前書き
機械の知能化や自動化にはシステム制御のプロセスが含まれていて,オフライン演算で知能を獲得して,オンライン演算で機能を実現するといった流れがあります。オフライン演算では計算に時間制約がないため,下手な演算器構成でも待てばなんとかなりますが,オンライン演算では演算器構成がクリティカルに効きます。ソフトリアルタイム処理であれば高機能OSが搭載されたCPUでもなんとかできて,ファーム/ハードリアルタイム処理が求められるのであればマイコンかFPGAが使いやすいと思っています。FPGAは細粒度性の強みがあり,特に短時間処理が求められる場面で活躍しています。
そんな感じで,サンプリング周波数が1MHzのロボット制御系をZynqを使って実装しました。現在でもサンプリング周波数が1kHのものを見ますし,相当早いと思います。制御性能も非常に良く,精密制御が簡単に実現できます。
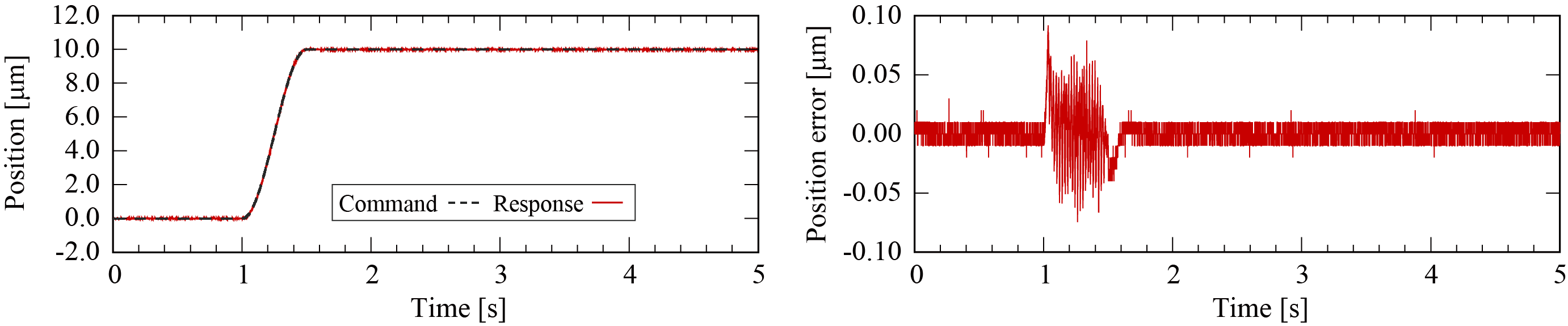
(分解能10nmの光学式エンコーダを使って位置決めをして,誤差1,2パルスに収まりました。)
このコントローラでは,やはりFPGAの細粒度性を使って高速信号処理などを行なって演算系に混入する雑音を消し,制御系のゲインをあげています。そうすると,従来の$H_{\infty}$制御系のような制約付最適化を行う際の制約自体を緩くすることができて,ゲインが上げられるので性能が上がります。なので,頑張って補償器を設計するより性能を出しやすいと思います。
