YOLOv3よりも精度が良いらしいM2Detを翻訳して箇条書きでまとめます.
原文: 「M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network」
ざっくりまとめ
Abstract
- 特徴ピラミッド構造のバックボーンはclassificationのために設計されてるから制限がある
- マルチ特徴ピラミッドネットワーク(MLFPN)を提案しました.
- SSDのアーキテクチャに組み込むと,精度がすごい(語彙力)出た.
Introduction
- 特徴ピラミッド構造は物体検出に都合が良いけど,いくつか制限がある
- 問題1 classificationのモデルをそのまま単純に利用しがち
- SSD, STDN, FPNについて問題点を記述
- 問題2 信号機と遠く離れた人の複雑さの違い
- TLN・FFMを使ったMLFPNを提案,M2Detが精度でた.
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
概要
特徴ピラミッド1は,オブジェクトインスタンス間の縮尺の違いという問題を軽減するため,the state-of-the artな物体検出器によって広く利用されています(one-stage detector2ではDSSD3, RetinaNet4, RefineDet5やtwo-stage detector6ではMask-RNN7, DetNet8など).
特徴ピラミッドを有するこれらのオブジェクト検出器は,有望な結果を達成しますが,
これらはもともとオブジェクト分類タスクのために設計されているバックボーン固有のマルチスケールピラミッドアーキテクチャにしたがって特徴ピラミッドを単に構築するだけであるため,いくつかの制限があります.
今回,本研究では,異なる規模の物体を検出するためのより効果的な特徴ピラミッドを構築するために,マルチレベル特徴ピラミッドネットワーク(MLFPN)を提示します.
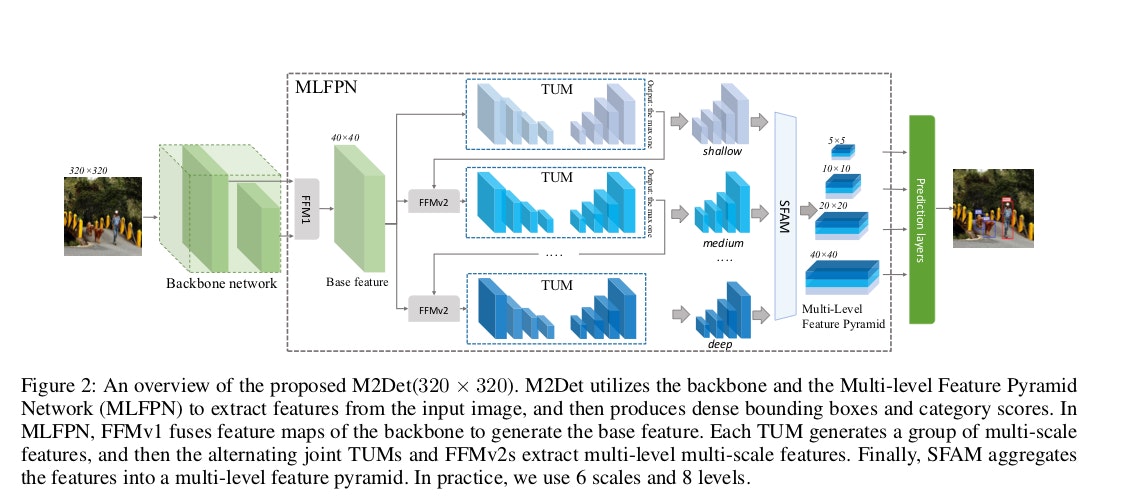
最初に,基本機能としてバックボーンによって抽出された,マルチレベル機能を融合します.次に,基本特徴を交互に結合したU字型モジュールと,特徴変異モジュールのブロックにフィードし,各U字型モジュールのデコーダレイヤをオブジェクト検出用のフィーチャとして利用します.最後に,同等の縮尺でデコーダレイヤをまとめて,全ての特徴マップが複数レベルの(特徴)レイヤで構成されているオブジェクト検出用の特徴ピラミッドを作成します.
