Azure Batch AI
Deep Learningを中心とした大量の計算とデータ処理が必要とし、特にGPUを効率的に利用するための仕組みが求められるようになっています。Azureには現在Previewですが、Azure Batch AIというDeep Learningのツールキットに依存せず、バッチを登録することにより、学習タスクを実行してくれる仕組みが存在しています。
学習専用のManaged Serviceであり、並列に複数のGPUインスタンスがコントロール可能です。さらに使用しないときはインスタンスが自動的に停止する設定も可能で、停止している時はインスタンスに関する課金は発生しないことからクラウドの特性を生かしたサービスと言えるでしょう。
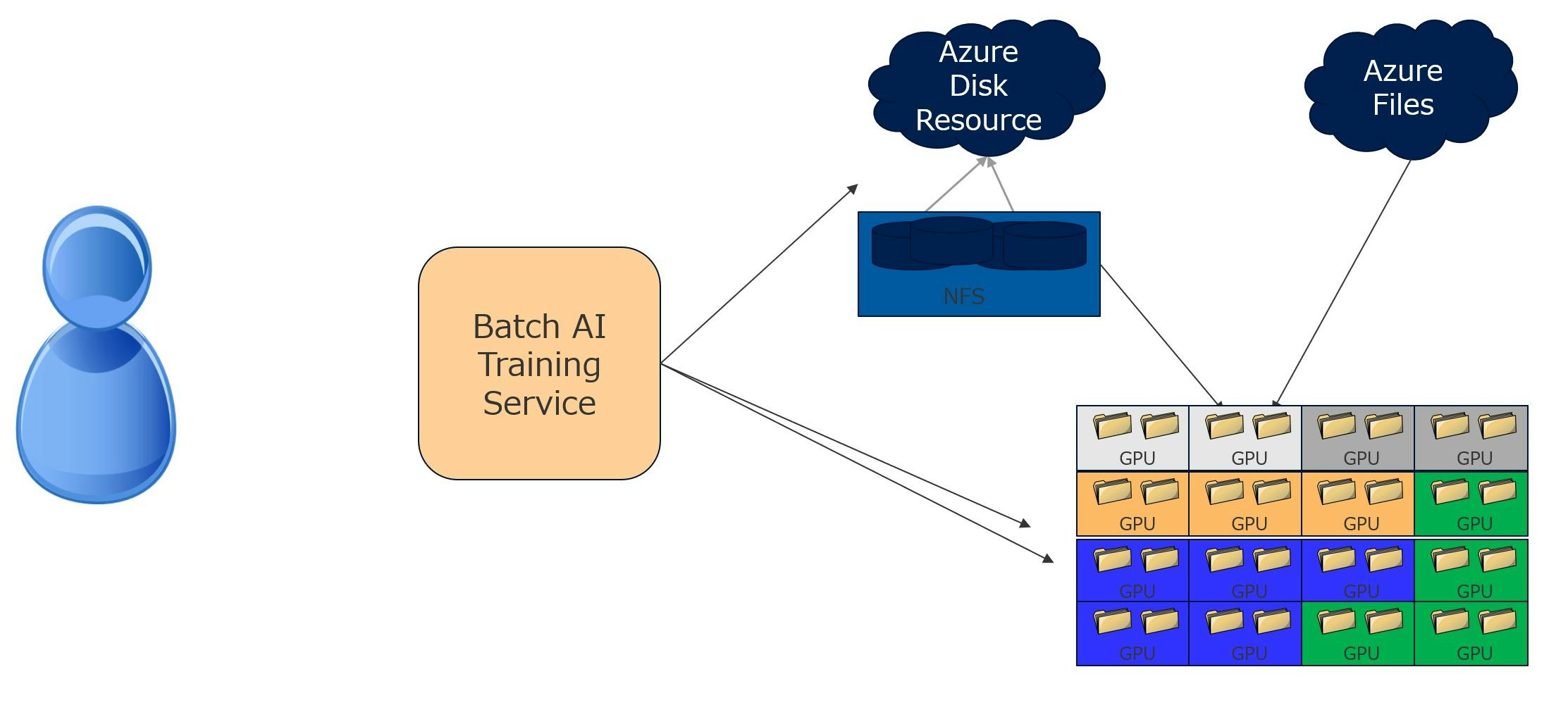
学習用のデータはファイル共有ポイントを作成しアップロードを行い、プログラムは同じく共有ポイント作成の後にアップロートします。あとはJSONで記述されるJOBを実行することにより学習を実行することが可能になります。
準備
ポータルから設定する方法や、Python、Azure CLIを使用する方法があります。手順が煩雑なので、Azure CLIで設定・実行するのが一番簡単ではないかと思います。
この記事では、Azure CLIを使用します。まずは端末側にAzure CLIを導入します。Azure CLIの導入についてはこちらの記事の後半を参照ください。
手順
JOBを実行できる環境の作成にはいくつかの手順が必要になります。順番に実行していきます。
Azureの設定
最初にプロバイダを登録します。Azure CLIでログインの後に下記を実行します。
az provider register -n Microsoft.BatchAI
az provider register -n Microsoft.Batch
登録には、15分程度かかることもあります。
リソースグループとリージョンをあらかじめ決めておきます
米国東部が現状GPUインスタンスの提供種類が多くディフォルトのリージョンとして選択しておきます。
az group create --name myRG --location eastus
az configure --defaults group=myRG
az configure --defaults location=eastus
ファイル共有の作成
