はじめに
こんにちは。
株式会社キカガク代表の吉崎です。

ChainerUIが公開され、とうとうChainerもリアルタイムに可視化することができる!と喜びの瞬間でした。
TensorFlowにはTensorBoardが存在していたため、Chainerにもあればなぁ、、、作ろうかなぁ、、、と迷っている段階でもありました。
そういったわけで、便利であることは間違いないChainerUIの使い方を、誰よりも先に紹介していきます。
環境構築
まずはGitHubのChainerUIのページへアクセスしましょう。

こちらに記載されているREADME.mdの通りに進めていきましょう。
まずは前提として、Chainerがインストールされていることとします。
PythonやChainerのインストール方法は下記の記事で解説しておりますので、こちらを御覧ください。
今回はMacで設定を行いますが、基本的にはWindowsの方も同様に進めることができるので、ご安心ください。
ChainerUIのインストール
まず、ターミナル(Windowsの方はコマンドプロンプトかWindows Powershell)
$ pip3 install chainerui
# もしくは pip install chainer
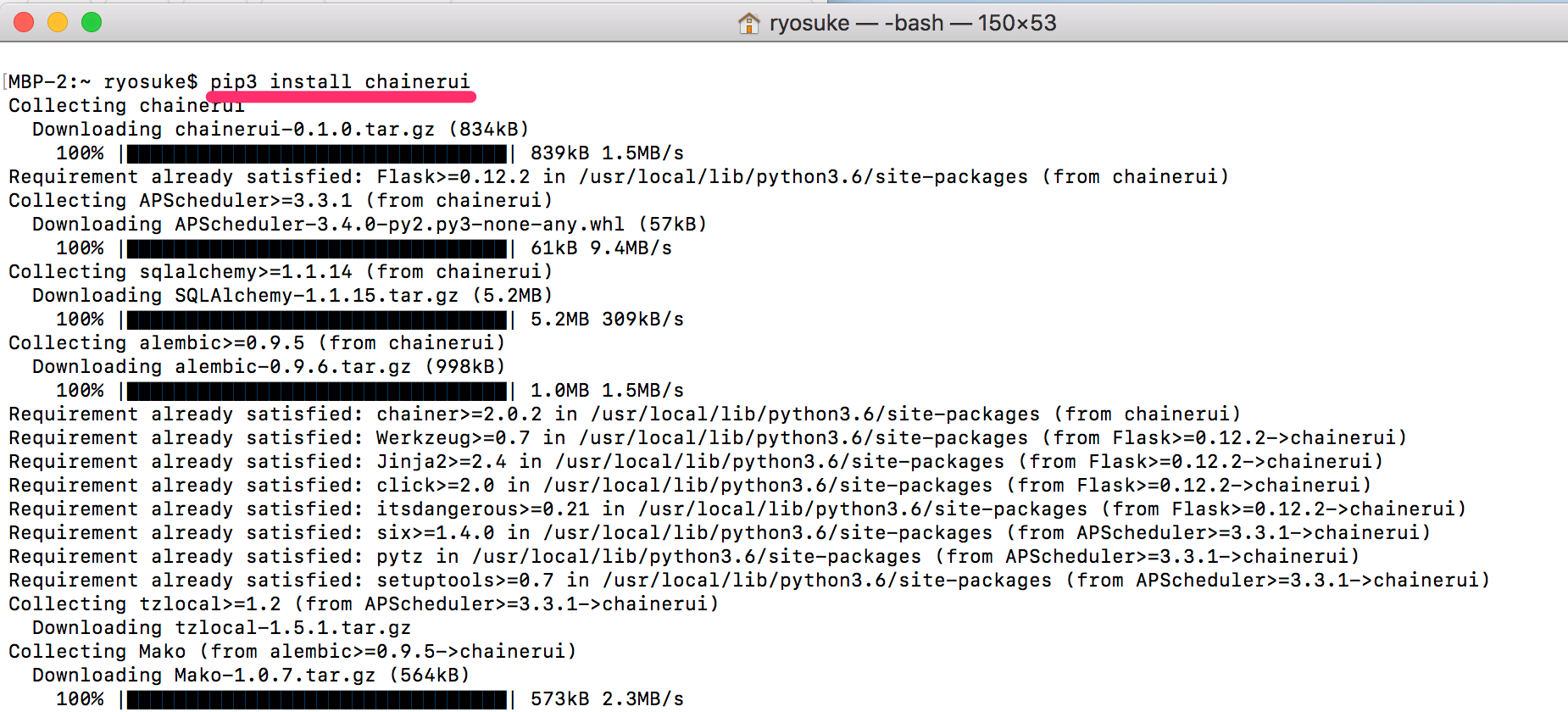
ここで正しくインストールできているか確認しておきましょう。
コマンドが存在しているかはwhichで確認しましょう(※コマンドプロンプトにはないかもです)。
$ which chainerui
うまくインストールができていれば、下記のようにコマンドのpathが表示され、インストールができていなければ、なにもpathが表示されません。
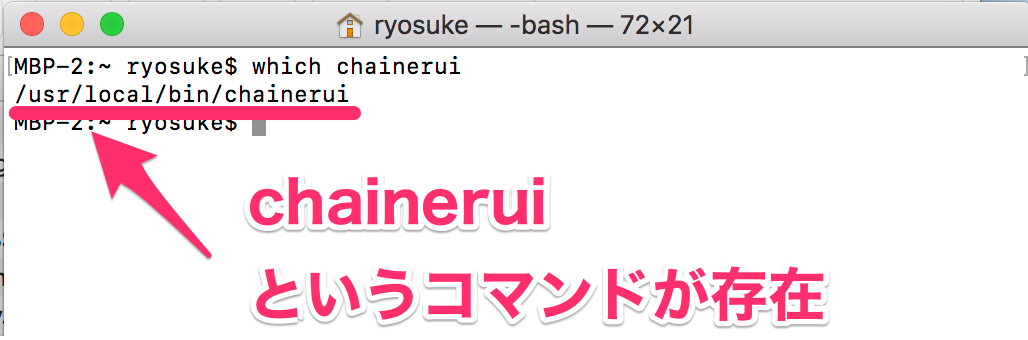
