はじめに
僕が、この本に出会ったのは、かれこれ1ヶ月前のことになる。
それまでは、自分は「AlphaZero」のAの字も知らない「AlphaZero童貞」だった。
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門

この本にであって、気づいたらAlaphaZeroを自分で実装するところまでいけた!
わかりやすい、大変オススメの本です。
(※この記事の図は、この本から引用しています。)
この記事を読むことで、
「AlphaZeroのアルゴリズム概要はつかめた。」
というところまで、噛み砕いてエクストリームに説明できればと思います。(中田敦彦風)
AlphaZeroのすごいところ
まず、AlphaZeroをかいつまんで話すと
- ルールを与えるだけで、自分のコピーとひたすら対戦を繰り返し勝手に学習して、進化していく(強化学習と呼びます)
- いろんなゲームに転用可能
- 十分に学習すれば、現況最強のアルゴリズムまで進化する。(alpha zeroは、googleがスパコン使って学習したところ人類含めて世界最強囲碁AIになった。)
- しかもこれが、自分でも作れるらしい!素晴らしい時代である。
アルゴリズムざっくり解説
全部で3つのPartに分けて説明します。
Part1.強化学習サイクル
下記の図のようなフローで学習が進みます。
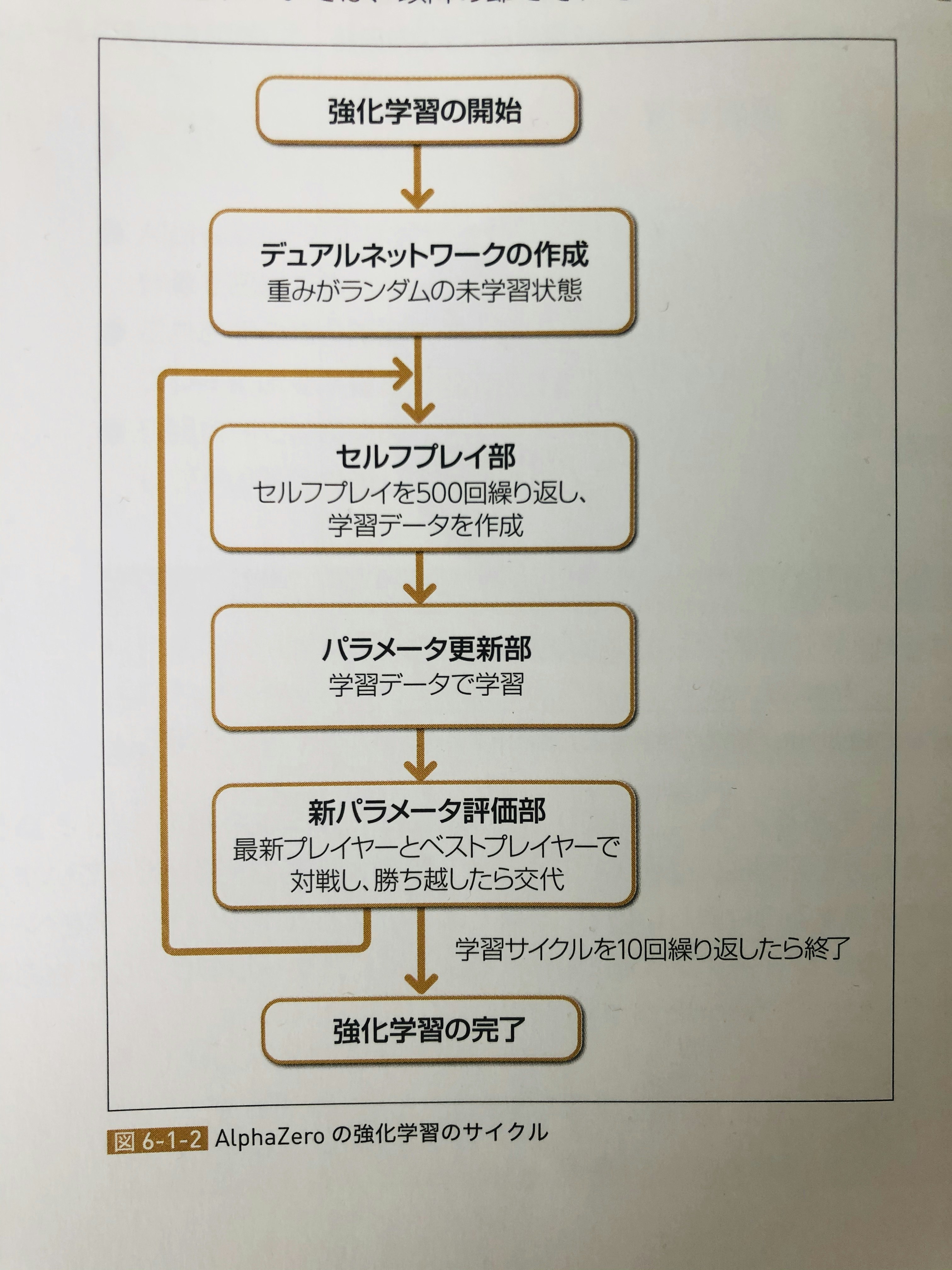
- 学習するのは、デュアルネットワーク(ニューラルネットワークの一種、後述)のパラメータ
- 500回、自分同士で戦ってパラメータ更新を繰り返す という部分さえ理解していればOKです。
Part2.モンテカルロ木探索部分説明
次に、対戦のときAlphaZeroはどうやって、次の一手を決めるかを説明します。
「モンテカルロ木探索」という手法を用いています。
ざっくり説明すると、「ゲーム木の中で、有望な手を深く調べることによって、いい手を見つけようとする探索法」です。
具体的には「選択」「評価」「展開」「更新」の4つの操作で構成されます。
ゲーム木前提
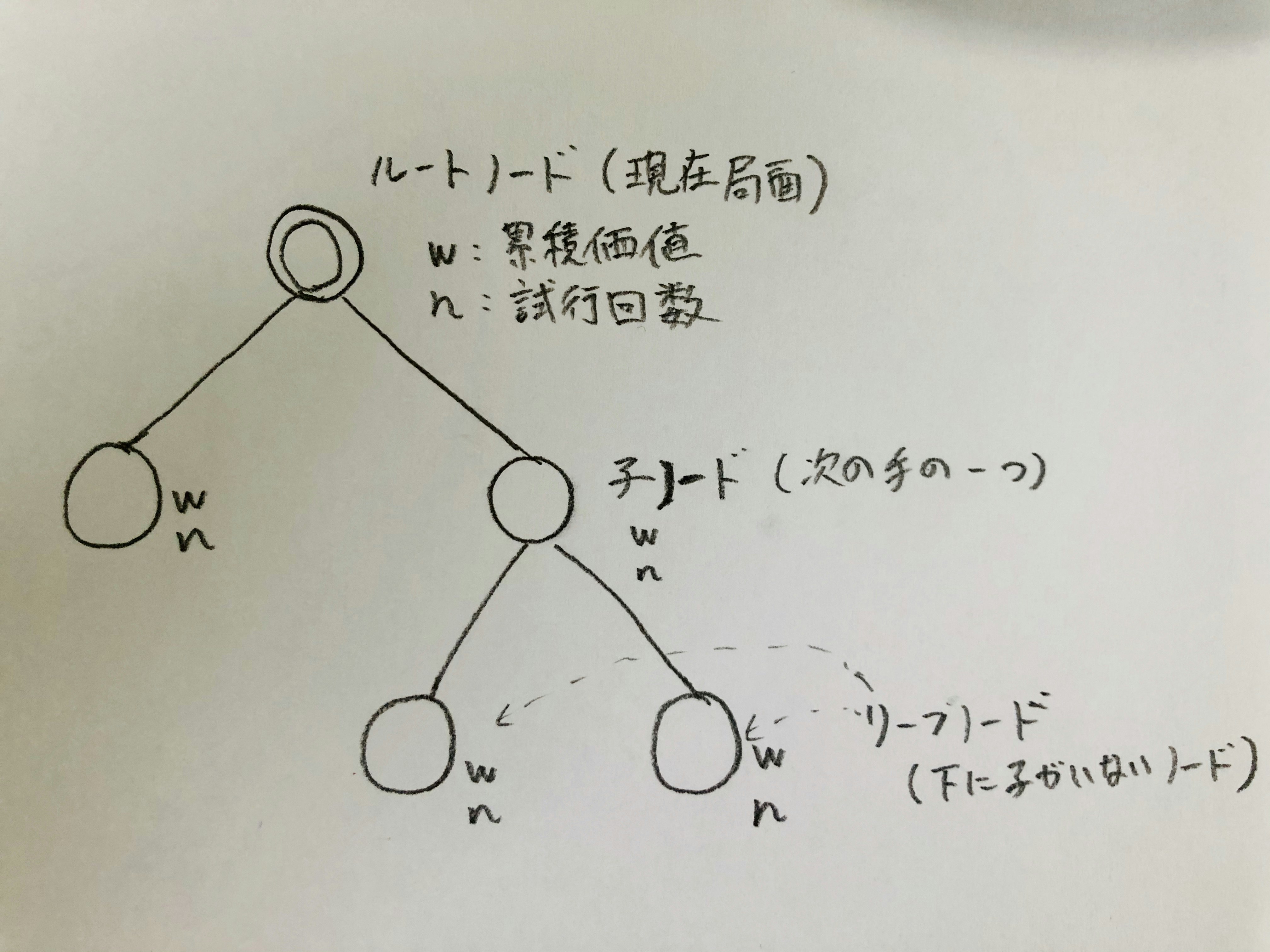
ゲーム木は、ルートノードから、始まり、一つの手が進む毎にノードが1階層下がっていきます。
