
毎回、ワールドカップのようなスポーツのイベントがあるとデータサイエンスティストやAI関連の研究員やエンジニアたちによっていかに正確に結果を予測するかというのが競われていたりします。
みなさんいろいろなタイプのアルゴリズムや手法を使って予測していたりしますが、こちらの「Why Did Artificial Intelligence Fail in the FIFA World Cup 2018? (なぜAIは今回のワールドカップの予測で失敗したのか)」という記事の中では今回のワールドカップの結果を予測しようとしていた3つの異なるグループの手法が簡単に紹介されています。その中の一つは機械学習の世界では王道のランダムフォレスト、統計学系のポワソン回帰、ランキングアルゴリズムを混ぜて予測モデルを作っていました。
そして以下のような結果を予測していました。
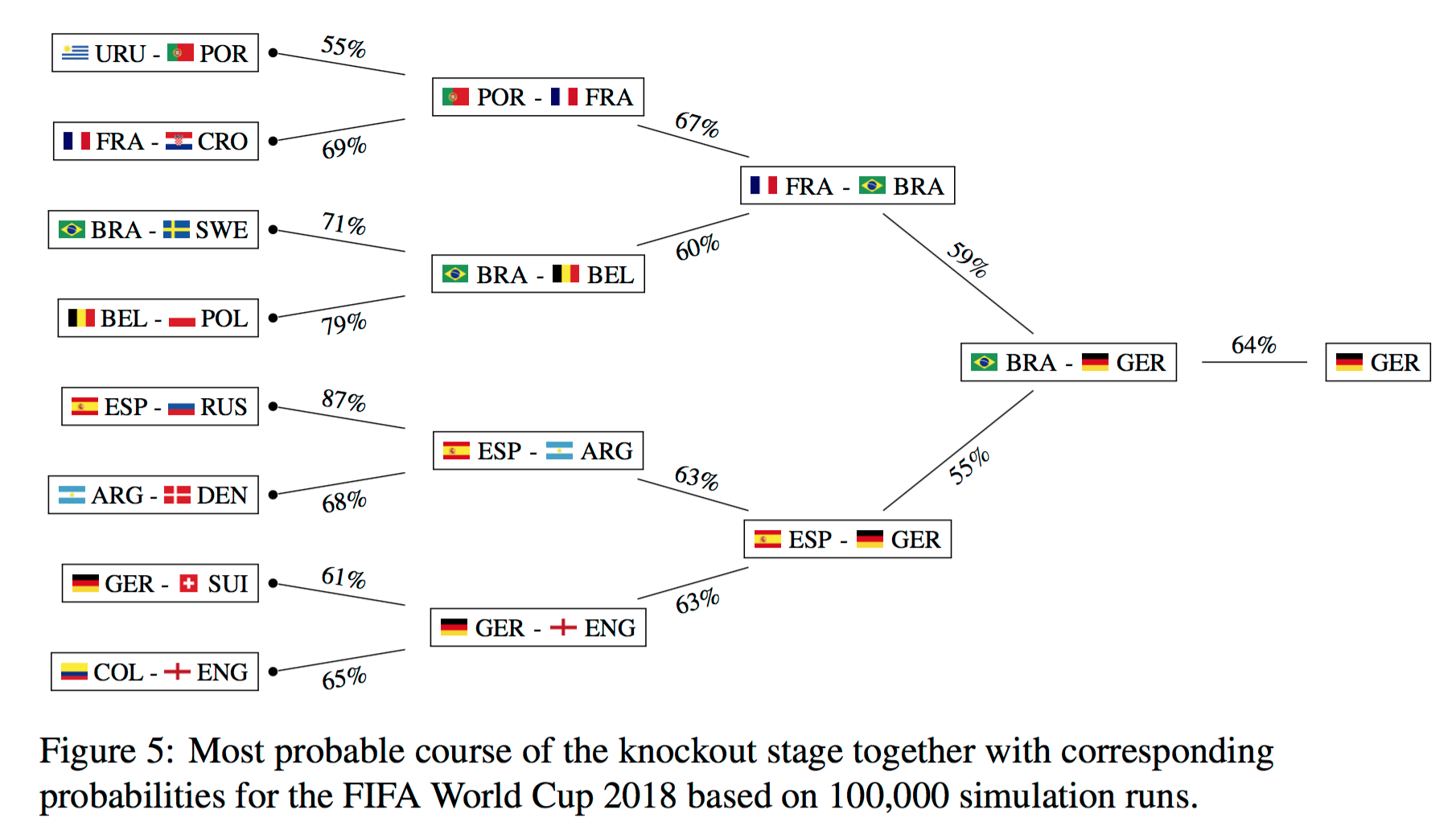
実際の試合結果は以下のようになっていますので、残念ながらあまり当たっていなかったようです。
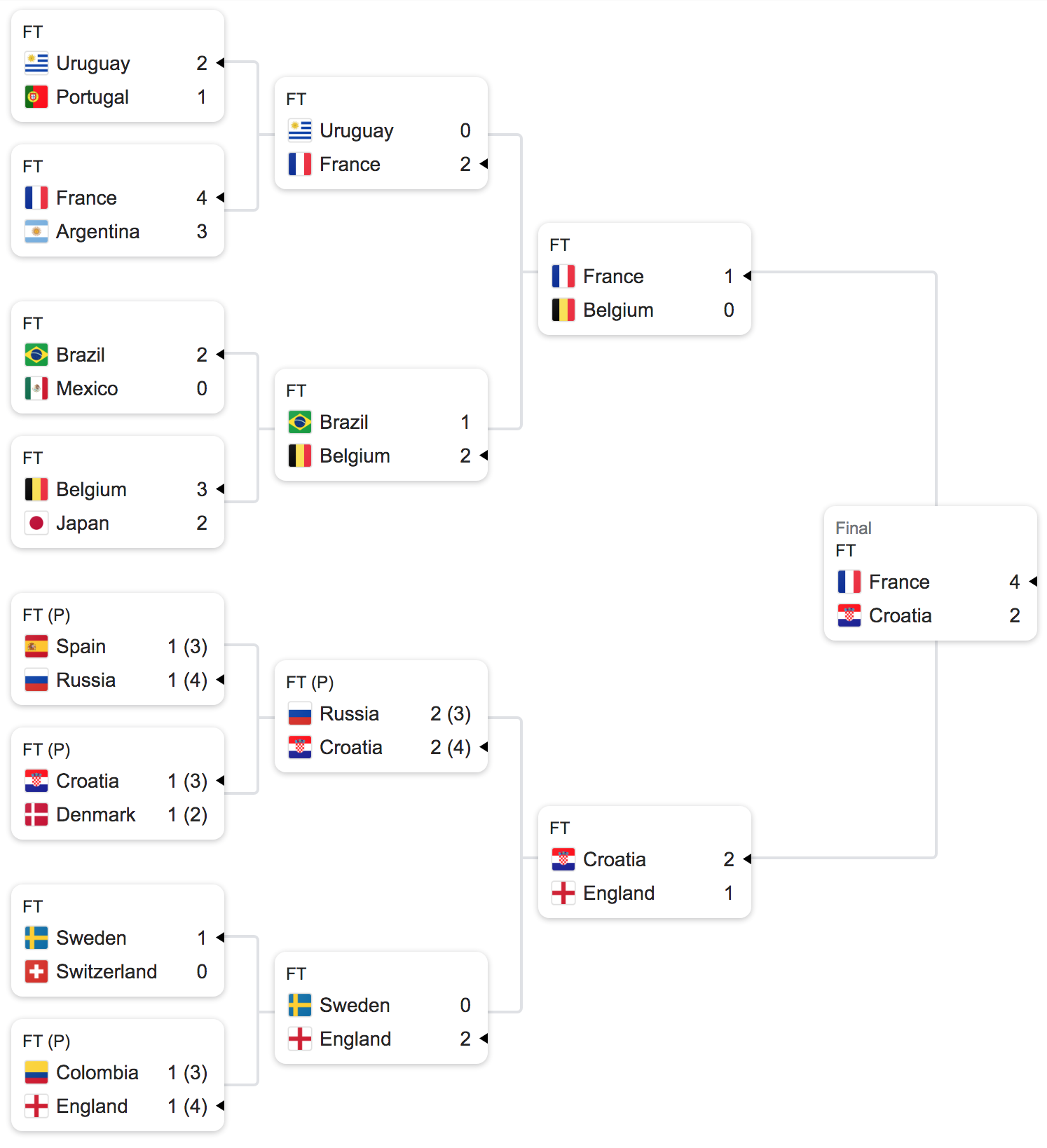
予測モデルの作成にあたっての詳しい話はこちらにオリジナルの論文があります。
以下のような指標からなる16の属性データを使って予測モデルを作っていたようです。
- 経済的な属性 (人口あたりのGDP, 人口)
- スポーツに関する属性 (ODDSET probability, FIFAのランク)
- ホーム・アウェイの優位に関する指標
- チームの選手の構成に関する属性
- チームのコーチに関する属性