産業用では制御用コントローラを可能な限り安くしたいため,サンプリング周波数を少し落としても良いからARMだけでできないかとの意見も頂いています。産業用コントローラの使用状況としては,古くはマイコンが広く普及し,IoTの流れを受けて安川電機や三菱のCPLDが普及しています。現在ではインタフェース(特に通信系)の柔軟性不足からマイコンに戻った例やSoC FPGAを導入してLinux on ARMで高機能を実現しつつFPGAで制御を行うといった例があるそうです。ARMベースのコントローラは国内だとオムロン(旧Delta tau)の製品があり,個人的な感想では高価ですが他社より高性能です。なので,ARM単体でもできないことはないのですが(実際にQuad CoreになったRaspberry Pi2B以降でも報告されています),ARM組み込みは大変そうなので,できる人がやってくれればと思います。
FPGAの利点
FPGAの利点は,とりあえず高速化だとか言われていますが,命令レベルで並列性が確保できない場合には,CPUの方が周波数が高いので,頑張って設計しても全然勝てません。なので,FPGAを計算補助に使うとしたら,ベクトル演算を行う並列ALUをたくさん載せるくらいしか思いつきません。実際にロボット制御の指令値生成はデータ依存性があって逐次的に計算したり三角関数を使ったりするので,FPGAで行うのは非常に効率が悪いです。他に思いつくのは,I/Oシステムと回路の密接設計による高速処理です。高頻度取引でもFPGAが強いのはこのためでしょうか。ロボット制御でも,誤差を補正するフィードバック制御においては観測(演算器入力)してから補正指示を出す(演算器出力)までが早い方が良いです。
