概要
数値をグラフ化してくれてダッシュボードも提供してくれるツールの「re:dash」を
使用して、DBの値(今回は在庫数の状況)を可視化するまでに行ったことを書いています。
この記事を読むと、re:dashのインストールとクエリを使用して、
在庫数の推移や前日比、在庫の減少数の標準偏差が出せるようになります。
どうしてこの記事を書いたのか
- 自分のやったことの整理のため。
- excelは便利だけど、データの再利用とかしやすい方法で管理したいなー。
そういうぼくと似た人の助けになれば。
前提条件
- どうやってDBに格納する数値を取得するのかについては触れません。
データは何かしらの方法で取得できている体で進めます。 - DB, テーブルの作成などの操作については触れません。
postgresqlを使うので、公式のサイトの https://www.postgresql.jp/document/9.6/html/tutorial-createdb.html の 辺りから見るといいかもです。 - セキュリティは考慮してません。
各自、いー感じにしてください。 - re:dashのグラフの作り方には触れません。
とても簡単なので省略します。そのグラフを作るためのクエリの方に触れます。
準備
- サーバを準備しておく。
re:dashを動かすサーバを準備します。
今回は以下のサーバを使用しましたが、virtual boxとかでも構いません。
さくらのクラウド 1Core-1GB ssd20GBの最小プラン OS: Ubuntu 16.04.2 LTS
サーバとストレージ合わせて、1日97円, 3日で300円弱の料金です。
サーバを停止中はサーバの分の料金がかからないので、
使うときだけ起動しているとさらにお安くなると思います。
- curlコマンドのインストール
以下のコマンドで用意したサーバにインストールします。
ubuntu@redashSRV:~$ sudo apt install curl
re:dashのインストール
用意したサーバにre:dashをインストールします。
postgresqlも合わせてインストールされます。
インストールスクリプトのダウンロード
公式HPの https://redash.io/help-onpremise/setup/setting-up-redash-instance.html にある
「other」の項の provisioning script のリンク先にあるスクリプトをダウンロードします。
コピペでも構いません。
今回はcurlで行います。
コマンド
ubuntu@redashSRV:~$ curl -o redash_build.sh 'https://raw.githubusercontent.com/getredash/redash/master/setup/ubuntu/bootstrap.sh'
インストールスクリプトの実行
以下のコマンドで実行します。
ubuntu@redashSRV:~$ sudo bash redash_build.sh
以下のような出力がされて、プロンプトが返ってくると思います。
そうしたら、完了です。
/etc/nginx/sites-av 100%[===================>] 453 --.-KB/s in 0s
2017-08-16 12:39:19 (109 MB/s) - ‘/etc/nginx/sites-available/redash’ saved [453/453]
ubuntu@redashSRV:~$
re:dashの画面を表示させる
サーバのIPアドレスにブラウザでアクセスすると、
redashのsetupページが表示されます。
こんな感じ。
