皆さん、Yahoo!検索大賞 2017はご覧になりましか?
このアワードで大賞に輝くと、「今年の顔」の名誉を手に入れることができるんです。
そんな栄えある今年の大賞は、ブルゾンちえみとのこと。
他にも、俳優部門は高橋一生、女優部門は吉岡里帆、といった具合に各分野毎に受賞者がいます。
ところで、僕はあまりテレビを観ないので、誰が誰やらわかりません。
このままだと安心して2018年を迎えることができないので、画像を読み込んでそれが誰なのか判定するアプリが必要です。
一目見れば区別つきそうなものですが、僕の濁った目で直接見るよりも、機械に判定させた方がよいに決まっていますので、作ってみました。
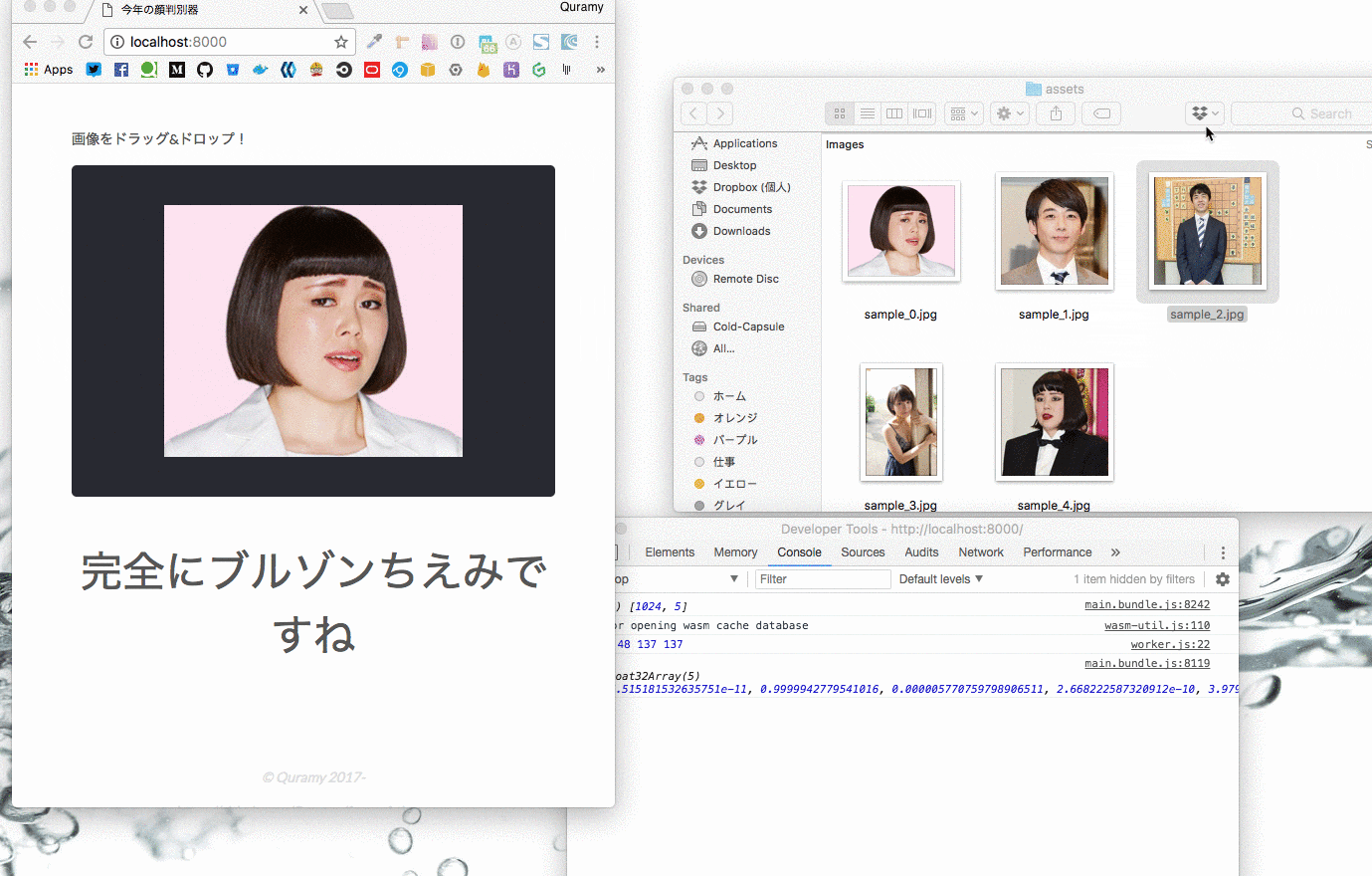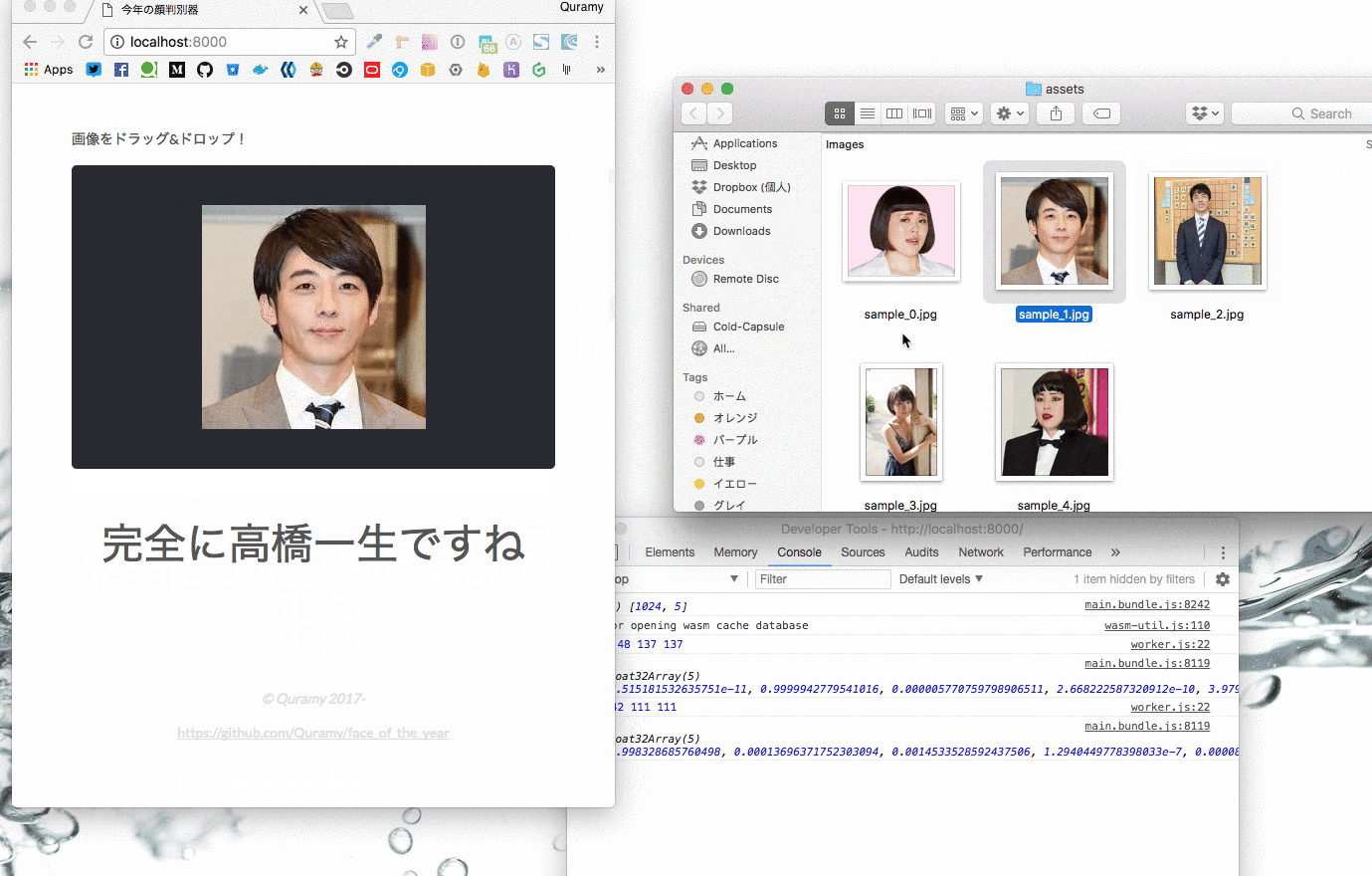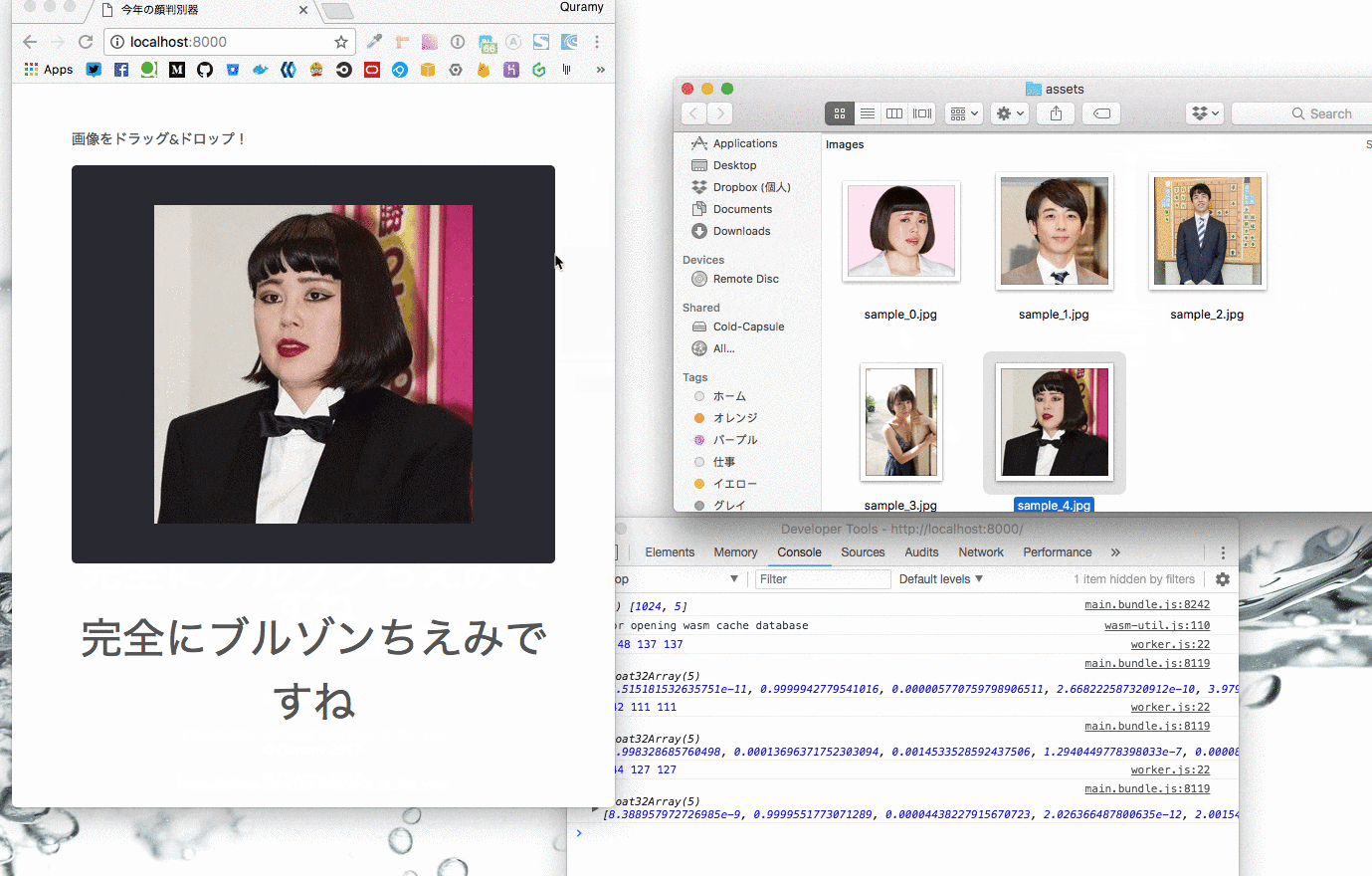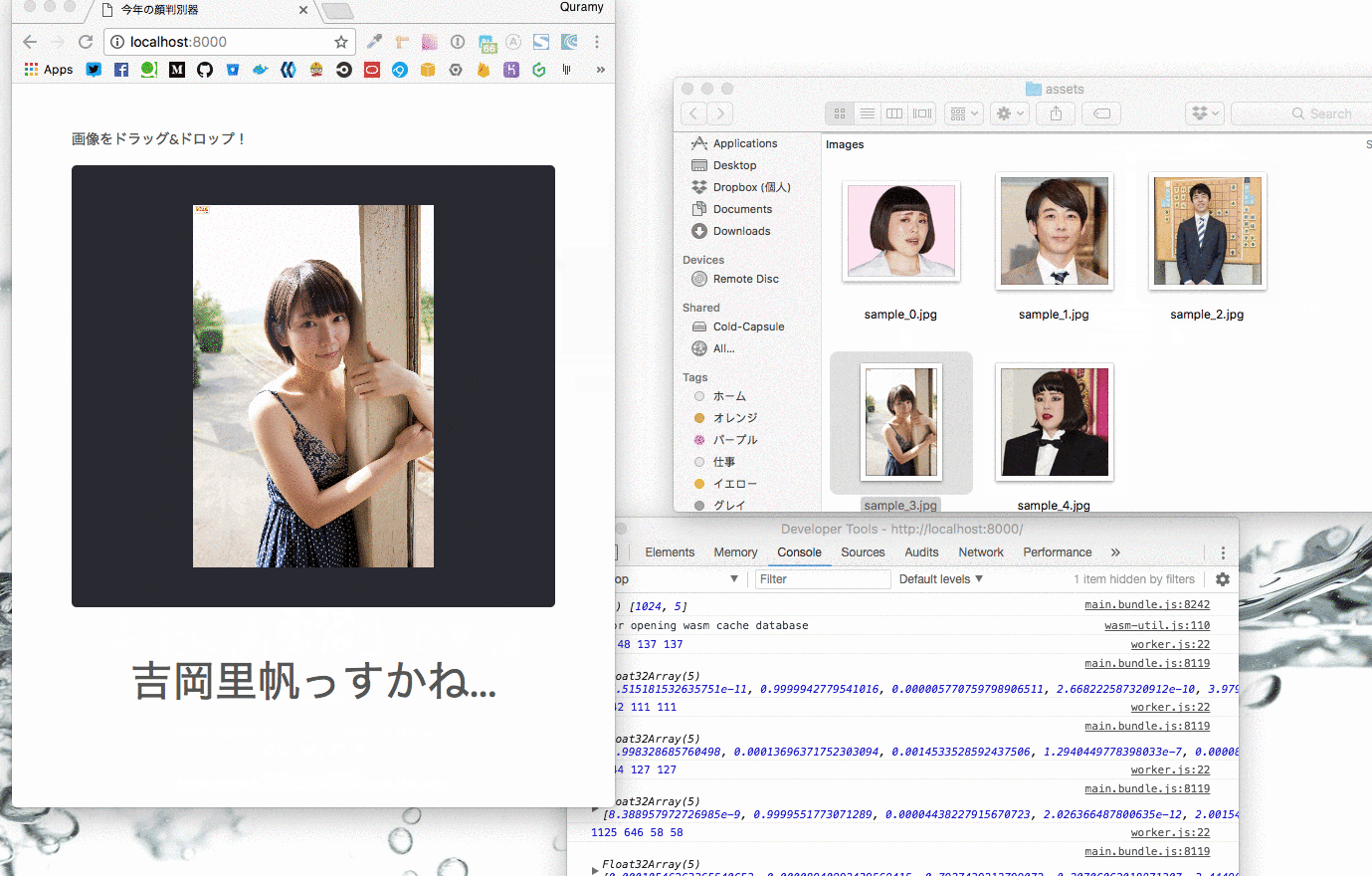
今回はブルゾンちえみも含め、Yahoo!検索大賞の受賞者から以下の5人をピックアップし、判別できるようにしています。
- ブルゾンちえみ(お笑い部門)
- 高橋一生(俳優部門)
- 吉岡里帆(女優部門)
- カズオ・イシグロ(作家部門)
- 藤井聡太(スペシャル部門)
ちなみにテストデータに対する正答率は8割程度なので、まだ割と甘々です。
実装プラン
ここから作り方の説明です。
主に以下の技術を使用していきます。
- 顔検出: OpenCV
- 顔判別: TensorFlow
また、デモに示したとおり、このアプリケーションはブラウザ上で動きます。より正確には、顔検出、顔判別の両方ともブラウザで処理しているという意味です。
処理の大まかな流れは次のようになります。
- TensorFlowで事前に訓練を済ませておき、モデルを保存しておく
- ブラウザで画像を読み込む(カメラ or FileReader or imgタグ, etc...)
