(2023/01/01 01:17:NovelAIの使用モデルについて追記しました)
(2023/02/10 09:59: 次回作ができました!(9fps化) https://ao-love-yuimop.hatenablog.com/entry/2023/02/10/094800 )
(2023/04/09: さらに次回作ができました。(ゆいもっぷ/ユメヲカケル アニメPV))
画像生成AIのNovelAIやSmoothGraphic等を使って ゆいもっぷ ちゃん(20)の激カワな歌にアニメPVをつけました(ファンアニメ)🏖
— あお (@ao_love_yuimop) April 9, 2023
SmoothGraphic Copyright(C)2013-2017 チラ裏エリア
Full: https://t.co/9fcWqWJ481 https://t.co/ZuwuqFNS5Y (digest)#AIArt #AIイラスト #AIAnime pic.twitter.com/3GdAdOOsV9
まとめですわ
- NovelAIで中割り画像を作る方法を見つけましたわ
- カメラワークだけでなく、人などの動作も中間のものが出力されますわ
- 服装も、そもそも前後の入力画像(原画)で服装を一致させれば、かなり服装一貫性を得られますわ
- その中割り生成作業を一部自動化するシステムを作りましたわ (17日間で)
- https://chara-zokusei.jp/nakawari を使えば皆様も中割り画像を作れますわ
- カメラワークだけでなく、人などの動作も中間のものが出力されますわ
- その中割り生成法を使って、 激かわ個人勢Vtuber ゆいもっぷ さん のアニメ映像を作りましたの
-
- (埋め込み動画だと画質が下がるみたいなので、 twitter本体で見て欲しいかも)画像生成AIのNovelAIで中割り画像を作る方法を発見したので、「ゆいもっぷ」さんの2Dアニメ動画を作りました(原画8枚、動画78枚)(中割画像生成用画像生成サイトつき)
— あお (@ao_love_yuimop) December 24, 2022
方法: https://t.co/1QrbKjpJcP
動画(高画質): https://t.co/jsF8WAMY7Q#NovelAI #AIイラスト pic.twitter.com/8giFiZ8Uym - 動画(高画質): https://www.nicovideo.jp/watch/sm41552041
-
背景・経緯
- 激かわ個人勢 Vtuberの「ゆいもっぷ」さんが、激かわですの (since: 4年前くらい)
- ↓の経緯で中割り生成法を発見したので、ゆいもっぷ さんのアニメ映像を作りたく思いましたの (ファン心理ですわ)
背景・経緯 2 (技術面)
- 一方その頃、2022年10月3日に、画像生成AI「NovelAI Diffusion」がエポックメイキングに登場されてましたの
- わたくしが画像生成AIを触っていましたら、下記に示す手順を行うと、前後の画像からちょうど中間状態の動作を描いた画像 (中割り画像) が得られることが分かりましたの
- 腕の動きなどもちょうど中間時点の画像になるので、とてもすごいですわ
- 8枚の (下記中割生成法で作っていない) 元となる絵を用意して (「原画」相当)、そこから、たくさん中割り画像を作って ゆいもっぷ アニメ動画を作りましたわ
- 動画78枚、6.74コマ/秒 (動画時間 11.57秒)
- 原画にあたる絵も 画像生成AIなど で用意可能ですわ
- その間の状態の画像を、下記の中割生成法で作っていきますわ
- ※: 今回の内容は個人的な趣味活動ですわ
- (お仕事でAIやアニメ関係の事をしたことはありませんことよ)
- (アニメの制作歴は、11月頭からなので2ヶ月未満ほどですわ)
手順&原理
- わたくし製、中割生成用入力画像を作る Webサービスのスクショを示しながら説明しますわね。
- 中割り画像を作りたい前後の画像を用意くださいませ (前と後ろで1枚ずつ)
-