次にデータやプログラムを保持するための共有を作成します。ストレージアカウントを作成して、その後共有を作成します。共有名はaibatchとしました。
az storage account create --name mysa –sku Standard_LRS
az storage share create –account-name mysa --name aibatch
次に実際のデータやプログラムをアップロードします。Kerasのサンプルのminist_cnn.pyをアップロードします。このサンプルはデータは自身でダウンロードしてくれるのでデータのアップロードは必要ないかと思います。
az storage directory create --account-name mysa --share-name aibatch --name mnistkeras
az storage file upload --account-name mysa --share-name aibatch --source mnist_cnn.py --path mnistkeras
クラスタ作成
クラスタ環境を作成します。ノード数の最大・最小の値を1にしていますが、最初に設定することができますし、あとで変更も可能です。最小値の部分が動き続けるので、使用しない場合でも下記だと1インスタンス分の課金が最低実施されます。--vm-sizeの部分で、インスタンスの種類をしています。一番安価なNC6を使用しています。
--imageの指定ですが、UbuntuDSVMには標準でkeras/tensorflow/chainer/cntkがインストールされているので、使用することが可能です。
az batchai cluster create --name mycluster --vm-size STANDARD_NC6 --image UbuntuDSVM --min 1 --max 1 --storage-account-name mysa --afs-name aibatch --afs-mount-path azurefileshare --user-name <<admin_name>> --password <<pass>>
最小値を0にすることにより、使用していない場合は自動停止されることもできます。
az batchai cluster auto-scale -n mycluster -g myRG --min 0 --max 2
