 2 | 10 * 2 | 500W | 2017年 |
DRIVE AGX XavierとDRIVE AGX Pegasusがあります。Jetson AGX Xavier相当。DRIVE AGX PegasusはNVIDIA T4相当のディスクリートGPUを搭載。DRIVE AGX Pegasusは2システム搭載。2017年発表。
Pascal
NVIDIA Drive PX 2 AutoCruise には NVIDIA Tegra X2 に加えて 1.25 TFLOPS (4GB GDDR5, 80 GB/s) のディスクリートGPUも搭載。ディスクリートGPUはノートパソコン向け GeForce RTX 10 シリーズ Laptop GPUのローエンド相当。2016年発表。自動車メーカーのTeslaが2016年~2019年に使用していました。
NVIDIA Drive PX 2 AutoChauffeur は AutoCruise を2つ搭載した物。
Maxwell
Drive CXとDrive PXがあります。Jetson TX1相当。2015年発表。
Intel
Intel Xeon
| 型番 | アーキ テクチャ |
コア 数 |
GHz | INT8 | BF16 | FP32 | メモリ 帯域 |
年 |
|---|---|---|---|---|---|---|---|---|
| Xeon Platinum 8490H |
Sapphire Rapids |
60 | 2.9 | 356 | 178 | 11.136 | 307 | 2023 |
| Xeon Platinum 9282 |
Cascade Lake |
56 | x | 262 | 2019 | |||
| Xeon Platinum 8180 |
Skylake | 28 | 3.2 | 23 | x | 5.734 | 119 | 2017 |
| E7-8890 v4 |
Broadwell | 24 | 3.4 | 21 | x | 2.611 | 85 | 2016 |
| E7-8890 v3 |
Haswell | 18 | 3.3 | 15 | x | 1.901 | 85 | 2015 |
| E7-8890 v2 |
Ivy Bridge |
15 | 3.4 | 2 | x | 0.816 | 85 | 2014 |
| E5-2687W | Sandy Bridge |
8 | 3.8 | 1 | x | 0.486 | 51 | 2012 |
すいません。クロック周波数は「全てのコアを使用するが AVX を使用しない場合」のクロック周波数で、AVX を使う場合は、もっとクロックが下がるそうです。Xeon Platinum 8180 は 3.2 → 2.3 GHz で、本当は 4.122 TFLOPS。
1コア・1クロックあたりの演算数(BF16)
- AMX-BF16: 第4世代Xeon SP = 1024
- AVX-512 BF16: Cooper Lake = 128
Intel AMX-BF16 は NVIDIA の Tensor Core に対応するものです。AMX-INT8 もあります。INT8は性能2倍。例えば、4コアの3GHzで25TOPS。
1コア・1クロックあたりの演算数(FP32)
- AVX-512: Skylake, Cascade Lake = 64
- AVX2: Haswell, Broadwell = 32
- AVX1: Sandy Bridge, Ivy Bridge = 16
パソコン用CPU
2023年発表の第1世代Core Ultraからディープラーニング用の Neural Processing Unit (NPU) が載りました。Intel AMX-INT8 を載せるのではなく、Movidius が載ります。Movidius 側は Versatile Processing Unit (VPU) と呼んでいたのですが、パソコン用は NPU という呼称になりました。
近年は2021年発表の第12世代インテルCoreから、かつては対応していたAVX-512が非対応になるなど混沌とした状況になっています。第12世代からPコアとEコアに分かれ、EコアでAVX-512対応が難しいという理由からAVX-512非対応になったそうです。内部事情は分かりませんが、なぜ難しい?低速でもEコアで対応させることは難しい?
| INT8 CPU |
INT8 GPU |
INT8 NPU |
発表年 | |
|---|---|---|---|---|
| Core Ultra X9 388H ノートパソコン |
10 | 120 | 50 | 2025 |
| Core Ultra 9 285K デスクトップ |
15 | 8 | 13 | 2024/10 |
| Core Ultra 9 285H ノートパソコン |
9 | 77 | 13 | 2025/01 |
| Core Ultra 9 288V ノートパソコン |
5 | 67 | 48 | 2024/09 |
| Core Ultra 7 165H ノートパソコン |
5 | 18 | 11 | 2023/12 |
Core Ultra シリーズ3のNPUは第5世代。FP8をサポート。
Core Ultra シリーズ2のNPUは、型番末尾がVで終わるモバイル向けのみ第4世代でNeural Compute Engineが6個。それ以外はシリーズ1と同じ第3世代。NPUはGPUよりも低消費電力を特徴としているのですが、パソコンに必要なんでしょうか?