- 特徴点(目の両端や、胴体の一定のY軸座標の両端などでしてよ) を前画像、後画像それぞれで2点(合計4点) ご指定 (クリック) くださいませ
- わたくしのシステムでは、右上に、1枚目の1点目(x,y), 1枚目の2点目(x,y), 2枚目の1点目(x,y), 2枚目の2点目(x,y) と座標が表示されてますわ
-
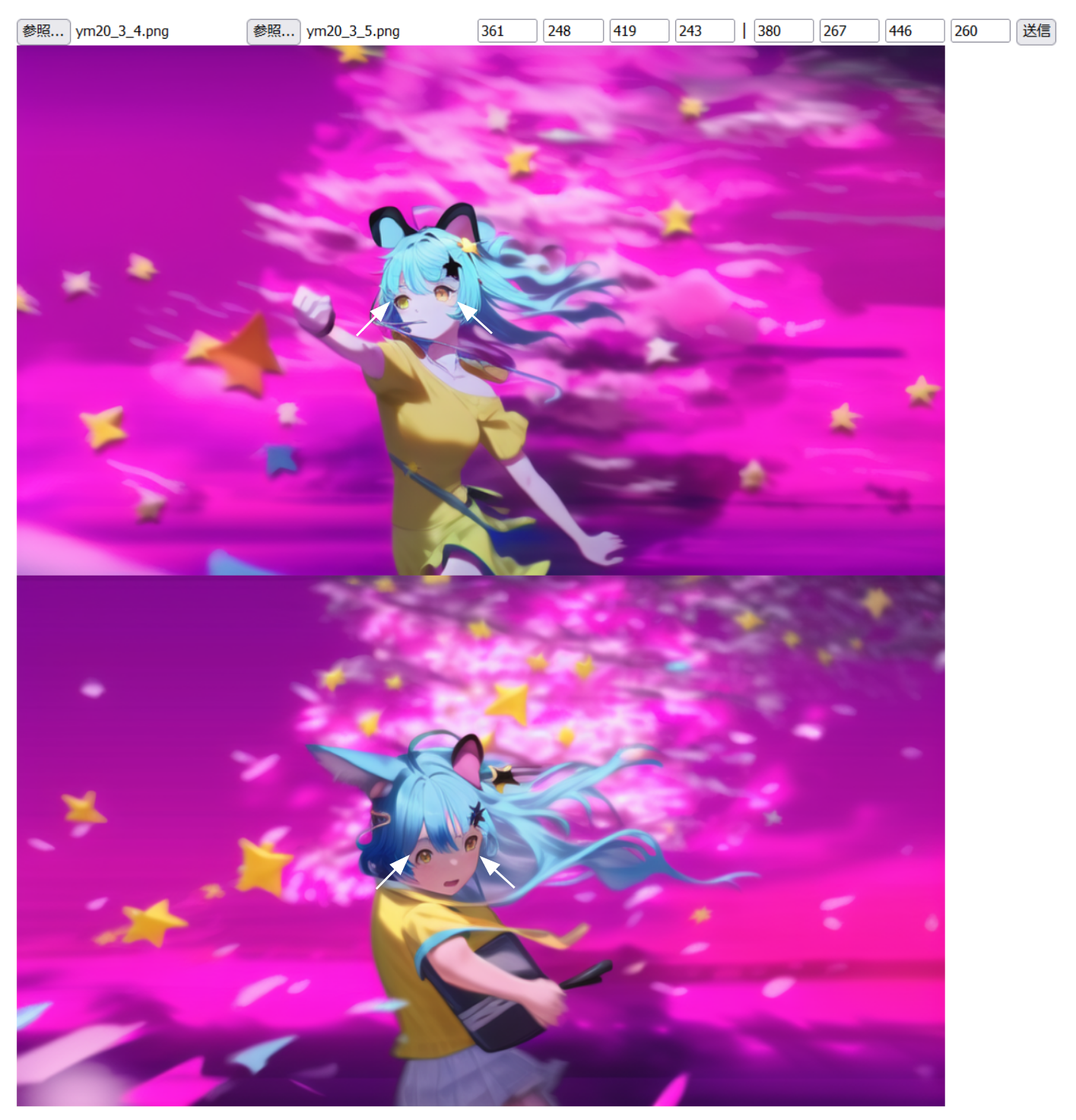
- 「送信」を押すと、画像生成AIに入力するための画像ができますわ
- それぞれの入力画像の特徴点の中間点が、新しい画像でそれらの中間にくるように移動させまして & 縮尺がちょうど中間の縮尺になるように拡大縮尺しまして & 背景が真っ白な部分ができませんように、縮小元の画像を元の縮尺で置いておく …ということをしつつ、50% ずつになる透明度(ただし、1枚の画像しか載っていない領域は元のままの濃さですわ)で重ね合わせていますわ (←今回の記事の核心部分ですわ)

- この入力用画像をNovelAI に入れて image to image で画像を出力させると、動作的にも中間な中割リ画像が得られますわ

- その際、Strength は 0.52 くらい、 Noise は 0.13 くらいだといい感じですわ (前後にずらして調整も可能ですわ)
- (たまに 0.78 0.2 くらいでも上手くハマることもあるかもしれませんわね)
- プロンプトは、前後の画像で使っていたものを使うと良さみですわ
- (NovelAIの場合、DLした.pngをテキストエディタに投げ入れますと、使ったプロンプトが分かりましてよ)
- 発展: 入力画像だけで いい感じの画像が得られない場合は(得られることも多いですわ)、プロンプトの最初のあたりで、中割り画像に求める構図やポーズや効果を指定すると、より効果的ですわ
- 構図、ポーズ、効果指定プロンプト語句の例:
very fast, from behind, from side, looking away, looking at viewer, looking ahead, ※: looking forward, leaning forward, staring, arms up, arms above head, smirk, sharp, close-up, chasing, running, cowboy shot, From diagonal angle, ※: from diagonally opposite, looking down, gentle, realistic, photo realistic, simple background, legs folded, ball on chest (←本当にある), holding ball, bare arms, hidden face (←本当にある), above thighs, outstretched arms- (※: は効くか分からないのですが、とりあえずつけてるものですわ)
- 構図、ポーズ、効果指定プロンプト語句の例:
- 出したくない構図をネガティブプロンプトに追加するテクニックもありますわ
- きれいな絵が出てこないときは↓のような文言を(全部)プロンプトの末尾につけるといいかもしれませんわ
,masterpiece,high quality,best,high resolution,best quality,award winning,highly detailed,hyper extreme detailed,
- ちなみに、下記のプロンプトだと (わたくし解釈の) ゆいもっぷ さんになるので、これを使って ゆいもっぷさん動画を沢山作るといいと思いますわ (ハッシュタグは #もっむび でしてよ)
-