今回は、うまくpathが表示されたため、インストールが完了していることがわかります。
それでは、まだ設定は終わっていませんが、アプリケーションを使ってみましょう。
$ chainerui server
これでWebサーバーが起動され、下記の画像のように http://localhost:5000/ にアクセスすれば良いことがわかります。

Webブラウザでアクセスしてみると、下記のように「There is no project yet.」と出ますが、起動できていることが確認できます。

一旦ここで動作確認はおしまいで、Ctrl + Cでアプリケーションを停止しておきましょう。
ここで、手順書どおり、DBの初期化を行っておきましょう。
$ chainerui db create
$ chainerui db upgrade
特に何も起こらなかったのですが、DB用のPATHなどが書き込まれたようです。
内部ではSqlite3が動いているようで各プロジェクトごとにディレクトリを作って参照するのではなく、どこかに共通のDBが作られており、そちらを参照しているようです。
Quick Start
まずはサンプルプロジェクトで良いので、使ってみましょう。
こちらも README.md に記載されている内容です。
# chaineruiのソースを一式ダウンロード
git clone https://github.com/chainer/chainerui.git
# ダウンロードしたディレクトリに移動
cd chainerui
# 新規プロジェクトの作成
chainerui project create -d examples -n example-project
# Webサーバーの立ち上げ
chainerui server
