TL; DR
- 東京のふ頭でヒアリの女王アリ50匹以上確認され、広範囲に分散すると国内に定着するおそれがあると環境省が言っているらしい[1]が、アリを見て、ヒアリかそうでないかなど一般人にわかるはずもない
- そこで、一般人でもアリを見てヒアリか判断できるように、AutoMLなるナウい機械学習技術を使い、写真からヒアリかどうか判別できるサービス(外部)を作った。
- 本記事ではAutoMLの技術的詳細ではなく、ビジネスで大切とされる、AutoMLを使ったサービスの作り方を説明することを目的とする。また、 実際にサービスの作成や運用にかかったコストを説明 することも目的とする。
想定している読者層
サービス企画職、サービス開発職、それらの卵である学生の人たち
はじめに
断り書きとして、ヒアリのようなアリをみつけた場合は、下記にある環境省のサイトを御覧ください。
なお、本記事はCyberAgent Developers Advent Calendar 2019の12日目です。
さて、日本は技術立国と言われ久しいですが、技術立国の通り、大量の材料を輸入し、大量の加工品を輸出している国であります。輸入や輸出により、我々は豊かな生活を送ることができています。しかし、その副作用として、本来運ぶ予定のなかった「招かれざる客」が輸入品に紛れて国に入ってくることがあります。その「招かれざる客」とは外来生物のことです。外来生物は従来の生態系を脅かすだけではありません。その代表例がヒアリと呼ばれる、非常に攻撃性と繁殖力の高い外来生物です。

図1 ヒアリの写真例
このヒアリがもし国内に定着すると、生態系を破壊するだけではなく、ヒアリが人間を襲うおそれがあります。幸い、現在、国内に定着していることは確認されておりません[1]。しかし、政府の発表の通り、輸入の最前線である埠頭でヒアリが発見されることがあります[1]。そこで、このヒアリがやってくる問題を解決するために、以下の3つの方法を考えました。
- あらゆるものを輸入しない
- ヒアリを含めたアリをすべて駆逐する
- どうにかしてヒアリだけを見分けて早期に撃退する
これらの問題点について考えたところ、以下の通りとなりました。
- あらゆるものを輸入しないとなるとそもそも国の経済が破綻するため、ボツ
- アリをすべて駆逐すると生態系そのものが壊れるため、ボツ
というわけで、3.の「どうにかしてヒアリだけを見分けて早期に撃退する」に主眼を置きます。
どうやったらアリの中からヒアリだけを見つけることができるのでしょうか。ヒアリかどうか怪しいアリを一般の方が発見したしても本当にヒアリかどうかは見分けらません。普通に考えると、疑わしいアリの写真を撮って、専門家に確認してもらう方法[2]があります。しかし、そんなにヒアリの専門家がいるわけではありません。みんなで問い合わせたら、専門家が過労で倒れます。
そこで現代の叡智の結集こと、画像認識技術でアリの判別を機械に行ってもらえば良いという話が出てきます(やっと本題だね!)。
画像認識技術は数学の塊でわけわかりませんが、幸いなことにAutoMLという素人にも画像認識技術をかんたんに取り扱うための技術があります。
本記事では、アリの中からヒアリだけを見つける方法とその方法を見つける手段AutoMLをかんたんに説明します。次に、実際にWebサービスとしてデモをして、AutoMLを用いたサービスを体験してもらうことも目的とします。また、そのサービスの作り方も説明し、理解してもらうことも目的とします
問題の具体化
ここではユーザに安全で簡易的な方法として、アリの遠くからアリが写っている写真をスマホなどで撮って、アリの専門家という役割の画像認識アルゴリズムに写真を共有してアルゴリズムに判定してもらうことを考えます。このようにアリの中でも、写真といった画像からアリの種類を調べる問題を詳細画像識別[3](Fine-Grained Image Classification[4], Fine-Grained Visual Categorization[3])といいます。
この詳細画像識別を解くのは画像認識アルゴリズムであり、そのコアとなる部分が画像認識モデルです。しかし、画像認識アルゴリズムそのものは一般のユーザに使いづらすぎるので、この詳細画像識別を解く方法を、Webサービスという形で提供することを考えましょう。それでは、専門家という役割の画像認識アルゴリズムをどうやったら開発者がサービス開発に使えるのかを説明しましょう。