ここで使われているランダムフォレストというのは機械学習のアルゴリズムです。そして、機械学習とはAIの一部です。実際AIのシステムと言われたときは、多くの場合、裏では機械学習のアルゴリズムが使われています。そこで、さきほどの記事のタイトルにあるように、”AIの失敗”とされているわけですが、3点ほど私の方からの考察を述べたいと思います。
1. Over Expectation (過剰な期待)
1つ目は、これは先ほどの記事の著者がこの記事の中で伝えようとしていることでもありますが、現在多くの人達の間にはAIに対する過剰な期待(もしくは心配)があります。しかし、以前にもこちらのExploratory Weekly Updateで紹介したように、現在のAIには様々な限界があります。その一つは相関は得意であるが因果は苦手であるということです。
つまり、Bということが起きるとAが起きているということがデータを見てみたところ確認できた(相関関係)、しかし、Bが原因でAという結果を引き起こしたという因果関係が分かったわけではない、ということです。
そしてこの相関関係をもとに機械学習の予測モデルは予測するので、モデルに与えられたデータの範囲では素晴らしい予測結果を出すことができるのですが、特にデータの量が充分でない場合には、未知のデータに対しては正確な予測ができないということがよくあります。
今回の場合は過去の4回に渡るワールドカップに関する対戦データ、チームの構成、コーチの属性などとそれぞれの国のチームに関するデータを使っていますが、直近のチームのゲームに関するデータに欠けていたり、当日の天候、不公平な審判、選手個人のプライベートライフが及ぼす影響、などと、より正確な予測をするには必要になるデータがもっとたくさんあると思います。