なお、chainerui project createの後のオプションは以下のとおりです。
-
-d:プロジェクトのディレクトリ(--project-dirも同じ) -
-n:プロジェクトの名前(--project-nameも同じ)
ここで、http://localhost:5000にアクセスしてみましょう。
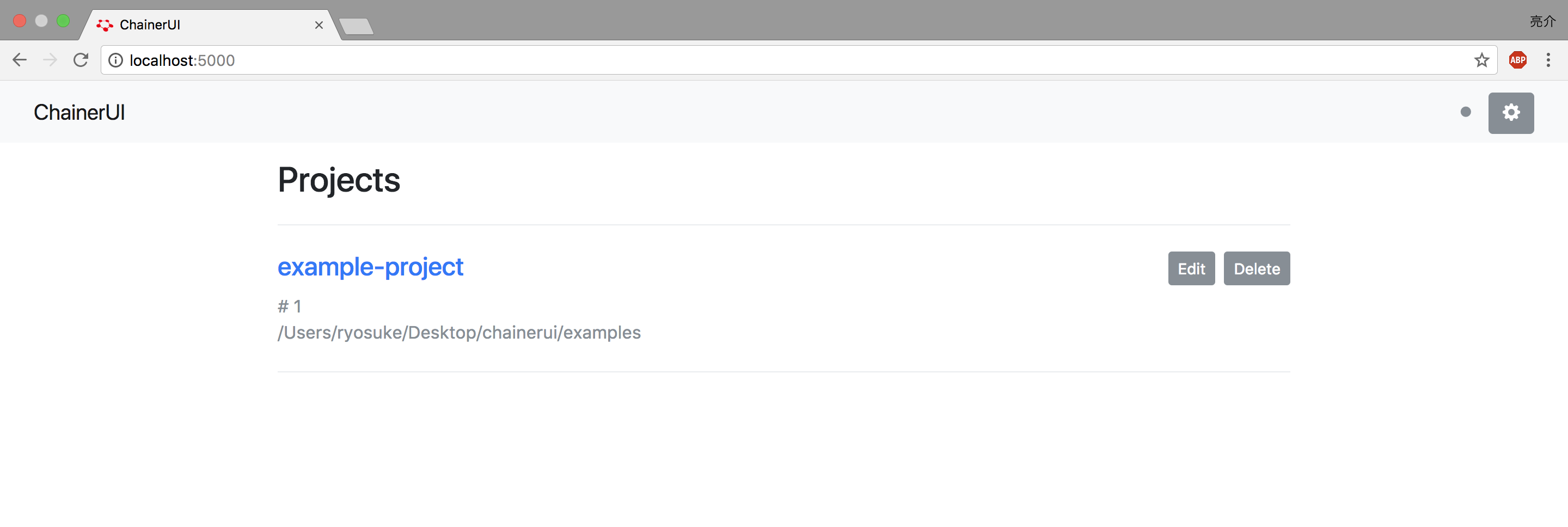
こちらのように、Projectが始まりました。
それでは、example-projectにアクセスしてみましょう。
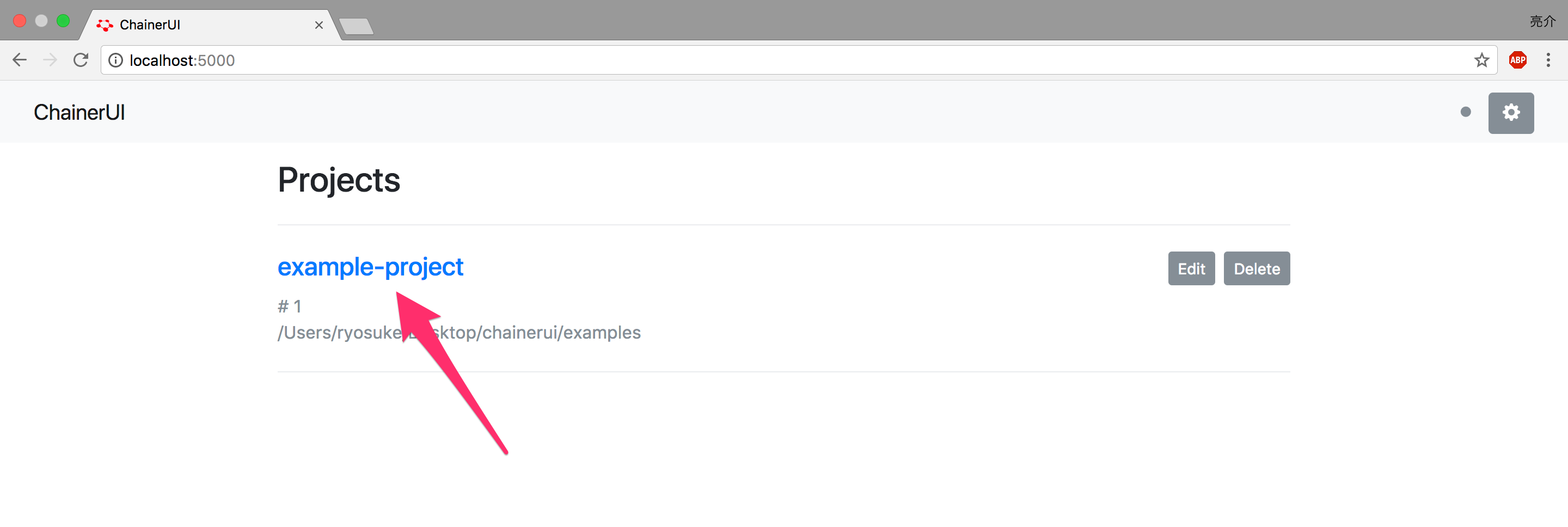
こちらのように非常に綺麗なUIが表示されました。感動です。
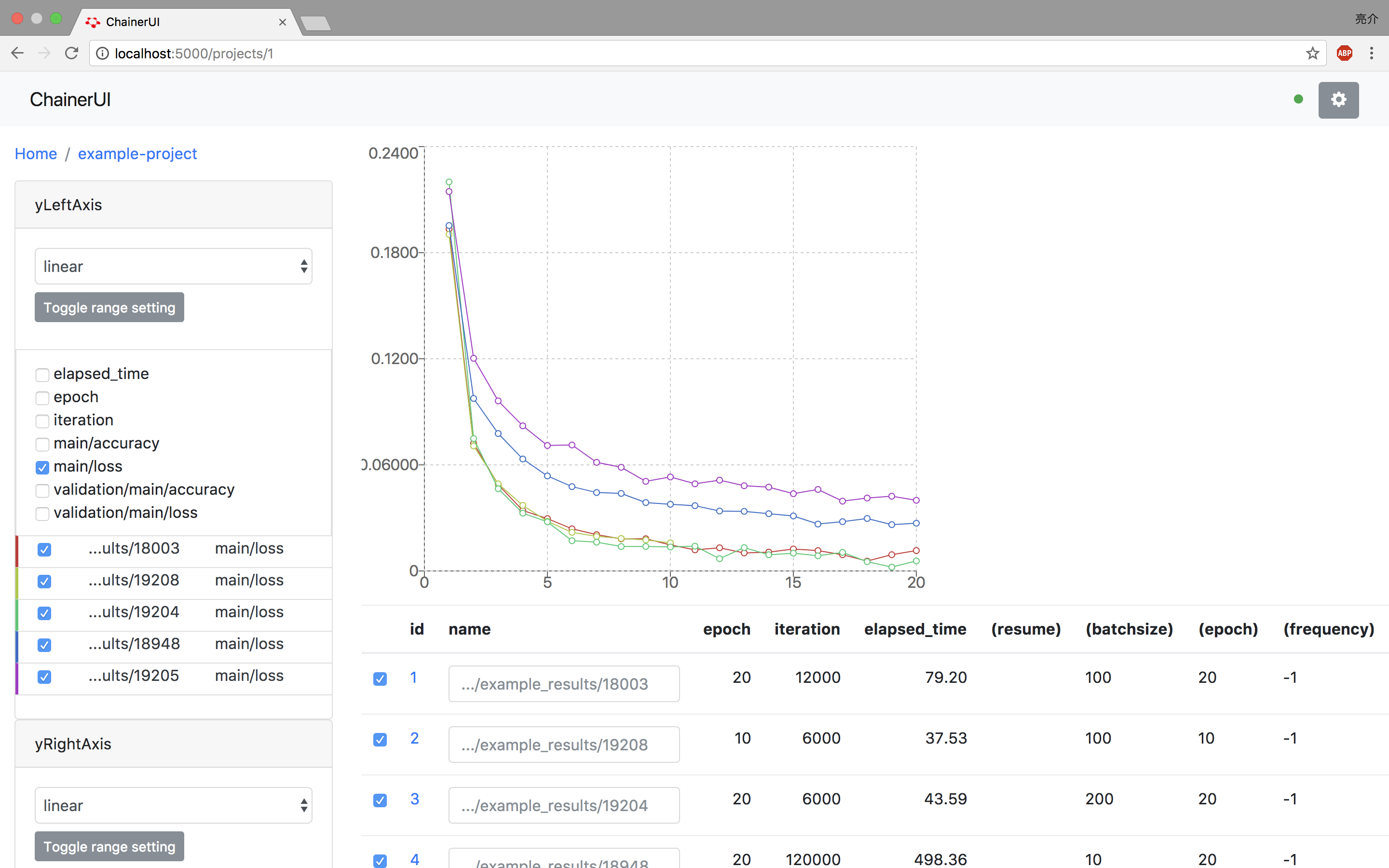
基本的には、ChainerのTrainerで書き込むことができるLogReportのlogを読み込んでいるようなので、日常のプロジェクトにもすぐ使えそうです。
簡単な自前のプロジェクトを作成しよう
サンプルプロジェクトで動いて満足しないのがキカガク流です。
まずはサンプルプロジェクトを動かし、次に簡単でも良いので自前のデータに対しても動くことを確認していきます。
今回は、ワインの等級をその成分から分類する定番の問題で考えていきましょう。
せっかくなので、少しChainerの使い方も紹介していおきましょう。
ディレクトリの構成
今回はtestというディレクトリの中でJupyter Notebookを起動して、Trainerで学習させた結果をresultというディレクトリのlogとして保存するようにしています。
test
├── ChianerUIのテスト.ipynb
└── result
└── log
準備
まず最初にディレクトリの作成を行っておきましょう。
