はじめに
最近、自分のところで使ってるサーバの目的はなんだろう?動作を見直してサーバレスにできないかな?と見直ししてます。
サーバに設定されている、動作は下記のようなものでした。
- Webサービスの公開。LaravelだったりWordPressなどを使用
- それらで使用しているデータベース(MySQLやSQLite)
- 外部webデータのスクレイピング+保存
- 自分管理のサーバのデータをバックアップするためにサーバからデータファイルを取得してクラウドストレージに保存
今回、4番目(+3番目)をサーバレス化していこうと思います。
AWS側の設定
Lambda関数の登録
やることは下記の流れで処理していきます。汎用的に使えるようにしているため、wgetで取得するサイトが1種類のWebサイトだともっとシンプルにできると思います。
処理の流れ
- Lambdaの起動パラメータを使って、保存対象とするURLをDynamoDBから取得
- 取得したURLをファイルに保存
- 保存したURLファイルをパラメータに指定してwget実行
- wgetの結果をtarファイルにまとめる
- tarファイルをS3に保存
- 最後にURLファイル/wget取得結果/tarファイルを削除
実装
リージョンなどは固定で設定しています。S3バケット名とDynamoDBテーブル名は環境変数で登録しています。
環境変数
- dynamoDb_table …… DynamoDBテーブル名(取得先のURLを管理)
- s3_bucket …… S3バケット名(取得結果を保存)
ソースコード:index.js
index.js
'use strict';
const AWS = require('aws-sdk');
const s3 = new AWS.S3();
const documentClient = new AWS.DynamoDB.DocumentClient({ region: 'ap-northeast-1' });
const execSync = require('child_process').execSync;
const fs = require('fs');
function getDb(domainKey) {
var params = {
TableName: process.env.dynamoDb_table,
Key: {
'domain': domainKey
}
};
return documentClient.get(params).promise();
}
function createUrlFile(urls, targetDate) {
var urlString = urls.join('\n');
console.log("urls:", urlString);
return new Promise(function(resolve, reject) {
fs.writeFileSync("/tmp/urls.txt." + targetDate, urlString);
resolve("createFile end.");
});
}
function callShellScript(cmd) {
return new Promise(function(resolve, reject) {
const childLog = execSync(cmd, (error) => {
// reject(error);
}).toString();
console.log("callShellScript: ", childLog);
resolve("callShellScript: success");
});
}
function s3Upload(domainKey, targetDate) {
var params = {
Bucket: process.env.s3_bucket,
Key: domainKey + "/" + targetDate.substr(0, 6) + "/" + targetDate + ".tar.gz",
ContentType: "application/tar+gzip",
Body: fs.readFileSync("/tmp/" + targetDate + ".tar.gz"),
};
return new Promise(function(resolve, reject) {
s3.putObject(params, (error, data) => {
if (error) {
console.log("s3Upload:", error);
reject(error);
}
else {
console.log("s3Upload:", "success");
resolve("s3Upload: success");
}
});
});
}
