はじめに
前回の記事『機械学習案件を納品するのは、そんなに簡単な話じゃないから気をつけて』に多くの反響があり、現時点で1000近い、いいねを頂きました。
まだまだ発展途上の業界でもあり、かつ私自身も起業直後で経験不足といったところで生じた問題ではあったのですが、「失敗談の共有は尊い」といった嬉しいコメントもいただきました。
私は株式会社キカガクという会社で機械学習に関する教育(主に数学やプログラミング)を行っておりますが、今後はこういったビジネスサイドでのフローやモデルの運用フローまでフォローしていくのが本当の教育だと思っています。
その中で、今回は現場でよく生じるある問題に関して、フォーカスを当ててお話をします。
現場でのよくある話のはじまり
キカガクのセミナーや個人で頑張って勉強し、現場で機械学習案件にアサインされた方々に待っているある問題をご存知でしょうか。
それは「人に伝えること」です。
営業の方であればお客様先へ、エンジニアの方であればプロジェクトのマネージャーへ状況を伝える必要があります。
プロジェクトを進める以上はひとりではなく複数人のケースが大半であり、もちろんその中には、機械学習を学んでいない方もたくさんいると思います。
その方々に、うまく自分自身の仕事について伝えたり、採用した機械学習アルゴリズムの中身について数式を用いずに伝える必要が出てきます。
みなさんは、どのようにしてこの問題を解決されているでしょうか。
この問題をすごくスムーズに解決してくれる例え話が『料理』ではないかと思っています。