とりあえず、そのままにしておきます。
DBの準備
sshでサーバにログインして、DB作って適当にテーブルも作ってください。
制約として、1品目につき特定の日付, 在庫数は整数 という感じでお願いします。
例えば、ぼくはこんな感じで作りました。
tdb=> \d count_for_build
Table "public.count_for_build"
Column | Type | Modifiers
-----------------+---------+-------------------------------
date | date | default statement_timestamp()
modelname | text |
stock | integer |
tdb=>
date=日付
modelname=在庫品の名前
stock=在庫数
を表していて、日付はレコードが挿入された日付でその時の在庫品の在庫数を
各カラムに挿入する感じです。
selectすると以下の感じの出力がされます。
tdb=> select date,modelname,stock from count_for_build where modelname = 'RX100';
date | modelname | stock
------------+-----------+-------
2017-07-03 | RX100 | 500
2017-07-04 | RX100 | 300
2017-07-06 | RX100 | 5
2017-07-05 | RX100 | 30
2017-07-07 | RX100 | 75
2017-07-08 | RX100 | 175
2017-07-09 | RX100 | 210
2017-07-10 | RX100 | 105
2017-07-11 | RX100 | 53
2017-07-12 | RX100 | 33
2017-07-13 | RX100 | 20
2017-07-13 | RX100 | 20
(12 rows)
7/3の時点ではRX100という品名の在庫は500あったってことを表します。
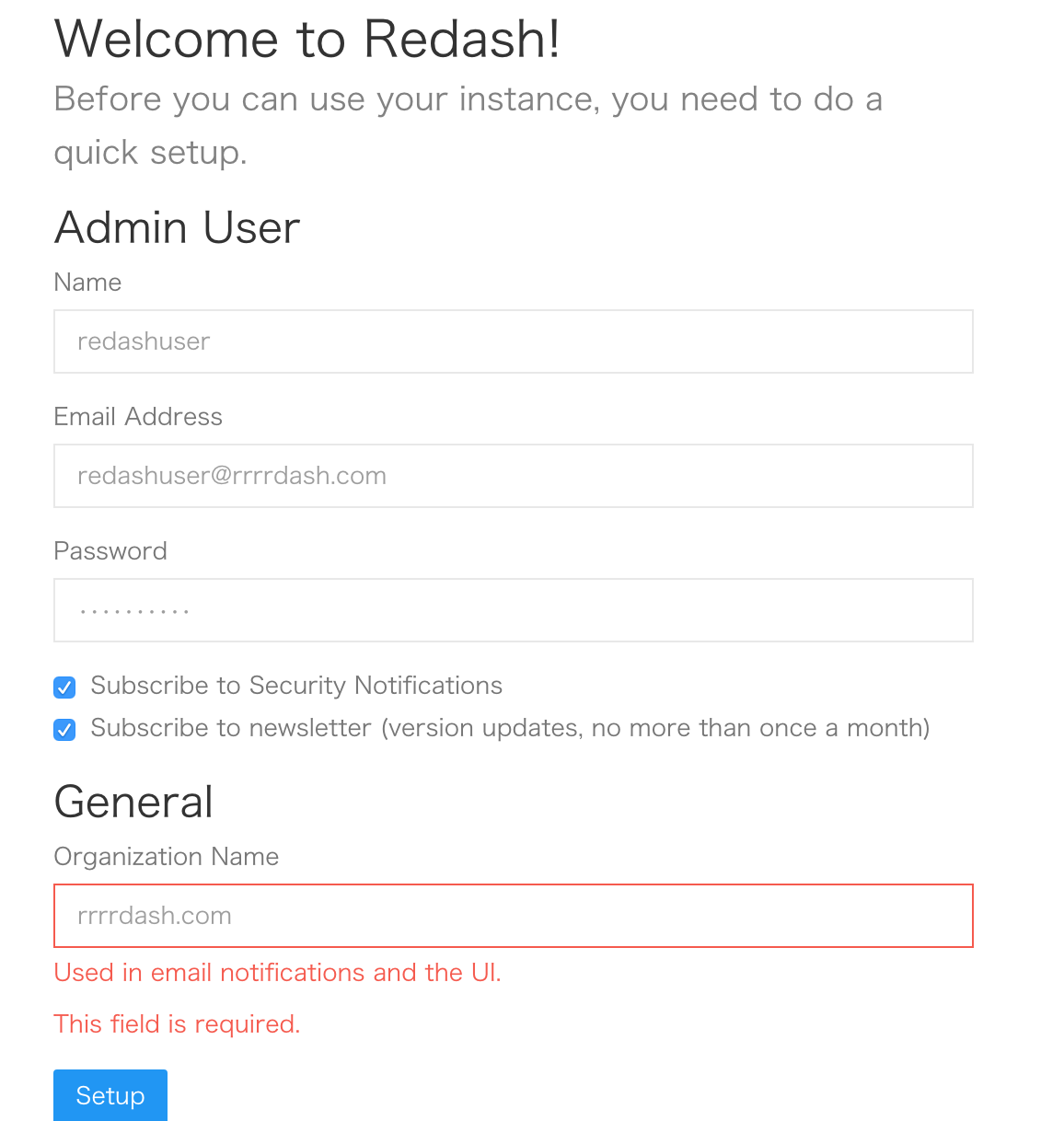
re:dashのセットアップ
ユーザーの作成とかパスワードの設定とか
re:dashをインストールしたサーバのIPにブラウザでアクセスします。
下の画像のようにusernameとかを入力します。
DBの登録
画面右上の方にある のマークをクリックします。
のマークをクリックします。
次に をクリック。
をクリック。
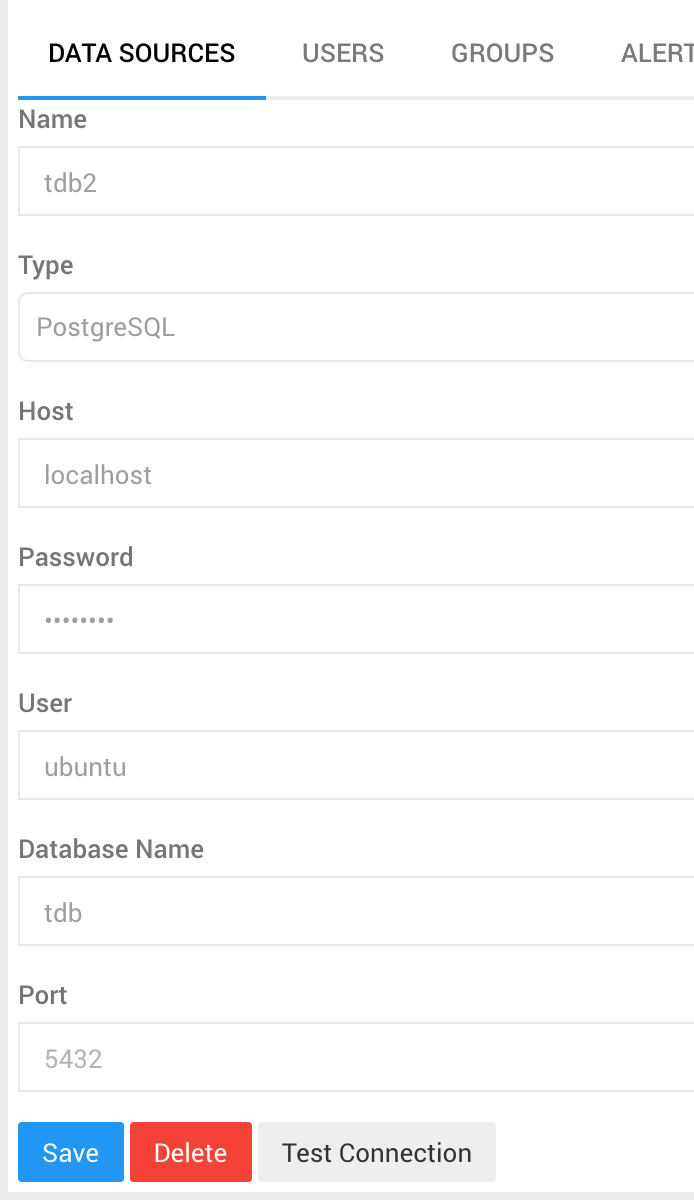
例えば以下の感じで入力します。入力したら一旦、saveしてみて 「test connection」を
クリックして接続できるのか確認してみましょー。
グラフを作る!
在庫数の推移をだす。
以下のクエリで出せます。
SELECT date, stock FROM count_for_build where modelname = 'RX100';
X軸はdate, Y軸はstockです。
前日比を出します。
以下のクエリで出せます。
select before.date, before.modelname, (after.stock - before.stock) as result
from count_for_build as before
inner join count_for_build as after
on before.modelname = after.modelname
and before.date = (after.date - 1)
