はじめに
InfoScale は、AWS上のRHELでの動作を保証しており、主なメリットとして以下2点が挙げられます。事実、オンプレミスの世界では、下記のメリットを享受する為に多くの企業がInfoScaleを導入しています。
1.独自のストレージ管理機能により、ストレージ(AWSの場合はEBS)メンテナンス時のダウンタイムや作業工数を削減
2.独自のクラスタリング機能により、アプリケーションやOSレベルの障害をカバーできる可用性の向上
しかし「クラウド上のI/Oパフォーマンス管理はオンプレと違って難しいのに、AWS上にInfoScaleを導入する事によって、さらに複雑になるのでは?」という懸念が根強いのが実情です。本記事では、そのような不安を払しょくするために、InfoScale7.4.2 RHEL版を AWS上に構築した代表的な構成におけるI/Oパフォーマンステスト結果を公開します。また、ストレージ管理やクラスタリングを行う為にInfoScaleを導入する事の妥当性を構成毎に考察します。I/Oパフォーマンスを向上させるための簡単なチューニングについても説明します。
パフォーマンステストを実施した5つの構成
構成1 シングルノード構成
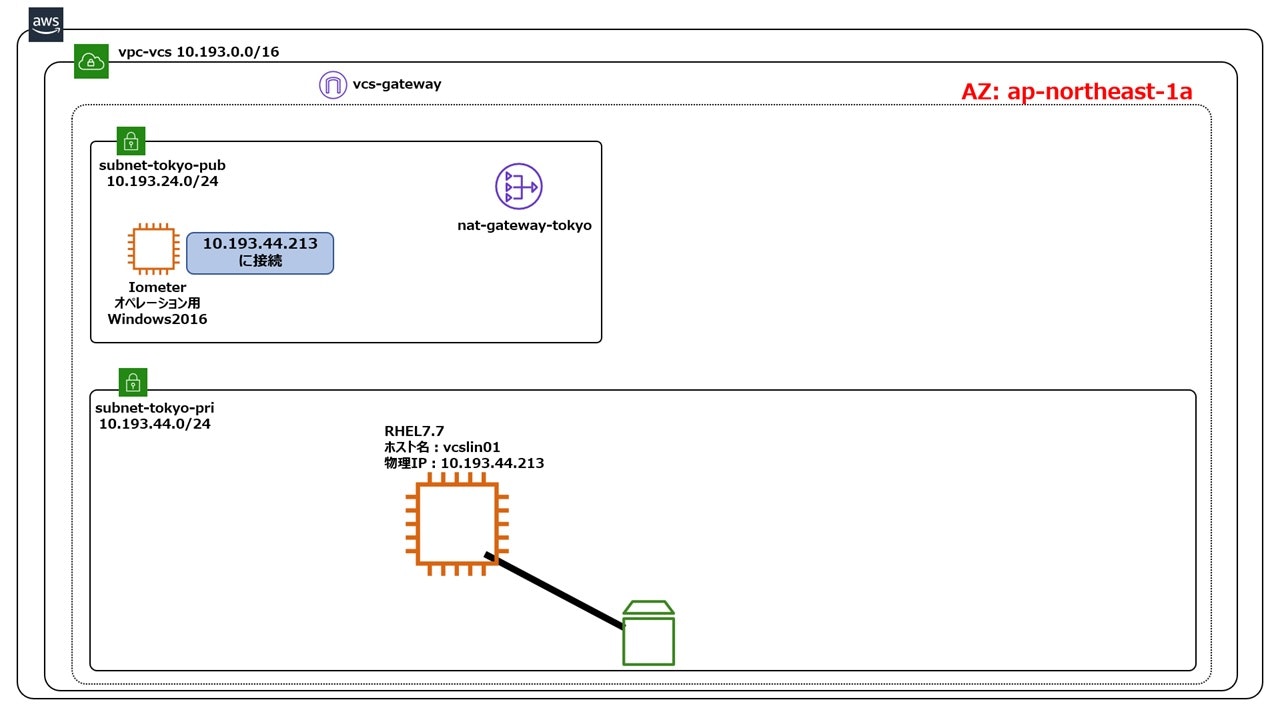
本書における基準となるべき構成です。AWS上の非クラスター構成のインスタンスにInfoScaleを導入してブロックストレージを管理対象にすると、ブロックストレージの拡張・追加時のファイルシステムの拡張がサービス停止を伴わず、もしくはより短いサービス停止時間で行える等のメリットがあります(詳しくは、こちらとこちらをご参照ください)。AWS上の非クラスター構成のインスタンスにInfoScaleを導入した場合に実現できるI/O性能の基準としてご活用ください。また、この構成で得られたI/Oパフォーマンスに対して、他の4つの構成がどれだけ劣るかを比べる事で、クラスター構成毎のI/Oパフォーマンスに関する留意点が明らかになります。