これを簡単に見るために,演算器を生体模倣的に図示してみました。
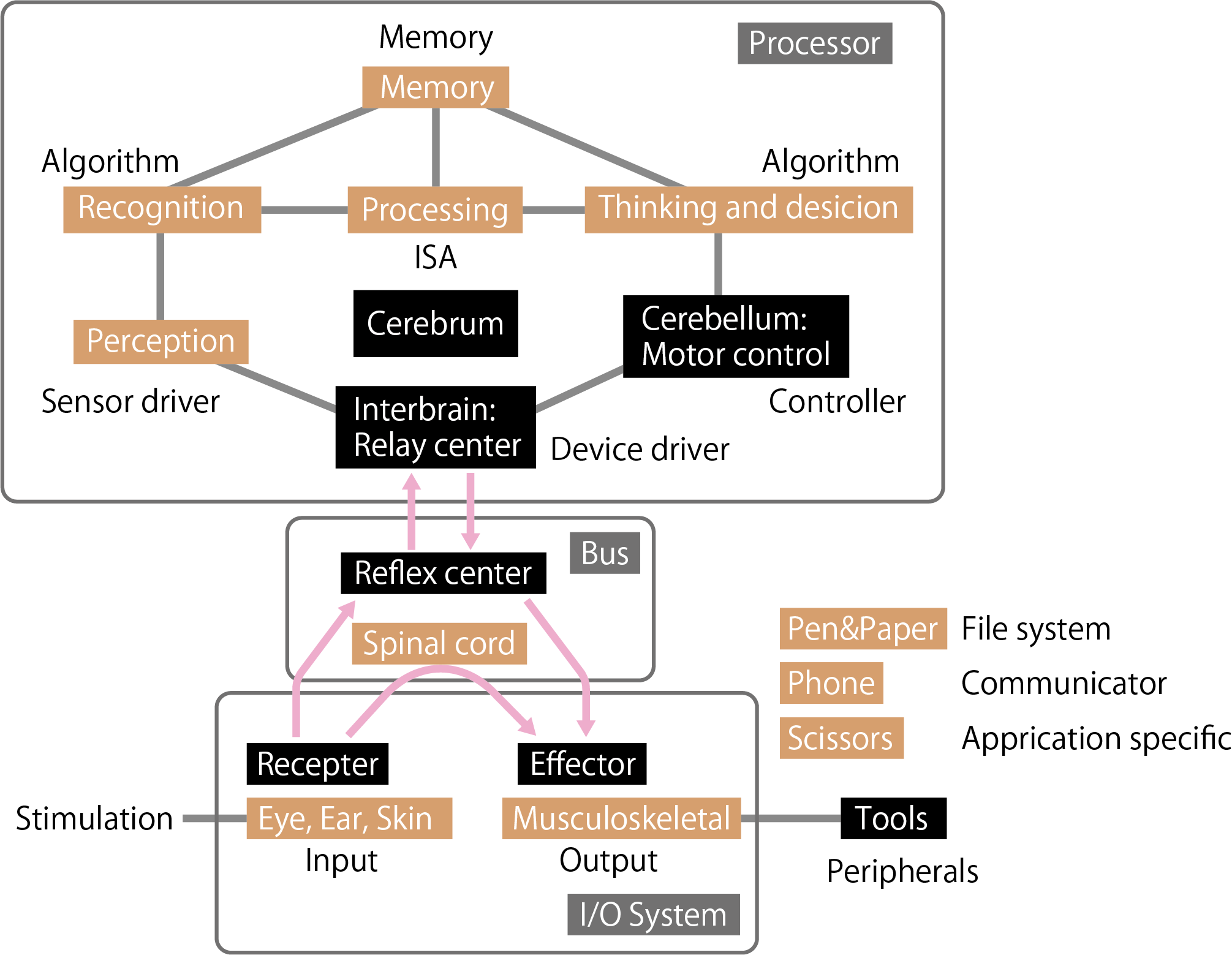
目や耳や皮膚にある受容体が人間への入力で,ある信号は脳まで,ある信号は脊髄まで行き,筋骨格系への指令が出される,という模式図です。脳まで行く信号は,間脳の中継中枢を通って側頭葉・後頭葉等の知覚部部を通って側頭葉・頭頂葉等で認識され,前頭葉で意思決定をして小脳で運動制御信号を発行した後にまた間脳を経て筋骨格系に行く。これはCPUで行われる処理に似ていると思う。FPGAで行う演算加速(並列ALU追加)は,頭頂葉の前頭連合野の面積を広くして演算量を増やすことに相当すると思う。一方で,脊髄反射は脳を経由しないから早い。この反射中枢はFPGA上のI/Oシステムに密設計される回路に似てると思う。筋骨格系は外部に作用するため効果器と呼び,外部の道具を使えたりする。ペンと紙を使えば記録や読み返しができたり,電話があれば通信できたり,ハサミがあれば物が切れる(特定用途)。
SoC FPGAを使った設計では,脳を辿る信号はARMを介す処理,脊髄反射はFPGAの設計だと思います。ARMはコンピュータプログラムを動かして非常に色々なことができますが,このプロセッサを介するためには様々な手続き(割り込みやバス制御)にかかる時間があります。ここでは,それぞれにかかる手続き時間を計測してみました。