- OpenCVで顔を識別して切り出す
- 3で切り出した画像を、1の訓練結果のモデルに入力して評価
- 誰だかわかる
単純ですね。3と4の部分、すなわちOpenCVとTensorFlowをおりゃっとWeb Assembly化すればあっさり終わりそうです。
これまでにもOpenCVのwasm化は何度かやったことがありますし、TensorFlowについても、tensorflow-emscriptenというレポジトリがあるので、
これを使ってさくっとポーティングすれば完成したも同然です。チョロいぜ。
、、、などと思って、進めていたのですが、あえなく頓挫しました。
tensorflow-emscriptenのクリーンビルドが6時間くらいかかる上に1、ビルドされたwasmを使ってデモを動かそうにも、全く動作しない状況です。
そこで4のTensorFlowモデル評価の部分については、Web Assemblyにポーティングするのは諦め、今回はdeeplearn.jsを使うことにしました。
emscriptenでもWeb Assemblyでもないんだけど、まぁ広い意味で他言語で実装されたフレームワークのjsポーティングなので許してほしい。
データ収集
「検索大賞」はYahooが主催しているアワードなのですが、それはそれとしてGoogleで画像を検索しましょう。
画像が手に入れば手段は問いません。僕はPuppeteerでスクレイパを書きました。
どうでもいい知見が得られた。
googleの画像検索結果画面をpuppeteerでスクレイピングするときは、最初からviewportを巨大にしておくことで、400枚(+もっと見るボタン)を描画させられる
— Yosuke Kurami (@Quramy) 2017年12月8日
収集した画像郡から顔部分を切り出して、訓練データとテストデータを作ります。
顔検出はOpenCVのHaarカスケードを用います2。
cascade_path = '../opencvjs/test/data/haarcascade_frontalface_default.xml'
classifier = cv2.CascadeClassifier(cascade_path)
for f in glob.glob('data/raw_images/*'):
img = cv2.imread(f)
faces = classifier.detectMultiScale(img, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1))
if len(faces) == 1:
rect = faces[0]
roi = img[rect[1]:rect[1] + rect[3], rect[0]:rect[0] + rect[2]]
cv2.imwrite(f.replace('raw_images', 'faces'), roi)
ここでは、顔が1つのときのみ、矩形切り出しした画像を保存しています。
これで大量のブルゾンちえみの顔が手に入ります。
画像検索結果やOpenCVの誤検出により、実際は別人の顔画像も保存されてしまうため、それらは目で見て取り除き、訓練データ及びテストデータとしました。
モデル作成(Python側)
Deep MNIST for Experts に書かれてるのと同じ、畳込みとプーリングを2回行うConvolutional Neural Network(CNN)を作ります。
こことかが参考になりました。
下のコードはほぼコピペなのですが、後にdeeplearn.jsで復元するときに判別しやすいよう、tf.Variable 使って変数をスコープに配置する際に、name=... で名前を付けておきました。
def inference(images_placeholder, keep_prob):
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name='weights')
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name='biases')
# 畳み込み層の作成
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
# プーリング層の作成
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 入力を28x28x3に変形
x_image = tf.reshape(images_placeholder, [-1, 28, 28, 3])
# 畳み込み層1の作成
with tf.name_scope('conv1') as scope:
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# プーリング層1の作成
with tf.name_scope('pool1') as scope:
h_pool1 = max_pool_2x2(h_conv1)
# 畳み込み層2の作成
with tf.name_scope('conv2') as scope:
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# プーリング層2の作成
with tf.name_scope('pool2') as scope:
h_pool2 = max_pool_2x2(h_conv2)
# 全結合層1の作成
with tf.name_scope('fc1') as scope:
W_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# dropoutの設定
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# 全結合層2の作成