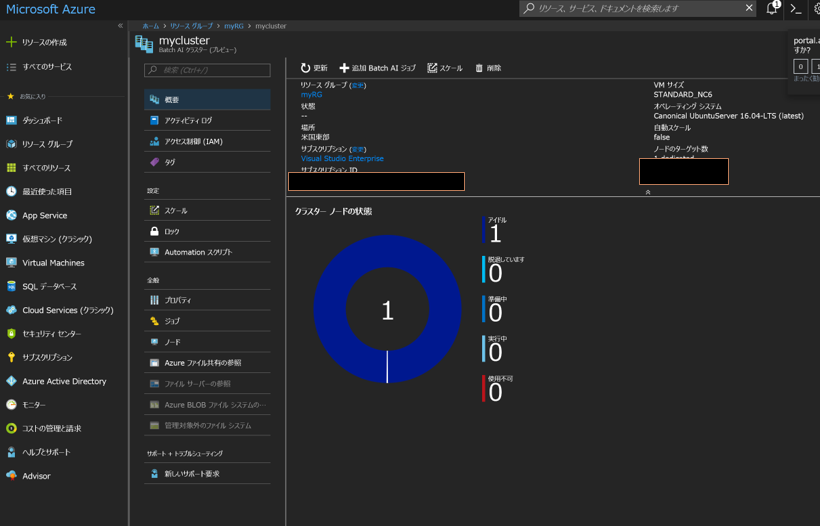
下記は作成後のクラスタの状態をポータルで表示しています
JOB作成
JOBはJSONで記述します
az batchai job create --name myjob --cluster-name mycluster --config job.json
job.jsonの中身ですが、下記となります。あまり情報がないのですが、設定できるパラメータはこちらのJSONファイルを参照するのが確実なようです
{
"$schema": "https://raw.githubusercontent.com/Azure/BatchAI/master/schemas/2017-09-01-preview/job.json",
"properties": {
"nodeCount": 1,
"customToolkitSettings": {
"commandLine": "KERAS_BACKEND=tensorflow python $AZ_BATCHAI_INPUT_SCRIPT/mnist_cnn.py"
},
"stdOutErrPathPrefix": "$AZ_BATCHAI_MOUNT_ROOT/azurefileshare",
"inputDirectories": [{
"id": "SCRIPT",
"path": "$AZ_BATCHAI_MOUNT_ROOT/azurefileshare/mnistkeras"
}]
}
}
実行
keras/tensorflowの実行例
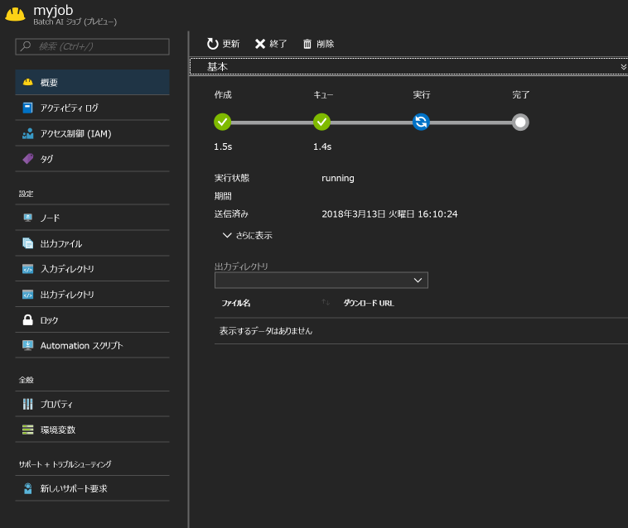
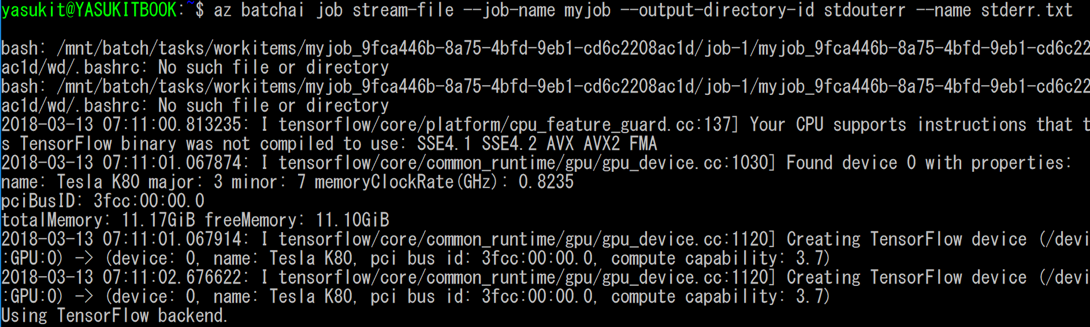
実行結果はポータルから確認できますが、Azure CLIからでも確認は可能です。
az batchai job stream-file --job-name myjob --output-directory-id stdouterr --name stderr.txt
keras/cntkの実行例
CNTKの場合はjob.jsonの記述、KERAS_BACKEND=tensorflowをKERAS_BACKEND=cntkに変更するだけです。同じサンプルを動かすと同じ動作になりますので、結果はtensorflowの場合と同じになります。MNISTだとあまり差がないですが、CNTKの方がおおむね高速に実行できます。