『機械学習』と『料理』は工程が似ている
たとえば、『あるレストランでお客様に提供するメニューを作成したい』といった工程が『機械学習プロジェクトをうまく安定運用させたい』といった工程と似ていると思います。
前回の記事でも書いていましたが、機械学習のプロジェクトを推進していく流れは以下の通りです。
※ 今回は仮運用と検証を一緒にまとめています。
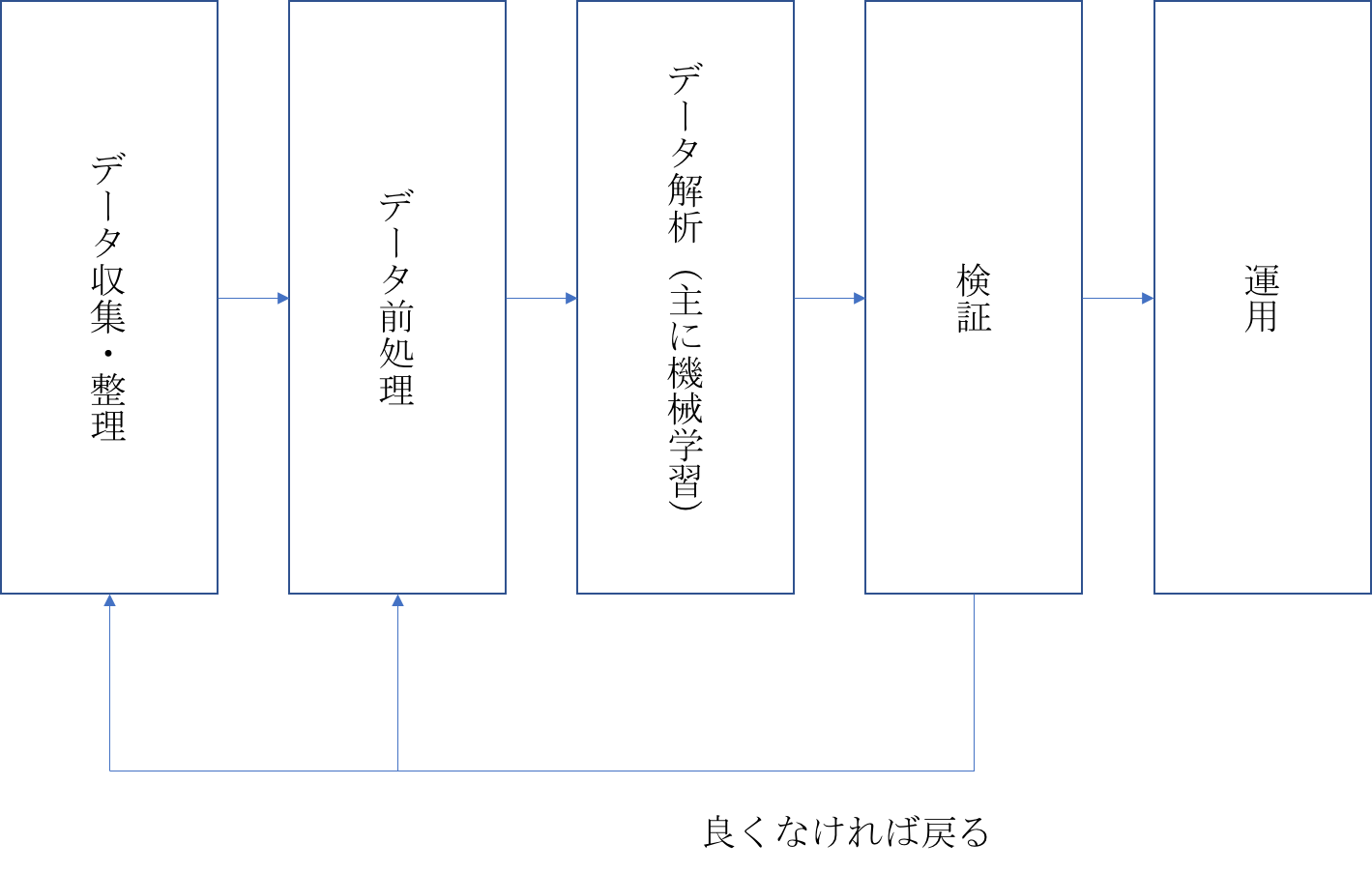
そして、レストランであるメニューを作っていく工程は以下の流れではないでしょうか。
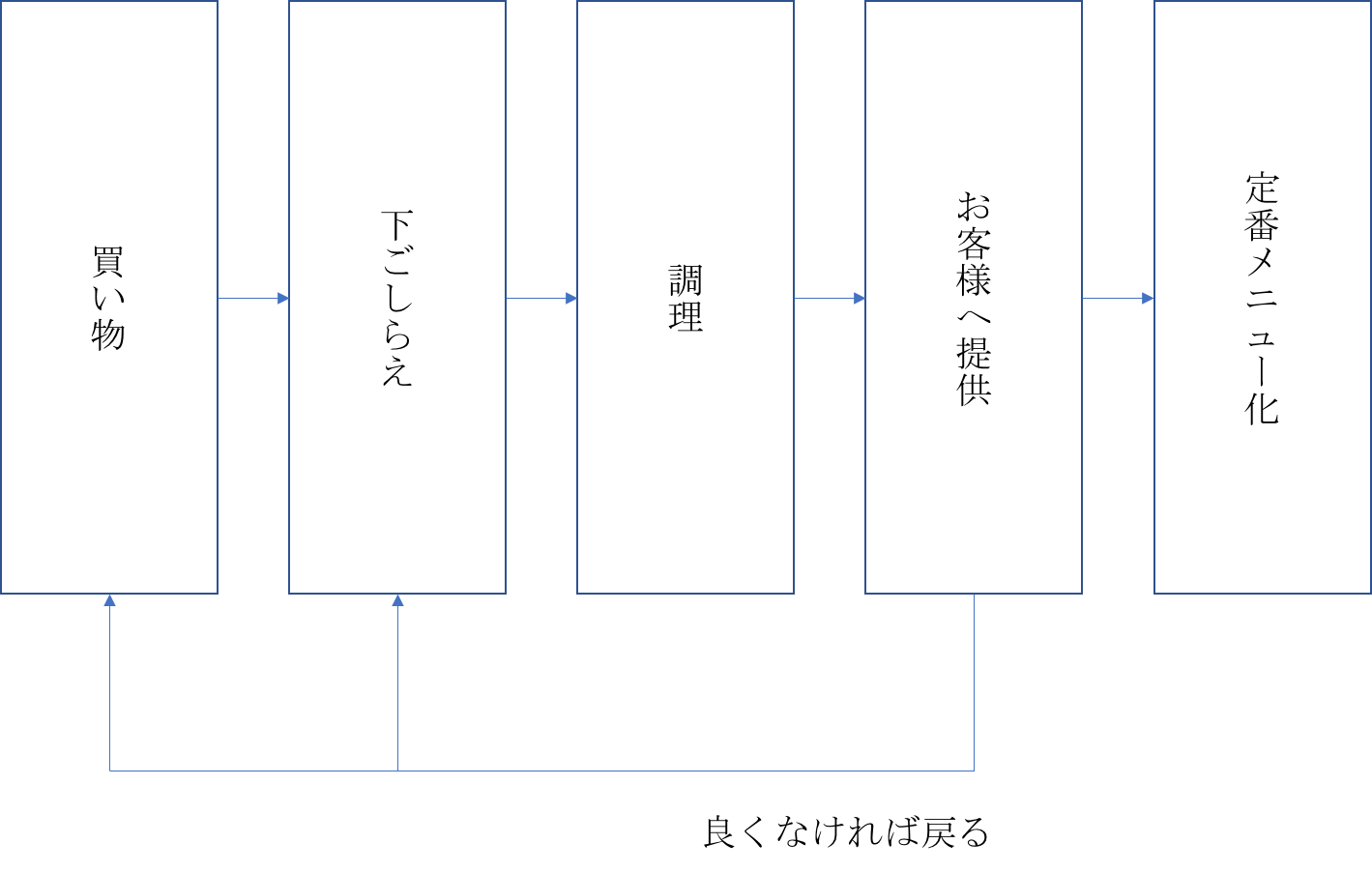
それでは、それぞれの工程について例えとともに見ていきましょう。
『データ収集・整理』=『買い物』