{{{{wavy hair}}}},{{{{{{{{{{{lightblue hair}}}}}}}}}}}, {{{{{{{{{{dog ears }}}}}}}}}}, ahoge, white skirt with blue lines, off shoulder, pannier skirt,sad, {{{{{{{{yellow hairpin}}}}}}}}, {{{{{star hair pin}}}}}, {{{{{yellow star hair ornament}}}}}, blue boots, {{{{{medium hair}}}}}, short skirt, college student, chiba girl,- (目の色について): なお、
purple eyesも ( ゆいもっぷ さんの) 設定としてあるのですが、画像を生成していると、目の色が紫以外になってしまうことがたまにあり、それを採用してしまい、その画像を元にさらに中割り画像を作っていってしまうと、その時に purple eyes を指定していると、コマごとに目の色が 紫以外と 紫とをコロコロ変わって見づらいことになりますわ。 なので、目の色は頑張って「紫に統一するぞ!」みたいなことに失敗した場合は、目の色を指定しない方が見やすい動画になると思いますわ。 - でも、目の色は由来がある ゆいもっぷ さんの大事な要素なので、極力紫にするのがよいですわ
- (目の色について): なお、
- ネガティブプロンプトの例:
split screen, stars in eyes, wink, vest, dog, blurry, gold hair, blonde hair, navy hair, Tail, more than 2 thighs, extra calf, extra legs, bad knee, more than 2 legs,{{{{{{{more than 2 arms, extra arms}}}}}}}(dog earを指定すると dog がついてきやすいのですわ)-
particlesもネガティブプロンプトにおすすめかもしれませんわ
-
-
-
追記:(普通はFullの方を使うので)設定ミスだったのですが、「バスケットゆいもっぷ」はNovelAIのモデルは、NAI Diffusion Anime(Curated) の方で作りましたことよ
- (Fullだともしかしたらもっと絵柄ばらけるかもしれなくってよ)
- こうしてできた中割り画像を入力画像にして、繰り返し中割り画像を作っていくと、どんどん動きが細かくなっていって動画にできますわ

手順 & 原理の実行例ですわ
- 入力画像1, 入力画像2, 画像生成AI入力用画像, AI生成画像 の順に示しますわ
- 例1: かわいいですわ
-
- 例2: ダイナミックなカメラワークの例ですわ
- 例2: ダイナミックなカメラワークの例ですわ
- 例3 でしてよ
- 例4: 地味な例 (動画制作の大部分では、かなり近い2枚の中間画像を得る使い方になりますわ)
- 例5: すごく綺麗な例ですわ



- 出力画像1 (足としっぽ(要らない)がおしい)
- 出力画像2 (これに1の頭をくっつけて使いました)
- 例6: 超助かる例ですわ
- (横向きの移動からダンクシュート後をつなぐ画像(=ダンクシュート中)を出力してくれましたわ)
- ズーム度合いがこれくらい違っても、有用な中割を作れますわ






















手順&原理のポイント
この手法のいいところ
- NovelAI の出力したものに NovelAI をかけるので前後の画像に近い画像になる気がしますわ
- (NovelAIの裁量を高められるので) NovelAI の激うまな描き味を活かせますわ
- そのおかげもあって、美しい ゆいもっぷ さんの表情を印象深く(NovelAIが) 描けたように思いますわ (眼福ですわ)
- NovelAIは動きを描くのも上手なので、ダイナミックな動きが得られますわ
- 例5, 6にある通り、連続性のかなり低い(動作的にかなり離れた) 2枚の画像でも、なんとか中割りを描こうとしてくれて、(元画像の用意する数をものすごく減らせて) 助かりますわ (原画8枚)
- 原理的には、NovelAIでなくても、他の画像生成AIなど画像を生成するものでも使えるはずですわ
補足ですわ
- 動画は ClipChamp という Microsoft の無料の動画作成ソフトで作りましたわ