Core Ultra シリーズ1はNPUとして第3世代Movidius(Keem Bay)を2つ搭載。CPU, GPU, NPU は INT8, BF16, FP16, FP32 対応なのですが、NPU だけ BF16 非対応です。2022年のハイエンドスマートフォン(Snapdragon 8 Gen 1)ではYOLOv8sは僕の実測では364fpsでしたが、OpenVINO - Ultralytics YOLO Docsによると、Core Ultra 7 155Hでは、GPUは100fps、NPUが38fps、CPUが34fpsだそうです。
出典
- IntelのMeteor Lake搭載ノート、dGPUなしでStable Diffusionを高速処理 - PC Watch
- Intel Puts AI, Arc Graphics at the Core of Its New Laptop CPUs - CNET
- 「AI PC」がベールを脱ぐ! 次世代のモバイル向け「Core Ultraプロセッサ」正式発表 搭載ノートPCは順次発売 - ITmedia PC USER
- Intelの次世代ノートPC向けCPU「Lunar Lake」の詳細が明らかに。AI性能と電力あたりの性能をさらに高める
- Lunar Lakeはウェハー1枚からMeteor Lakeの半分しか取れない インテル CPUロードマップ - 週刊アスキー
- Intel、NPUを搭載したデスクトップPC向けプロセッサ「Core Ultra 200S」を発表 | TECH+(テックプラス)
- Intelの「Core Ultraプロセッサ(シリーズ3)」は2025年末に一部出荷 2026年1月にはラインアップを拡充:開発コード名は「Panther Lake」 - ITmedia PC USER
Intel Data Center GPU
Jaguar Shores
Jaguar Shores は2026年頃発表予定。
Ponte Vecchio
| 型番 | INT8 | FP16 BF16 |
TF32 | FP32 | FP64 | メモリ 帯域 |
発売日 |
|---|---|---|---|---|---|---|---|
| Intel Data Center GPU Max 1550 |
1664 | 832 | 419 | 52 | 52 | 3277 | 2023/1 |
| Intel Data Center GPU Max 1100 |
704 | 352 | 176 | 22 | 22 | 1229 | 2023Q2 |
Ponte Vecchio 対応クラウド
出典
Habana Labs (Intel) 2018年~2024年
| 用途 | INT8 | FP8 | BF16 | FP32 | 発表年 | |
|---|---|---|---|---|---|---|
| Gaudi 3 | x | 1835 | 2024/04 | |||
| Gaudi 2 | x | 2022/05 | ||||
| Gaudi HL-2000 | 学習 | x | 2019 | |||
| Goya HL-100 | 推論 | x | x | 2018 |
販売不振のためGaudiは2024年にGaudi 3で終了し、社員も退職。Intel Data Center GPUが残るそうです。
Gaudi 2 までの TFLOPS の形での性能は非公開。
Gaudi 2 対応クラウド
Gaudi HL-2000 対応クラウド
- EC2 DL1
出典
- Gaudi Architecture — Gaudi Documentation
- Intelの没落は2019年に買収したイスラエルのスタートアップ「Habana Labs」を飼い殺しにした時がターニングポイント - GIGAZINE
Intel Nervana (2019年)
| コア数 | flex16+5 | 発表年 | |
|---|---|---|---|
| NNP-L1000 | 120 | 2019 | |
| Lake Crest | 12 | 39 | 2017 |
Lake Crest の性能は理論性能の96.4%が38TOPSという事から逆算。 Intel、深層学習を高速化する「Nervana NNP-L1000」を2019年末までに出荷 ~2020年の東京オリンピックのAIプラットフォームパートナーに就任 - PC Watch
2020年2月に Nervana は終了。Habana Labs に注力。そのHabana Labsは2024年に終了。
Intel Xeon Phi (2012年~2017年)
| コア数 | MHz | FP32 | 発表年 | |
|---|---|---|---|---|
| 7295 | 72 | 1500 | 14 | 2017/12 |
Xeon Phiは2012年に販売開始して、2017年に終了。
Intel Movidius
| コア数 | MHz | INT8 | FP16 | 発表年 | |
|---|---|---|---|---|---|
| Gen 3 Intel Movidius VPU Keem Bay |
500~700 | 3.0~7.1 | x | 2021 | |
| Myriad X MA2485 | 16 | 1 | ? | 2017/8 | |
| Myriad 2 MA2450 | 12 | 600 | 0.2? | 0.1? | 2014/9 |
Gen 3 Intel Movidius VPU 搭載デバイスは色々ありますが、面白い商品としては Luxonis の Robotics Vision Core 3 があります。以下、出典。
- https://www.arrow.com/ais/intel/wp-content/uploads/sites/6/2021/04/Keem-Bay-One-pager_Draft_NA_External_Feb-26.pdf
- Robotics Vision Core 3 - Luxonis Docs
Intel Neural Compute Stick 2 は Myriad X を搭載。