$ mkdir test
$ cd test
そして、Jupyter Notebookを立ち上げましょう。
$ jupyter notebook
これでブラウザ上でhttp://localhost:8888へアクセスし、Juptyer Notebookへアクセスができれば完了です。
データの読み込み
import pandas as pd
# サンプルデータの置き場所
url = 'https://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
# データの読み込み
df = pd.read_csv(url, header=None)
こちらで読み込んだデータは以下のようになります。
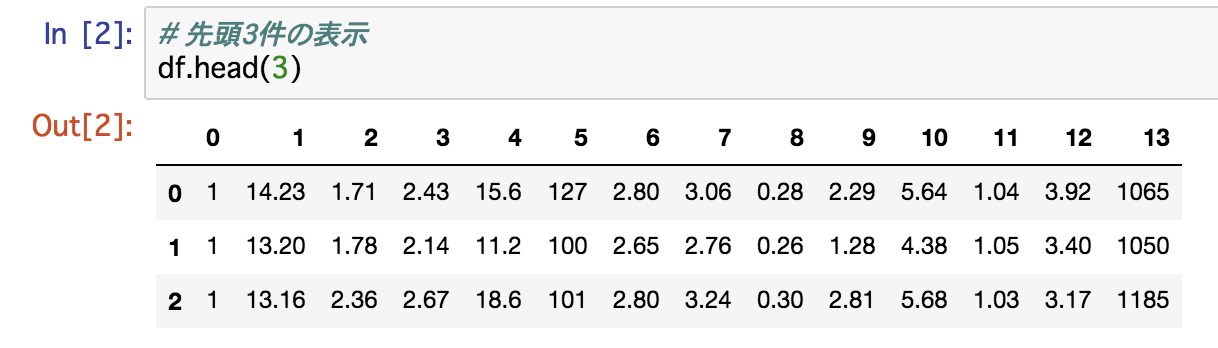
一番左の列がワインの等級(教師データt)であり、それ以外が使用する入力変数xとなります。
# Chainerのラベルは0始まりのため1を引く + numpy int32に変換
t = (df.iloc[:, 0].values - 1).astype('i')
# numpy float32に変換
x = df.iloc[:, 1:].values.astype('f')
Pandasをうまく使って切り分けるのですが、Chainerではデフォルトのデータ型がint32もしくはfloat32であることに留意して変換したげることと、クラスラベルは0から始めることに気をつけています。
import chainer
# datasetの作成
dataset = list(zip(x, t))
# 訓練(70%)と検証(30%)に分ける
n_train = int(len(dataset) * 0.7)