- AI生成画像の気に入らないところはちょこちょこ SAI (エアブラシ、ぼかしツールなど)で消してますわ (手修正)
- ごくたまに「シャープにする webサービス」なども使ってますわ
- ごくたまに SAI の フィルタ > ぼかし > ガウスぼかし も役立ちますわ
- 服装一貫性は、前後の入力画像(原画)で服装を一致させるのが大事ですわ
- (Strength: 0.52, Noise: 0.13 だと、服装もかなり入力画像に寄ってくれますわ)
今回の動画(「バスケットゆいもっぷ」)のスペック
- 11秒57 (最後の伸ばしたところ除く)
- 動画 78枚
- 6.74枚/秒
- (日本の一般的なTVアニメ(=リミテッドアニメーション)は 8枚/秒)
- 6.74枚/秒
- 原画 8枚
- これ以外の70枚の画像を、中割り生成法で作りました
- (原画もNovelAIで作りました(プロンプト指定 + ちょっとだけ手書き(脇に抱えたボールとゴール)))








- 大きく手で描いた画像 9枚
- ボールの位置までは中間地点で描いてくれませんでしたわ (人体でしたらとても中間で描いてくれますわ)
- (近くにボールが移動するだけならNovelAIが自分で描いてくれますわ)
- ボールの位置までは中間地点で描いてくれませんでしたわ (人体でしたらとても中間で描いてくれますわ)









- 制作中にNovelAIで生成した画像 588枚
- 原画制作中: 53枚 (採用率 15.0%、6.6枚に1枚採用) (= 0 Anlas、i2iではないから0ですわ)
- 動画制作中: 535枚 (採用率 13.1%、7.64枚に1枚採用) (=2675Anlas)
- (難しくない構図なら、3~4枚で採用できます…が、ダンクシュートみたいな難しいのだと15~20枚とかかかりますわ)
制作時間
- 製作時間 14時間50分 (= 890分)
- (単純に動画時間で割ると、 76.9分/秒)
- 原画の制作時間
- 3.8分 / 枚
- 特に入力画像に手を入れない動画画像の作成時間
- 3.8分 / 枚
- 入力画像に手をいれる動画画像の作成時間
- 22.7分 / 枚 (↑ の6.0倍)
- つまり、今回は難しいコマが9枚あったので
- 簡単なところ: 69枚 * 3.8分 = 262分
- 難しいところ: 9枚 * 22.7分 = 204分
- 合計すると、464分だが、実際の作業時間 (890分) は この1.9倍かかってる
- ので、簡単な構図は 7.2分/コマ (=48.7分/秒)、難しい構図は 43.1分/コマ (=291分/秒) が 実際にはかかってそう
- 動画制作ソフトでの操作や、できた動画をチェックしての直しの分が0.9倍分かかっているのだろう
- 今回の11.57秒の動画も、ダンクシュートを入れなかったら、14.8時間 (890分)ではなく、9.4時間 (563分)でできていたはずですわ
アニメOPを作るなら
- アニメOP(80秒)の動いてる部分は 40秒と思う
- 今回の動画の 3.5倍の長さなので、 (今回と同じくらい難しい構図を入れるとしたら) 52時間 (=3115分) あればアニメOPを作れそう
- → 簡単な構図だらけにしよう ( 全部簡単な構図の場合、32.4時間 (=1948分) で作れる (4人日?)) (ゆいもっぷさんの歌の在庫多数)
(AI入力用画像を作るWebサービスの) 実装 (やっとエンジニアリングな内容)
- ↑の手法では、入力用中間画像を作るのがポイントとなりますわ
- ペイント3Dを使って手作業でもできる (ステッカー貼り付けだと透明度が使える) のですが、作業量を大幅軽減するためにプログラムを書きましたわ
- (特に、手作業だと背景の処理とかが大変ですわ)
- でも、 https://chara-zokusei.jp/nakawari で、皆様は実装せずに使えますわ
- キャラ属性王国 さんのご好意で、コードの実行場所を提供していただきましたわ! ありがとうございますですわ!