ヒントはAutoMLという画像認識モデルを作成できるアルゴリズムです。
モデルを使ったり作成できたりするAutoMLってなんだ
AutoMLとは参考文献[5,6,7]をまとめると
「人間が機械学習モデルを作成する手続きを一部自動化した手法」
という概念のような気がします。機械学習モデルの中には画像認識モデルも含まれています。特に明確に決められた概念ではないのではないようです。エンジニアではない人が手軽にモデルを構築したり、人間では作れないほど複雑なモデルをエンジニアが構築するために使われるようです。手軽に使えるAutoMLとしてGoogleのCloud AutoMLがあります。そこで、今回は、入門編として、Cloud AutoMLのAutoML Visionを用います。
AutoML Visionそのものの使い方は公式のチュートリアルやその他に書いてくださった方(その1、その2)がいるので、そちらをまずご覧になったほうが良いと思います。
本記事では、AutoML Visionを使った「サービスの作り方」に主眼をおいていこうと思います。
サービスの作り方
まず、全体のイメージを湧きやすくするためにデモページを作ったので、試してみてください。
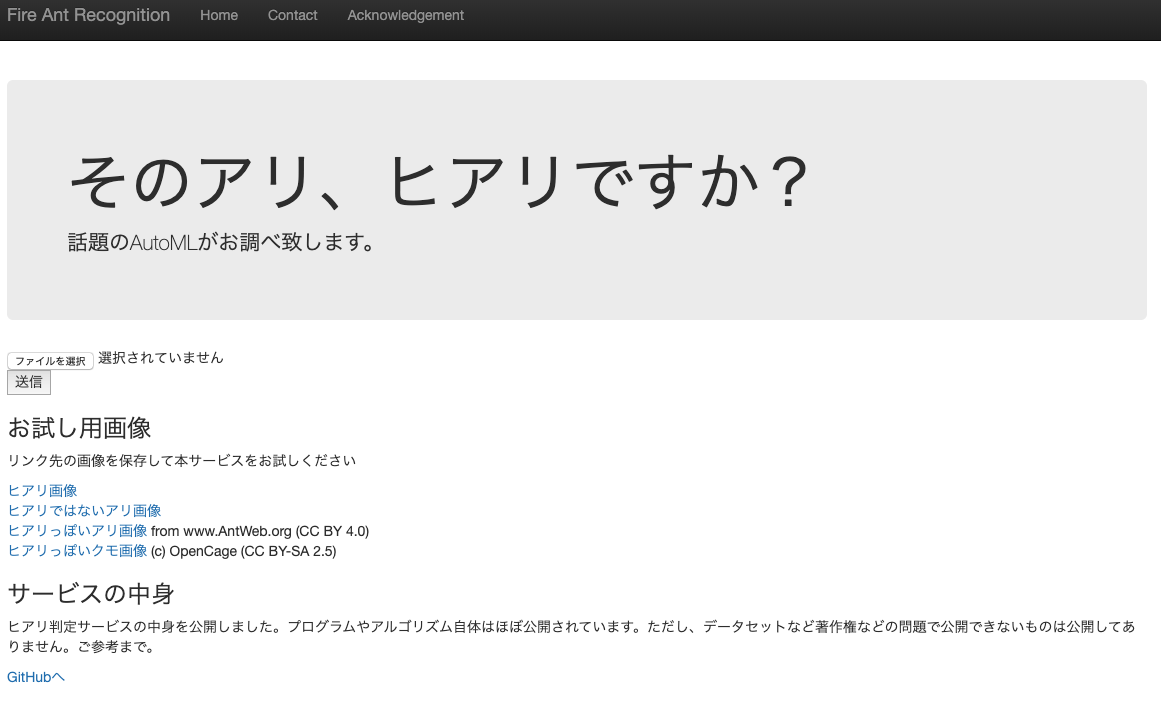
図2 デモページのスクリーンショット
さらに全体のイメージを湧きやすくするために全体のブロック図を図3に描いてみました。
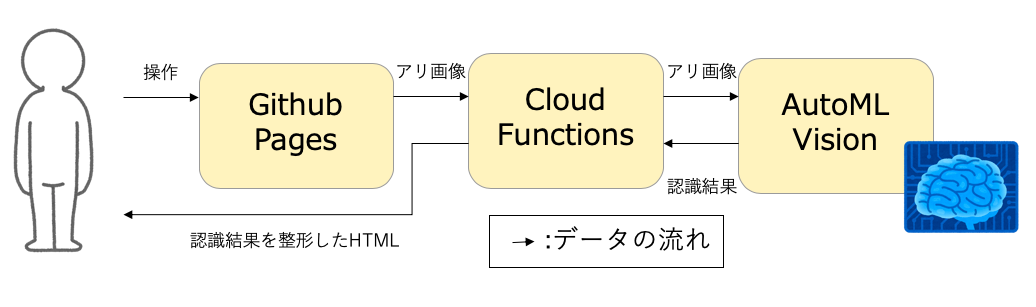
図3 ヒアリ判定サービス全体のブロック図
ユーザインタフェースはGitHub Pagesで具体的な処理はCloud FunctionsとAutoML Visionで構築されています。それぞれ、具体的な役割は次節以降のとおりです。
GitHub Pagesでやっていること
GitHub Pagesではユーザが使い方に戸惑わないようにサービスの使い方や例を表示し、AutoML Visionへ画像を投稿するインタフェースを提供しています。ここでは全体のページから関連する場所だけ抜き出します。余談ですが、この記事に記載されているコードはすべてPublic Domainと明記しておきます。勝手に使ってください。
<div class="jumbotron">
<h1>そのアリ、ヒアリですか?</h1>
<p>話題のAutoMLがお調べ致します。</p>
</div>
<form action="https://us-central1-fireantrecognition.cloudfunctions.net/FireAntRecognition" method="POST" enctype = multipart/form-data>
<input type="file" name="image" size="16" value="" accept="image/jpeg"/>
<input type="submit" value="送信"/>
</form>
見ての通り、Cloud FunctionsへHTTPで画像をPOSTしているだけです。ユーザインタフェースをCloud Functionsに組み込めないこともないですが、URLが混沌としすぎていて第一印象がよくないため、やめておきました。また、Stack Overflow(プログラミングの質問サイト)を見てみると、一般的なWebサービスでも静的なページはApacheやnginxなどの本格的な運用ソフトを使うことが多いらしく、Flaskはあくまで動的で試作的なものに向いているだそうです。
Cloud Functionsでやっていること
Cloud FunctionsではGitHub PagesでPOSTされた画像をリサイズしてAutoMLに画像を渡したり、AutoMLからの結果をHTMLとして見やすい形を整えることをやっています。ここでは例によって全体のページから関連する場所だけ抜き出します。
def recognizeByAutoMLVision(request):
from flask import render_template
# リクエストがポストかどうかの判別
if request.method == 'POST':
