IBMのBluemixが、1ヶ月間のフリートライアル中とのことなので、早速体験してみることに。
今回は、WatsonのText to SpeachとRaspberry Pi 3を使ってプチIoTをしてみました。
ちなみに、この記事は、Bluemixアドベントカレンダーの12/23の記事となっています。
恥ずかしながら、投稿は初めてなので、温かい目で見ていただけると幸いです。
青汁飲みたい。
Text to Speechとは?
Watsonで提供されている機能の1つである音声認識APIのことです。
とあるテキストをリクエストとして投げると、音声として返ってきます。
どうやら日本語も喋れるみたいなので、どうせなら日本語で何か喋っていただきましょう。
利用にはここからBluemix専用アカウントの作成が必要です。
APIの利用準備
アカウントの作成が終わったらIBM Bluemixカタログのページで「Text to Speach」の項目を選択してください。
「作成」でサービスを作成します。
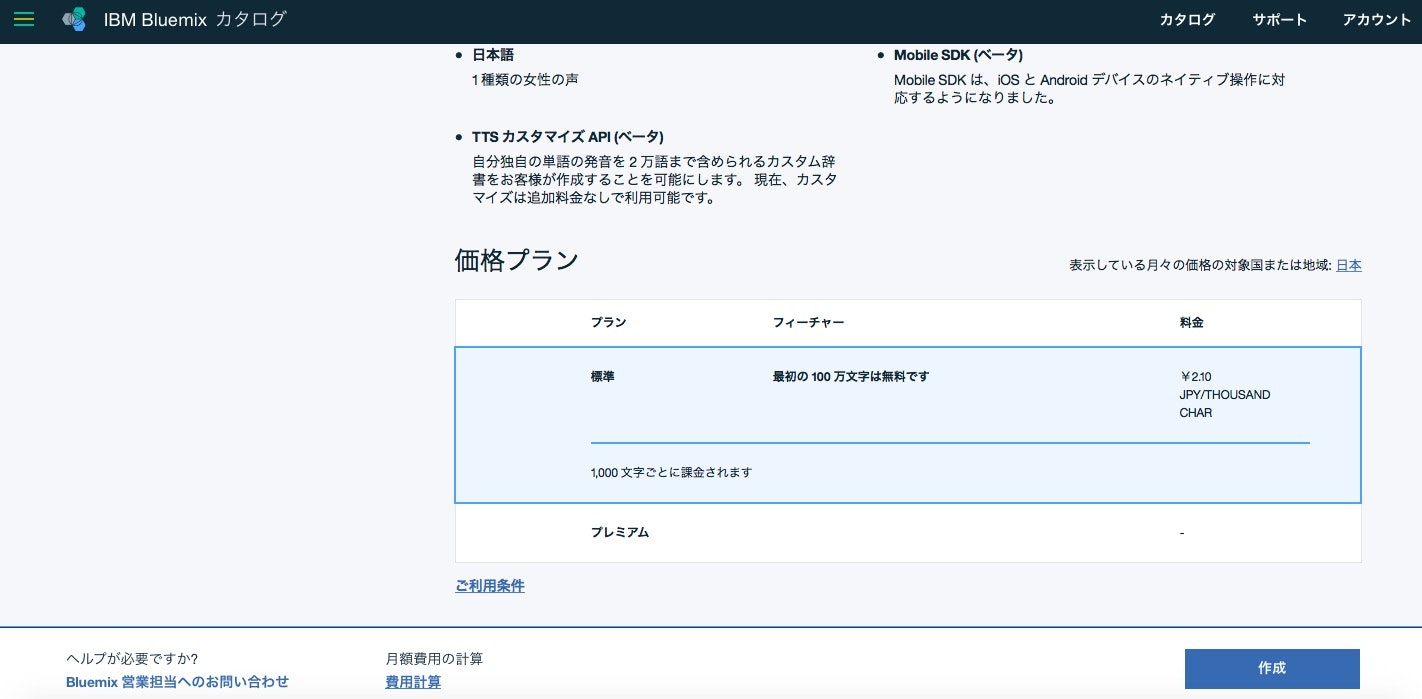
フィーチャーの欄を覗いてみると、英語やフランス語、その他諸々の言語が利用可能なようです。(もちろん日本語も)
あとは、サービスのダッシュボード画面から先程作成したサービスを選択し、「サービス資格情報」を確認します。
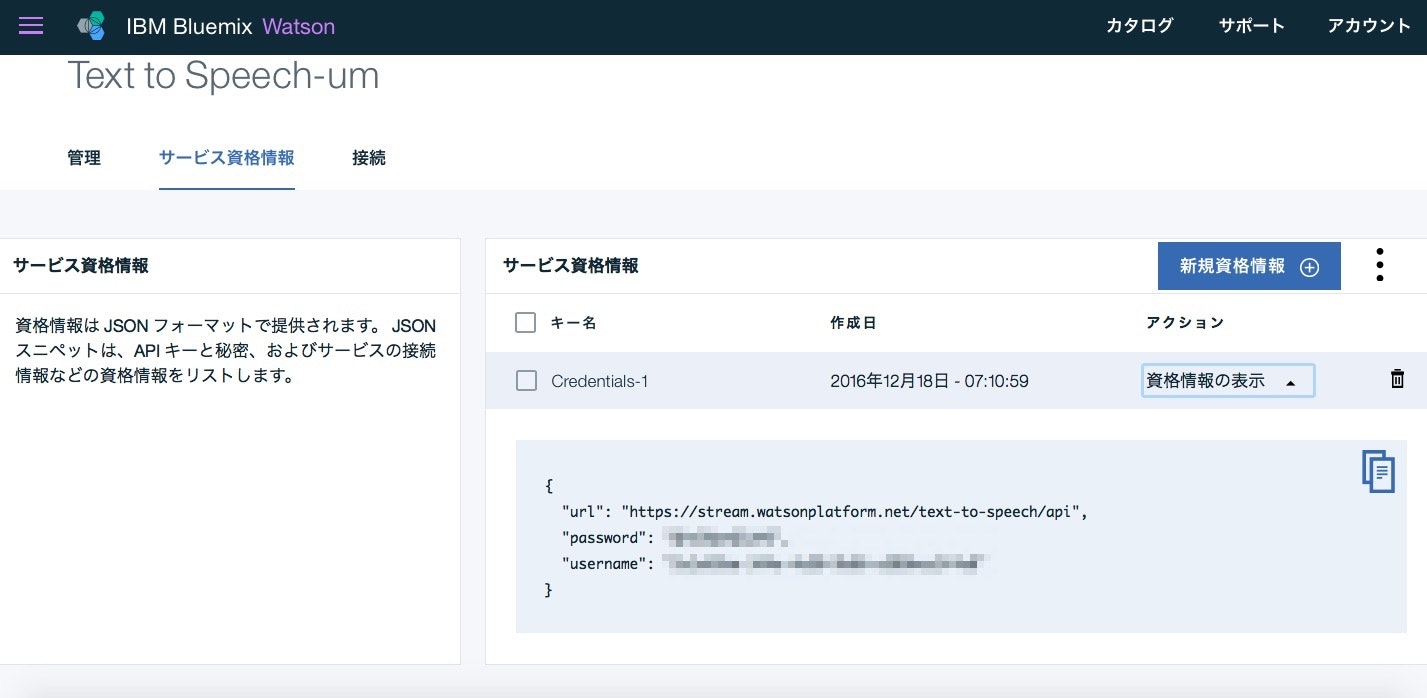
右下にあるJSON形式の情報(url、password、username)が、今回Text to Speech利用の際に用いる情報です。API利用における準備はこれでOKです。簡単。
