はじめに
文系大学1回生です。
4月から京都のベンチャー企業でプログラミングを勉強していますが、一応社会学部です。
社会学部の統計なんちゃらという講義で、初めて課題が出されました。
課題の内容は後で詳しく説明しますが、プログラミング使えそうやなと思ったので実践してみました。
ずっと勉強しているのは、自社サービスの開発で使うWebフレームワーク(Django)なので、今回初めてpythonでexcelをいじりました。
もっと効率の良い方法があるかもしれないのであったらご教授よろしくお願いします。
課題1
40〜44歳の男女それぞれの未婚率について、大正9年(1920)〜平成27年(2015)の推移がわかるグラフを作成する。
e-statの平成27年国勢調査、表番号018のエクセルデータをダウンロード。
デスクトップに、課題1.xlsxという名前で保存。
シート名は統計とした。
無駄なデータが多すぎて萎える。
欲しいデータは一定間隔で並んでいるので、for文で回すと良さそうである。
#階層はデスクトップ
>>> import openpyxl
>>> workbook = openpyxl.load_workbook('課題1.xlsx') #エクセルデータを読み込む
>>> sheet = workbook['統計'] #シートを読み込む
>>> men =[] #男性のデータを格納する配列
>>> for i in range(18,350,18): #欲しいデータが18行目から350行目まで、18行の間隔で存在する
... cell_value = sheet.cell(row=i, column=22).value #22列目の未婚男性のデータを取ってくる
... men.append(cell_value) #男性の配列に格納
...
>>> print(men) #中身を見てみる
[2.8226725860750834, 2.2618185668971766, 2.433152007128241, 2.42505913295056, 2.7279871407456153, 1.8786074373027002, 1.731654081105934, 2.029317309052426, 2.435816149820673, 2.8217178027485557, 3.663055264061388, 4.745904414424089, 7.441149878901069, 11.782847819794217, 16.516216642700453, 18.68972716464149, 22.69954351969778, 28.608082521321627, 29.96467924]
>>> women = [] #女性のデータを格納する配列
>>> for i in range(18,350,18): #欲しいデータが18行目から350行目まで、18行の間隔で存在する
... cell_value = sheet.cell(row=i, column=26).value #26列目の未婚男性のデータを取ってくる
... women.append(cell_value) #女性の配列に格納
...
>>> print(women) #中身を見てみる
[2.1451690354285287, 1.8915320483167568, 1.799512556426348, 1.792620045117628, 2.004885801326332, 1.9950856330606017, 2.336005200045303, 3.141619233709965, 4.672354781027056, 5.298430348786773, 4.994852742564659, 4.449672719207714, 4.898620144204961, 5.77997354997166, 6.7614273057305425, 8.644673775990801, 12.241047899785631, 17.36816701422245, 19.30004096]
>>> new_sheet = workbook.create_sheet("集計") #集計という名のシートを作る