構成2 共有ディスク型クラスター構成
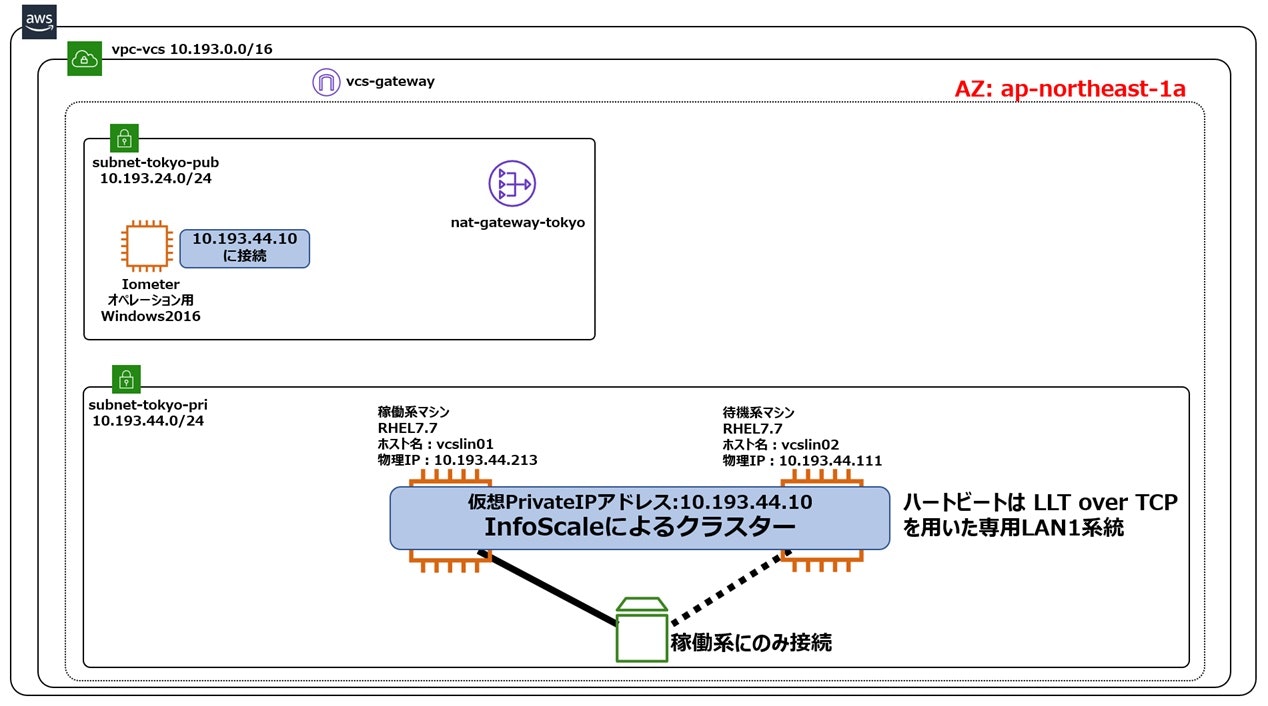
構成1に対してどれだけI/O性能が劣化するかを考察する事で、クラスター化に伴うオーバーヘッドの度合いを把握する事ができます。構成1と構成2では、1つのインスタンスが1つのEBSに専用アクセスする事は変わりませんので、理論上はクラスター化のオーバーヘッドのみが顕著化します。尚、上記構成の構築方法については、こちらをご参照ください。
構成3 FSSを用いたAZ内クラスター構成(ハートビートはTCP1系統)
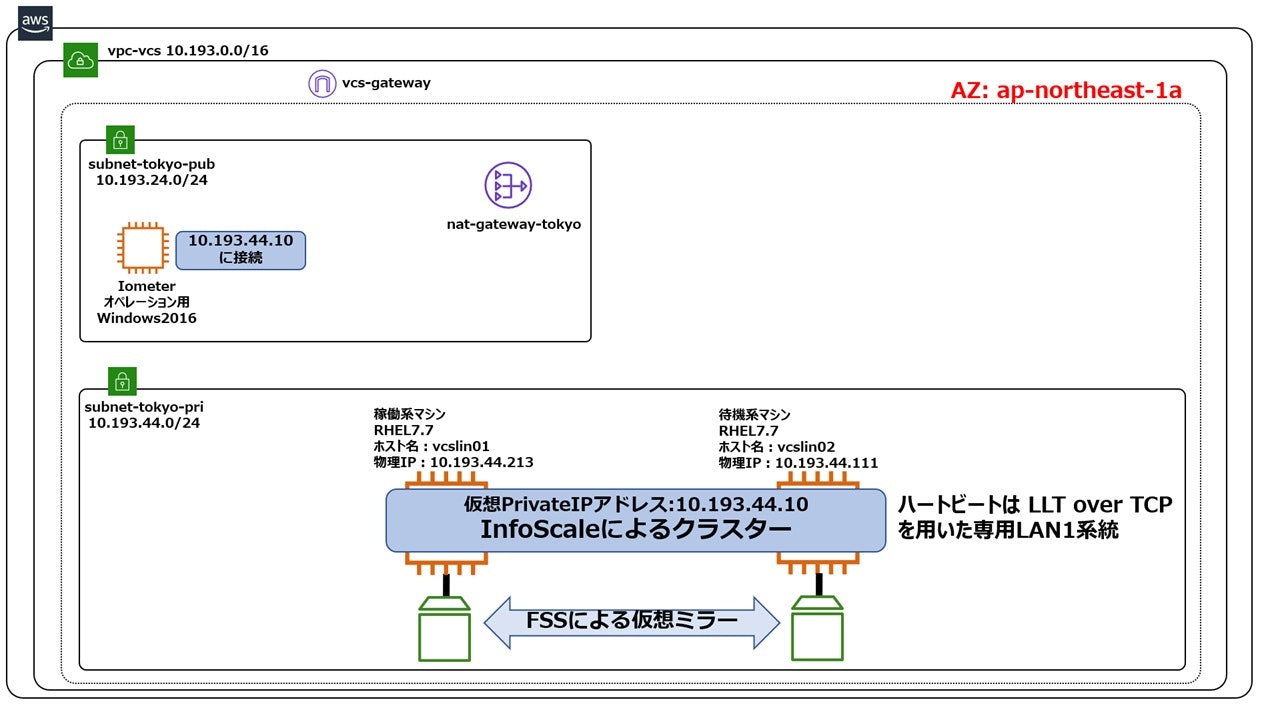
構成2に対してどれだけI/O性能が劣化するかを考察する事で、FSSによる仮想ミラーに伴うオーバーヘッドの度合いを把握する事ができます。構成2と構成3の相違点は仮想ミラーを行っているかどうかのみですので、理論上は仮想ミラーのオーバーヘッドのみが顕著化します。尚、上記構成の構築方法については、こちらをご参照ください。
構成4 FSSを用いたAZ内クラスター構成(ハートビートはUDP2系統)
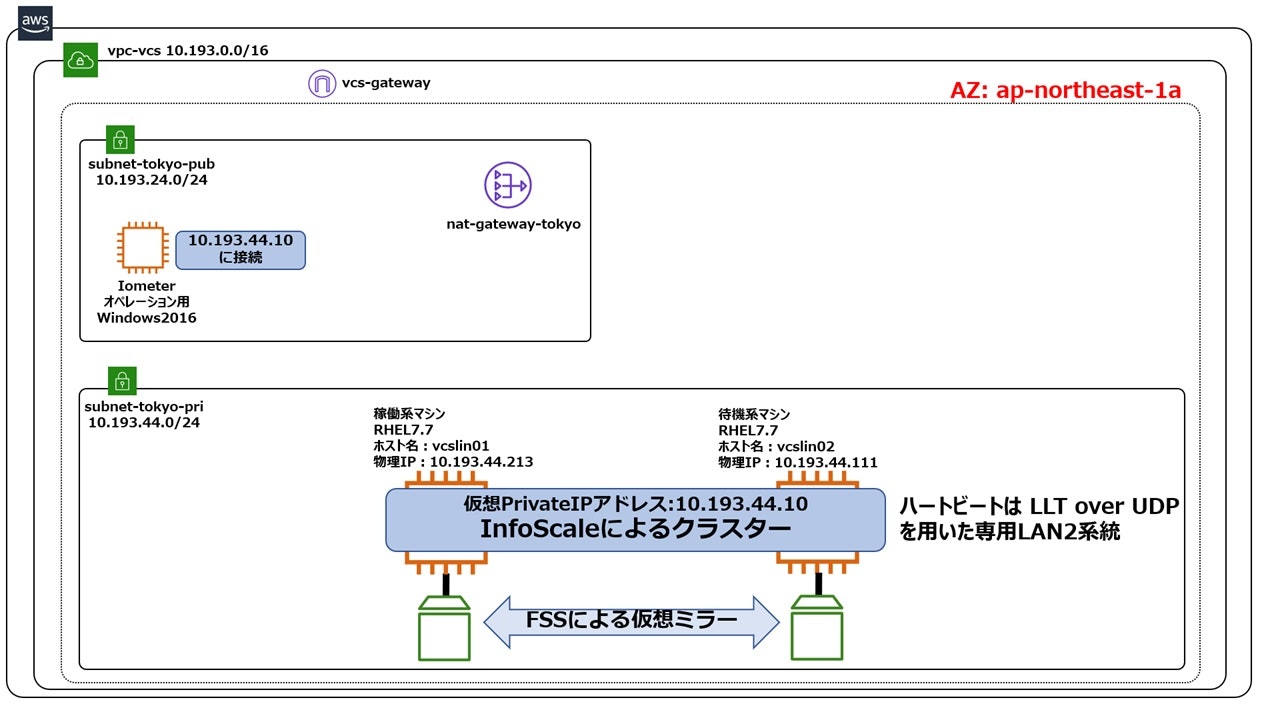
構成3とI/O性能を比較する事で、FSSによる仮想ミラーを実現するハートビートLANの構成がI/O性能に与える影響を把握する事ができます。構成3と構成4の相違点はハートビートLANがTCP/IPを1系統持っているか、UDP/IPを2系統持っているかです。AWSのNICの性能を上回るようなI/O負荷をかけた場合は、2系統で負荷分散できる構成4が勝り、そうでない場合はオーバーヘッドの小さい構成3が勝る事が予想できます。尚、上記構成の構築方法については、こちらをご参照ください。
構成5 FSSを用いたAZ跨ぎクラスター構成(ハートビートはUDP2系統)