さらに言ってしまえば、試合の始まる直前、試合中のデータなど、秒単位での試合運びといったつながりを持ったデータも必要かもしれません。つまり、因果関係でなく相関関係による予測結果である以上、正確な予測をするには現実の試合とほぼ同じようなデータが必要となってきます。
こうしたAIの限界が理解できていないとついついAIという名前のもとに現実から離れた高い期待を持ってしまうので、逆に思ったような結果が出なかったときに、失望とあきらめの気持ちが起きてしまいます。これでは、これからせっかく機械学習なり、統計なりのアルゴリズムを利用してデータを分析していこうとしていくときに、余計な反発を招くことになってしまいます。「AIでも結局予測できないんだから、やっぱ、勘と経験だよ!」といった具合です。
Under Expectation (期待されてもいない)
2つ目は、逆にそうはいっても、何げにそこそこの結果を予測できているじゃないかということです。つまり、AIなりデータサイエンスによってできること、できないことを理解していると、そもそもAIが完璧に予測できるという期待はなく、逆に、これは確率の話でありエラー(間違い)はいつもあるという正しい期待を持っています。そうすると実はこの結果はまったくデタラメというわけではなく、むしろそれなりの結果を出しているというのが見て取れます。
こちらが元の論文にも乗っていたそれぞれの国のチームがそれぞれのステージで勝ち残る確率が計算された表です。
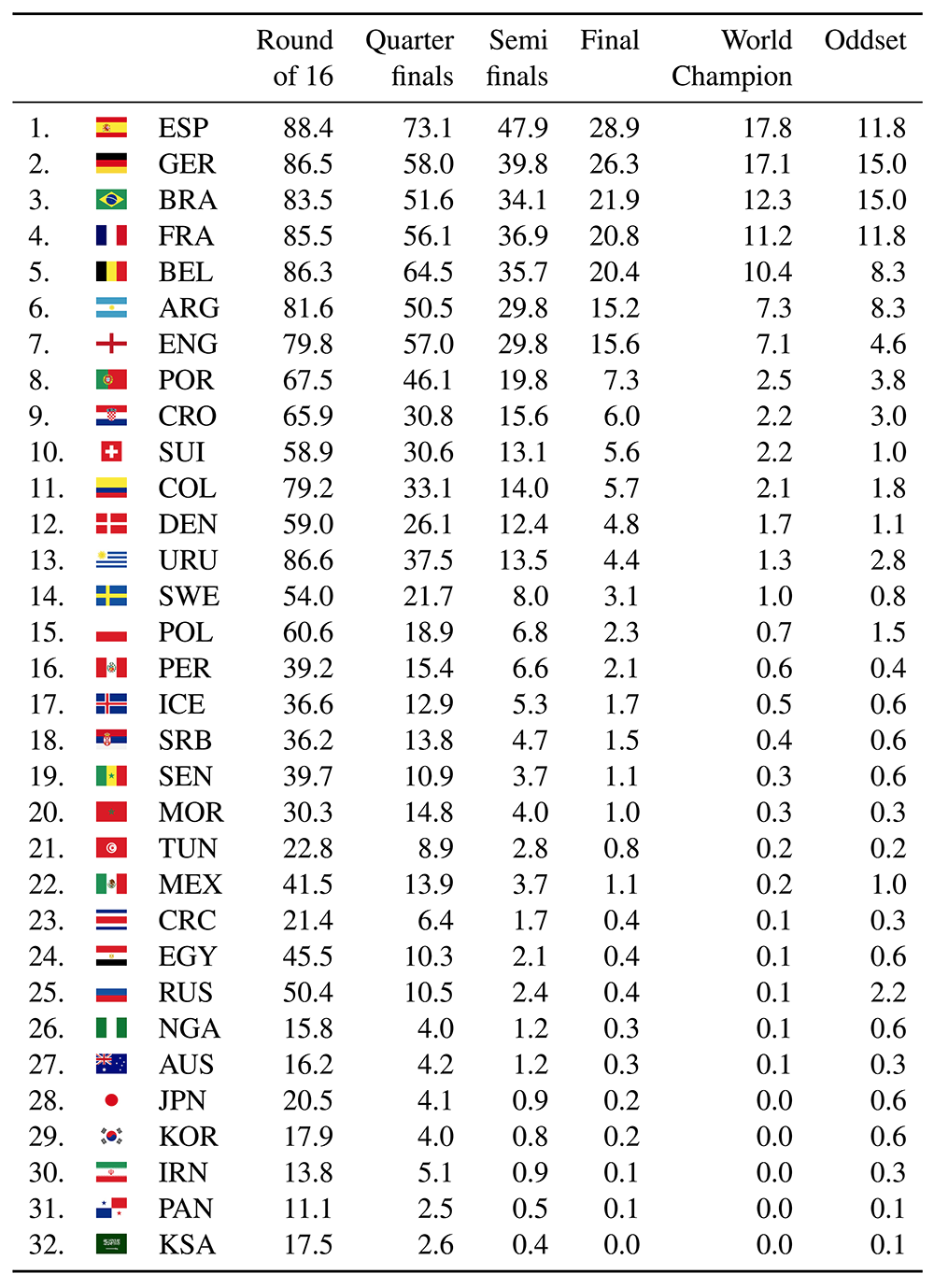
