はじめに
InfoScale は、AWS上のRHELでのクラスタリングを保証しています。ただし、顧客要件によって実装パターンが複数存在します。そして、InfoScaleをAWS上のRHELに構築する場合は、以下2つのポイントに留意する必要があります。
1.どのような要件を満たすために、どのような構成のクラスターを構築するか
2.オンプレとは異なるInfoScaleの前提条件
本記事では、上記2つのポイントを中心に、AWS上でクラスタリングが必要になった場合に、要件毎の最適なソリューションと、実装パターン毎の注意点を説明します。
どのような要件を満たすために、どのような構成のクラスターを構築するか
同一AZ内で、共有ディスクを用いたクラスター
もっとも単純なクラスター構成です。クラスタリングされたオンプレのシステムを、そのままAWSに移行する際に用います。同一AZ内ですので、共有ディスク構成をとることができますし、AWSのPrivateIPをクラスターのノード間で切り替える事も可能です。Active-Standby型のクラスターで、切り替え時間が3分以上かかっても大丈夫な要件に向きます。
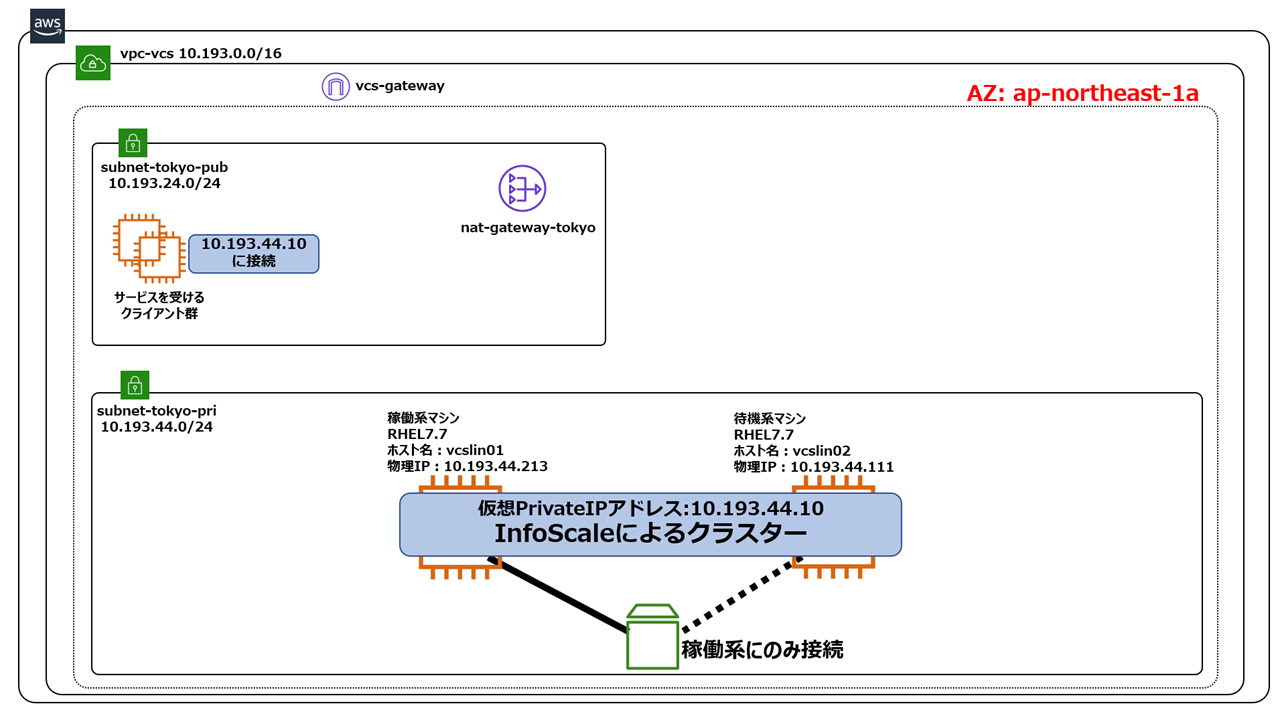
詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
同一AZ内で、ローカルディスクの仮想ミラーリング用いたクラスター
AWSでは、1つのEBSを複数のインスタンスで共有する事はできませんが、インスタンス間でシリアルに切り替える事はできます。前述のクラスターは、その切り替え機能を利用してデータ領域を切り替えを行っています。しかし、切り替えには時間がかかるので、クラスターのフェイルオーバー時間が長くなります。