Myriad 2 MA2450 は、おそらく 128bit / 16bit * 2 * 12コア * 0.6GHz / 1000 = 0.1152 TFLOPS (FP16) だと思われます。性能は曖昧な形で発表しています。上記とは別にHoGやガンマ補正など各種画像処理の専用回路も多数搭載。メモリもLPDDR2ですし、速度的にはRaspberry Piレベルのチップと釣り合うレベル。LPDDR4のIntel AtomだとCPUの方が速くてバランスが悪いです。
MobileEye (Intel)
自動運転用のチップ。Intel の子会社。
情報源
- http://wccftech.com/tesla-autopilot-story-in-depth-technology/5/
- http://www.mobileye.com/wp-content/uploads/2016/11/Mobileye_EyeQ_Infographic6-002.pdf
- 【PR】モービルアイ&インテル、将来のEyeQ6までのロードマップ公開 - Car Watch
以下、TOPS は INT8。
EyeQ7
| INT8 | 電力 | 発売年 | |
|---|---|---|---|
| EyeQ7 High | 67 | 最大60W | 2025Q2 |
当初はEyeQ Ultraの名称で176TOPS予定でした。CPUはRISC-V。プロセスルールは5nm。
出典
EyeQ6
| CPU コア数 |
INT8 | BF16? | GPU | 発売年 | |
|---|---|---|---|---|---|
| EyeQ6 High | 8 | 34 | 1.00 | 0.064 | 2024年 |
| EyeQ6 Lite | 2 | 5 | 0.72 | 2023/Q2 |
PMA, VMP, MPC, XNN という4種類のアクセラレーターを CPU や GPU とは別に搭載。XNN はニューラルネットワーク用。CPUはMIPS64。プロセスルールは7nm。
EyeQ5
2021年発売予定。プロセスルール7nm。
| 種別 | コア数 |
|---|---|
| CPU | 8 |
| Computer Vision Processors | 18 |
- 7 TOPS @ 7.5W
- 12 TOPS @ 17 W
- 24 TOPS @ 34 W
EyeQ4
2018年出荷。下記4種類を1つにまとめた物。プロセスルールは28nm。
| 種別 | コア数 | MHz | MAC/コア | TOPS |
|---|---|---|---|---|
| CPU | 4 | 1000 | 32? | 0.256? |
| VMP (Vector Microcode Processors) | 6 | 1000 | 76 | 0.912 |
| PMA (Programmable Macro Array) | 2 | 750 | 372 | 1.116 |
| MPC (Multithreaded Processing Clusters) | 2 | 1000 | 32 | 0.128 |
- 1.1 TOPS @ 4.5W
- 2.2 TOPS @ 6.5 W
EyeQ3
2014年出荷。テスラモーターズ等に採用。TDP 2.5W。プロセスルールは40nm。
| コア数 | MHz | MAC/コア | TOPS |
|---|---|---|---|
| 4 | 500 | 64 | 0.256 |
EyeQ2
2010年出荷。TDP 2.5W。プロセスルールは90nm。0.026 TOPS。
EyeQ1
2008年出荷。TDP 2.5W。プロセスルールは180nm。4.4 GOPS。
AMD
サーバー
| INT8 | FP16 | BF16 | FP32 | FP64 | メモリ 帯域 |
発表年 | |
|---|---|---|---|---|---|---|---|
| Instinct MI325X | 2614 | 1307 | 1307 | 163.4 | 163.4 | 6000 | 2024/06 |
| Instinct MI300X | 2614 | 1307 | 1307 | 163.4 | 163.4 | 5300 | 2023/12 |
| Instinct MI300A | 1960 | 980.6 | 980.6 | 122.6 | 122.6 | 5300 | 2023/12 |
| Instinct MI250X | 383 | 383 | 383 | 95.7 | 95.7 | 3200 | 2021/11 |
| Instinct MI100 | 184.6 | 184.6 | 92.3 | 46.1 | 11.5 | 1200 | 2020/11 |
| Instinct MI25 | 24.6 | 12.3 | 0.8 | 484 | 2017/06 |
MI300AはCPUとGPUが一体型。NVIDIAのGrace Hopperに対応する商品。
Instinct MI300X 対応クラウド
- Azure ND MI300X v5
Instinct MI25 対応クラウド
- Azure NVv4
出典
パソコン(NPU)
| INT8 | BF16 | 発表年 | |
|---|---|---|---|
| Ryzen AI 9 HX PRO 375 | 55 | 2024/10 | |
| Ryzen AI 300 | 50 | ? | 2024/06 |
| Ryzen 8000G Ryzen 8040 |
16 | ? | 2024/01 2023/12 |
| Ryzen PRO 7040 | 10 | ? | 2023/06 |
Ryzen AI 300 は block FP16 に対応しているそうですが、block FP16 がなんであるか AMD の資料を見つけられなかったのですが、https://www.anandtech.com/show/21419/amd-announces-the-ryzen-ai-300-series-for-mobile-zen-5-with-rdna-35-and-xdna2-npu-with-50-tops の感じだと、bfloat16 において指数部は8ビットですが、これを MXFP8 のように、指数部8ビットを複数の浮動小数点数で共有して使うという話のようです。INT8と同じ速度で動くようです。
2023年12月にNPU対応のAMD Ryzen AI Softwareをリリース。ONNX Runtimeとして動作。