- 動画ができましたら、できるだけニコ動にも投稿してもらえますと嬉しいですわ
実装の中身 (コード)
(ImageMagick が必要ですわ。あとwebサーバとPHPが動く環境も必要ですわ)
# convert -version
Version: ImageMagick 7.0.8-45 Q16 x86_64 2019-05-13 https://imagemagick.org
Copyright: © 1999-2019 ImageMagick Studio LLC
License: https://imagemagick.org/script/license.php
Features: Cipher DPC HDRI Modules OpenMP(3.0)
Delegates (built-in): bzlib cairo djvu fftw fontconfig freetype gvc jng jp2 jpeg
lcms ltdl openexr pangocairo png rsvg tiff webp wmf x xml zlib
<form action="" method="post" enctype="multipart/form-data">
<input type="file" class="image_upload_button" id="uploaded_image_1" name="uploaded_image_1">
<input type="file" class="image_upload_button" id="uploaded_image_2" name="uploaded_image_2">
<input type="text" id="point1_1x" name="point1_1x" size="4">
<input type="text" id="point1_1y" name="point1_1y" size="4">
<input type="text" id="point1_2x" name="point1_2x" size="4">
<input type="text" id="point1_2y" name="point1_2y" size="4">
|
<input type="text" id="point2_1x" name="point2_1x" size="4">
<input type="text" id="point2_1y" name="point2_1y" size="4">
<input type="text" id="point2_2x" name="point2_2x" size="4">
<input type="text" id="point2_2y" name="point2_2y" size="4">
<input type="submit">
<br>
<img id="preview_uploaded_image_1">
<img id="preview_uploaded_image_2">
<script>
{literal}
// todo: 思いっきり2回書いてるのでこなれてませんわ
document.getElementById('uploaded_image_1').addEventListener('change', function (e) {
var file = e.target.files[0];
var blobUrl = window.URL.createObjectURL(file);
var img = document.getElementById('preview_uploaded_image_1');
img.src = blobUrl;
});
document.getElementById('uploaded_image_2').addEventListener('change', function (e) {
var file = e.target.files[0];
var blobUrl = window.URL.createObjectURL(file);
var img = document.getElementById('preview_uploaded_image_2');
img.src = blobUrl;
});
// ターゲットにする img 要素ですわ
const targetImage1 = document.getElementById('preview_uploaded_image_1');
const targetImage2 = document.getElementById('preview_uploaded_image_2');
// クリックイベント登録ですわ
targetImage1.onclick =( evt )=> {
console.log( `( ${ evt.offsetX }, ${ evt.offsetY } )` );
if ($('#point1_1x').val() == "") {
$('#point1_1x').val(evt.offsetX);
$('#point1_1y').val(evt.offsetY);
} else {
$('#point1_2x').val(evt.offsetX);
$('#point1_2y').val(evt.offsetY);
}
};
targetImage2.onclick =( evt )=> {
console.log( `( ${ evt.offsetX }, ${ evt.offsetY } )` );
if ($('#point2_1x').val() == "") {
$('#point2_1x').val(evt.offsetX);
$('#point2_1y').val(evt.offsetY);
} else {
$('#point2_2x').val(evt.offsetX);
$('#point2_2y').val(evt.offsetY);
}
};
{/literal}
</script>
<?php
if (count($_FILES) >= 2) {
$uploadedImage1 = $_FILES['uploaded_image_1']['tmp_name'];
$uploadedImage2 = $_FILES['uploaded_image_2']['tmp_name'];
$_exploded = explode("/", $uploadedImage1);
$name1 = $_exploded[2];
$_exploded = explode("/", $uploadedImage2);
$name2 = $_exploded[2];
$publicImageDirBase = "/home/xxxx/public_html/image/nakawari/";
$path1 = $publicImageDirBase . $name1;
$path2 = $publicImageDirBase . $name2;
move_uploaded_file($uploadedImage1, $path1);
move_uploaded_file($uploadedImage2, $path2);
$inputPoints = []; // [1,2][1,2]['x','y'] // [1枚目,2枚目][1クリックめ、2クリックめ][x座標,y座標]
$inputPoints[1][1]['x'] = (int)$_POST['point1_1x'];
$inputPoints[1][1]['y'] = (int)$_POST['point1_1y'];
$inputPoints[1][2]['x'] = (int)$_POST['point1_2x'];
$inputPoints[1][2]['y'] = (int)$_POST['point1_2y'];