つまり、1分以内で切り替えを完了しなければならないようなビジネスクリティカルな要件には対応できませんし、OracleRACのようなActive-Active型のクラスターも実現できません。このような要件に対応するのが、ローカルディスクの仮想ミラーリング用いたクラスター構成です。InfoScale独自のSDS機能により、各インスタンスのローカルディスクを仮想共有してミラーリングし、その上にクラスターファイルシステムを実装する事で、1分以内のクラスター切り替えやOracleRACのようなActive-Active型のクラスターを可能にします。
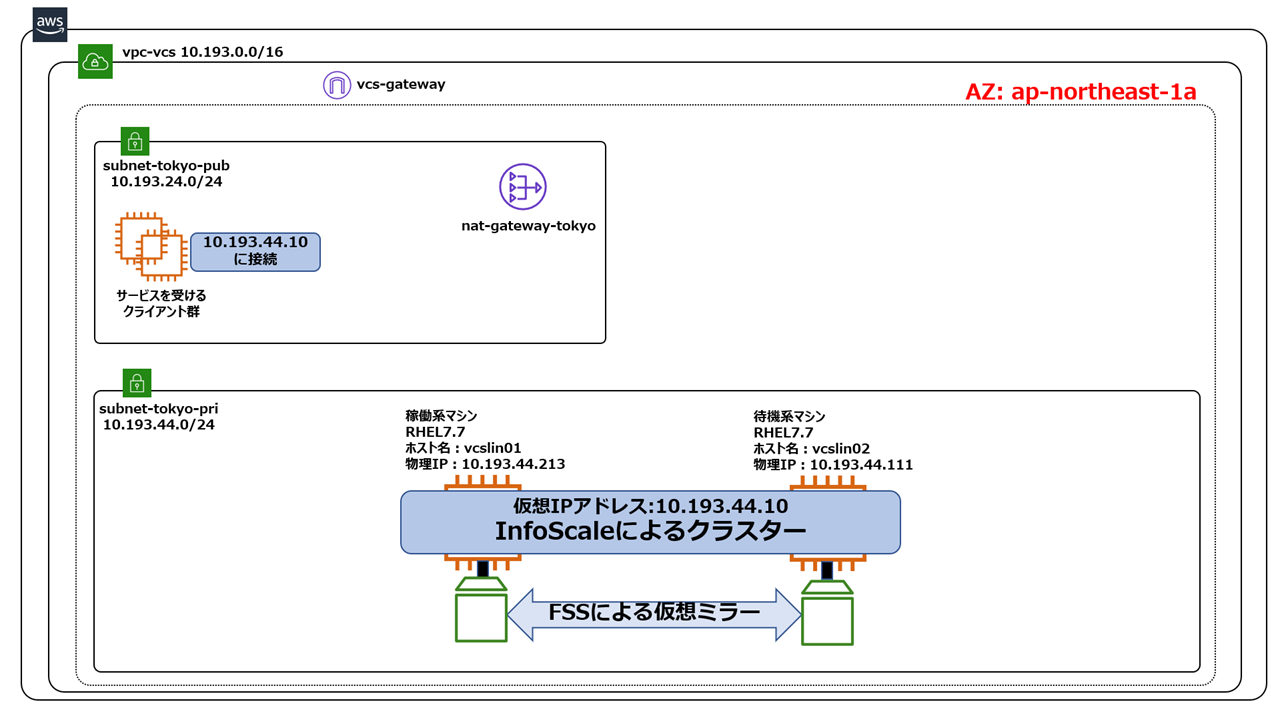
詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
AZを跨いだクラスター(AZ間のLatencyが十分小さい場合)
AWSのAZ障害に対応するためには、AZを跨いで複数のRHELインスタンスを配置し、それらをクラスタリングする必要があります。このような場合、subnetが分かれますのでPrivateIPを切り替える事ができません。また、EBSを切り替える事もできません。従って、オンプレで通用していた従来のクラスタリング手法(最初に紹介した手法)は使用できません。しかし、InfoScaleのローカルディスク仮想共有機能(2番目に紹介した手法でも使用。正式名称は「FSS」と言います)と、OverlayIP機能を使用する事で、これらの問題を解決する事ができます。下記の構成では、クラスターノード間のローカルディスクのデータを同期し、AWSと連携してクライアントの要求先IPのルートテーブルを変更する事で、AZ跨ぎのクラスタリングを実現する事ができます。
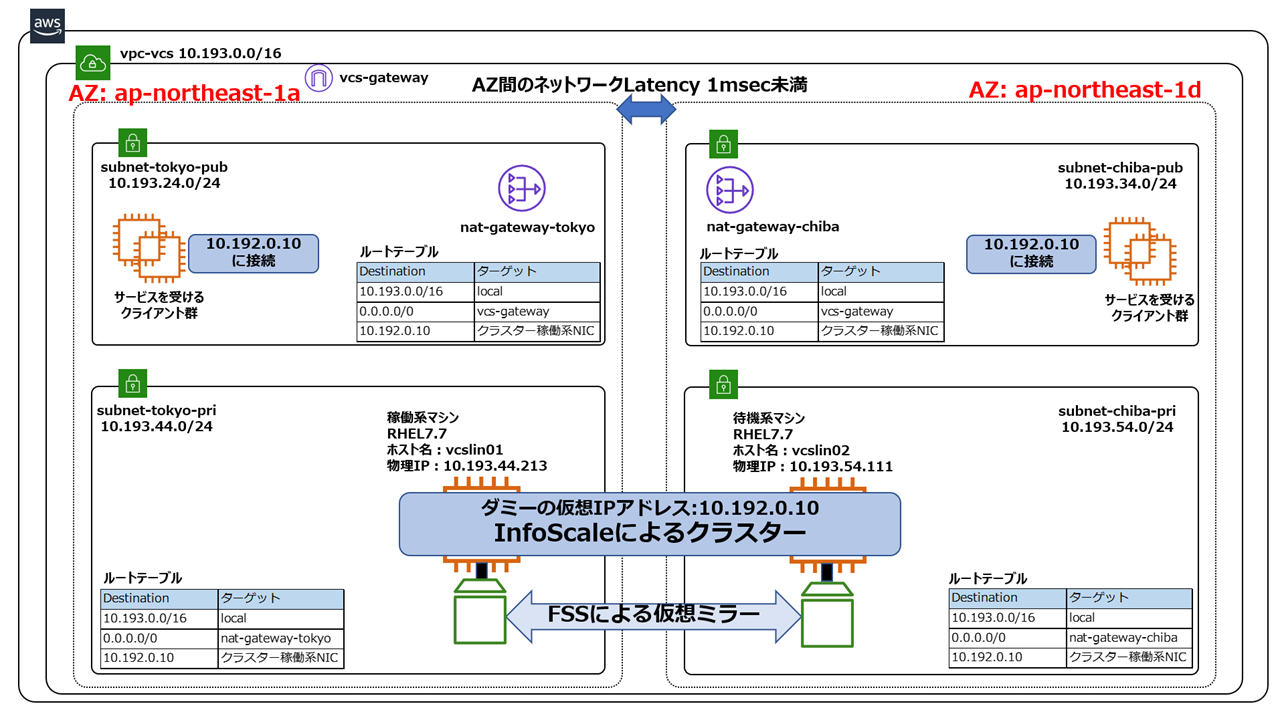
詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
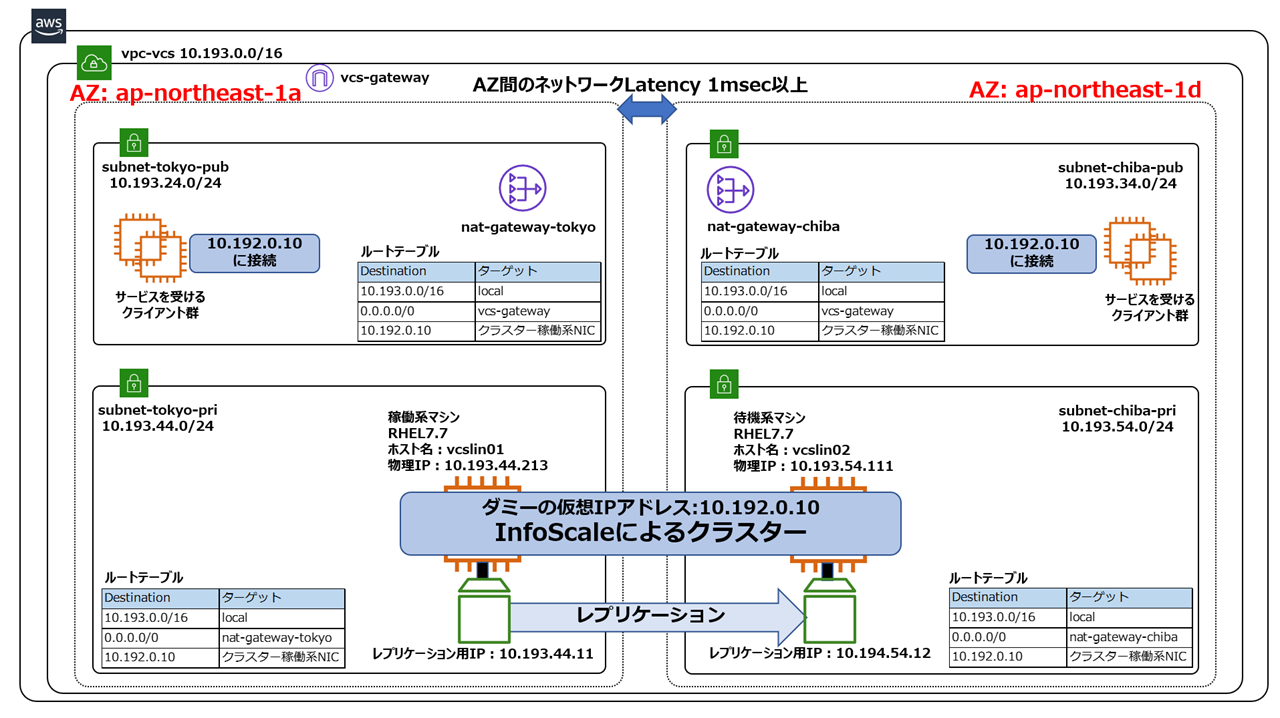
AZを跨いだクラスター(AZ間のLatencyがデータのリアルタイム同期に耐えられない場合)
上記の構成では、FSSを用いて仮想ミラーを行いましたが、この手法はデータのリアルタイム完全同期を行う為、AZ間のLatencyが大きいとI/Oパフォーマンスが低下します。これを避けるために、FSSではなくVVRを用いた非同期レプリケーションを用いる事も可能です。下記の構成では、クラスターノード間のローカルディスクのデータをVVRによって非同期レプリケーションし、AWSと連携してクライアントの要求先IPのルートテーブルを変更する事で、AZ跨ぎのクラスタリングを実現する事ができます。
VPCを跨いだクラスター
AWSのリージョン障害に対応するためには、リージョンを跨いで複数のRHELインスタンスを配置し、それらをクラスタリングする必要があります。このような場合、VPCが分かれますのでPrivateIPを切り替える事もルーティングテーブルを切り替える事もできません。また、EBSを切り替える事もできません。従って、オンプレで通用していた従来のクラスタリング手法(上記に紹介した手法)は全て使用できません。しかし、InfoScaleのレプリケーション機能と、AWSのRoute53と連携したDNS切り替え機能を使用する事で、これらの問題を解決する事ができます。下記の構成では、クラスターノード間のローカルディスクのデータを同期し、AWSと連携してDNSを更新する事で、AZ跨ぎのクラスタリングを実現する事ができます。
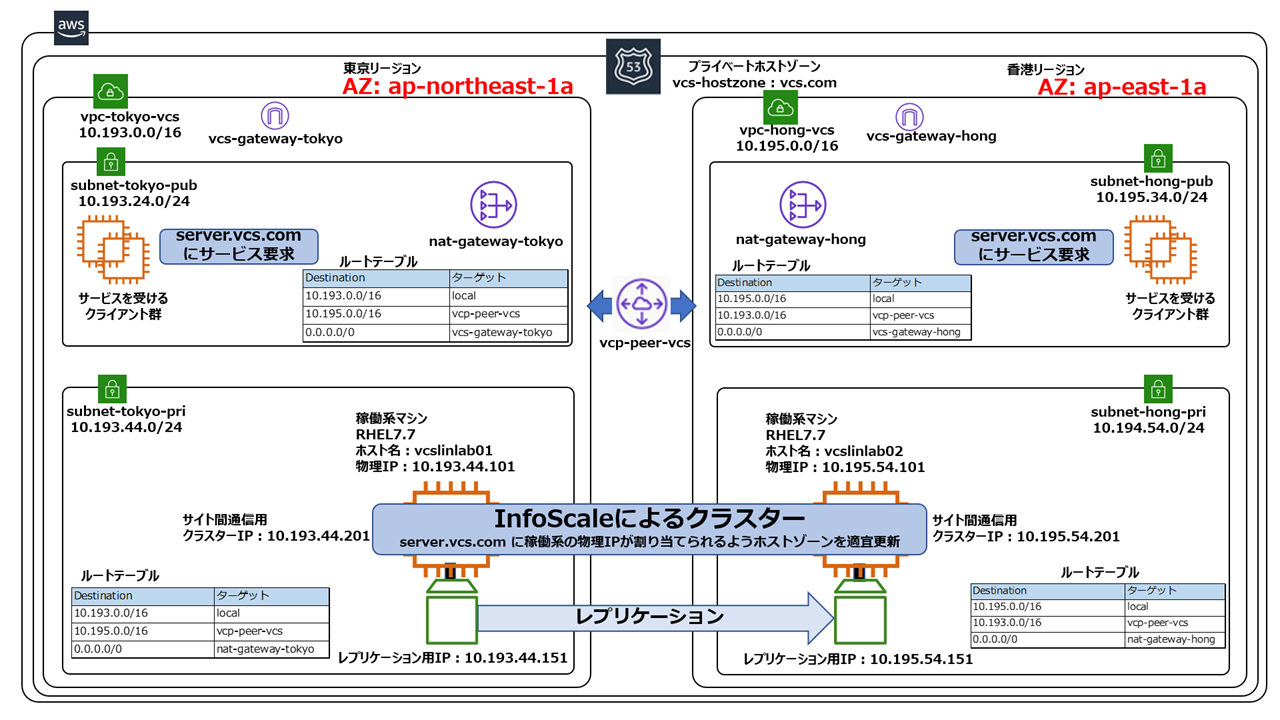
詳しい実装方法については、ベリタスよりホワイトペーパーが公開されています。是非こちらをご覧ください。