提案されたMLFPNの有効性を評価するために,SSDのアーキテクチャに統合することによってM2Detと呼ぶ強力なエンドツーエンドのone-stage detectorを設計し,訓練したところ,one-stage detectorの最先端技術より良い検出性能を達成しました.具体的にはMS-COCOベンチマークでは,M2DetはAP 41.0 (11.8 FPS)のスコアを達成しました.シングルスケールの推論戦略で11 FPS,マルチスケールの推論戦略でAP 44.2であり,これはone-stage detectorの中では最先端の結果です.
コードは https://github.com/qijiezhao/M2Det で公開されます.(2018/02/20現在: レポジトリのみ)
はじめに
スケールオブジェクトインスタンスは,物体検出タスクのための主要な課題の一つで,この問題の解決に挑戦するには,通常2つの戦略があります.1つ目は,画像ピラミッド内のオブジェクト(入力画像の一連のサイズが変更されたコピー)を検出することです.これは,テスト時にしか利用できません.明らかに、この解決法はメモリおよび計算上の複雑さを非常に増大させるため、そのような物体検出器の効率は劇的に低下します。2つ目は、入力画像から抽出された特徴ピラミッドの中のオブジェクトを検出することです。これは、トレーニングとテストの両方の段階で利用できます。画像ピラミッドを使用する最初のソリューションと比較すると、メモリと計算コストが少なくて済みます。さらに、特徴ピラミッド構築モジュールは、最先端のディープニューラルネットワークベースの検出器に容易に統合することができ、エンドツーエンドの解決策をもたらします.
特徴ピラミッドを有する物体検出器は有望な結果をもたらしますが、それでもなおいくつかの制限があります。それは、オブジェクト分類タスク用に実際に設計されているバックボーンの固有のマルチスケールのピラミッド型アーキテクチャに従って、機能ピラミッドを単純に構築するということです。例えば、図1に示すように、SSDは独立骨格(e.g. VGG16)から二つの層を使用し,特徴ピラミッドを構築するためにストライド2の畳み込み層を4つ追加しています。STDNのみDenseNetの最後稠密ブロックを使用して操作をプールし、スケール移動によって特徴ピラミッドを構築します。FPNは深い層と浅い層をトップダウン方式で融合して、フィーチャーピラミッドを構築します。一般的に言って、上記の方法には以下の2つの制限があります。第1に、ピラミッド内の特徴マップは、物体検出タスクにとって十分に代表的なものではなく、それらは、物体分類タスクのために設計されたバックボーンのレイヤ(特徴)から単に構築されます。次に、ピラミッド内の各フィーチャマップ(特定のサイズ範囲のオブジェクトを検出するために使用される)は、バックボーンのシングルレベルのレイヤから主に、または単独で構築されます。つまり、単一レベルの情報のみを含みます。一般に、より深い層における高レベルの特徴は分類サブタスクにとってより識別力があり、より浅い層における低レベルの特徴はオブジェクト位置回帰サブタスクにとって有用です。また、低レベルの機能は、単純な外観を持つオブジェクトを特徴付けるのに適していますが、高レベルの機能は、複雑な外観を持つオブジェクトに適しています。実際には、同じサイズのオブジェクトインスタンスの外観はかなり異なる場合があります。例えば、信号機と遠く離れた人とは同程度のサイズである可能性があり、その人の外観ははるかに複雑になります。