$inputPoints[2][1]['x'] = (int)$_POST['point2_1x'];
$inputPoints[2][1]['y'] = (int)$_POST['point2_1y'];
$inputPoints[2][2]['x'] = (int)$_POST['point2_2x'];
$inputPoints[2][2]['y'] = (int)$_POST['point2_2y'];
////// 中間点がどこになるか計算しますわ
// それぞれの入力画像でのクリック点(2点)の中間点 = midPoints ですわ
$midPoints = []; // [1, 2]['x', 'y'] // [1枚目の中点, 2枚目の][x座標, y]
$midPoints[1]['x'] = ($inputPoints[1][1]['x'] + $inputPoints[1][2]['x']) / 2;
$midPoints[1]['y'] = ($inputPoints[1][1]['y'] + $inputPoints[1][2]['y']) / 2;
$midPoints[2]['x'] = ($inputPoints[2][1]['x'] + $inputPoints[2][2]['x']) / 2;
$midPoints[2]['y'] = ($inputPoints[2][1]['y'] + $inputPoints[2][2]['y']) / 2;
// 2つの中間点の間をとって、出力する画像での中間点を求めますわ
// (2つの入力画像は、中間点がこの位置に来るような移動処理を後で受けますわ)
$newmid = []; //['x', 'y']
$newmid['x'] = ($midPoints[1]['x'] + $midPoints[2]['x']) / 2;
$newmid['y'] = ($midPoints[1]['y'] + $midPoints[2]['y']) / 2;
////// 2つの入力画像を、新中間点に向けて平行移動させますわ
$movedPath1 = $publicImageDirBase . "move_1";
$movedPath2 = $publicImageDirBase . "move_2";
// moveは距離がマイナスだと反対方向に動かす便利な自作メソッドですの
ImageUtil::move('right', $newmid['x'] - $midPoints[1]['x'], $path1, $movedPath1);
ImageUtil::move('down', $newmid['y'] - $midPoints[1]['y'], $movedPath1, $movedPath1);
ImageUtil::move('right', $newmid['x'] - $midPoints[2]['x'], $path2, $movedPath2);
ImageUtil::move('down', $newmid['y'] - $midPoints[2]['y'], $movedPath2, $movedPath2);
////// 以下、幅の大きさを拡縮して揃えますわ (すると、同じ大きさで重なることになりますの)
$width = []; // [1, 2] 1枚目の指定点間の幅と2枚目の指定点間の幅
$width[1] = $inputPoints[1][2]['x'] - $inputPoints[1][1]['x'];
$width[2] = $inputPoints[2][2]['x'] - $inputPoints[2][1]['x'];
$widthAverage = ($width[1] + $width[2]) / 2;
$toMultiplyProportions = []; // [1, 2]
$toMultiplyProportions[1] = $widthAverage / $width[1];
$toMultiplyProportions[2] = $widthAverage / $width[2];
// 1枚めの画像の高さと幅を新画像の高さと幅にしますわ
// todo: サブメソッドに切れそうですわ
$result = exec("identify ${path1} 2>&1");
$_exploded = explode(" ", $result);
$originalSizes = $_exploded[2];
$_exploded = explode("x", $originalSizes);
$originalWidth = $_exploded[0];
$originalHeight = $_exploded[1];
// 拡縮は、newmid中心に行いますわ
for($i = 1; $i <= 2; $i++){
if ($i >= 3) {
break;
}
//// 拡大の場合
if ($toMultiplyProportions[$i] > 1.0) {
// まず、拡大すると元のサイズになるサイズを とりあえずnewmid中心に切り出しますわ
// …ではなく、centMid(切り出し位置を真ん中に求めた時のmid割合的な位置ですわ)と
// 本当のmidの距離を出しますわ (大学入試で訓練した力が発揮されますわ)
$cutOffWidth = round($originalWidth / $toMultiplyProportions[$i]);
$cutOffHeight = round($originalHeight / $toMultiplyProportions[$i]);
$midProportion = []; // ['x', 'y']
$midProportion['x'] = $newmid['x'] / $originalWidth;
$midProportion['y'] = $newmid['y'] / $originalHeight;
$centMid = []; //['x', 'y']
$centMid['x'] = ($originalWidth / 2) - ($cutOffWidth / 2) + ($cutOffWidth * $midProportion['x']);
$centMid['y'] = ($originalHeight / 2) - ($cutOffHeight / 2) + ($cutOffHeight * $midProportion['y']);
//var_dumP("centMid");
//var_dumP($centMid);
//$cutOffOffsetX = max(round($newmid['x'] - ($cutOffWidth / 2)), 0);
//$cutOffOffsetY = max(round($newmid['y'] - ($cutOffHeight / 2)), 0);
//$cutOffOffsetX = max(round($newmid['x'] - $centMid['x']), 0);
//$cutOffOffsetY = max(round($newmid['y'] - $centMid['y']), 0);
$cutOffCenterX = round(($originalWidth / 2) + round($newmid['x'] - $centMid['x']));
$cutOffCenterY = round(($originalHeight / 2) + round($newmid['y'] - $centMid['y']));
//$cutOffOffsetX = round(($originalWidth - $cutOffWidth) / 2);
//$cutOffOffsetY = round(($originalHeight - $cutOffHeight) / 2);
// ↑ 試行錯誤の跡ですわ (大学入試も何回か試して試行錯誤できれば解けますわ)