Ryzen PRO 7040 は AI アクセラレーターを搭載。Intel よりも先に AI アクセラレーターを載せました。
出典
- https://www.amd.com/en/newsroom/press-releases/2024-6-2-amd-extends-ai-and-high-performance-leadership-in-.html
- AMD、55TOPSのNPUを採用した企業向け「Ryzen AI PRO 300」 - PC Watch
組み込み
| INT4 | MXFP6 | INT8 | BF16 | 発表年 | |
|---|---|---|---|---|---|
| Versal AI Edge Gen2 | x | 61~370 | 31~185 | 15~92 | 2024/04 |
| Versal AI Edge Gen1 | 13~431 | x | 7~228 | ? | 2023/09 |
Versal AI Edge Gen2 の対応データ型は INT8, INT16, FP8, FP16, BF16, MXFP6, MXFP9 。疎行列にも倍の性能で対応。MXFP6, MXFP9 とは32個で8ビットのスケールを共有する浮動小数点数。https://arxiv.org/abs/2310.10537 に説明があります。
出典
- https://www.amd.com/en/products/adaptive-socs-and-fpgas/versal/gen2/ai-edge-series.html
- https://www.amd.com/ja/products/adaptive-socs-and-fpgas/versal/ai-edge-series.html
Tensor Processing Unit
| MAC数 | MHz | FP8 | INT8 | BF16 | メモリ帯域 | 開発年 | |
|---|---|---|---|---|---|---|---|
| v7 | 4614 | 7370 | 2025 | ||||
| v6e | x | 1836 | 918 | 1640 | 2024 | ||
| v5p | x | 918 | 459 | 2765 | 2023 | ||
| v5e | x | 393 | 197 | 820 | 2023 | ||
| v4 | x | x | 275 | 1228 | 2020 | ||
| v3 | x | x | 123 | 900 | 2018 | ||
| v2 | 32768 | 700 | x | x | 45 | 600 | 2017 |
| v1 | 65536 | 700 | x | 92 | x | 2015 |
v2以降はGoogle Cloudで提供している。
v5e以外のv4以降はSparseCoreを搭載。
v2は1つのTPU Chipに2コア。1コアにつき128 * 128 = 16384個の積和算回路。TPU Chipに2 * 8 = 16GBのメモリ。上記はTPU Chipの情報。1つのTPUボードに4つのTPU Chip搭載。メモリは合計4 * 16GB/TPUボード。TPU Podは64TPUボード。コア→TPU Chip→TPUボード→TPU Podという階層構造。単にTPUと呼んだ場合は1枚のTPUボードの事をさす。bfloat16を採用。符号部1ビット、指数部8ビット、仮数部7ビット。仮数部以外はfp32と同じ。
v1も発表は2017年。
出典
Edge TPU
| MAC数 | MHz | INT8 | 開発年 | |
|---|---|---|---|---|
| Edge TPU | 4096 | 480 | 4 | 2018 |
何種類かシングルボードコンピュータあり。https://coral.ai/products/
Amazon
サーバー
| 名称 用途 |
INT8 | FP8 | FP16 BF16 |
FP32 | 年 | クラウド |
|---|---|---|---|---|---|---|
| AWS Trainium3 学習 |
2024 | EC2 | ||||
| AWS Trainium2 学習 |
? | 1299 | 667 | 181 | 2023 | EC2 trn2 |
| AWS Inferentia2 推論 |
380 | 190 | 190 | 47.5 | 2022 | EC2 inf2 |
| AWS Trainium 学習 |
420 | x | 210 | 52.5 | 2022 | EC2 trn1 |
| AWS Inferentia 推論 |
128 | x | 64 | x | 2019 | EC2 inf1 |
| Amazon Elastic Inference 推論 |
x | x | 8 | 1 | 2018 | EC2 eia1, eia2 |
Inferentia2 および Trainium は共に NeuronCore-v2 を2コア使用。1台のマシンに Inferentia2 は12枚、Trainium は16枚搭載。Inferentia2 は NeuronLink-v1 でつながっているのに対して、Trainium はより高速な NeuronLink-v2 で16枚を接続。取り扱えるデータ型は cFP8, FP16, BF16, TF32, FP32, INT8, INT16, INT32 。
- ScalarEngine が 1,600 FLOP/cycle per core
- VectorEngine が 2,500 FLOP/cycle per core
- TensorEngine が 100 TFLOPS/core (BF16)
AWS Inferentia と Amazon Elastic Inference はディープラーニングの推論用であり、学習は GPU を使ってください、という方針。学習はバッチ処理により複数のデータをまとめて処理するが、推論は1つのデータしか扱わないため、処理の向き不向きが異なるため、推論用に作られたチップ。
出典
- Trainium2 Architecture — AWS Neuron Documentation