with tf.name_scope('fc2') as scope:
W_fc2 = weight_variable([1024, NUM_CLASSES])
b_fc2 = bias_variable([NUM_CLASSES])
# ソフトマックス関数による正規化
with tf.name_scope('softmax') as scope:
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
# 各ラベルの確率のようなものを返す
return y_conv
モデルの復元(JavaScript側)
TensorFlowからdeeplearn.jsへモデルをポーティングする方法は、公式チュートリアル に記載があります。
ポーティングと言っても、deeplearn.js で復元できるのは、各スコープに定義した変数テンソルや定数テンソルのチェックポイント時点での値だけで、グラフそのものは自分で再構築する必要があります。
先述のTensorFlowのモデルをdeeplearn.jsで表現すると、下記のようになります。
function createInfer(math: NDArrayMath, vars: { [varName: string]: NDArray }) {
// セッションのチェックポイント時点における変数を復元
const W_conv1 = vars["conv1/weights"] as Array4D, b_conv1 = vars["conv1/biases"] as Array1D;
const W_conv2 = vars["conv2/weights"] as Array4D, b_conv2 = vars["conv2/biases"] as Array1D;
const W_fc1 = vars["fc1/weights"] as Array2D, b_fc1 = vars["fc1/biases"] as Array1D;
const W_fc2 = vars["fc2/weights"] as Array2D, b_fc2 = vars["fc2/biases"] as Array1D;
return (x: Array4D) => {
const conv2d = (input: Array4D, weight: Array4D) => math.conv2d(input, weight, null, [1, 1], "same");
const max_pool_2x2 = (x: NDArray) => math.maxPool(x, [2, 2], [2, 2], "same");
// 畳み込み層1の作成
const h_conv1 = math.relu(math.add(conv2d(x, W_conv1), b_conv1));
// プーリング層1の作成
const h_pool1 = max_pool_2x2(h_conv1) as Array4D;
// 畳み込み層2の作成
const h_conv2 = math.relu(math.add(conv2d(h_pool1, W_conv2), b_conv2));
// プーリング層2の作成
const h_pool2 = max_pool_2x2(h_conv2) as Array4D;
// 全結合層1の作成
const h_pool2Mat = h_pool2.as2D(1, 7 * 7 * 64);
const h_fc1 = math.relu(math.add(math.matMul(h_pool2Mat, W_fc1), b_fc1)) as Array2D;
// 全結合層2, softmax計算
const y_conv = math.softmax(math.add(math.matMul(h_fc1, W_fc2), b_fc2));
return y_conv as Array2D;
};
}
maxPool(x, [2, 2], [2, 2], "same") のように、ストライドやカーネルサイズの指定方法がPythonとTypeScriptで少し異なる点だけ注意しましょう。
パラメータの与え方を間違えると、同じ構成のグラフで、同じ重みやバイアスを使っているのに出力値が異なってしまいます。
逆にそこさえ気をつければ、TensorFlowに定義された演算やノード定義が NDArrayMath に同名で定義されているので、割と簡単に書き直せます。
上記コードにおける vars (TensorFlowのスコープ変数)は、セッションのチェックポイントログから、manifest.jsonというファイルに変換し、復元します。
この復元処理については、deeplearn.jsのチュートリアル通りなので説明は割愛します。
OpenCVの準備
前述の通り、CNNに通す前に顔をROIとして切り出す必要があります。ここはwasm化したOpenCVで対応するため、事前準備としてOpenCVをwasmビルドします。
以前に [OpenCV][WebAssembly]ブラウザで2画像の特徴量比較してみるという投稿を書いているので、基本は大きく変わりません。
今回は顔識別さえできればよいので、下記のOpenCVパッケージのみをリンクすれば十分です。
- core
- imgproc
- objdetect
また、カスケード分類器に食わせるXMLデータ(haarcascade_frontalface_default.xml)も emccの --preload-file か --embed-file に指定して生成する必要があります。