かつ各ノードは、w:累積価値と、n:試行回数というパラメータを持ちます。
最初は、ルートノード(現在の局面)のみのゲーム木から始まり、探索と共に子ノードが増えつつ、w,nが更新されていきます。
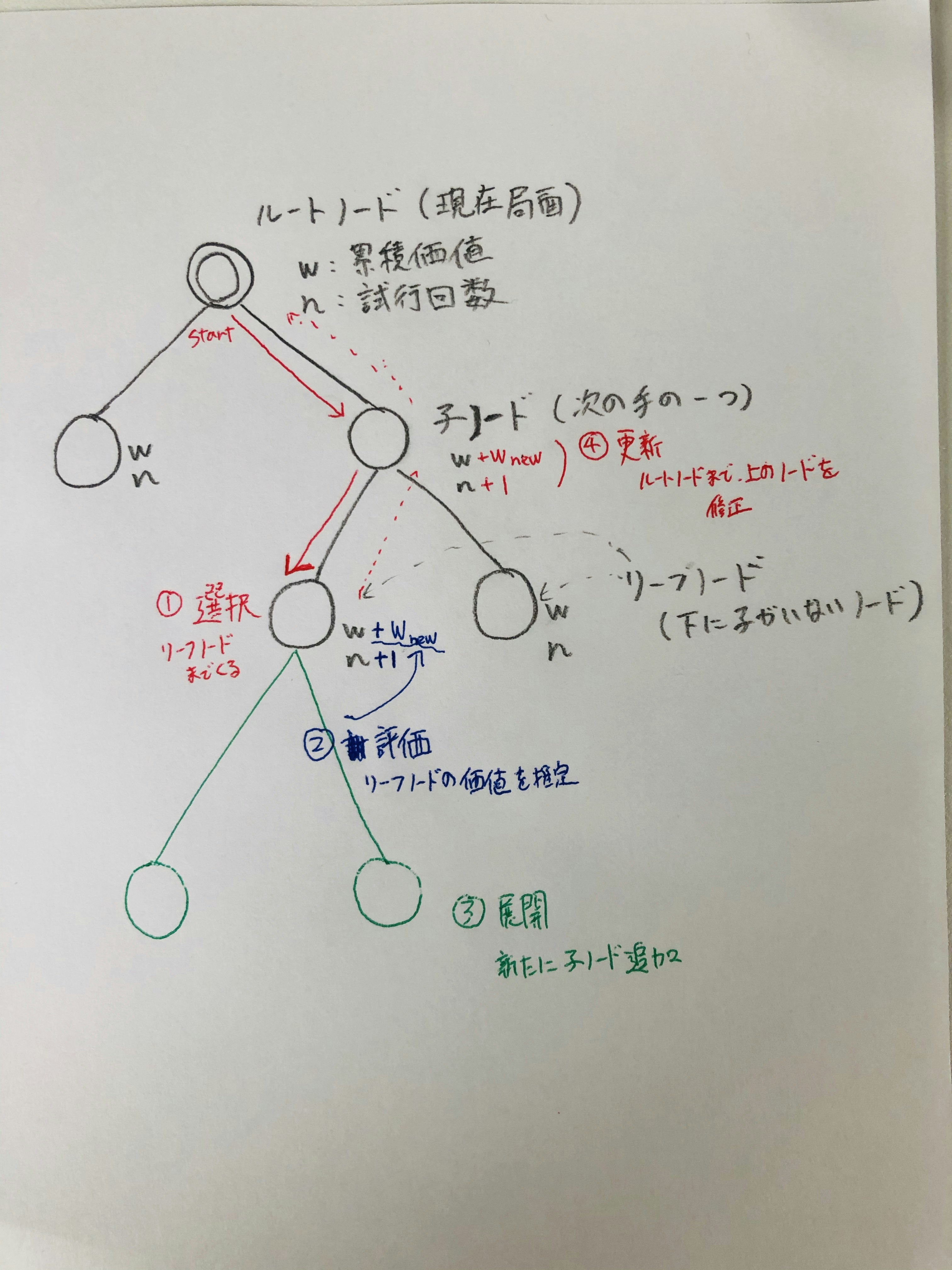
- 1.選択: ルートノード(現在の局面)から、子ノードへの移動を繰り返し、リーフノード(次の子ノードがないところ)まで進みます。 手の進め方は、累積価値を考慮しつつ、少しランダム性をもたせることで、良いと思われる手を多く選択するようにします。
- 2.評価: リーフノードにて、そのノードの価値を計算することです。評価のためには、プレイアウト(ランダムCPU同士で10回競わせてみて勝率をみる)などが用いられます。 その後、リーフノードの試行回数を+1、累積価値も評価値をプラスします。
- 3.展開: リーフノードの試行回数が、設定limitを超えた場合、展開といってそのノードの下に子ノードを追加します。
- 4.更新: 最後にリーフノードから、ルートノードに戻りなから、2の評価値と、試行回数をそれぞれのノードに足していきます
