はじめに
近年Deep Learningへの注目が高まっていますが、多くの場合膨大なデータを必要とすること、学習にはGPU計算環境が必要であったりなど、独特の敷居の高さがあります。この記事では、この敷居を大きく下げるであろうCaffeについて紹介します。ただ、Caffeを紹介する記事はすでに良いものがたくさんあり、そもそも公式documentがかなり充実しているので、今回は躓きやすい部分や他の記事があまり触れていない部分を中心に紹介していきます。
Caffeって何?
CaffeはDeep Learningのフレームワークの一つです。Deep Learningは一般に実装が難しいとされていますが、フレームワークを使えばかなり手軽に扱うことができます。
代表的なフレームワークには、
- Caffe
- theano/Pylearn2
- Cuda-convnet2
- Torch7
などがあります。この中でも最速でありかつ最も活発に開発が行われているのがCaffeです。
とりあえず今回はCaffeとtheanoで速度比較もしてみようと思っています。
前提
- Deep Learning, Convolutional neural network(CNN)に関する知識
- Pythonの基礎的な使い方
画像認識については多少触れるつもりです。
やること
多くのCaffe紹介記事でまだやられていないっぽいことを中心に。モデルをたてるところからCaffeを使ってみたり、CaffeとtheanoでCNNのmnistチュートリアルを回してスピードを比較してみたり、Caffeで回帰問題を扱ってみたり、Caffe実装の最新手法を紹介したり。
記事紹介
これからCaffeを勉強したい人に参考になりそうな記事をまとめていきます。
公式:
http://caffe.berkeleyvision.org/
まずは公式ページ。documentやipython notebookによるPyCaffeなどのチュートリアルが大変充実していていい感じです。
class listなど:
http://caffe.berkeleyvision.org/doxygen/annotated.html
caffeで使用可能なlayerなどについてまとめられています。
Caffeで手軽に画像分類:
http://techblog.yahoo.co.jp/programming/caffe-intro/
reference modelを使って、Caffeを特徴抽出器として使う方法やデータベースの用意、ファインチューニングなどを行う方法が丁寧に説明されています。
Caffeのwiki:
http://wiki.ruka-f.net/index.php?Caffe
上の記事を実際にやってみたりいろいろしています。
Caffeとmafを用いたディープラーニング開発・実験方法:
http://www.slideshare.net/KentaOono/how-to-develop
Caffeの簡単な紹介と、mafによる実験方法についてまとめられています。
Caffeについて困ったときやわからないことがあった時は、
caffe users mailing list:
https://groups.google.com/forum/#!forum/caffe-users
github issue:
https://github.com/BVLC/caffe/issues
http://boardreader.com/site/Issues_BVLC_caffe_GitHub_598836690.html
を見ると良いです。大抵の疑問はここに書いてあります。
Deep Learningによる画像分類
大雑把に言うと、何か画像分類をしたいと思った時に、普通は、
1. 画像から何らかの特徴量を抽出する
2. 抽出した特徴量を使って画像を分類する
の2ステップを踏む必要があります。それぞれのステップでは具体的に何が行われているかを見てみましょう。
1の部分では、SIFTやらSURFなどの"設計済み"の特徴抽出子が配布され、それが使われていました。しかし、Deep Learning(特に、今回はsparseな実装の一つであるCNNを使います)では、これまでは人手で行う必要があった特徴量の抽出が自然に行われます。
2の部分では、好きなsupervised classifierを使うことができます。SVMやLogistic Regressionなどです。
Caffeで特に面白いのは、学習済みのモデルが配布されていることでしょう。これによって、自前で学習させようとすると何日もかかるようなデータサイズ, モデルも簡単に使えるようになります。論文に既存手法として並べる時とかに便利ですね。
インストール
Caffe公式のinstallationを参考に進めていきます。prerequisitesにあるパッケージを全部用意すればいいのですが、一番簡単なのはおそらくAnaconda Pythonを使い、できるだけcondaとpipで落として来てやる方法だと思っています。Makefile.configは適宜書き換えてください。
また、CaffeはcuDNNというDeep Learningのためにできたらしいcudaを使うことができます。どうやら1.4倍程度早くなるらしいです(僕は使ったことがありません・・・)。
以下、思いつく限りの注意点です。ubuntu14系の話多めです。
- ubuntuの14系を使っている場合はコンパイラの変更が必要です。