# ファイルがなかった場合の処理
if 'image' not in request.files:
return render_template("error.html",reason="ファイルが取得できないため")
# ファイルに関するデータの取り出し
file = request.files['image']
# ファイル名がなかった時の処理
if file.filename == '':
return render_template("error.html",reason="ファイル名が取得できないため")
# ファイルの存在チェック
if file:
import base64
import cv2
import numpy as np
# 非公開なパラメータを入れておくところ
import Params
from google.cloud import automl_v1beta1
MAX_WIDTH=640
# ペイロードの作成。大きすぎる画像をリサイズ。
img_array = np.asarray(bytearray(file.stream.read()), dtype=np.uint8)
img = cv2.imdecode(img_array, 1)
if(img.shape[1]>MAX_WIDTH):
img= cv2.resize(img,(MAX_WIDTH,int(img.shape[0]*MAX_HEIGHT//img.shape[1])))
encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 85]
result, encimg = cv2.imencode(".jpeg",img, encode_param)
# GoogleのAPIはbytes、表示するHTMLはbase64の文字列でないといけないらしい
imageBin = base64.b64encode(bytes(encimg))
imageString=imageBin.decode()
payload = {'image': {'image_bytes': bytes(encimg)}}
client = automl_v1beta1.AutoMlClient.from_service_account_json(Params.keypath)
prediction_client = automl_v1beta1.PredictionServiceClient.from_service_account_json(Params.keypath)
params = {"score_threshold": bytes(b'0.5')}
model_full_id = client.model_path(Params.project_id, Params.compute_region, Params.model_id)
response = prediction_client.predict(model_full_id, payload,params)
# 地味にここがミソでクラスの詳細がドキュメントにかかれていないので苦労した
response=response.payload[0]
resultString = "ある" if result == 1 else "ない"
# 画像を含んだ結果をHTMLに埋め込む
# 画像を埋め込んだ理由はCloud FunctionsからStorageにアップロードできないように作られているためである
# (不正なアップローダー防止の対策とはいえ、めんどくさい仕様だ・・・
return render_template("result.html",
image_string=imageString,
class_name=f"class_{result}", result=resultString)
# GETなどの例外処理
return render_template("error.html", reason="想定されていないため")