機械学習の案件で、まず一番最初に取り組むべきこととして、データの収集と整理が必ずあります。
既にこのデータが揃っている状況であればかなりラッキーですが、『揃っているデータ=使えるデータ』でもないケースが多く、結局『使えるデータの収集』は機械学習のことを詳しく知っている人でないとできません。
そのため、工数の見積りに入れ忘れてはいけない工程のひとつです。
『解析をお願いしていて、データ揃えるのもお金払わないといけないの?』
と言われた際には、
『料理の依頼をして材料の買い出しの時間にはお金を払わないことありますか?』
と尋ねると納得してもらえるかも知れません。
料理を行うためには、もちろん一番最初に、決めた料理を作るために必要な材料をリストアップして、材料の売っているスーパーを調査して、材料をスーパーに購入しに行く必要があります。
もちろん、料理のことを知らないで揃えられた材料で、決めた料理を作ることができるわけないですよね?
これが『揃っているデータと使えるデータが違う』ということです。
もちろん、与えられた材料の中でなんとか料理を作って欲しいという依頼であれば、ありあわせの材料で作った賄いを作ることができますが、本当に食べたい料理を作るのであれば、シェフに材料の調達も任せるべきなのです。
シェフが材料のリストアップを行い、買い物はアルバイトに任せるなどして行い、美味しい料理を作るために適切な材料を揃えてくれるはずです。
そのため、機械学習エンジニアには、必要な材料のリストアップを行うスキルやどの部署(スーパー)に行けば欲しいデータ(材料)が手に入るかを知る必要があります。
リストアップを行う際には、カッコを付けずに、現場でのヒアリングが一番効果が高く、私は現場に出向いて職人の方にどこに着目しているか?といった要因に関する話を尋ねるようにしています。
案外、この要因をしっかり聞くだけで、データを解析する前から重要な変数への目処をつけることができ、少ない変数の数でも精度を高められるというのが、個人的な経験談です。
『データ前処理=下ごしらえ』

いつもよく言っている話ですが、データの整理や前処理にデータ解析プロジェクトの大半の時間を費やします。
とは言え、なかなかデータ解析の作業風景をイメージできない方にとっては、この現実が受け入れられるものではありません。
解析を始めれば、「どう?成果出た?」と聞かれる日々で、その質問のたびにテンションが下がってしまう人も多いのではないでしょうか。
その際には、『まだ野菜の皮剥きといった調理のための準備に時間をかけているので、まだ料理が出来上がった報告はできないのです』というと少しは納得してもらえるかも知れません。
それでも納得してもらえない場合は、
『どれだけ優れたコックがいたとしても、エビの殻をむかずに調理すれば、それでお客様が満足できる料理にはならないのではないでしょうか』
というと、もう少し説得力が増し、前処理の時間も必要だと理解してもらえるかも知れません。
『データ解析(主に機械学習)=調理』

材料の準備が終わると、煮るなり焼くなりして、材料をひとつの形にまとめ上げます。
決して、全ての材料(データ)に対して『焼く』といった手法が適切ではなく、材料(データ)によっては『煮る』方が適切な場合もあります。
また、状況によっては、『煮た後に焼く』といった合わせ技もあるかも知れません。
そんな『煮る』や『焼く』などの調理法ひとつひとつに対応するものが機械学習のアルゴリズムです。
『万能な調理法はありませんよ』とお伝えすると、『それは素材によって違いますもんね』と納得していただけますが、
『今回はディープラーニングより適切な手法があると思いますがいかがでしょうか?』と提案すると、がっかりされるケースも少なからずあります。
そして、受講生の方々も『ディープラーニングを学びたい!』というモチベーションの強い方が多くいらっしゃいますが、データやクライアントの要望に合わせて手法はケースバイケースで選択するため、それぞれの手法を広く理解しておくことをおすすめします。
(焼くだけを覚えればプロとして大丈夫と教える料理の専門学校があるでしょうか?)
とは言え、ディープラーニングでの適用範囲は他の手法と比べると広いため、幅広い料理に使える中華鍋(調理法ではありませんが)ぐらいの位置付けかもしれません。
『オーバーフィッティング=コックの主観』