- Inferentia2 Architecture — AWS Neuron Documentation
- AWS Trn1/Trn1n Architecture — AWS Neuron Documentation
- AWS Inf1 Architecture — AWS Neuron Documentation
組み込み
| INT8 | 発表年 | |
|---|---|---|
| AZ2 | 数 | 2021/9 |
| AZ1 | 0.1程度 | 2020/9 |
性能の詳細は非公開です。AZ2はAZ1の22倍TOPSが多い、AZ2は数TOPSとだけ公開されています。Amazon Echoシリーズなどに使用されています。
出典
Microsoft
| 発表年 | |
|---|---|
| Azure Maia 100 | 2023/11 |
Apple
Apple Neural Engine
| FP16 | 発表年 | |
|---|---|---|
| M4 | 38 | 2024/5 |
| A18 Pro A18 A17 Pro |
35 | 2024/9 2024/9 2023/9 |
| M3 | 18 | 2023/10 |
| A16 Bionic | 17 | 2022/9 |
| M2 A15 Bionic |
15.8 | 2022/6 2021/9 |
| M1 A14 Bionic |
11 | 2020/11 2020/9 |
| A13 Bionic | 6 | 2019/9 |
| A12 Bionic | 5 | 2018/9 |
| A11 Bionic | 0.6 | 2017/9 |
出典
- https://machinelearning.apple.com/research/neural-engine-transformers
- https://apple.github.io/coremltools/docs-guides/source/typed-execution.html
Apple 内蔵GPU (ARM)
| FP16 | FP32 | FP64 | 発表年 | |
|---|---|---|---|---|
| M2 | 7.10 | 3.55 | 0.89 | 2022/6 |
| M1 Max 32コア |
20.8 | 10.4 | 2021/10 | |
| M1 | 5.22 | 2.61 | 0.65 | 2020/11 |
ARM
CPU
ARMv8.6-A および ARMv9.1-A より bfloat16 および行列積の命令が追加になります。さらに、ARMv9.2-A より、ARM Scalable Matrix Extension (SME) が追加になります。Intel Advanced Matrix Extensions (AMX) に対応するものです。ARMv9.4-A より SME2 が追加。
出典
- https://developer.arm.com/Architectures/A-Profile%20Architecture
- https://community.arm.com/arm-community-blogs/b/architectures-and-processors-blog/posts/scalable-matrix-extension-armv9-a-architecture
NPU
| INT8 | 発表年 | |
|---|---|---|
| Ethos-N78 | 1~10 | 2020/5 |
| Ethos-N77 | 4 | 2019/5 |
Ethos は Arm Compute Library と Arm NN を経由して利用可能です(当然、その上に上位ライブラリを経由して利用する前提です)。Arm Compute Library では GPU 別の個別に最適化した行列積も実装されています。
2025年1月現在、なんか、ARMはハイエンドのNPUを作る気が無いように僕には見えますが、NVIDIAのようにGPUに行列積のエンジンを載せるわけでもなく、どうなるんでしょう?GPUにINT8のベクトル内積は載っています。【後藤弘茂のWeekly海外ニュース】ニューラルプロセッサに対抗するArmのMali GPU - PC Watch。
出典
Qualcomm Snapdragon
| INT8 | 発表年 | |
|---|---|---|
| Snapdragon X Elite | 45(NPU) 30(CPU+GPU) |
2023/10 |
| Hexagon 780 | 26 | 2020/12 |
| Hexagon 698 | 15 | 2019/12 |
| Hexagon 690 | 7 | 2018/12 |
| Hexagon 685 | 3 | 2017/12 |
下記グラフはハイエンドおよびミドルレンジ(5万円前後)のスマートフォンのSnapdragonの畳み込みニューラルネットワークの性能比較です。ハイエンドはGalaxy S、ミドルレンジはAQUOS senseを使用しました。数値は https://ai-benchmark.com/ranking_processors.html です。ハイエンドは2021年に大きく性能が向上しています。ミドルレンジはハイエンドの3年遅れです。ローエンド(2万円前後)はハイエンドの7年遅れのようです。AI Benchmark 6にはYOLOv8sが含まれていて、Galaxy S22(2022年)のNPUでは僕の実測では364fpsでした。
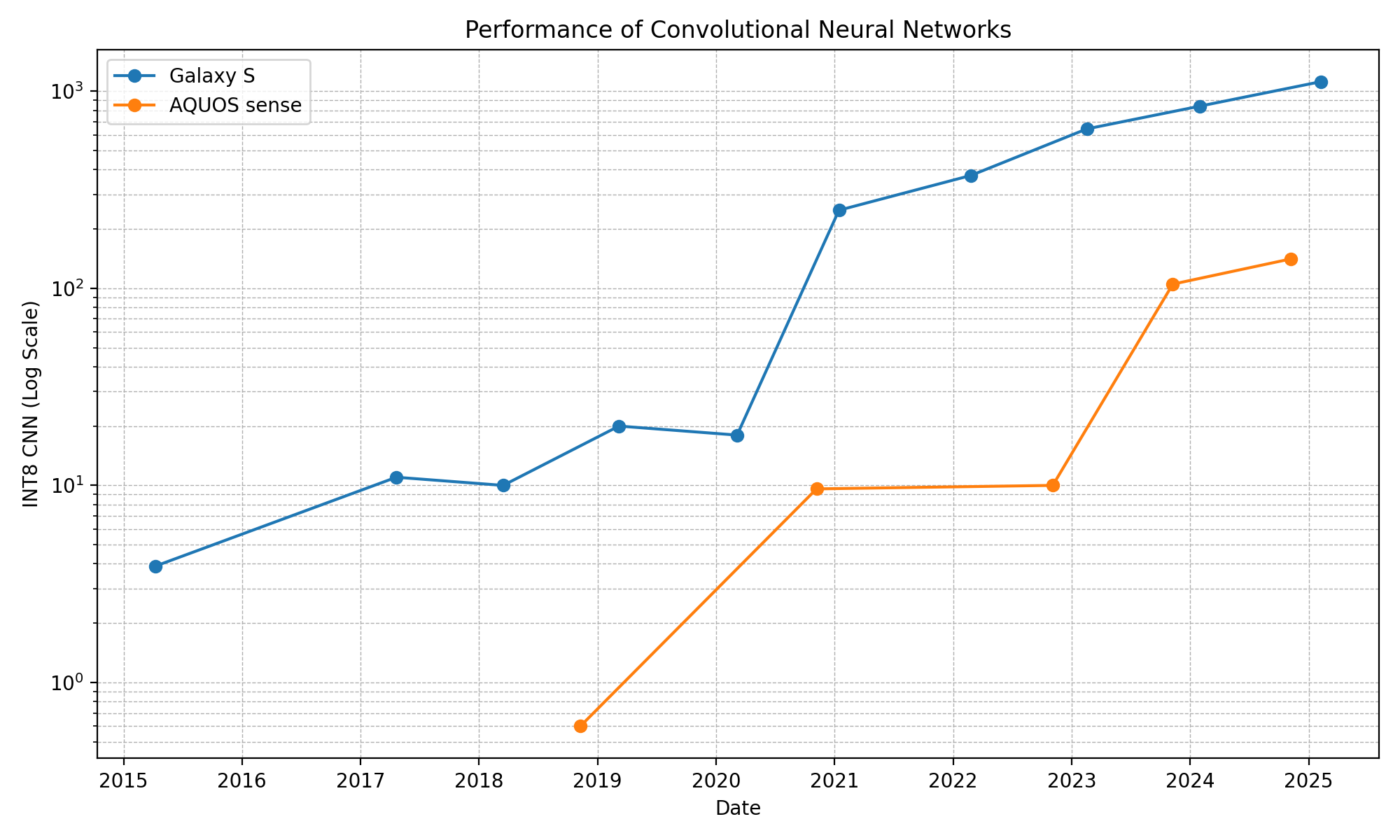
Snapdragon X Elite はパソコン用。第1世代Core Ultra 7との比較動画が https://www.youtube.com/watch?v=47WRzE8c7e8 にあります。
(2018年頃の話)Google Pixel 4 は Snapdragon 855 (Hexagon 690) ですが、実測のベンチマーク結果が https://www.tensorflow.org/lite/performance/measurement#android_performance_benchmarks にあります。ベンチマーク結果を見て思ったのですが、専用回路を止めて GPU で INT8 を扱った方が良いのではないでしょうか?