where before.modelname = 'RX100'
order by before.date;
inner joinで同じテーブルをくっつけるのですが、
どうくっつけるかというと、modelnameが同じで、
beforeとしたテーブルのdateとafterとしたテーブルのdateの1日前のdateが
同じデータを取得するという感じです。(ややこしい)
具体的な日付を当てはめるとbefore.dateが 2017/8/3 なら
-1日して 2017/8/3 になるのは 2017/8/4 なので、2017/8/3 と 8/4 のレコードが抽出されます。
標準偏差を出します。
以下のクエリで出せます。
select stddev_pop(zenjituhi.result)
FROM
(
SELECT
before.date, (after.stock - before.stock) as result
FROM
count_for_build as before
inner join count_for_build as after
on before.modelname = after.modelname
and before.date = (after.date - 1)
WHERE
before.modelname = 'RX100'
and
(after.stock - before.stock) <= 0
)
as zenjituhi
;
前日比をだすクエリをちょろっと変えるだけです。
クエリの解説
- 3行目の ( から 15行目の ) までの解説
前日比をだすクエリのwhere句のところに前日比が0以下のもののみを
抽出するようにしています。
これは、在庫が補充された際に前日比が+300とか数字も標準偏差の計算に含めてしまうと、
大きくずれるし、消費数の標準偏差を出したいのでそのズレがあると困るためです。 - 16行目の as zenjituhi について
3行目の ( から 15行目の ) までをzenjituhiという名前に置き換えています。
エイリアスみたいなものです。 - 1行目の select stddev_pop(zenjituhi.result) について
stddev_pop が標準偏差を求める関数なので、前日比が内包されている、
zenjituhi.result を引数に渡して標準偏差を出しています。
TIPS
- なんでre:dashなの?
特にすごい理由はありません。
最初はelasticsearch と kibana でやろうと思ってました。
識者にそういった目的ならelasticsearchは向かないかもと言われたからかな。 - curlコマンドのオプション
インストールスクリプトをダウンロードする時に実行したcurlコマンドの -o オプションは、
getした内容をファイルに書き出すということをするオプションです。
オプションをつけないと標準出力に出ちゃいます。
以下だと、ダウンロードした内容を "redash_build.sh" というファイル名で保存します。
ubuntu@redashSRV:~$ curl -o redash_build.sh 'https://raw.githubusercontent.com/getredash/redash/master/setup/ubuntu/bootstrap.sh' - インストールスクリプトをsudoで実行している理由
公式HPの https://redash.io/help-onpremise/setup/setting-up-redash-instance.html にある
「other」の項にrootの権限で実行するべしと書かれているから。