Raspberry Pi 3の準備
今回はRaspberry Pi 3 Model Bを使用しており、NOOBSを使ってRASPBIAN JESSIEをインストールしました。デフォルトでRuby2.1.5が入っているので(少し古いですが)こちらを使ってAPIにリクエストを投げます。
OSインストール方法の話は、長くなるのでこの辺で割愛します。
Raspberry Piの音声出力は、デフォルトだとHDMIに設定されていますが、今回はスピーカーを使いたいので、アナログ出力に設定します。
#アナログに設定
$ amixer cset numid=3 1
#音声テスト
$ speaker-test -t sine -f 1000
#音量の変更
$ alsamixer
curlでリクエスト送信
一通りの準備が揃ったので、早速curlを使ってリクエストを投げてみます。
Watson Developer CloudのText to SpeechのAPIリファレンスを見てみると、curlを使用したリクエスト送信方法が記述されていました。
curl -u "{username}":"{password}"
"https://stream.watsonplatform.net/text-to-speech/api/v1/{method}"
サービス資格情報で取得したパスワードとユーザ名を使って認証を行ってあとはメソッドを追加すればよさそうです。
読み進めていくと、voiceメソッドを使えばテキストとして使用可能な言語に関する情報がJSON形式で得られるみたい。
その中にいました!Emiちゃん!