train, test = chainer.datasets.split_dataset_random(dataset, n_train, seed=0) # ! シードの固定を忘れないように
chainer.datasetsで準備されている関数を使用して、全体の70%を訓練、30%を検証データとします。
ちなみに、本日時点で最新版のChainerを使用しており、chainer.__version__で調べると、3.2.0でした。
モデルの作成
Chainerで簡単なNNモデルを定義し、インスタンス化しましょう。
まずは必要な主要ライブラリの下記2つを読み込みましょう。
import chainer.links as L
import chainer.functions as F
そして、NN用のクラスを定義しましょう。
class NN(chainer.Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.fc1 = L.Linear(13, 5)
self.fc2 = L.Linear(5, 3)
# 順伝播
def __call__(self, x):
h = self.fc1(x)
h = F.relu(h)
h = self.fc2(h)
return h
とても簡単な 入力層(13ノード) → 中間層(5ノード) → 出力層(3ノード)の構成としています。
入力層から中間層の線形変換の後に、非線形変換としてRelu関数も使用しています。
このあたりをもう少し詳しく勉強したい方は、ディープラーニングハンズオンセミナーを覗いてみてくださいね。
インスタンス化して、モデルを宣言します。
import numpy as np
# シードの固定
np.random.seed(1)
# NNモデルを宣言
nn = NN()
model = L.Classifier(nn)