(2014~2016年の話)ハイエンドの GPU は NVIDIA Tegra とほぼ同じ性能です。Snapdragon には Hexagon DSP が搭載されていて、8/16/32bitの固定小数点が扱えます。GPU の半分の性能で設計されていますが、8bitが扱えることが特徴です。
出典
Huawei
Ascend
| INT8 | FP16 | 発表年 | |
|---|---|---|---|
| Ascend 910B | 640 | 320 | 2023/11 |
| Ascend 910 | 512 | 256 | 2019/08 |
| Ascend 310 | 16 | 8 | 2019/08 |
Kirin NPU
| NPU数 | FP16 | 発表年 | |
|---|---|---|---|
| Kirin 990 5G | 2 | 5? * 2 | 2019/9 |
| Kirin 980 | 2 | 2.1? * 2 | 2018/9 |
| Kirin 970 | 1 | 1.92 | 2017/9 |
Kirin 990 5G は 980 から2.5倍の高速化だそうですが詳細不明。INT8 も対応。
Kirin 980 の NPU の詳細は非公開ですが、NPU が1つから2つに増え、合計して2.2倍高速になったと書いてあったので、そこから逆算して10%高速になったと推測しました。
Kirin 970 の NPU は3行3列の行列積。HiKey 970 などのファンレスシングルボードコンピュータあり。TensorFlow や Caffe が利用可能。
PowerVR
| INT8 | 発表年 | |
|---|---|---|
| AX2185 | 4.1 | 2018/6 |
| AX2145 | 1.0 | 2018/6 |
AX2185, AX2145 は Android Neural Networks API 経由で利用可能。
Rockchip
| INT8 | 発表年 | |
|---|---|---|
| RK3588 | 6 | 2021/7 |
| RK3566 RK3568 |
0.8 | 2020/12 |
| RK1808 | 3 | 2018/11 |
| RK3399Pro | 2.4 | 2018/1 |
RK3588 は INT4, INT8, INT16, FP16, BF16, TF32 に対応。
Amlogic
| INT8 | |
|---|---|
| A311D | 5 |
| C305X | 2 |
| C308X | 4 |
| S905D3 | 1.2 |
| S928X | 3.2 |
| T982 | 2.6 |
| V901D | 1 |
全てを網羅できないほどたくさんあります。
Axera
| INT4 | INT8 | 発表年 | |
|---|---|---|---|
| AX650N | 72.0 | 18.0 | 2023/03 |
| AX650A | 43.2 | 10.8 | |
| AX630C | 12.8 | 3.2 |
無数に商品あり。INT4は大規模言語モデル(LLM)用。M5Stack LLMなどに使われています。
出典
Hailo
| INT8 | 電力 | 発表年 | |
|---|---|---|---|
| Hailo-10H | 40 | 典型的3.5W | 2024/4 |
| Hailo-15H | 20 | 2023/3 | |
| Hailo-15M | 11 | 2023/3 | |
| Hailo-15L | 7 | 2023/3 | |
| Hailo-8 | 26 | 最大8.25W | 2019/5 |
| Hailo-8L Hailo-8R |
13 | 典型的1.5W | 2023/8 |
Hailo-15 シリーズは CPU として Arm Cortex-A53 4コア を内蔵(Raspberry Pi 3相当)。
Hailo-8 の 8.25W はヒートシンクだけで動くギリギリに設定されていますが、ケースファンもしくは金属ケースで NPU とケースを金属で結合させる必要があります。
Hailo-8, Hailo-8L は Raspberry Pi AI HAT+ としても発売されています。AI HAT+ はヒートシンク無しです。
ルネサス
| INT8 | FP16 | 電力 | 発売年 | |
|---|---|---|---|---|
| RZ/V2xx | 15 | x | ||
| RZ/V2H | 8 (80@枝刈り) |
x | 8W | 2024/2 |
| RZ/V2MA RZ/V2M |
x | 0.7 | 1W | 2022/9 2020/6 |
| RZ/V2L | x | 0.5 | 1W | 2021/5 |
RZ/V2H はモデルの枝刈り(スパース化)することで10倍性能を上げることが出来るそうです。
出典:
- RZ/V Embedded AI MPU | Renesas
- ルネサスがエッジAIでNVIDIAへの対抗心むき出し、電力効率10倍だけじゃない | 日経クロステック(xTECH)
- TinyML Comes to Embedded World 2023 - EE Times
- ルネサス、ファンレスで80TOPSのAI推論を実現したDRP-AI搭載MPU「RZ/V2H」を発売 | TECH+(テックプラス)
デンソー
| INT8 | 電力 | 年 | |
|---|---|---|---|
| ML041 | 5.08 | 0.42W | 2022 |
NSITEXEが開発していたのですが、NSITEXEは2023年3月が63億円の債務超過で、デンソーに吸収され消滅しました。
Preferred Networks
| 型番 | TF16 | FP16 | FP32 | FP64 | 稼働開始年 |
|---|---|---|---|---|---|
| MN-Core L1000 | 2026 | ||||
| MN-Core 2 | 393 | 49 | 12 | 2024 | |
| MN-Core 1 | 131 * 4 | 32.75 * 4 | 8.19 * 4 | 2020 |
MN-Core 1 には1つのパッケージには4つのダイがあり、パッケージの性能で発表しているのですが、上記は4で割ったダイの性能です。2020年稼働で当初は社内利用専用、2023年よりPFNのパートナー企業向けにも提供。
出典
- MN-Core Series - Preferred Networks
- PFN、深層学習を高速化するプロセッサーMN-Core 2の開発および、MN-Coreシリーズのクラウドサービス構想を発表 - 株式会社Preferred Networks
自動車メーカーのTesla
| 型番 | INT8 | FP16 | FP32 | 年 |
|---|---|---|---|---|
| Dojo D1 | 362 | 22.6 | 2021/8 | |
| ? | 36 | 0.6 | ? | 2019 |
Dojo D1 はサーバー用。
2019年のは車載用で、NNプロセッサ+GPU+CPUの組合せ。NNプロセッサがINT8、GPUが浮動小数を扱える。
Meta
| INT8 | FP16 | 年 | |
|---|---|---|---|
| MITA v1 | 102.4 | 51.2 | 2020 |