$cutOffOffsetX = round($cutOffCenterX - ($cutOffWidth / 2));
$cutOffOffsetY = round($cutOffCenterY - ($cutOffHeight / 2));
$cutOffPath = $publicImageDirBase . "cutoff";
$cutOffInputPath = $movedPath1;
if ($i == 2) {
$cutOffInputPath = $movedPath2;
}
$result = exec("convert ${cutOffInputPath} -crop ${cutOffWidth}x${cutOffHeight}+${cutOffOffsetX}+${cutOffOffsetY} ${cutOffPath} 2>&1");
// 切り出したものを拡大しますわ
$magnifiedPath = $movedPath1;
if ($i == 2) {
$magnifiedPath = $movedPath2;
}
$magnifyPercentage = round($toMultiplyProportions[$i] * 100);
$result = exec("convert ${cutOffPath} -resize ${magnifyPercentage}% ${magnifiedPath} 2>&1");
}
//// 縮小の場合
if ($toMultiplyProportions[$i] < 1.0) {
// まず、そのまま縮小しますわ
$shrinkInputPath = $movedPath1;
if ($i == 2) {
$shrinkInputPath = $movedPath2;
}
$magnifyPercentage = round($toMultiplyProportions[$i] * 100);
$shrinkedPath = $publicImageDirBase . "shrinked";
$result = exec("convert ${shrinkInputPath} -resize ${magnifyPercentage}% ${shrinkedPath} 2>&1");
// つぎに、 newmid 中心に配置しますわ (そのためには、縮小後の画像の幅と高さが必要ですわ)
// 配置先は、元のinput 画像ですわ (overで配置しますわ) (このようにすることで、背景が無い箇所をなくしますわ)
// todo: サブメソッドに切れそうですわ
$result = exec("identify ${shrinkedPath} 2>&1");
$_exploded = explode(" ", $result);
$shrinkedSizes = $_exploded[2];
$_exploded = explode("x", $shrinkedSizes);
$shrinkedWidth = $_exploded[0];
$shrinkedHeight = $_exploded[1];
$shrinkedMid = []; // ['x', 'y']
$shrinkedMid['x'] = $newmid['x'] * $toMultiplyProportions[$i];
$shrinkedMid['y'] = $newmid['y'] * $toMultiplyProportions[$i];
//$overOffsetX = max(round($newmid['x'] - ($shrinkedWidth / 2)), 0);
//$overOffsetY = max(round($newmid['y'] - ($shrinkedHeight / 2)), 0);
//$overOffsetX = round(($originalWidth - $shrinkedWidth) / 2) + round( $newmid['x'] - ($originalWidth / 2) );
//$overOffsetY = round(($originalHeight - $shrinkedHeight) / 2) + round( $newmid['y'] - ($originalHeight / 2) );
//echo "newmid: " . $newmid['x'] . "," .$newmid['y'] . "shrinkedMid: " . $shrinkedMid['x']. "," . $shrinkedMid['y'];
$overOffsetX = round($newmid['x'] - $shrinkedMid['x']);
$overOffsetY = round($newmid['y'] - $shrinkedMid['y']);
// ↑ 試行錯誤の跡2ですわ (大学入試も何回か試せれば解けますわ)
$originalPath = $path1;
$magnifiedPath = $movedPath1;
if ($i == 2) {
$originalPath = $path2;
$magnifiedPath = $movedPath2;
}
$result = exec("composite -gravity northwest -geometry +${overOffsetX}+${overOffsetY} -compose over ${shrinkedPath} ${originalPath} ${magnifiedPath} 2>&1");
}
}
////// 最後に、moveや拡大縮小したものを重ね合わせますわ
$blendPath = $publicImageDirBase . "blend";
$composePath = $publicImageDirBase . "composed";
$output = [];
$result = exec("composite -blend 50x50 ${movedPath1} ${movedPath2} ${blendPath} 2>&1", $output);
// 重ね合わせる時に、片方しか存在しない領域は色が薄くなってしまいますので、
// Xor で重なってないところだけの画像を用意して、最後にそれと重ね合わせますわ
$substractPath = $publicImageDirBase . "substruct";
$result = exec("convert ${movedPath1} ${movedPath2} -compose Xor -composite ${substractPath} 2>&1", $output);
$result = exec("composite -compose darken ${blendPath} ${substractPath} ${composePath} 2>&1", $output);
}
<?php
class ImageUtil{
/**
* 逆方向を返しますわ
* @param String 'down' / 'up' / 'right' / 'left'
* @return String
*/
public static function reverseDirection($direction) {
switch ($direction) {
case 'down':
return 'up';
case 'up':
return 'down';
case 'right':
return 'left';
case 'left':
return 'right';
}
}
/**
* 指定した方向に、画像全体を動かし、元の方向に余白をつけます (移動した方向に見切れます)
* (ImageMagick に元からあるコマンドでは、はみ出た部分が反対側から出てくきますので、
* このメソッドがありますわ)