必要となるOpenCVの機能は cv::Mat, cv::CascadeClassifier、 また、必要とする関数は、cv::resize, cv::cvtColor です。これらに加えて、JavaScriptのTypedArrayから、cv::Matを生成するための関数、 matFromArray をexportします。詳細は https://github.com/Quramy/face_of_the_year/blob/master/opencvjs/bindings.cpp を見てください。
ブラウザから呼び出す
これで準備が整いました。
- 画像をcanvasタグのContextに書き出し、ArrayBufferを取得
- ArrayBufferからOpenCVのMatを作成
- 4チャネルRGBA -> 3チャネルBGRへコンバート
- Haarカスケードで顔を識別、矩形から部分画像(ROI)を切り出す
- 28 x 28へresize。28 x 28 x 3 = 2,352 byteLengthのUint8Arrayを得る
- 0 ~ 255 のUint8Array から、0 ~ 1.0のFloat32Arrayへ変換
- rank4テンソル 1 x 28 x 28 x 3として、deeplean.jsのCNNに与える
2~5ら辺がOpenCV処理ですね。コードで書くと下記のような感じ。
function detectFace(inputImage) {
const classifier = new cv.CascadeClassifier();
classifier.load('../../test/data/haarcascade_frontalface_default.xml');
const imgRaw = cv.matFromArray(inputImage, cv.CV_8UC4);
const imgColor = new cv.Mat();
cv.cvtColor(imgRaw, imgColor, cv.ColorConversionCodes.COLOR_RGBA2BGR.value, 0);
const faces = new cv.RectVector();
classifier.detectMultiScale(imgColor, faces, 1.1, 3, 0, [0, 0], [0, 0]);
let x;
if (!faces.size()) {
x = imgColor;
} else {
const rect = faces.get(0);
x = imgColor.getROI_Rect(rect);
}
const resized = new cv.Mat();
cv.resize(x, resized, [28, 28], 0, 0, 0);
const faceData = new Uint8Array(resized.data());
[imgRaw, imgColor, faces, classifier, resized].forEach(p => p.delete());
return faceData;
}
これはOpenCV特有の話かもですがcanvas要素から作られるMatはRGBAの順で値が格納されています。
一方、C++/Pythonの imread でファイルからMatを作ったときとチャネルの並びが異なるので注意です。
あと、もう一点注意があって、これは別のレポジトリでやはりOpenCV + wasmの作業をしていたときにドハマリしたのですが、matFromArray を2回連続で呼び出すと、1回目の引数のMatのdataが破壊される、という謎の現象にぶちあたりました。
完全に追ったわけではないのですが、Matのコンストラクタから cv::MatAllocator::upload あたりで、Module.memory に妙なアクセスをしてる雰囲気なんですよね。
原因がわかったら、どこかにちゃんと書きます。
上記で得た faceData を、先ほど createInfer 関数で作っておいたCNNに通せば、最終的な確率を得ることができます。
function toFloatList(data) {
const out = new Float32Array(data.length);
for (let i = 0; i < data.length; ++i) {
out[i] = data[i] / 255.0;
}
return Array1D.new(out).as4D(1, 28, 28, 3);
}
async function execInfer(faceData) {
const logits = infer(toFloatList(faceData));
const conv = await logits.data(); // ここに誰の確率かが入ってるので、値がもっとも大きいインデックスを探索すればOK
}
おわりに
結果的にあんまりwasm成分の多くない内容になってしまいましたが、如何でしたでしょうか。
僕個人としては、.wasmであれ何であれ、他の言語で書かれた優れたライブラリがブラウザで動かせる、ということがWebの表現力を高めるという意味で価値があることだと思っています。
今回のように、メインとなるUIは、HTML/CSS/JavaScriptで構成しつつ、一部の計算処理をwasmやdeeplearn.jsのようなポーティング層に肩代わりさせる、というスタンスは割と気に入っています。
2017年は、主要なモダンブラウザでWeb Assemblyが動作するようになりましたし、Android, iOSでも動作するので「カメラを起動して写真とって友達の名前としてタグ付け」みたいなアプリを完全にWebだけで作れてしまう、ということです。また、SafariがService Workerやるという件もありますし、Webの未来も明るいのでは、と思っています。
なお、今回のデモに利用したコードは https://github.com/Quramy/face_of_the_year に公開しています。訓練データやテストデータもS3に置いて、レポジトリにリンクを書いているので、参考まで。