理由は良く分からないのですが、なぜか2020年に設計した MITA v1 を2023年に発表。試作品?組み込み向けの Jetson Orin NX 16GB 相当。
出典:MTIA v1: Meta’s first-generation AI inference accelerator
Cerebras
| 型番 | INT8? FP8? |
発表年 |
|---|---|---|
| WSE-3 | 125,000 | 2024/03 |
| WSE-2 | 2021 | |
| WSE-1 | 2019 |
WSE-3 はチップサイズが 46,225 mm² という、NVIDIA H100 の57倍という巨大チップ。値段は1億円くらいでしょうか?性能もNVIDIA H100の63倍です。SRAMも44GBと大量に載せています。
出典:https://www.cerebras.net/product-chip/
Graphcore
| 型番 | MHz | FP16 | FP32 | 発表年 | クラウド |
|---|---|---|---|---|---|
| Colossus MK2 GC200 | 1325 | 250 | 62.5 | 2020/7 | Azure NDv3 |
GPUではなくIPUと呼んでいます。MK2は1IPUに1472タイルあり、1タイルに624KBのSRAMを搭載。それぞれのタイルが異なる計算を並列に実行可能。よって、小さなバッチサイズでも動作するそうです。Azureでは1台に16IPU。
Xilinx Virtex
| 型番 | DSP | INT8 | クラウド |
|---|---|---|---|
| UltraScale+ VU9P | 6840 | 21.3 | EC2 f1 Alibaba f3 |
YOLOのベンチマーク結果
物体検出YOLOのベンチマーク結果です。単位はfpsです。記載が無ければINT8です。画像1枚処理で、バッチ処理無しです。本来は640pxの画像処理ですが、USB Coral Edge TPUだけ512pxです。
YOLOとして、Androidアプリ Ultralytics HUB が配布されているのですが、挙動から見るに、おそらく非推奨となったNNAPIを使用していてCPU動作だと思われます。Snapdragon 8 Gen 1は AI Benchmark による僕の実測です。
| デバイス | YOLO v5s |
YOLO v8n |
YOLO v8s |
YOLO 11n |
|---|---|---|---|---|
| Hailo-8 | 542 | 1036 | 398 | 156 |
| Snapdragon 8 Gen 1 (2022, NPU) |
364 | |||
| Intel Core Ultra 7 155H 内蔵GPU |
100 | |||
| NVIDIA A100 | 3448 | |||
| NVIDIA T4 (FP16) | 521 | 680 | 376 | 645 |
| NVIDIA RTX 3080 | 1351 | |||
| NVIDIA RTX 3060 | 741 | |||
| NVIDIA RTX 2060 | 1316 | |||
| NVIDIA Jetson Orin NX 16GB |
431 | |||
| Raspberry Pi AI Camera Sony IMX500 |
15 | |||
| Rockchip RK3588 | 10 | 8 | ||
| iPhone 12 (2020) | 70 | |||
| USB Coral Edge TPU (2018, 512px) |
24 | 10 |
出典
- https://github.com/hailo-ai/hailo_model_zoo/blob/master/docs/public_models/HAILO8/HAILO8_object_detection.rst
- https://docs.ultralytics.com/integrations/openvino/#intel-ultra-7-155h-meteor-lake-cpu
- https://docs.ultralytics.com/integrations/tensorrt/#nvidia-a100
- https://docs.ultralytics.com/models/yolo11/#performance-metrics
- https://docs.ultralytics.com/integrations/tensorrt/#consumer-gpus
- https://docs.ultralytics.com/integrations/tensorrt/#embedded-devices
- https://docs.ultralytics.com/integrations/sony-imx500/#benchmarks
- https://docs.ultralytics.com/integrations/rockchip-rknn/#benchmarks
- https://github.com/ultralytics/yolov5/issues/1276
- https://docs.ultralytics.com/guides/coral-edge-tpu-on-raspberry-pi/#benchmarks
クラウドのコスト比較
| 会社 | 種別 | マシン名 | CPU コア数 |
BF16 | FP32 | 価格 | コスパ BF16 |
コスパ FP32 |
|---|---|---|---|---|---|---|---|---|
| Amazon | CPU | c7i.48xlarge | 96 | 294 | 18.4 | 2.6839 | 109.5 | 6.85 |
| Amazon | GPU | g5.xlarge | 2 | 125 | 31.2 | 0.3383 | 369.4 | 92.22 |
| Amazon | GPU | p4d.24xlarge | 48 | 2496 | 156 | 9.5333 | 261.8 | 16.36 |
| Amazon | inf2.xlarge | 2 | 190 | 47.5 | 0.1972 | 963.4 | 240.87 | |
| Amazon | trn1.2xlarge | 4 | 210 | 52.5 | 0.3461 | 606.7 | 151.69 | |
| CPU | c3-highcpu -176 |
88 | 270 | 16.8 | 1.43 | 188.8 | 11.74 | |
| GPU | g2-standard -4 |
2 | 121 | 30.3 | 0.24 | 504.1 | 126.25 | |
| GPU | a2-highgpu -1g |
6 | 312 | 19.5 | 1.4693 | 212.3 | 13.27 | |
| TPU | TPU v5e | 197 | x | 0.6000 | 328.3 | x | ||
| Azure | CPU | F72s v2 | 36 | x | 6.9 | 0.46 | x | 15.00 |
| Azure | GPU | NC24ads A100 v4 |
12 | 312 | 19.5 | 0.67 | 465.6 | 29.10 |
全てスポットインスタンスです。価格は2024年9月22日の米国インスタンスの価格。価格の単位はドル/時。コスパの単位は TFLOPS・時/ドル 。CPU のクロックは全て 3.0 GHz (ブースト) として計算(やや不正確です)。