ここで、モデル内で使用されるパラメータの初期化がランダムに行われるため、シードの固定を忘れないように気をつけてください。
ChainerではNumpyのシードを固定すればOKです。
基本的には、こちらの順伝播だけユーザー側で定義しておけば、後はChainer側でパラメータの最適化が行われます。
モデルの学習
それでは、下記のようにoptimizerを定義したりしながら、Trainerを使用して学習を行いましょう。
基本的には、下記のコードを毎回コピペして、適宜必要な箇所だけ変更するようにしています。
# 最適化のアルゴリズムには SGD を使用
optimizer = chainer.optimizers.SGD()
optimizer.setup(model)
# iteratorsの設定
batchsize = 20
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
# updaterの設定
updater = chainer.training.StandardUpdater(train_iter, optimizer, device=-1)
# trainerとそのextensionsの設定
from chainer.training import extensions
# trainerの基本設定
epoch = 100
trainer = chainer.training.Trainer(updater, (epoch, 'epoch'), out='result')
# 評価データで評価
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
# 学習結果の途中を表示する
trainer.extend(extensions.LogReport(trigger=(1, 'epoch')))
# 1エポックごとに、trainデータに対するaccuracyと、testデータに対するaccuracyを出力させる
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']), trigger=(1, 'epoch'))
# 学習の実行
trainer.run()
これを実行すると、途中経過が表示されながら学習が実行されます。
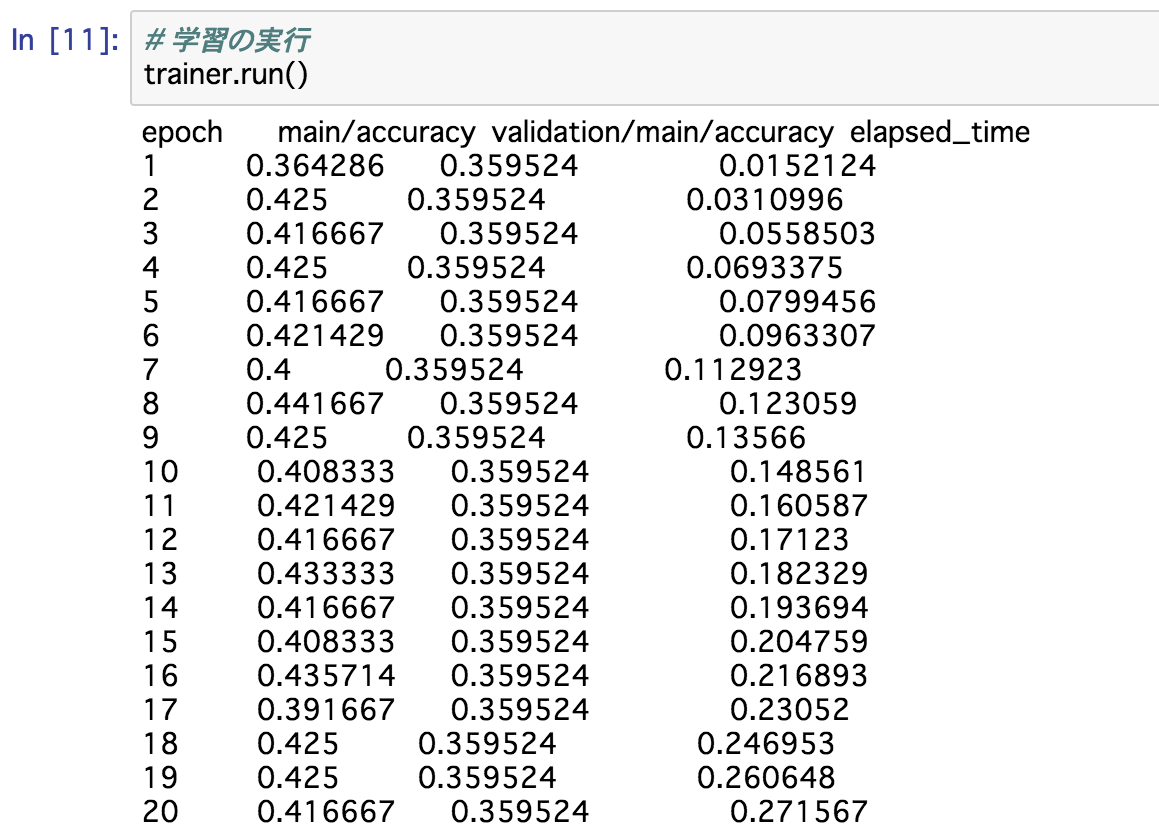
はい、ここまでが学習です。
こちらの学習結果がresult/logに保存されているため、確認してみましょう。
ChainerUIで結果の確認
Jupyter Notebookでターミナルを1つ立ち上げていると思いますが、もう1つ別のターミナルを立ち上げましょう。
今回使用しているtestのディレクトリに移動した後に、まずはChainerUI用のプロジェクトを作成しましょう。
$ chainerui project create -d result -n test-project
logデータの格納先ディレクトリであるresultをプロジェクトのディレクトリとしておき、名前は適当にtest-projectとしました。
こちらのプロジェクトを作成後に、ChainerUIのWebサーバーを立ち上げると、新しいプロジェクトが追加されています。
$ chainerui server
http://localhost:5000にアクセスすると、下記のように、test-projectが増えていました。

そして、プロジェクトにアクセスすると下記のように綺麗に表示されていました。
※ 設定で横幅等編集しています。

とても綺麗!素晴らしいですね!