次の一手の選択
1~4までの操作を1試行とし、これを特定回数(500回とか)行います。
その後、試行回数が多いノードを「次の一手」として採用します。(累積価値は使わない)
三目並べAlphaZeroの場合
- 選択: アーク評価値を使う

なんだがややこしい式が出てきましたが、大枠としては
「平均的に良いと思われる手を刺す」というのに、適度に新しい手を指すように、「バイアス(偏り)」というスコアを付加してるイメージで捉えてもらえばいいと思います。
評価: 今回は、この評価を2で作成したニューラルネットを用いて行います。
このニューラルネットが学習するにつれ、盤面毎の評価を正確にすることができるようになり強いAIになります。次の一手の選択: 展開回数に応じた確率分布に、ボルツマン分布というバラツキを足した分布に応じて選択します。
ボルツマン分布を足すことで、ときには変な手を打たせて、いろんな学習をさせるためだと思います。
Part3.デュアルネットワーク
AlphaZeroは、デュアルネットワークというニューラルネットワークの一種のモデルを使いそれを学習します。
入力として盤面を見て、方策: 次の1手毎の価値、価値: 現在の盤面の勝敗予想の両方を予測するモデルです。
出力するのが、2つなので、「デュアル」ネットワークなのですね。
そして、画像解析で使われているニューラルネットワークを使って、盤面を一枚の写真と考えて評価してるってことですね。
全体像から行くと、
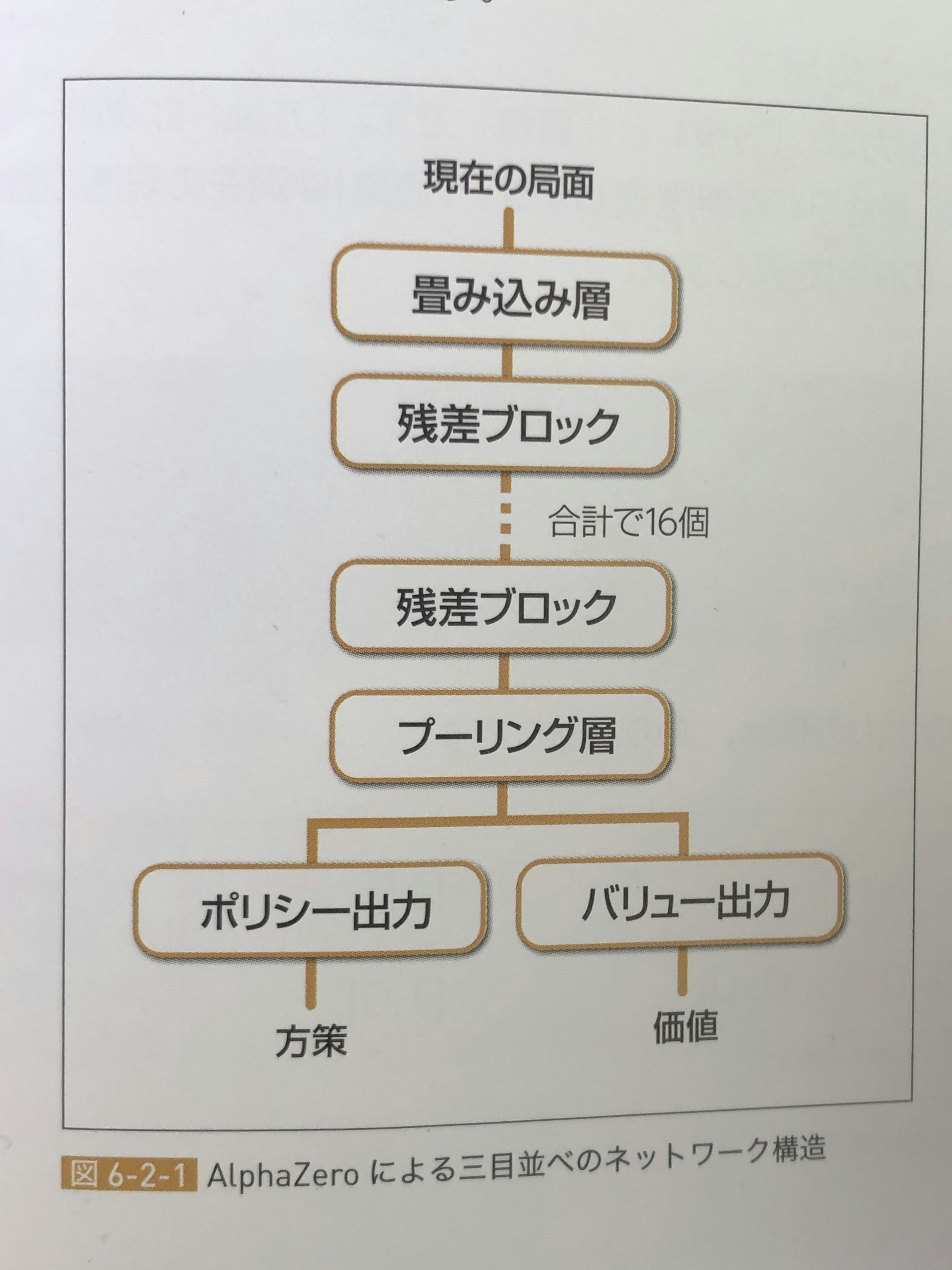
おーなんか、色々層が出てきた。w
例えば「畳み込み」というと具体的には、下記画像のような処理を行なっています。
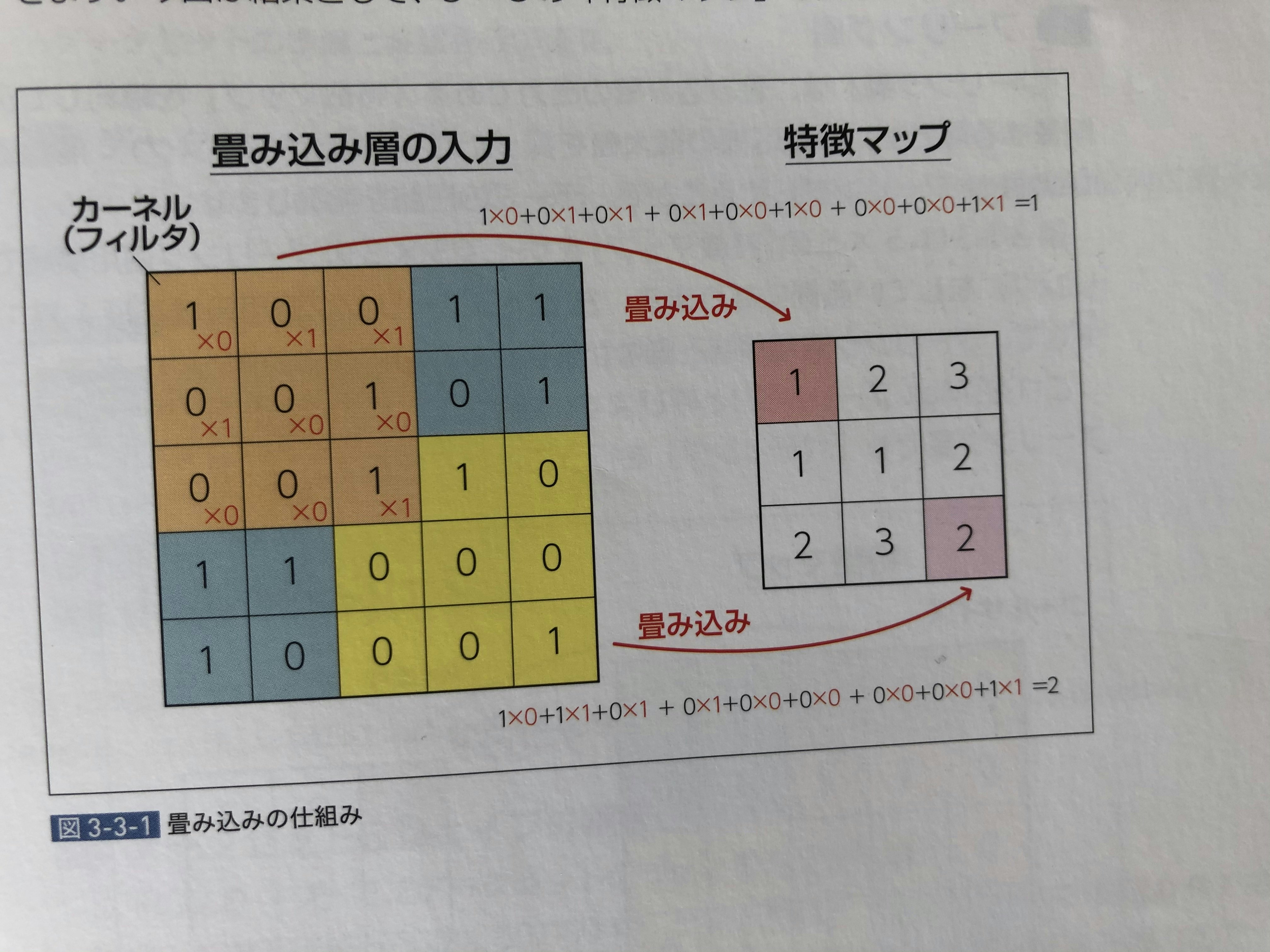
まあ、画像の歪みや、並行移動の影響を受けにくくなるような処理をかませているということです。
(目を細めてぼやっと見てるイメージですかね。w)
そんな処理を色々やってます。
またこの残差ブロックというところには、画像分類で使われるResNetという手法が組み込まれています。
具体的にはこんな感じです。
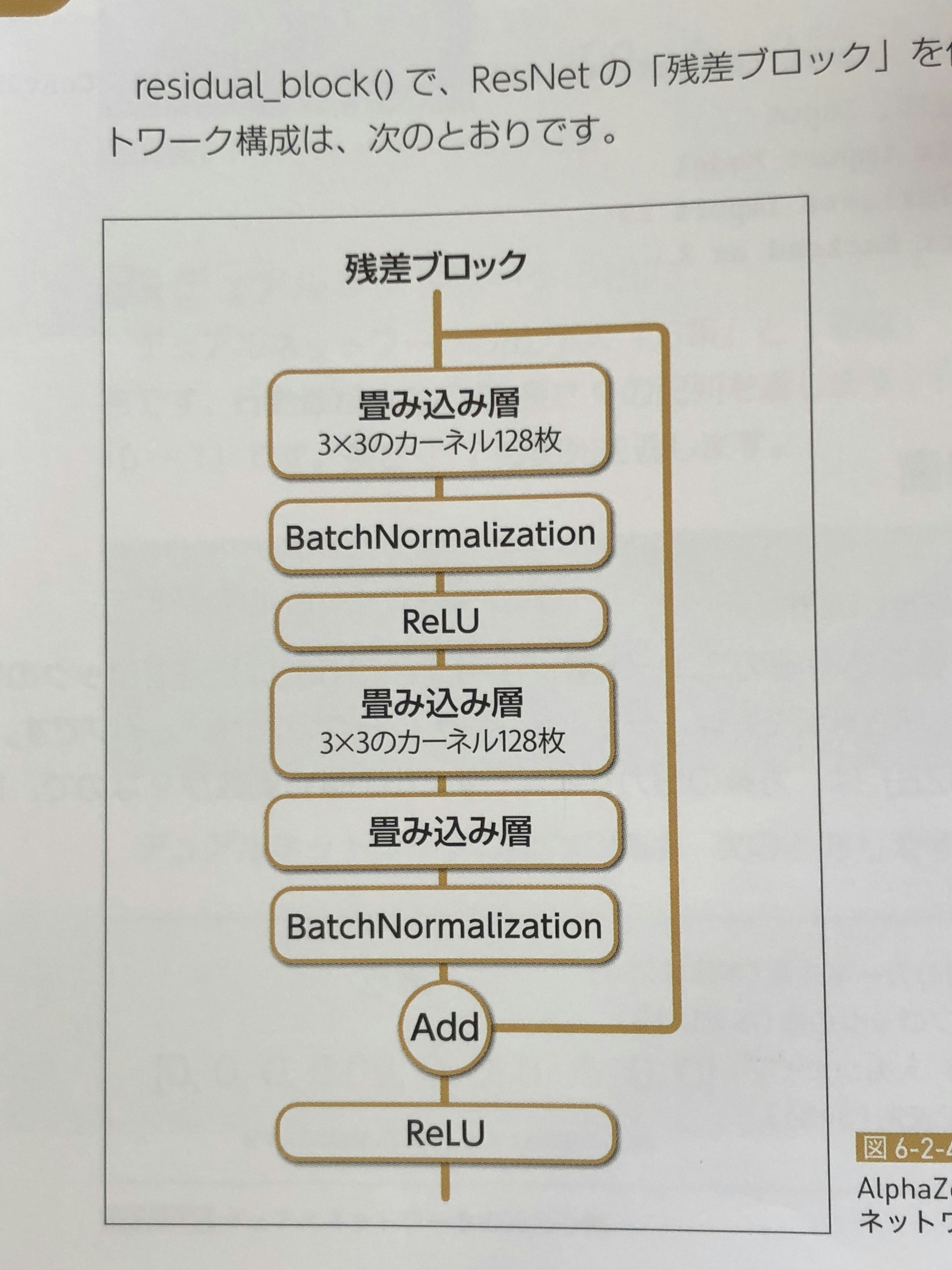
まー、いきなり初見では、よくわからないですよね。w