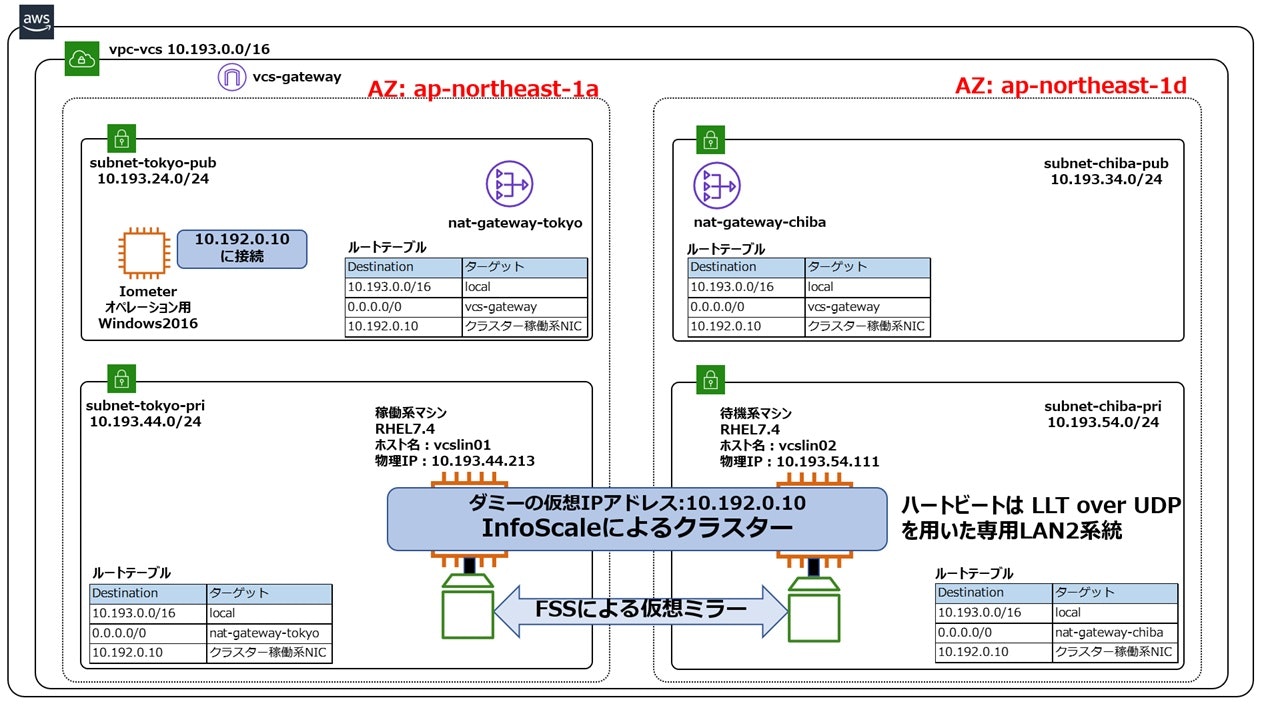
構成4とI/O性能を比較する事で、AZを跨ぐことによるネットワーク遅延がI/O性能に与える影響を把握する事ができます。構成4と構成5の相違点はAZを跨ぐか跨がないかのみです。FSSによる仮想ミラーの性能、特にIOPSは使用するハートビートネットワークのLatencyに依存しますので、構成4が勝る事が予想できます。尚、上記構成の構築方法については、こちらをご参照ください。
使用するEBSの種類
本書では、検証に使用するEBSは「gp2」を使用します。gp2には「バーストバケット」という機能があり、バーストチケットに余裕があれば一定のIOPSを保証します。一般にEBSのIOPSは容量に比例する為、容量の小さなEBSを使用する場合は十分なIOPSが得られない事がありますが、gp2を使用する事でこのデメリットを回避する事ができます。ただし、バーストチケットを使い切らないよう注意が必要です。gp2やバーストバケットに関しては、AWSの情報を参照してください。
マシン環境
本検証の環境情報は以下の通りです
OS:RHEL7.7
InfoScale 7.4.2
インスタンスタイプ:t2.large(2Core, 8Gbyteメモリ)
EBS:gp2 の Standard SSD 5Gbyte
5つの構成のパフォーマンステスト結果の比較
各構成の比較においては、下記9種類のいずれでも概ね同じ傾向となりました。本書では、最も代表的な「I/Oサイズ4Kbyte、Read/Write比率5対5、ランダムアクセス」についての結果を紹介し、考察を述べます。
・I/Oサイズ4Kbyte Read/Write比率10対0、ランダムアクセス
・I/Oサイズ4Kbyte Read/Write比率5対5、ランダムアクセス
・I/Oサイズ4Kbyte Read/Write比率0対10、ランダムアクセス
・I/Oサイズ4Kbyte Read/Write比率10対0、シーケンシャル