これで、学習を実行させながらリアルタイムにモニタリングが出来るようになります。
特にGPUマシンを使用するため、クラウド環境が多くローカルよりもデータの可視化に少し手間取るところが解消されますね。
ChainerUI素晴らしいです。
ここまででChainerUIの使い方に関しての解説は終了ですが、そもそも分類の結果が全然良くないため、少しその改善策についてせっかくなので、レクチャーしていきましょう。
発展:モデルのカスタマイズを行おう
複数の変数がある場合にあるあるなのが、スケールによる違いを考慮できていないことです。
もう一度データを見てみましょう。

列番号13の変数では1065, 1050, 1185, ...とスケールが他よりも大きいことがわかると思います。
それにも関わらず、ニューラルネットワーク内の重みは同じスケールでランダムに生成されており、重み×入力変数の値が与える影響が大きく異なることがわかると思います。
この問題を解決するには、データの標準化などのスケーリングを行うのですが、前処理として行うよりも、ディープラーニングでは BatchNormalization を使用すると非常に楽に実装できるため便利です。
Chainerでは、L.BatchNormalizationが準備されています。
それでは、BatchNormalizationを使用して、スケーリングの処理も施した状態のニューラルネットワークを学習させてみましょう。
モデルの定義
# モデルの定義
class NN(chainer.Chain):
def __init__(self):
super().__init__()
with self.init_scope():
self.fc1 = L.Linear(13, 5)
self.fc2 = L.Linear(5, 3)
self.bn1 = L.BatchNormalization(13) # 追記
self.bn2 = L.BatchNormalization(5) # 追記
# 順伝播
def __call__(self, x):
h = self.bn1(x) # 追記
h = self.fc1(h)
h = F.relu(h)
h = self.bn2(h) # 追記
h = self.fc2(h)
return h
モデルの学習
モデルの定義以降は全く一緒ですので、こちらで学習させていきましょう。
# シードの固定
np.random.seed(1)
# NNモデルを宣言
nn = NN()
model = L.Classifier(nn)
# 最適化のアルゴリズムには SGD を使用
optimizer = chainer.optimizers.SGD()
optimizer.setup(model)
# iteratorsの設定
batchsize = 20
train_iter = chainer.iterators.SerialIterator(train, batchsize)
test_iter = chainer.iterators.SerialIterator(test, batchsize, repeat=False, shuffle=False)
# updaterの設定
updater = chainer.training.StandardUpdater(train_iter, optimizer, device=-1)
# trainerとそのextensionsの設定
from chainer.training import extensions
# trainerの基本設定
epoch = 100
trainer = chainer.training.Trainer(updater, (epoch, 'epoch'), out='result')
# 評価データで評価
trainer.extend(extensions.Evaluator(test_iter, model, device=-1))
# 学習結果の途中を表示する
trainer.extend(extensions.LogReport(trigger=(1, 'epoch')))
# 1エポックごとに、trainデータに対するaccuracyと、testデータに対するaccuracyを出力させる
trainer.extend(extensions.PrintReport(['epoch', 'main/accuracy', 'validation/main/accuracy', 'elapsed_time']), trigger=(1, 'epoch'))
# 学習の実行
trainer.run()
結果が下記のように表示されます。

今回はBatchNormalizationの効果によって、かなり大幅に性能が改善できていそうですね。
そして、Trainerによってlogファイルが更新されるかと思いきや、同じファイル名の場合は更新されないようですね。
ChainerUIのサーバーを一旦停止して、projectをUI側から削除し、もう一度プロジェクトを作成しました。
$ chainerui project create -d result -n test-project
$ chainerui start

そうすると、上記のようにとても綺麗な画面が表示されました。
おそらく、プロジェクトの再作成とWebサーバー再起動は非常に効率が悪い方法であるため、試していただいた方で効率良く再読込できる方法を見つけた方はコメントお願いします。
おわりに
ChainerUI便利ですね。
非常に綺麗に表示されるので、お客様先の満足度が上がること間違いなしです。
とても良いサービスをありがとうございます。
みなさん、ChainerUIでハッピーなChainerライフを送りましょう!
参考
Chainerの実験に対してログを可視化したり外部制御するExtension&WebアプリをPFNで作った
著者紹介
株式会社キカガク
代表取締役社長 吉崎 亮介(twitter: @yoshizaki_kkgk)
一緒に機械学習の教育を推進してくださるメンバーを募集しています!
ぜひ、Twitterからメッセージお待ちしています!