$10/h ルール
クラウドで金銭的に暴走しない自主規制ルールとして$10/h(1500円/時)というルールがあります。月720時間使っても108万円です。個人の裁量としてここまでは自由に使って良いという会社さんもあるようです。
Google Cloud の $10/h ルールの場合の上限(スポット)
| 種別 | 個数 |
|---|---|
| n2-highcpu | 1240 vCPU (620コア) |
| c3-highcpu | 580 vCPU (290コア) |
| NVIDIA L4 | 44 GPU |
| NVIDIA A100 | 6 GPU |
| TPU v4 | 16 TPU |
マシンの台数は数百台を限度にしないと面倒なことになるので、CPUの場合は n2-highcpu-8 を155台が上限になります。クラウドの傾向として、多くのマシンは負荷を限界まで使っていないため、どうも、1つ1つのvCPUを少なめにして、多くのマシンにばらけさせた方が、発熱の制限が余っていたり、L3キャッシュやメモリ帯域は共有なので、1つ1つの処理速度を上げられて高速に動作します。あとは台数の数の制限で、現在は、n2-highcpu-8 がちょうどだと思います。(もちろん計算する内容次第で highmem だったり色々です)
Google Cloud のリソースの割り当てを増やすのにかかる日数
昔は違ったのですが、2021年12月現在は、Google の窓口で聞いたところ、
- 請求先アカウント別のリソース quota (利用者からは見られない)
- プロジェクト別のリソース quota (利用者から見られる)
の2つがあるそうです。https://cloud.google.com/compute/quotas には執筆時現在はプロジェクト別のリソース quota の方しか記載がありません。プロジェクト別 ≦ 請求先アカウント別 の制限があるそうです。プロジェクト別のリソース quota の方は48時間以内に対応するとなっているのですが、$10/h 程度の規模感の場合、請求先アカウント別のリソース quota の引き上げも必要です。
その際は、
- https://console.cloud.google.com/iam-admin/quotas から申請する
- アメリカ本社から日本のセールスに再度申請して欲しいと言われる
- セールスの窓口に申請すると、担当者を割り振るというメールをいただく
- 担当者が割り振られ、リソースの割り当てが完了する
という手順をたどります。1ステップ1週間程度かかり、合計1か月程度かかりました。最悪3か月程度はかかることを見越して早めに申請されることをお勧めします。
分散化の方法
1つだけスポットではない落ちないサーバー(親ノード)を立て、ここに NFS サーバーも立てます。Google Cloud の場合、インスタンステンプレートを作り、そこからインスタンスグループを立ち上げるとインスタンス(子ノード)を一気に立ち上げられます。インスタンステンプレートのメタデータで startup-script と shutdown-script で起動時と終了時に実行するスクリプトを指定できます。
処理の流れはこうなります。
- 落ちない親ノードにキューとそのサーバーソケットを開いて、子ノードを待ちます。通信がボトルネックにならない粒度で問題を細かく分割してキューに詰めます。
- インスタンスグループで子ノードを立ち上げます。
- 子ノードは startup-script で rsync して親ノードからソースコードをダウンロードし、プログラムを開始します。
- 子ノードは親ノードのサーバーソケットから、(分割された問題に不変な)計算全体に必要なデータをダウンロードします。Cloud Storage や S3 からダウンロードしても良いです。マシンイメージに大量のデータを入れるのは起動が遅くなるので止めた方が良いです。
- 子ノードは親ノードのキューから1つ取りだし、問題を解き、計算結果を親ノードにソケットで返したり、親ノードの NFS にファイルとして返します。
- スポットインスタンスが強制終了する際に shutdown-script が走るので、親ノードに離脱する旨をソケットで返します。計算が完了しなかった旨を親ノードに通知して、キューに詰め直し、別の子ノードに振り分けます。
なお Google Cloud のドキュメントによると「まれに」、ちゃんと計測はしていませんが5%位の確率で shutdown-script が実行されずにインスタンスが突然終了します。なので、インスタンスが生きているかどうか定期的にポーリングして死活監視する必要があります。Java ならば InetAddress.isReachable() で死活監視できます。
普通の LAN ではなく NVLink や高速な通信回線を使用する場合は、当然、方法は変わります。
(親ノードではなく)子ノードから計算したい内容をキューに詰めて、子ノードで計算結果を受け取るのは、子ノードのインスタンスが強制終了させられる状況では、継続渡しスタイルが必要になると思うのですが、多くのケースで厄介だと思います。
Java の場合の Tips
Java の場合は、ラムダ式をシリアライゼーションして送信してしまうと便利ですが、問題点はラムダ式から親スコープの変数にアクセスしている場合、それらを含んでシリアライゼーションするのですが、一体、何を送信するのかが分かりにくいです。自明な場合以外は XStream の toXML() を使って XML にしてシリアライゼーション内容を確認すると便利でした。Java の static フィールドや Scala の object のフィールドはラムダ式からアクセスしてもシリアライゼーション対象外なので、大規模データは static フィールドなどに置くと便利です。
更に、Scala の場合は、def distributedMap[A, B](childrenCount: Int, machineType: String, nvcpu: Int)(tasks: Seq[A])(fn: A => B): Seq[B] こんな感じの分散化マップを自作すると良いです。distributedMap 内からクラウドのインスタンスグループを作成してしまいます(distributedMap が2回目に呼ばれる際は共有して利用)。タスク非依存のデータはサイズが小さい場合(1KB以下など)はラムダ式 fn の親スコープの変数に置き、fn をシリアライゼーションする際に自動的についてくるので、fn を送信する際にまとめて送ってしまいます。distributedMap を実行する度に fn を送信するので、サイズが大きいデータは object のフィールドに置きます。
Scala の並列コレクションと共存させるには、並列コレクションは「CPUを使用しない長時間処理は blocking {} で包むこと」というルールがあるので、distributedMap の中の子ノードからの計算結果待ちの所を blocking で包めば、並列コレクションの .par.map() の所を distributedMap() に置き換えることが出来ます。多重ループを綺麗に並列化かつ分散化処理として記述することが出来ます。
ムーアの法則
5年で10倍速くなるムーアの法則は健在。(モバイルの通信速度も5年で10倍速くなっています)