したがって、ピラミッド内の各フィーチャマップ(特定のサイズ範囲のオブジェクトの検出に使用される)は、主に、または単一レベルのフィーチャのみで構成されているため、次善の検出パフォーマンスが得られます。信号機と遠く離れた人は同程度の大きさであるかもしれず、その人の外見はずっと複雑です。したがって、ピラミッド内の各フィーチャマップ(特定のサイズ範囲のオブジェクトの検出に使用される)は、主に、または単一レベルのフィーチャのみで構成されているため、次善の検出パフォーマンスが得られます。信号機と遠く離れた人は同程度の大きさであるかもしれず、その人の外見はずっと複雑です。したがって、ピラミッド内の各フィーチャマップ(特定のサイズ範囲のオブジェクトの検出に使用される)は、主に、または単一レベルのフィーチャのみで構成されているため、次善の検出パフォーマンスが得られます。
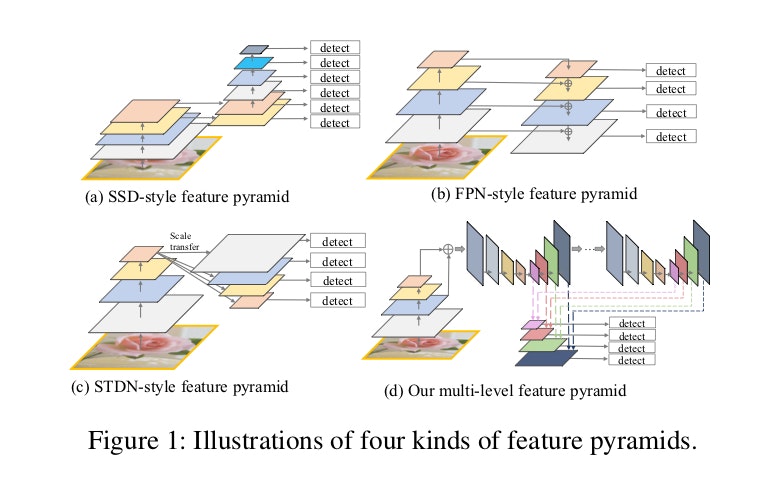
本論文の目的は、上述の既存の方法の制限を避けながら、異なるスケールの物体を検出するためのより効果的な特徴ピラミッドを構築することです。図2に示すように、この目標を達成するために、最初のマルチレベルの機能を融合,すなわちベースフィーチャとしてバックボーンから抽出し、次にそれを交互結合のU字型モジュール(TUM)とフィーチャフュージョンモジュール(FFM)のブロックにフィードして、より代表的なマルチレベルマルチスケールフィーチャとして抽出します。注目すべきは、各U字型モジュール内のデコーダレイヤが同じ深さを共有していることです。最後に、オブジェクト検出のための最終的な特徴ピラミッドを構築するために、同等の縮尺で特徴マップを集めます。明らかに、最終的な特徴ピラミッドを形成するデコーダレイヤは、バックボーン内のレイヤよりもはるかに深く、それらはより代表的です。さらに、最終特徴ピラミッド内の各特徴マップは、複数のレベルからのデコーダ層からなる。それゆえ、この特徴ピラミッドブロックをマルチレベル特徴ピラミッドネットワーク(MLFPN)と呼ぶ。
提案されたMLFPNの有効性を評価するために、MLFPNをSSDのアーキテクチャに統合することによって、M2Detと呼ぶ強力なエンドツーエンドの1ステージ物体検出器を設計・訓練した。 M2Detの結果(達成すなわち単一スケール推論戦略とマルチスケール推論戦略と44.2 APと11.8 FPSの速度で41.0 AP)は、MS-COCOの一段階検出器のベンチマークにおいて(既存の手法を)上回ります.
参考にしたページ
物体認識モデルYOLOv3に完全勝利
Understanding Feature Pyramid Networks for object detection (FPN)
-
段階的にConvフィルタサイズを小さくするピラミッド構造のこと.大きさを変更することで,異なるスケールの物体の検出に対応する. ↩
-
1段のCNNでbounding boxの座標とクラスを推定する検出器.two-stage detectorに比較すると検出速度に優れ,検出精度に劣る傾向にある. ↩
-
Single-Shot Refinement Neural Network for Object Detection ↩
-
領域候補の抽出と,bounding boxとクラスの推定の2つのプロセスで物体認識を行う検出器.one-stage detectorに比べ,検出精度に優れ,検出速度に劣る傾向にある. ↩
-
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks ↩