そして、このモデルは順位、すなわち数値を予測するためのモデルなので、そのクオリティを示す指標は以下のように提供されています。
RMSE: 8.052
MAE: 6.468
それぞれの詳しい説明はここでは省きますが、簡単に言うとどちらも平均的な予測値と実測値のズレだと考えていただければいいと思います。ということは、予測の結果が一位だとしても、6位または8位くらいのであることもあるということです。つまり、もともと全てのチームが予測された結果にぴったり来るなどとはこの予測モデルは言っていないのです。
それでは、この予測値と実際の試合結果である実測値はどれだけのずれがあったのでしょうか。そちらを以下のようにチャートにして表してみました。
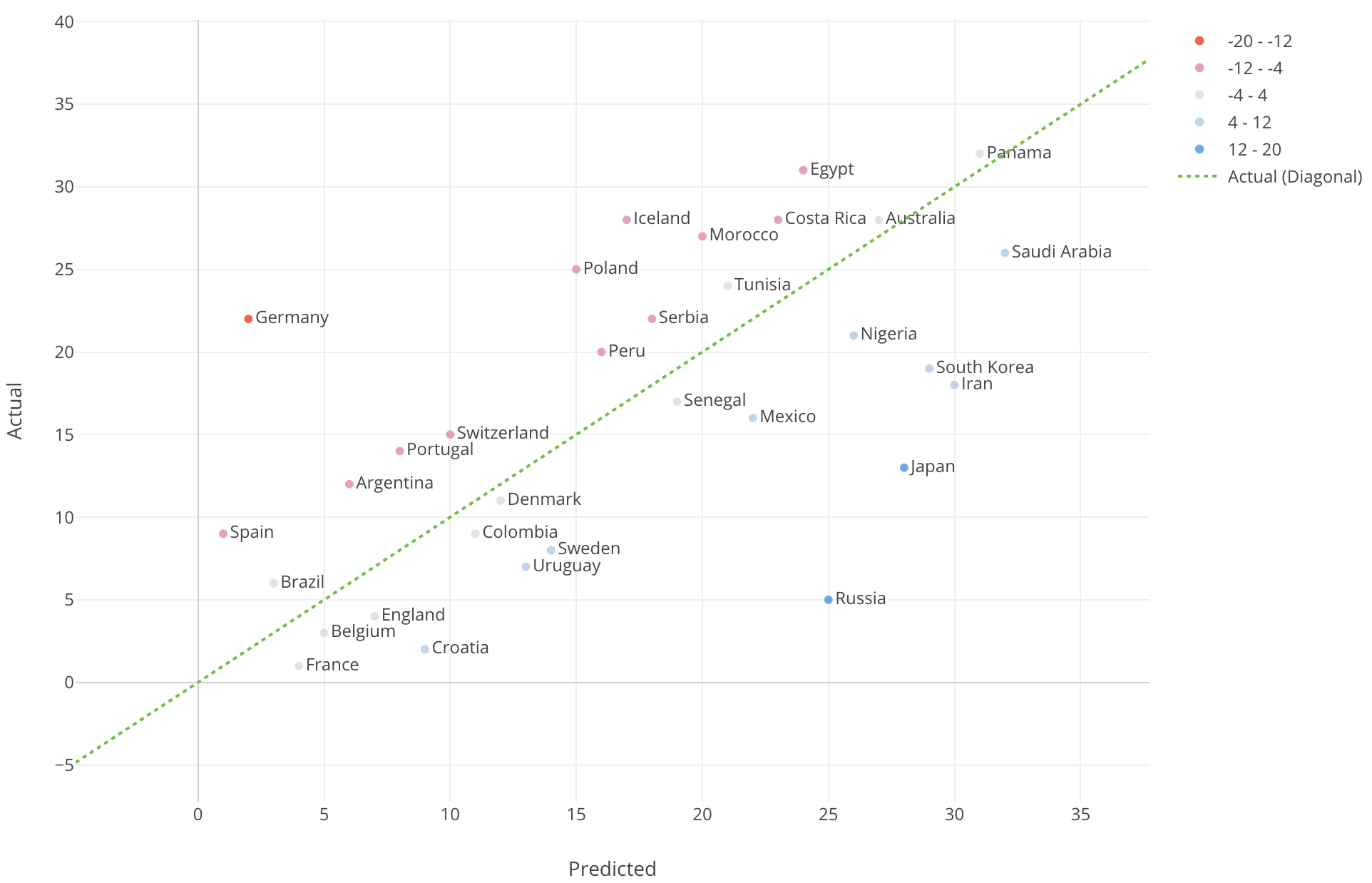
それぞれの点はそれぞれの国を表し、X軸は予測結果の順位で、Y軸は実際の順位です。色は予測値と実測値がどれだけ離れていたのかを表し、赤ければ実際の順位が予測に比べてより悪く、青ければその逆です。日本の場合は右下の方にありますが、予測された順位は28位で実際は13位だったということです。つまり思った以上に良かったということです。
実は、先日こちらの記事の中で日本とベルギーそれぞれのチームの選手の能力スコアをもとにPCAというアルゴリズムを使って比較分析したのですが、そのときも同じ印象を持ちました。というのも、日本の選手がベルギーの選手たちに比べて一般的にスコアが低いにもかかわらず、実際の試合ではほとんど互角に勝負したのですから、それはたいしたものだったと思います。
ちなみに一番期待されてて、結果がさっぱりだったのはドイツです。2位と予測されていたのですが、決勝トーナメントにすら上がれず22位に終わってしまいました。