# 参考URL
# https://flask.palletsprojects.com/en/1.1.x/patterns/fileuploads/
# https://cloud.google.com/vision/automl/docs/base64?hl=ja
# https://cloud.google.com/vision/automl/docs/predict?hl=ja#automl-nl-example-python
# https://qiita.com/iss-f/items/fcc766fca27f3685025d
通常、こういったサーバレスアーキテクチャの操作にはNode.jsが使われることが多いのですが、今回はあえてPython+Flaskを使っています。なぜならば、PythonはOpenCVのラッパーが昔からあり、画像処理にとても向いているという性質があるからです。余談ですが、前回ヒアリ判定サービスを作ったときはNode.jsを使っていました。自分の専門分野であるクラウドサービスを使ったIoTデバイス試作にはNode.jsが向いており、その関係上とっつきやすかったからです。
AutoML Visionでやっていること
AutoML Visionでは、Python用ライブラリ経由でCloud Functionsから受け取った画像を、AutoML Visionで事前に作ったモデルに入力し、その入力に対する認識結果をPredictResponseというGoogle自作のクラスとしてCloud Functionsに返しています。AutoML Visionは認識するためのモデルを作る機能とそのモデルを使って画像の中身を認識する機能があります。今回はサービス提供にはその後者を使っています。
余談: AutoML Visionで事前に作ったモデルの性能について
一応、AutoML Visionは認識するためのモデルを作った話も説明しておきます。今回は過去に自力で集めたヒアリデータセットを事前に準備しています。ヒアリデータセットにはアリが写っている画像しか含まれておらず、そのアリがアリかヒアリかの情報をフォルダ名で保存しています。アリの画像は2668枚あり、この内ヒアリの画像は714枚、ヒアリでないアリの画像は1954枚で構成されています。これを学習セット2401枚と検証セット267枚に分けて学習させた結果、平均適合率は0.972(!)となる学習モデルが構築できたようです(図2、図3)。今回はこのモデルをデプロイしてヒアリ判定サービスに用いています。
 図4 ヒアリ認識モデルのROCカーブ(曲線の内側、特に塗られている場所が広いほど、性能が良い)
図4 ヒアリ認識モデルのROCカーブ(曲線の内側、特に塗られている場所が広いほど、性能が良い)
 図5 ヒアリ認識モデルの混合行列(斜めのマスが高いほど性能が良い)
図5 ヒアリ認識モデルの混合行列(斜めのマスが高いほど性能が良い)
サービスのテスト
以上の通り、AutoMLで作ったヒアリ判定サービスを実際に試してみます。
テストデータは、一般的なヒアリの画像とヒアリでない画像、
そして、最近公開された東京埠頭で見つけた女王アリ[1]も判定してみましょう。
まず、以下のヒアリの画像認識結果です。

図6 ヒアリの画像を判定させた結果
次に、ヒアリでない画像を判定させてみましょう。

図7 ヒアリではないアリの画像を判定させた結果
次に、最近公開された東京埠頭で見つけた女王アリも判定してみましょう。

図8 東京埠頭で見つかった、ヒアリの女王アリの画像を判定させた結果(写真は[1]より引用)
図6と図7、図8の通り、AutoMLで作ったモデルはヒアリかそうでないアリか正しく判定できていることがわかります。
作成コストと運用コスト
今回、このサービスを作成し、実際に1週間程度運用した結果、3万円程度かかることがわかりました。この要因として、作成や運用にTesla V100という高級なハードウェアを利用しているためとなります。Tesla V100は通常購入すると100万円程度かかることから、3万円に収まったのはとてもコスパが良いと思われます。ただ、個人で運用するにはちょっと無茶がありますね。特に運用時には常にTesla V100を専有するため、お金がそこそこかかります。
具体的には以下の通りとなりました。参考に運用コストの推移を図9に示します。ただし、無料枠を一部使っていたり支払いが外貨ベースであるため、別のタイミングで作成運用するとコストがだいぶ変わる可能性があります。また、自分の人件費は0円としています。(俺を雇ったときの人件費は秘密だよ!)