・I/Oサイズ4Kbyte Read/Write比率5対5、シーケンシャル
・I/Oサイズ4Kbyte Read/Write比率0対10、シーケンシャル
・I/Oサイズ64Kbyte Read/Write比率10対0、シーケンシャル
・I/Oサイズ64Kbyte Read/Write比率5対5、シーケンシャル
・I/Oサイズ64Kbyte Read/Write比率0対10、シーケンシャル
IOPS
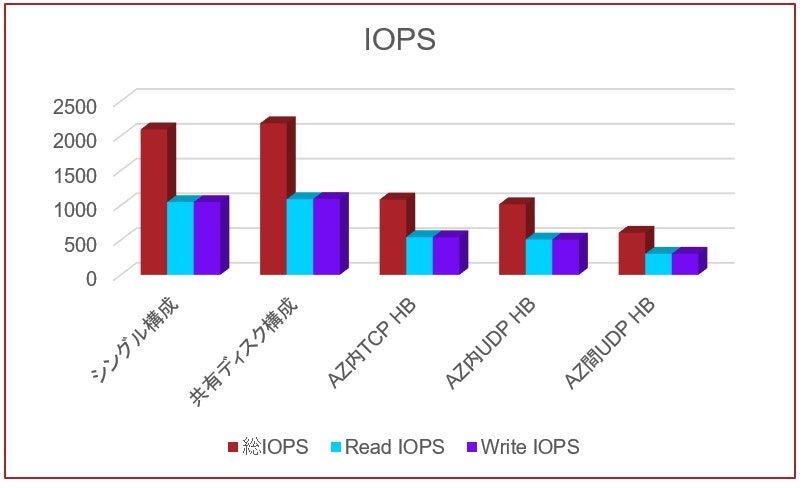
IOPSに関しては想定通り、シングル構成と共有ディスククラスター構成がほぼ同じ結果となりました。共有ディスククラスター構成がわずかに上回ったのは誤差と思われます。この2つとも2000IOPS程度の性能を発揮しました。バーストバケットが保証するIOPSが3000であった事と、IOMETERが掛けられる負荷を考えると、想定通りの結果と言えます。AZ内でFSSによる仮想ミラーを行った2つの構成は、先の2つの構成に比べて半分程度のIOPSです。これは、仮想ミラーによるオーバーヘッドと考えられます。最後に、AZを跨いでFSSによる仮想ミラーを行った構成では、AZ跨ぎに起因するハートビート遅延により、さらに性能劣化が見られました。
スループット
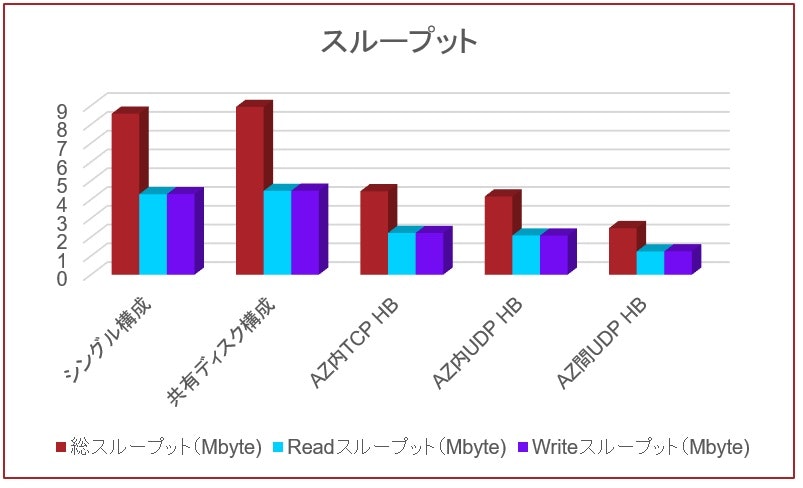
スループットに関しては、IOPSと全く同じ比較結果となりました。これは、スループットはIOPSにI/Oサイズを乗算したものだからです。具体的なスループット値も、例えばシングルノード構成に着目した場合、前ページのIOPSが2000だったので、それにI/Oサイズである4Kbyteを乗算すると8Mbyteになり、上記のグラフと一致します。
CPU使用率
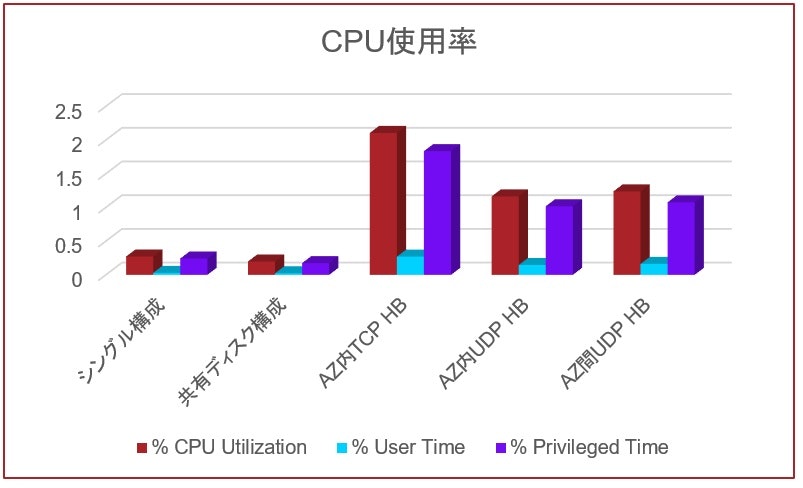