しかし、こうした日本やドイツのように予測値と実測値の間に大きな開きがあるものは実は例外で、多くの国は予測値と実測値が比較的近いです。上のチャートの緑の斜めの点線は、予測がパーフェクトだった時の理想の線、つまり予測値と実測値が全く同じという直線ですが、殆どの国がその線に近いのが見て取れると思います。
つまり、過去のワールドカップのデータをもとにした、たった16の属性で作った予測モデルであるにもかかわらず、ここまでの予測ができる事自体が実は大したものだというのが私の感想です。さらに見方を変えると、15位圏内に入ると予測された国はほぼそうなっているのです。ドイツとポーランドを除けば。
つまり、AI(正確には機械学習と統計学習のアルゴリズム)を使っても、こんなものは予測できるはずがないと思う人もいれば、そもそもこんなことができることすら知らないという人もいると思います。しかし、やってみるとこの程度の結果であれば、比較的簡単に出来てしまうものなのです。そしてこのレベルの予測結果であれば十分役に立つというデータ分析は現実世界にはたくさんあるのです。
3. 予測結果とその結果をはじき出した方法の公開
最後にこれが私達、データサイエンスなりデータ分析なりを勉強し続けるものにとっては最も重要なのですが、予測の結果がどうであれ、こうやって予測結果とそこに行き着いた具体的な方法を公開するというのは、データサイエンスのコミュニティにとって、素晴らしい貢献だと思います。予測が当たっていたか、当たっていなかったというバイナリー(0か1、または白か黒といったようにどちらか一方のという意味)の判断ではなく、何がうまくいって、何がうまくいかなかったのかというのをコミュニティにいるみんなで学んでいくことが出来るからです。