オンプレとは異なるInfoScaleの前提条件
RHEL構築時の注意点
AWS上にRHELインスタンスを構築すると、一部オンプレ上と異なる挙動になります。InfoScaleを構築する場合、その違いによって構築が上手くいかない事があります。以下の点に注視してください。
ノード間でpingが通ること:InfoScaleはインストーラー時や稼働時に、pingによる相互監視を行います。しかし、AWS上のRHELはデフォルトでpingが通らない設定になっています。セキュリティグループの「インバウンドの設定」を変更し、pingが通るようにしてください。
RHELのインスタンスにsshを用いてrootでパスワードを用いてログインできること:InfoScaleのインストール時は、1台のノードからpush installを行いますが、その際に他のノードにsshを用いてrootでパスワードを用いてログインします。AWS上でdeployされるRHELは、デフォルトでsshを用いてrootでパスワードを用いてログインできるようになっていません。/etc/ssh/sshd_config や /etc/passwdを変更してパスワードを用いてrootでsshができるようにしてください。
yumが使用できること: AWS上でdeployされるRHELには、InfoScaleが必要とするパッケージの幾つかがインストールされていません。そのため、InfoScaleのインストーラーの中でyumを用いて必要なパッケージをインストールします。適切なネットワークの設定(NatGatewayを経由してyumのサーバーにアクセス等)もしくはyumのリポジトリの設定を行い、yumが使用できるようにしてください。