CPU使用率に関しては、IOPSやスループットとは全く異なる比較結果となりましたが、これも想定通りです。I/Oに関連して特別な処理を一切行わないシングルノード構成と共有ディスク構成は、非常に低い結果となりました。一方、FSSによる仮想ミラーを行う残りの3つの構成は、最大で2%程度のオーバーヘッドが発生しています。グラフでは突出しているように見えますが、システム全体から見れば2%は無視しても良い値です。尚、仮想ミラーの同期処理を行う為のネットワーク通信において様々なチェックを行っている分、TCP/IPを用いた構成は若干CPU使用率が高くなっています。
考察
シングルノード構成
WS上のシングルノード(非クラスター構成)のRHELインスタンス上に、ストレージの管理性向上を理由にInfoScaleを導入する場合、InfoScaleの導入によるCPUオーバーヘッドは誤差の範囲であり、I/O性能もネイティブ環境と大差ないと言えます。
共有ディスク型のクラスター構成(AZ内でのクラスター)
nfoScaleを用いた共有ディスク型のクラスター構成のI/O性能やCPUオーバーヘッドは、非クラスター構成と大差ない値でした。従って、AZ内でのクラスター構成を検討する際は、パフォーマンスの観点では共有ディスク型のクラスターを選択される事をお勧めします。
AZを跨ぐクラスター構成
FSSによる仮想ミラーを用いた3つのパターンのいずれも、シングルノードや共有ディスク型と比べてI/O性能やCPUオーバーヘッドで劣る結果となりました。従って、仮想ミラーを行う必然性が無い場合(AZ内でのクラスター)は、パフォーマンスの観点では仮想ミラー型クラスターはお勧めできません。しかし、AZを跨いでのクラスターでは共有ディスク構成が使用できない為、仮想ミラーが有力な選択肢の1つになります。仮想ミラーの他にレプリケーションを使用する事も可能ですが、話を分かりやすくするため、あえて本書ではレプリケーションには言及しません。