gcc4.6を呼び出すようにしてください - tools/extract_features.binのbuildで止まる場合→https://github.com/BVLC/caffe/issues/985
- protocol buffer関連はよくインストールし忘れがちなので注意。
pip install protobufで問題ないはずです - PyCaffeはmakeが必要
Caffeで画像分類
Caffeで画像分類しようとするとき、大きく分けて二つの方法があると思います。
- reference model(training済みのモデル)を使う
- 自分で用意したデータセットで学習させたmodelを使う
reference modelを使う方法であれば、自分でモデルを定義・学習させる必要はありません。ハイパーパラメータなども出来合いのものになります。しかし、実際に研究などの目的でCaffeを使用する場合は、自分でデータセットを用意しモデルをたてる方法を取ることがほとんどでしょう。また、自分でデータセット用意,モデル定義を行い、学習させることができるようになれば、reference modelを使う方法も簡単に行えるようになります。なので、ここでは自分で用意したデータセットで学習を行う方法を解説しようと思います。
以下の手順を踏むことになると思います。
0. 前処理
1. データセット用意
2. データベース作成
3. mean(平均画像)を取ってくる
4. deploy, train_test, solverのprototxtを用意する
5. trainingを行う
6. 得られたcaffemodelをPyCaffeでテスト
順に見ていきます。
0. 前処理
学習の収束性や識別性能に大きく関わる部分で、実は非常に重要です。ただ、今回の趣旨から外れるので、よく行われるものについて簡単に触れます。
Data augumentation
画像をあらゆる方法で増やす処理です。増やすとは言っても、ただ人工的なノイズを加えるだけ、などは意味がありません。よく行われるのは、元画像を任意の大きさに切り抜いて、サイズが少し小さい画像を沢山用意したり、左右反転させたりです。
正規化
輝度値をある値域に収める処理です。データ全体の平均や標準偏差を利用していい感じに正規化します。いろいろ方法があります。
1. データセット用意
training用とtest用の二つ用意する必要があります。
画像は、training用とtest用でそれぞれあるひとつのディレクトリにまとめておきます。適当にtraining_dataset/, test_dataset/とでもしておきます。さらに、train.txt, test.txt(名前は別になんでもいいのですが)を準備します。txtの中身は、
lion.jpg 16
cat.jpg 13
penguin.jpg 27
...
というように、画像名 クラスの順に並べて記述します。これで、training_dataset/, test_dataset, train.txt, test.txtの4つが準備されました。
2. データベース作成
build/tools/convert_imageset.binを使うとleveldb, あるいはlmdbを作ってくれます。先ほど作ったデータセットとtxtファイルを使って、train_leveldbを作る場合は以下のようになります。
build/tools/convert_imageset train_dataset/ train.txt train_leveldb 1 -backend leveldb 28 28
引数は、順に、
- 画像のあるディレクトリ
- 画像名とクラスを書いたtxtファイル
- データベースの作成先
- 画像をシャッフルするかどうか(1でシャッフル)
- -backend の後にleveldbかlmdbを指定
- 縦、横の順で、このサイズに画像をリサイズする
というようになっています。もちろん、testも同様です。リサイズとシャッフルとbackendは省略可のはずです(backendを指定しなければlmdbになる)。
3. mean(平均画像)を取ってくる
Caffeでは平均画像を読み込んだら自動で入力画像から平均画像を引いてくれる機能がついています。・・・が、これは前処理の一部と解釈しているので、僕はこの機能を使っていません。。。reference modelなどで、平均画像を引いて学習したモデルを使うときなどは考慮しなければならないですが。
4. deploy, train_test, solverのprototxtを用意する
チュートリアルの内容などを参考にして、自分のモデルを定義していきます。これを使ってtrainingとvalidationを交互に行うことになります。ハイパーパラメータの数が多くて大変ですが、そもそもDeep Learningはそういうものです。最初はチュートリアルを丸パクリするのが良いです。ただ、その場合でも、最低限以下は変更してください。
deploy
-
input_dimの下二つは画像の縦・横のピクセルサイズを指定 - 最終layerの
num_outputをクラス数に設定
train_test
-
data_paramのsourceに自分の作ったデータベースを指定 -
data_paramのbatch_sizeはメモリに乗るように適宜調整 -
deployと同様、最終layerのnum_outputをクラス数に設定
solver
-