{
"name": "ja-JP_EmiVoice",
"language": "ja-JP",
"customizable": true,
"gender": "female",
"url": "https://stream-s.watsonplatform.net/text-to-speech/api/v1/voices/ja-JP_EmiVoice",
"supported_features": {
"voice_transformation": false,
"custom_pronunciation": true
},
"description": "Emi: Japanese (日本語) female voice."
},
更にリファレンスを眺めていくと、synthesisメソッドを使えば音声ファイルの形式を指定できるみたいです。(下記はGETの場合)
curl -X GET -u "{username}":"{password}"
--output hello_world.wav
"https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?accept=audio/wav&text=Hello%20world.&voice=en-US_AllisonVoice"
Raspberry Pi はデフォルトでwavファイルの読込みができるので、こちらを採用して、今回はwavファイルを生成します。
ちなみにこのリファレンスでは、curl以外(nodeやjava)で実行する方法もまとめられています。
あとは、日本語のURLに注意しつつ、音声ファイルの生成から実行までをRubyで実装しました。
require 'uri'
my_data = "{username}:{password}"
url = URI.escape("https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?&accept=audio/wav&voice=ja-JP_EmiVoice&text=おはようございます、マスター。2016年12月23日のご予定は、16時に会議室でミーティングです。")
`curl -u "#{my_data}" -o "test.wav" "#{url}"`
`aplay ./test.wav`
結構スムーズに喋ってくれます。ありがとうEmiちゃん。
メモ入力用のwebアプリ作成
タイトル通り、今日の予定を伝えてほしいので、メモ入力用のwebアプリ作成します。
ここらへんはこんな感じでささっとSinatraで作っちゃいます。
かつてこんなにも悲しいUIがあったでしょうか。いや、無い。(反語)
最終形態
あとはRaspberry Pi側のソースコードを少しだけいじってあげれば完成です。
全体フローは
- メモを書く
- DBに登録
- Raspberry Piが日時にあったメモを取ってくる
- 喋る
といった感じです。
最終的なRaspberry Pi側のソースコードがこちらになります。
require 'date'
require 'uri'
today = Date.today.to_s
today[4]="年"
today[7]="月"
today[10]="日"
todays_plan = `curl -F "today=#{today}" http://・・・/todays_plan`
my_data = "username:password"
url = URI.escape("https://stream.watsonplatform.net/text-to-speech/api/v1/synthesize?accept=audio/wav&voice=ja-JP_EmiVoice&text=おはようございます、マスター。#{today}のご予定は、#{todays_plan}")
`curl -u "#{my_data}" -o "plan.wav" "#{url}"`
`aplay ./plan.wav`
これで、予定のある日も無い日も楽しく過ごせるようになりました。
まとめ
Webアプリの実装含めても1~2時間程度でできちゃいます。
音声認識は過去にもやったことはありますが、色んなものをインストールしたりビルドしたりがめんどくさかったりするので、今回のようにある程度API任せにすると、ストレスレスな開発ができてありがたいです。
初めての投稿がアドベントカレンダーという謎のシチュエーションでしたが、なんとか間に合ってよかったです。
Niceいただけたら嬉しいです。
メリークリスマスイブイブ。