つまり、AZを跨いでのクラスターを想定し、仮想ミラーを用いたクラスターのI/O性能を向上させるチューニングが必要という事です。チューニングについては、次の章で詳しく説明します。
仮想ミラーのパフォーマンスを向上させるチューニング
仮想ミラー型クラスターのI/Oパフォーマンスを向上させるには、ハートビートのチューニングが効果的です。なぜなら、仮想ミラー型のクラスターは、個々のクラスターノードのローカルディスクの同期をハートビート経由で行うからです。ハートビートのチューニングは、以下の3つの方法があります。
1.MTUサイズ拡張
2.RHELの通信バッファサイズ拡張
3.InfoScaleのハートビートドライバーであるLLTのフロー制御閾値の拡張
それぞれ向き不向きがありますので、個別に説明します。
MTUサイズ拡張によるパフォーマンス向上
ローカルディスクの同期をハートビート経由で行う際、MTUサイズが大きければデータ転送の単位が大きくなるので、転送効率が良くなります。ただし、データの書き込みサイズが小さい場合は、逆に転送効率が悪くなるので注意が必要です。以下のようなケースでチューニングが有効です。
1.バッチ系の処理
2.シーケンシャルアクセス
3.書込みが多い
例えば、NICのMTUが1500バイトで、ファイルシステムのブロックサイズが8Kである場合、MTUサイズを8Kより大きくする事で、パフォーマンス向上が期待できます。
以下は、AZ内でTCP/IPをハートビートに用いたクラスターにおいて、I/Oサイズ4Kbyte、Read/Write比率5対5、シーケンシャルアクセスでのパフォーマンス比較です。比較したのは、以下4パターンです。
1.チューニング無し
2.MTUサイズを1500バイトから9000バイトに拡張
3.RHELの通信バッファサイズをデフォルトの4倍に拡張
4.LLTフロー制御の閾値をデフォルトの2倍に拡張
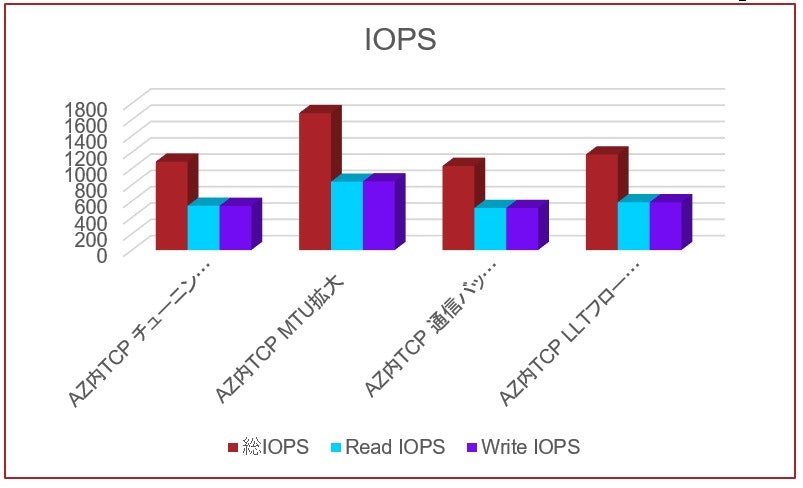