* @param direction string 'down' / 'right' / 'up' / 'left'
*/
public static function move($direction, $distance, $inputPath, $outputPath) {
$distance = round($distance);
// distance がマイナスだったら向きを逆転させますわ
if ($distance < 0) {
$direction = self::reverseDirection($direction);
$distance *= -1;
}
$transparentPath2 = $inputPath;
$movedPath2 = $outputPath;
// todo: このあたりもメソッドに切れるといいですわね3
$result = exec("identify $transparentPath2 2>&1");
$_exploded = explode(" ", $result);
$sizes = $_exploded[2];
$_exploded = explode("x", $sizes);
$width = (int)$_exploded[0];
$height = (int)$_exploded[1];
switch ($direction) {
case 'down':
$splice = '0x' . $distance;
$gravity = 'north';
break;
case 'up':
$splice = '0x' . $distance;
$gravity = 'south';
break;
case 'right':
$splice = $distance . 'x0';
$gravity = 'west';
break;
case 'left':
$splice = $distance . 'x0';
$gravity = 'east';
break;
}
// ↓ では、確かに下にずらせましたが、頭の色が上余白に引き伸ばされましたわ
//$result = exec("convert $transparentPath2 -distort Affine '10,10 10,110' $movedPath2 2>&1", $output);
// ◎↓ これで、上に 100px 伸ばせましたわ
$result = exec("convert $transparentPath2 -alpha set -background none -channel RGBA -fill '#00000000' -mattecolor '#00000000' -gravity ${gravity} -splice ${splice} $movedPath2 2>&1",$output);
// 元の大きさに、 gravity を指定しつつ、切り取りますわ
// (下を削りたいときは gravity は north ですわ)
$result = exec("convert $movedPath2 -background none -gravity ${gravity} -extent ${width}x${height} $movedPath2 2>&1", $output);
}
}
- 動作するようになったら、早速使いたい訳ですから、リファクタできてなくても仕方ないですわね
実装のポイント
- 最後のブレンド、 25x75 にするか 50x50 にするか 悩ましいところもありますわ
- 片方の入力画像で背景が黒くて服が白かったりすると、50x50 だとあまり綺麗に重なり合わない場合もあるかもしれませんわ
- ImageMagickの公式ドキュメントはこちらですわ
うまくいかなかった方向性
- 実は方向性を試行錯誤しましたわ (なので 支援システム作りに17日間かかりましたわ)
- うまくいかなかった方向性
- クラウドサービスでよくある 画像認識 (顔の左上や目の左端などの座標をとれるもの) サービスで特徴点を取ろうとしましたわ
- 動画製作だと、10ピクセルくらいズレるとダメなのですが、わたくしが試したサービスだと、それ以上にズレましたわ(動画製作用途には使えなさそうでしたわ) (大手2社を試しましたわ)
- でも、外部サービスだと、すぐに試して、すぐに使えるか否かの判断ができますからいいですわね
- 2枚の前後画像をズラしていきながら重ね合わせて、 ImageMagick compare で 色の類似度が最大になる移動距離を探しましたわ
- 結構処理が重かったですわ (画像処理が)
- きれいに重ならない場合が多かったのよ (腕とかバリバリうごいてますし、画面外に見切れてる事も多いため)
- そういう特徴点を自動で取ることができたら、自動化度合いを高められたのですが、うまくいかなかったので、妥協して、使う人間が入力することにしましたわ
- (最初理想を追って、自動化率高めで挑戦するけど、結局妥協してそこそこの自動化度合いに落ち着くのは個人開発によくあることでございますわね)
- クラウドサービスでよくある 画像認識 (顔の左上や目の左端などの座標をとれるもの) サービスで特徴点を取ろうとしましたわ
- うまくいかなかった方向性
今後
- AfterEffect? などで映像効果を使えるようにしたいですわ
- 次のゆいもっぷアニメPVを作りたいですわ
- 特に、大量にカラオケ配信の録画が残ってるので、それに合う動画を作りたくってよ
- もっと複雑な服装で試してみたいですわ (セーラー服とか)
- nijijourney を調べたいですわ
課題
画像生成の課題
- simple background で出力して、背景は後で合成の方がいいのかもしれませんわね
- NovelAI は 背景も迫力あるので、できれば活用したいものではありますわ
- 今回の中割り生成手法は、人体の動作の中割はとても作れるのですが、ボールが大きく動く場合の中割りは全然作れませんでしたわ
- ダンクシュートよりも前のところは、1箇所 (左から右に持ち変える所) 以外は、ボールの動きはNovelAIのなすがままにしておいたのですが、ダンクシュートのところは自分で入力用画像に手をいれましたわ
- 服装一貫性が結構高いとはいえ、余計なものがつくことがそこそこありますわ
- なので、NovelAIの出力の選別も要るし、場合によっては SAIで消す必要も出てきますわ (=フル自動ではなくってよ)
- (動画は一瞬なので、適当に消してもバレませんわ)
- とはいえ、↑にもありましたが、自動化率100%にならなくても上手く回るケースもありますわ
- なので、NovelAIの出力の選別も要るし、場合によっては SAIで消す必要も出てきますわ (=フル自動ではなくってよ)
動画制作の課題
- コンテ(どんな動画にするかの計画)を作ってから作る
- 秒間8枚にするには「1秒でどれだけ動かす」の計画が必要
- あと、今回の動画も、最初の走るシーンが短かった
- 最初の8枚くらいの原画の時点で、服装を一致させるだけでなく、見た目年齢など、見た目全体を一致させる
- (そうでなかったので、今回は動画が進むにつれて若返った)
- 動画で描いた ゆいもっぷ さんが本人と性格が違う気がしますわ (本人はもっとおしとやか)
- あと本人はバスケ部ではなくて剣道部ですわ (ゆいもっぷ けんどうぶ)
おわりに
- 個人勢 Vtuber 向けとしてはかなり大迫力な、 ゆいもっぷ さんの アニメ映像を作れて満足ですわ
- ゆいもっぷ (https://twitter.com/yui_mop) さんがめちゃかわでしたわね! 次回の配信も楽しみでしてよ。
- 1日目の記事はこちら!
次の記事
(2023/02/10 09:59: 次回作ができました!(9fps化) https://ao-love-yuimop.hatenablog.com/entry/2023/02/10/094800 )