net:に使うtrain_testを指定 - あとは適宜としか言いようが無いですが、
snapshot_prefix:は変なのが指定されている可能性が高いので変更しておいた方がいいかもしれません
また、Caffeでは、solver_mode:GPUと指定しさえすればGPUを使ってくれます。
5. trainingを行う
solver名がsolver.prototxtなら、
build/tools/caffe train -solver solver.prototxt
でtrainingが始まります。
6. 得られたcaffemodelをPyCaffeでテスト
これによって得られたcaffemodelはreference modelと同じものです。なので、reference modelを使う場合は以下を読むだけで十分でしょう。
ここからは、PyCaffeで学習後のモデルをテストする方法について簡単に見ていきます。
まず、caffemodelを読みこみます。
net = caffe.Classifier('_deploy.prototxt','_iter_10000.caffemodel', image_dims = (33, 33))
net.set_phase_test()# test phaseで定義されたcaffe netを使用する
net.set_mode_gpu()# GPUモード指定
net.set_raw_scale('data', 255) # data layerに入力として与えられる画像の輝度上限を指定
これによってnetにclassifierが読み込まれました。ここでも、set_mode_GPU()してやればGPUを使って計算してくれます。
各blob,layerでのデータ,重みの次元は以下のようにすれば調べられます。
[(k, v.data.shape) for k, v in net.blobs.items()]
[(k, v[0].data.shape) for k, v in net.params.items()]
また、predictを使うことによって読み込んだ画像のクラスを推定できます。
scores = net.predict([caffe.io.load_image('car.jpg', color = False, )], oversample=False)
各layer,blobの値は以下のようにして取り出せるので、これを用いて適当に可視化してやればよいでしょう。
net.blobs['data'].data[0]
net.params['conv1'][0].data
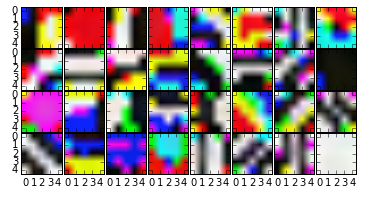
↑こんな感じ
複数の入力画像に対する出力を見たいこともあります。そんな時は、leveldbで保存した画像を読み込んでやれば良いです。caffe.io.load_imageで一枚一枚画像を読み込むより(たぶん)早いです。
import leveldb
db = leveldb.LevelDB('./test_leveldb/')
test_data_raw = [v for v in db.RangeIter()]
PyCaffeにはdrawという、ニューラルネットを視覚的に見るためのパッケージが存在します。これによってCaffeのlayerとblobをグラフっぽく出せます。
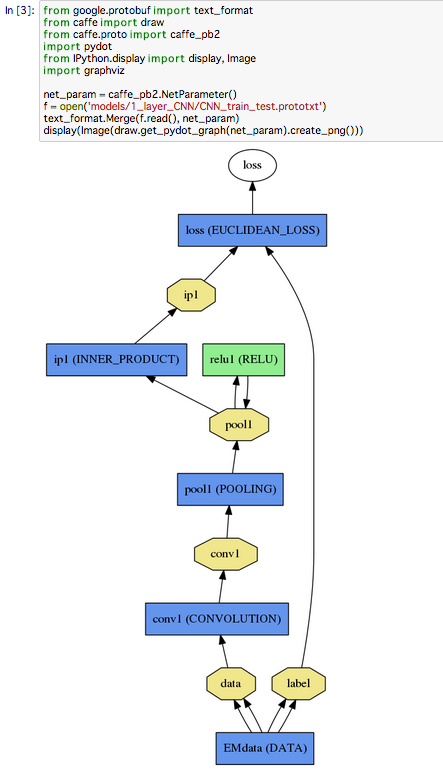
↑こんな感じです。convolution1層,full connect1層のregressionを書いてみました。
Caffe vs theanoスピード比較
Caffeとtheanoのmnistチュートリアルを回してスピード比較してみました。ネットワーク構造とかいろいろ違うんですけど、あえて変更していません。GPUはteslaのm2070です。
結果は、、、
いずれも精度99%で、かかった時間は
theano: 約56分
Caffe: 約4分
でした!!まさに圧勝!!
回帰問題について
Caffe公式のどこを見ても回帰問題のチュートリアルはありません。なので、簡単にやり方を紹介します。通常分類問題ではsoftmax_loss layerと呼ばれる、softmaxとcross validationをやってくれるlayerを最終出力とするかと思いますが、その部分をeuclidean_lossなどの回帰問題用の誤差を計算できるlayerに変更します。さらに、分類問題ではaccuracyは正解率としていましたが、回帰問題においてaccuracyに相当するものは平均二乗誤差などが一般的でしょう。なので、accuracyもeuclidean_lossを出力するようにしてやれば良いと思います。
後は適切なデータセットを与えてやればよいのですが、各種ハイパーパラメータ、特にsolverのlearning rateには注意してください。分類問題で使っていたlearning rateのままだと大きすぎる場合が多いです。参考までに、10^-6程度からはじめて、良い学習が行えるように調整してやると良いかと思います。
最新手法など
最新の論文などでも、Caffe実装が存在するものは多いです。下に代表例を挙げます。
Deeply-Supervised Nets:
https://github.com/s9xie/DSN
Network in Network:
https://gist.github.com/mavenlin/e56253735ef32c3c296d