このパターンでは、4Kbyteのデータが連続的にハートビートに流れるので、MTUサイズの拡張が最も効果が高い結果となりました。
RHELの通信バッファサイズ拡張によるパフォーマンス向上
ローカルディスクの同期をハートビート経由で行う際、RHELの通信バッファサイズが大きければデータ転送の効率が向上するパフォーマンスが良くなります。ただし、バッファサイズが使用できるメモリ量を上回らないようにする必要があります。以下のようなケースでチューニングが有効です。
1.バッチ系の処理
2.クラスターのハートビートにUDPを選択している
3.書込みが多く且つI/Oブロックサイズが大きい
RHELの通信バッファとチューニング方法についての詳細は、Red Hat社のドキュメントを参照してください。
以下は、AZ内でUDP/IPをハートビートに用いたクラスターにおいて、I/Oサイズ64Kbyte、Read/Write比率5対5、シーケンシャルアクセスでのパフォーマンス比較です。比較したのは、以下4パターンです。
1.チューニング無し
2.MTUサイズを1500バイトから9000バイトに拡張
3.RHELの通信バッファサイズをデフォルトの4倍に拡張
4.LLTフロー制御の閾値をデフォルトの2倍に拡張
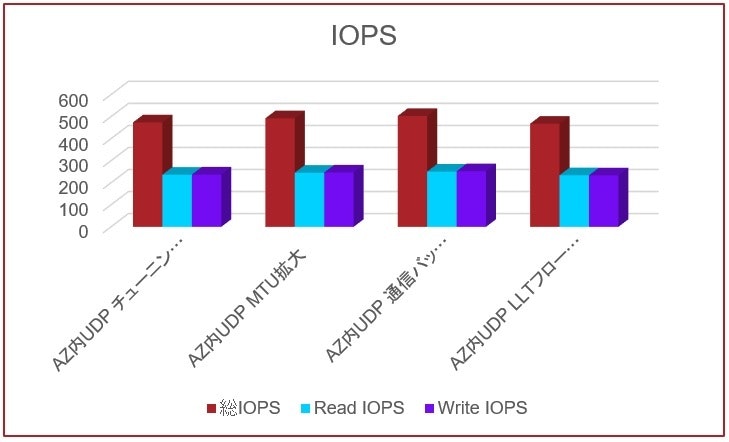
このパターンでは、どのチューニングもあまり差はありませんが、通信バッファサイズの拡張が他よりも若干効果が高い結果となりました。
LLTフロー制御閾値の拡張によるパフォーマンス向上
InfoScaleのハートビートは、LLTという独自のプロトコルで行われています。LLTは送信キューに大量のデータが溜まる事を防止するためにフロー制御を行っています。フロー制御には閾値があり、キューに溜まったデータの量がハイウォーター値を超えると、溜まったデータの量がローウォーター値を下回るまで、キューの受付を停止します。従って、バースト的にデータ転送が発生する場合は、フロー制御によってデータ転送効率が低下します。逆に言うと、フロー制御閾値(ハイウォーター値)を拡張する事で、データ転送の効率が向上しパフォーマンスが良くなります。ただし、キューのサイズが使用できるメモリ量を上回らないようにする必要があります。以下のようなケースでチューニングが有効です。