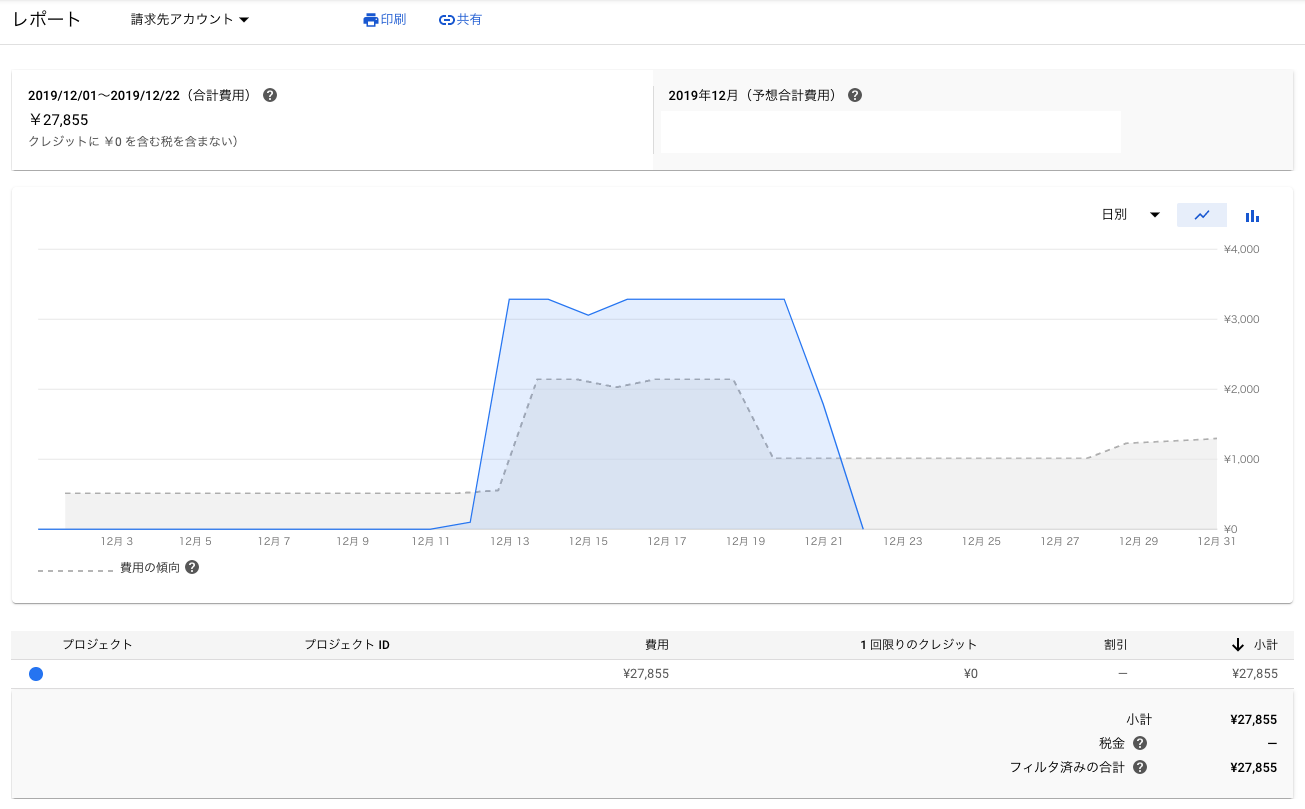
図9 AutoML Visionの運用コストの推移
- 作成コスト(イニシャルコスト):
- 約2,000円(税抜)
- 1カウント時間
- 運用コスト(ランニングコスト):
- 約28,000円
- 約204時間
なお、Cloud Functionsのコストはほとんど0に近いです。サービス企画職ではサービス企画段階でのコストの見積が大切となってきますので、参考にしていただければ幸いです。
頻繁にアクセスされるサービスにAutoML Visionを適用するならばよいのですが、たまにアクセスされるような本サービスだと全部サーバレスアーキテクチャで組み直したほうがコスト的に良さそうです。
考察
AutoML Visionを含むヒアリ判定サービスにより、ヒアリかヒアリでないかを判定させることが現場の画像からでもできました。しかし、現状のAutoML Visionで作成されたモデルには説明性がかけています。果たして本当にアリを見て判断したのか、はたまた背景を見て判断したのかよくわかりません。その点についてもアリの場所を検出してアリで判定するように全体のアルゴリズムを修正する必要があるかもしれません。
これは余談ですが、機械学習の予測には人間への説明性がかけているという問題が機械学習アルゴリズム全般的にあります。その問題を解決するための、説明可能なAI(Explanable AI; XAI)という技術が提案されています。もし、ヒアリを駆逐するなどの意思決定を行う際の材料としてAIを使いたい場合はAutoMLではなく、そちらを利用することも便利でしょう。なお、このXAIの流れに関連してか、Google CloudではAIのモデルを理解しやすくするためにModel Cardsというサービスを提供しています。
まとめ
本記事では、アリの中からヒアリだけを見つける方法とその方法を見つける手段AutoMLを説明し、実際にWebサービスとしてデモをして、AutoMLを用いたサービスを体験してもらうことを目的としました。実際お試しいただけたでしょうか。また、そのサービスの作り方も説明しました。ご理解していただけたでしょうか。