exports.handler = (event, context, callback) => {
var dtYmdHis = new Date().toISOString().replace(/[-:]/g, '').replace(/T/, '-').replace(/\..+/, '');
console.log("dtYmdHis:", dtYmdHis);
getDb(event.domain)
.then((r) => {
console.log('getDb result:', r);
createUrlFile(r.Item.urls, dtYmdHis);
})
.then((r) => {
callShellScript("/bin/bash ./callShellWget.sh " + dtYmdHis);
})
.then((r) => {
s3Upload(event.domain, dtYmdHis);
})
.then((r) => {
callShellScript("/bin/bash ./callShellDelete.sh " + dtYmdHis);
})
.then((r) => {
callback(null, r);
})
.catch((e) => {
console.log('error:', e);
});
};
シェルスクリプト:callShellWget.sh
wgetしてtarしてます
callShellWget.sh
#!/bin/sh
bin/wget -P /tmp/wget.$1 -i /tmp/urls.txt.$1 -r -l 1 -nv
tar cvzf /tmp/$1.tar.gz /tmp/wget.$1
シェルスクリプト:callShellDelete.sh
ファイルを削除します。
callShellDelete.sh
#!/bin/sh
ls -la /tmp/
rm -rf /tmp/wget.$1
rm /tmp/urls.txt.$1
rm /tmp/$1.tar.gz
ls -la /tmp/
TIPS
- メモリ:128MB, タイムアウト情報 30秒くらいで設定。
- 並列化処理はしていません。
- wgetを使う理由:request-promiseの検討も考えましたが、処理が煩雑になってしまうため、wgetを使うことにしました。
- Lambdaとwget:Lambdaの実行環境にはwgetが導入されていないため、wgetのバイナリをを持ち込む必要があります。
- 持ち込む方法は、EC2などの環境で
which wgetでバイナリの場所を調べて作業ディレクトリの./binにコピー。 -
index.js(空っぽのファイルでよい)と./binをzip圧縮。 - zip圧縮したファイルをLambdaにアップロード。
- 持ち込む方法は、EC2などの環境で
- Lambda(node.js)で最速にシンプルにするためにシェルスクリプトを多用してます。多分これが一番早いと思います。
- 同時に実行されることも考えて、URLファイル/wget取得結果/tarファイルにはsuffix(実行時刻)をつけてます。
- wgetでダウンロードするデータサイズは200MBまでを推奨。tarでまとめた一時ファイルを置く容量も計算しておいたほうが良いです。
DynamoDB
いろいろなサイトのデータをバックアップする=汎用化のため、DynamoDBを使用しています。
実装
- テーブル名:管理しやすいテーブル名 (このテーブル名をLambdaの環境変数に登録します)
- キー:domain …… String型
- 項目:urls …… LIST型
- 各種urlを列挙していく …… String型
TIPS
- 読み込み容量ユニット/書き込み容量ユニット は"1"。大量に動かすときは調整してください。
S3
登録作成したバケット名をLambdaの環境変数に登録します。
CloudWatch Event
ルールを作って登録します。
- イベントソース
- Cron式を記述します。正しいCron式が入力されると次回の動作タイミングが表示されます。CentOSなどのCron式とはちょっと違うので注意が必要です。
- ターゲット
- 機能:作成したLambda関数を指定して下さい。
- 定数(JSONテキスト)を指定します。ここの値をキーとしてDynamoDBからURLを取得してきます。
{"domain": "example.com"}
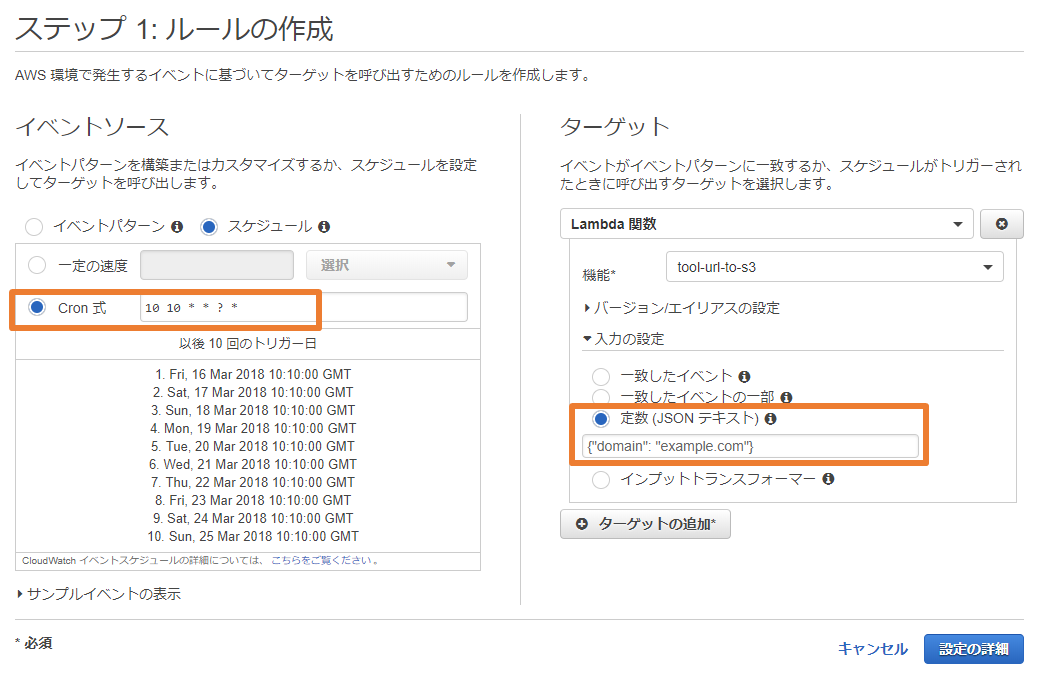
その後のEVENTルール名や説明は分かりやすい内容を記述してください。
最後に
動作ログはColudWatch Logsに記録されていきます。サイトにもよりますが、12MB程度のデータをwgetでダウンロードしてきてS3に保存するまで、大体9秒くらいで終わるようです。