後になって、「俺の言ったとおりだった」とか、「だからそんなのだめなんだ」といった感じで、後出しジャンケンのように外部から批判するのは簡単です。しかし、データサイエンスの世界は、いつも「正しいやり方」があるとは限らないので、結果がどうであれ、他の人によって紹介される様々な手法の中から学ぶことはいつもたくさんあります。
さらに、こうしてデータ分析の方法を公開することで、それを見た人からの建設的なフィードバックを得られることもよくあります。私自身も、今まで様々な分析結果をブログという形で公開してきていますが、いろんな人達から、「こういうやり方は試してみた?」、「こういう事は考えてみた?」などというフィードバックをいただくことがあり、なかには、次のステップへと成長していくための貴重な学びのきっかけがあったりするものなのです。
みなさんも、データ分析をこれから学んでいこうという人は特に、データ分析の結果であれ、こうした予測結果であれ、そこに行き着く方法を含めたかたちで、オープンに、さらに再現可能な形で、間違いを恐れずにどんどん公開していってただければと思います。

この10月の中旬に、Exploratory社がシリコンバレーで行っているトレーニングプログラムを日本向けにした、データサイエンス・ブートキャンプを東京で開催します。データサイエンスの手法を基礎から体系的に、プログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に参加を検討してみてください。詳しい情報はこちらのホームページにあります!