swapがあること:AWS上でdeployされるRHELには、swapがありません。InfoScaleのインストール時は、swapが必須ですので、ファイルを作成してswapに割り当ててください。
AWS関連の注意点と推奨事項
AWS上のRHELをInfoScaleでクラスタリングする場合、AWSCLIの使用が必須です。その際、以下の点に注意してください。
AWSCLIをconfigureする際は、「Default output format」は、必ず「json」にしてください。「json」以外では、InfoScaleはAWSCLIと連携できません。

InfoScaleがインストールされたノードからAWSCLIを使用する際、セキュリティの観点から、クラスターの動作に必要な機能のみが可能になるべきです。その為に、ポリシーとIAMロールを作成し、それをInfoScaleがインストールされたノード(インスタンス)に割り当てる事を推奨します。AWSCLIをconfigureする際に Access Key と Secret Key を入力する事で、ポリシーとIAMロール関係の作業を省略できますが、セキュリティの観点から、推奨できません。
おわりに
如何でしたでしょうか? 今回の記事と記事中に紹介したホワイトペーパーによって、AWS上のRHELでクラスターを構築する際のハードルはかなり下がったのではないでしょうか? 今回の内容は、高可用性に関する様々な顧客要件を満たすInfoScaleのほんの一部をご紹介にしたにすぎません。次回は Windows 版をお送りします!
商談のご相談はこちら
本稿からのお問合せをご記入の際には「コメント/通信欄」に#GWCのタグを必ずご記入ください。
ご記入いただきました内容はベリタスのプライバシーポリシーに従って管理されます。
その他のリンク
【まとめ記事】ベリタステクノロジーズ 全記事へのリンク集もよろしくお願いいたします。