機械学習にはオーバーフィッティング(過学習)と呼ばれる訓練データではばっちりと精度が出るのですが、実運用を始めると、まったく精度がでないと言う現象にしばしば遭遇します。
調理を行っているコック(学習用のデータ)としては、『抜群に美味しい料理ができた!』と思っていても、それが世間一般として美味しいとは限らないのです。
これがオーバーフィッティングの原因です。
そうならないためにも、コックは他の人に味見(検証)をしてもらって、世間一般の美味しいに合わせた料理を作れるようになる必要があります。
『訓練データと検証データ=コックとテスター』

オーバーフィッティングの対策として、コックの主観(訓練データ)だけでなく、他の人の意見(味見)を聞く必要があります。
そのため、機械学習では、手持ちのデータを訓練データと検証データに分割して、訓練データはモデルの学習に使用して、検証データはモデルの精度を確認するために使用します。
イメージとしては、他のコックに味見をしてもらったり、テスターを招いて味見をしてもらって美味しいかを客観的に判断してもらう作業です。
ここで大事な点としては、『30代女性に好かれる料理』と定めた場合、そのペルソナに合った人に味見のテストを依頼する必要があります。
これは機械学習の検証データ選びと同じで、予測したいと定めている状況(ペルソナ)において、予測精度が良いことを確かめる必要があるため、全てのデータに対して予測精度が高い必要はありません。
『ハイパーパラメータのチューニング=最後の塩コショウ』

機械学習ではハイパーパラメータと呼ばれる人間側で調整すべき変数が存在します。
これもなかなか伝わりづらかったりするのですが、料理も完成間近に塩コショウなどで最後の味付けを行いますよね?
これと同じで、機械学習においても最終的なチューニングが必要となります。
このハイパーパラメータがどこに存在するかよくわからないといった悩みから数学をちゃんと勉強される方が多いです。
このご時世、優秀なライブラリの登場により、ほとんどがプログラミングだけで機械学習を実装出来るようになっていますが、この最後の味付けのポイントを抑えておかないと最後の最後に締まりのない結果(味)となります。
そういった悩みまで到達してから数学を学び始めても大丈夫ですし、やはり原理がわからないと気持ち悪くて始められないという方は、最初から数学とプログラミングを1セットで勉強することをおすすめします。
『検証=お客様へ提供』

前回の記事でも書いていましたが、
『検証とは、検証データに対する結果をみることではなく、仮運用をはじめた後に得られる結果を見ることである』
だと考えています。
そのため、実際にお客様へ提供して初めて本当のターゲットからの評価が得られ、そちらが本当の意味での検証となります。
美味しくなければ注文の数が減っていき、美味しければ注文の数が増えるといった本番での検証を行うことができます。
そのため、検証とは3段階あり、『コックが味見(訓練データに対する検証)』、『テスターが味見(検証データに対する検証)』、『店のお客様に提供して調査(仮運用を始めた後に得られるデータに対する検証)』です。
ここで気をつけないといけないこととしては、テスターでの味見でクライアントが納得するのではなく、基本的にはそのレストランに来るお客様が喜ぶかどうかを確認するまでは、プロジェクトの完結ではないということです。
ここで、3段階目でも高評価であれば、定番メニュー化(本運用)となります。
おわりに
いかがでしたでしょうか。
機械学習の工程を料理で例えると、落とし穴のポイントであったり、どのくらい重要で時間がかかる作業であるかが、少しは見えてくるかもしれません。
ぜひ、クライアントとの交渉を行う際に、わかりやすい例として使っていただければ幸いです。
他にも、この例はわかりやすいよ!というものがありましたら、こちらの記事に追記させていただきますので、コメントいただけますと嬉しいです。
長文お読みいただき、ありがとうございました。
著者紹介
株式会社キカガク
代表取締役社長 吉崎 亮介(twitter: @yoshizaki_kkgk)

一緒に機械学習の教育を推進してくださるメンバーを募集しています!
ぜひ、Twitterからメッセージお待ちしています!