1.AZ跨ぎなど、ネットワークのLatencyが大きい
2.書込みが多い
LLTフロー制御閾値とチューニング方法についての詳細は、InfoScaleのマニュアルの1155ぺージを参照してください。
以下は、AZを跨いだUDP/IPをハートビートに用いたクラスターにおいて、I/Oサイズ4Kbyte、Read/Write比率5対5、シーケンシャルアクセスでのパフォーマンス比較です。比較したのは、以下4パターンです。
1.チューニング無し
2.MTUサイズを1500バイトから9000バイトに拡張
3.RHELの通信バッファサイズをデフォルトの4倍に拡張
4.LLTフロー制御の閾値をデフォルトの2倍に拡張
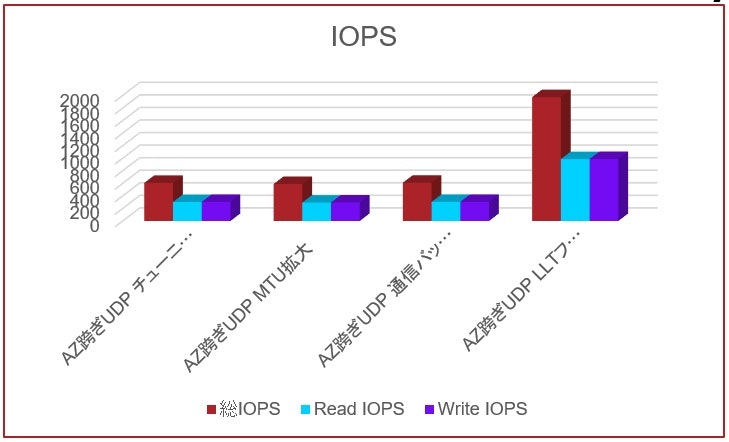
このパターンでは、ハートビートのLatencyが大きいためフロー制御が頻発します。それを抑制するためのチューニングが最も効果が高い結果となりました。AZを跨ぐクラスターでFSSによる仮想ミラーを使用しパフォーマンスを向上させたい場合は、このチューニングを行う事をお勧めします。
尚、ここで説明したチューニング方法の詳細を含むパフォーマンステスト全般に関するホワイトペーパーがベリタスより公開されています。是非こちらをご参照ください!
おわりに
如何でしたでしょうか? 今回の記事と記事中に紹介したホワイトペーパーによって、AWS上のRHELにInfoScaleを導入する際の懸念点が減ったのではないでしょうか? 今後も、AWS上のInfoScaleにご期待ください!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。