こういったAutoMLを用いたサービスはエンジニアだけではなくサービス企画者に簡易にシステムの実装手段を提供してくれます。AIの民主化に向けてエンジニアは日々技術を開発していくのです。
ポエム
今回のようにあえてAutoMLそのものではなく、それを使ったサービスを説明したのにはわけがあります。それはAIという真新しい手段に気を取られ、どういった価値をユーザーに提供するのかを忘れがちになってしまうサービス開発やサービス企画の人たちへメッセージを送りたかったからです。機械学習などのアプローチを採用することは良いと思いますが、最終的にどんな価値を提供できるのかを考え、サービス開発や技術開発を行いたいところです。あとはAutoML自体はそう新しいものでもなく、すでに1年前からお試し記事はありましたし、今年の他のアドベンドカレンダーにも出てきているので、単に解説してもしようがないかなというところがあったためです。
参考文献
[1] 環境省, "東京港青海ふ頭におけるヒアリの確認について(令和元年10月10日の続報)", https://www.env.go.jp/press/107355.html
[2] 環境省, "ヒアリ同定マニュアル",2019, https://www.env.go.jp/nature/intro/2outline/attention/file/hiaridoutei_Ver.2.0.pdf
[3] 中山 英樹,"タカとハヤブサはどこが違う?", http://www.nlab.ci.i.u-tokyo.ac.jp/pdf/ssii2014fgvc.pdf
[4] https://paperswithcode.com/task/fine-grained-image-classification
[5] HELLO CYBERNETICS,"AutoMLとは?",https://www.hellocybernetics.tech/entry/2019/02/09/155618
[6] https://www.automl.org/
[7] Barret Zoph, Quoc V. Le, "Neural Architecture Search with Reinforcement Learning", https://arxiv.org/abs/1611.01578