「AlphaZeroには、ResNetが使われてて、
ResNetはショートカットコネクションというのがあるのが特徴的で、これによって深い学習が可能になってるんだよね〜」
と言ってドヤりましょう。もし、突っ込まれたら口笛でも吹きながら逃げましょう。w
「画像解析で使われているニューラルネットワークを使って、盤面を一枚の写真と考えて評価してる」
この部分だけ理解してればOKと思います。
以上がAlphaZeroアルゴリズムのざっくり説明です。
AlphaZeroまとめ
正直ここまで読んできて「よーわからん」という人は、以下の3点ざっくりポイントだけ覚えてもらえば良いかな〜と思います。
- AlphaZeroは、ゲームのルールさえ教えて上げれば、ひたすらAIが戦い続けて自動で最強まで強くなるアルゴリズム(強化学習)。すごい!
- 次どの手を刺すかは「モンテカルロ木探索」という手法で決められてる。ざっくり言うと、良さそうな手」を深く考えることでいい手を見つける手法。
- 今の盤面評価には、ニューラルネットを使ってる。画像解析とかに使われてる手法。それを応用して、盤面を一枚の写真として見て、いい局面かどうかっていうのを判定している。
これだけ掴んでいれば、AlphaZeroって大枠分かってるよ。
と言えるのではないでしょうか。(当社調べ)
実際に組んでみての感想まとめ
繰り返しになりますが、この本神です。興味持ったら是非読んでみてください。
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門-
2日弱の学習で、最強の五目並べできました!もう少し複雑なゲームもやりたい。
- 2人完全情報ゲーム以外にも転用できそうな気がする。複数人とか確率入ったゲームとか(麻雀とか?)
google colaboratory最高!無料で、高価なGPU使えるし、使い方も楽!
アルゴリズムの細かいところに疑問点がでてきました。とくに、ニューラルネットの組み方がなんでこうなってるのかは経験則なのかもしれませんが、職人技に感じます。ここらへんの構築理論が知りたいです。
良かったら「LGTM」いただけると、冥利につきます。テンション上がって、続きの記事をお届けできるかもしれません。w よろしくお願い致します。m(_ _)m