>>> new_sheet["A1"] = "男" #A1のセルを男にする
>>> new_sheet["B1"] = "女" #B1のセルを女にする
>>> for i, j, k in zip(list(range(3,50)), men, women): #数字、男子の配列、女性の配列を同時に回す
... new_sheet.cell(row=i, column=1, value= j) #1列目に男性の配列を出力
... new_sheet.cell(row=i, column=2, value= k) #2列目に女性の配列を出力
>>> workbook.save("課題1回答.xlsx") #課題1回答という名のエクセルデータをデスクトップに保存
課題1回答の中身を少しいじってexcelでグラフを作りやすい配置にする。
pythonでグラフも作れるようだが、これは手作業の方が早いと判断。
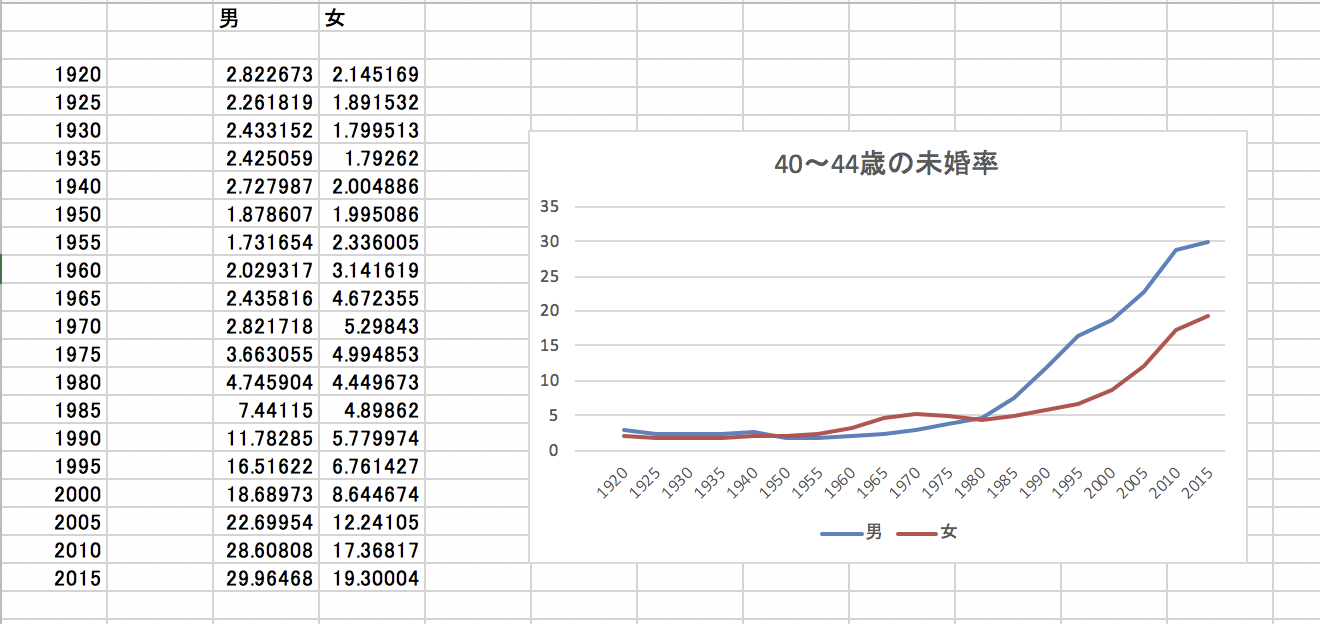
excel標準の機能も優れているのでpythonじゃなくてもグラフはほぼ自動である。
課題2
40〜44歳の男女それぞれについて、「就業者」「完全失業者」「非労働力人口」ごとに、「未婚」「有配偶」「離別」「死別」「不詳」の内訳がわかる表を作成する。
今回はcsvファイルをダウンロードしたが、excelで表示できるので問題ない。

今回はこのように、必要な情報にマークをつけた。
行数に規則性がない(あるかもしれないがめんどくさかった)ので、男女それぞれに欲しい行数を配列に入れておき、使い回しできるようにした。
>>> import openpyxl
>>> workbook = openpyxl.load_workbook('課題2.xlsx')
>>> sheet = workbook["内訳"]
>>> workmen_sum = 4152566 #分母を代入
>>> menbox = [87,141,195,249,303] #男性の分子となる行数を配列に格納
>>> for i in menbox:
... numerator = sheet.cell(row=i, column=14).value #分子を順番に
... print((numerator/workmen_sum)*100)
...
25.534500836350343 # 未婚
69.10223702645546 # 有配偶
0.19855193150452033 # 離別
4.220884147295913 # 死別
0.9438260583937739 # 不詳
今回は面倒だったのでファイルに書き込むのではなく出力した。
これは、男性就業者のデータである。
>>> workwomen_sum = 3273263
>>> womenbox = [105,159,213,267,321]
>>> for i in womenbox:
... numerator = sheet.cell(row=i, column=14).value
... print((numerator/workwomen_sum)*100)
...
20.936050662595704 # 未婚
67.68551747904155 # 有配偶
0.6554010478229216 # 離別
10.156379123828424 # 死別
0.5666516867113948 # 不詳
男性、女性両方対応できるようになった。
これは、女性就業者のデータである。
>>> unworkedmen_sum = 182097
>>> for i in menbox:
... numerator = sheet.cell(row=i, column=24).value
... print((numerator/unworkedmen_sum)*100)
...
73.44547136965464
17.9788793884578
0.22240893589680227
6.96002679890388
1.3932135070868823
これは、男性完全失業者のデータである。
あとは配列を使い回して列を変えるだけである。
まとめ
文系でもプログラミングは学ぶべきである。