ARMセットアップ
ARMには@ikwzm様提供のLinuxを載せました。
https://qiita.com/ikwzm/items/7e90f0ca2165dbb9a577
デバイスドライバは書いておらず,UIOでI/O操作と割り込みをしています。ARMとFPGAの接続にはAXI4(MasterはARM側に設置)を使用しています。
時間計測
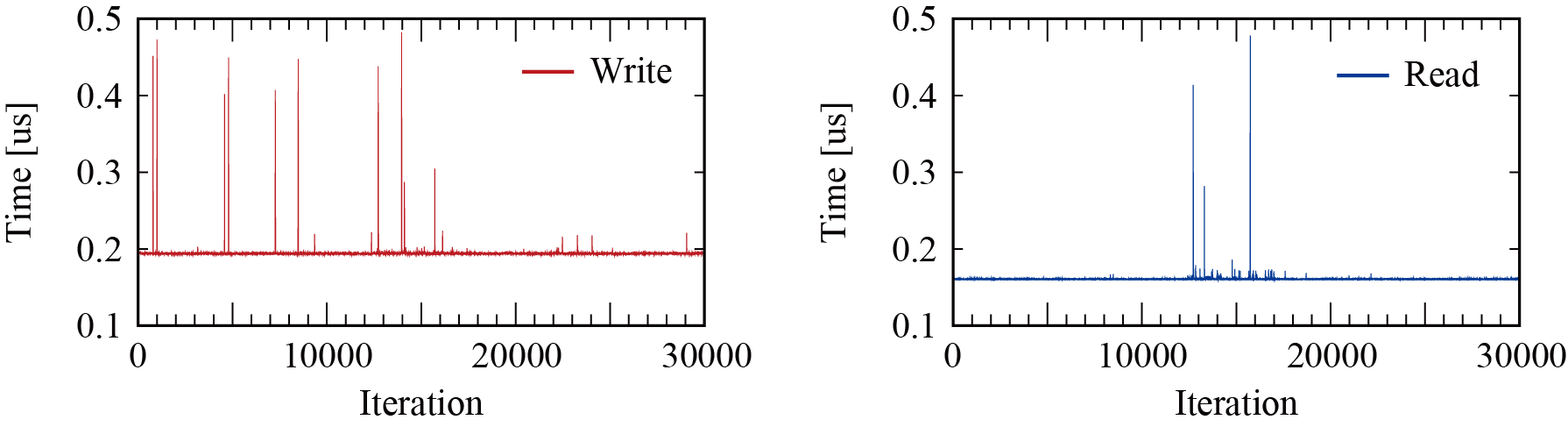
受容器および効果器と間脳(中継中枢)の通信速度
ARM上でマッピングしたI/Oの書き込み/読み込み速度に相当すると思います。ARMのAXI4 Masterが行ってくれる制御にかかる時間を30000回計測しました。100回ずつの書き込みと読み込みにかかった時間を100で割ってます。計測用タイマはFPGAに置いてます。
大脳部分の演算時間
適当に,普段使用しているロボット制御用のコードを回して,clock_gettime()を使用しました。clock_gettime()自体のオーバーヘッドの問題で,1us程度の誤差があります。
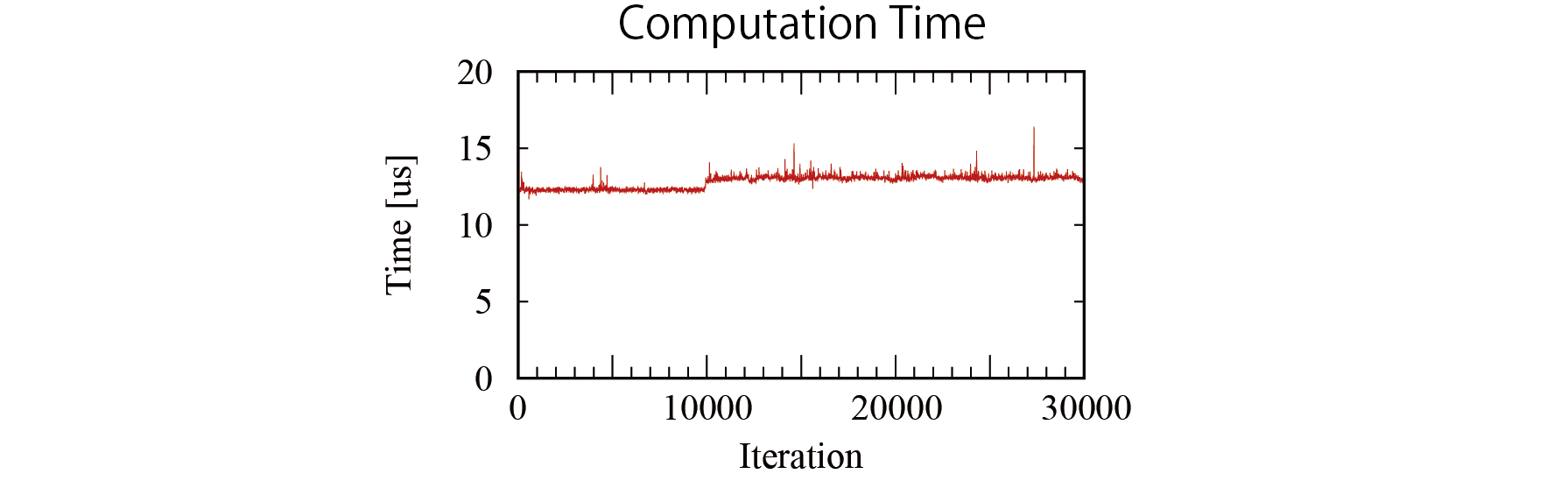
10000回目以降に三角関数の計算を入れてみたら,演算時間が増えました。
受容器から効果器までのラウンドトリップ時間
FPGAからARMに割り込みをかけ,ARMからI/O書き込みが来るまでの時間をFPGA上のタイマで計測しました。
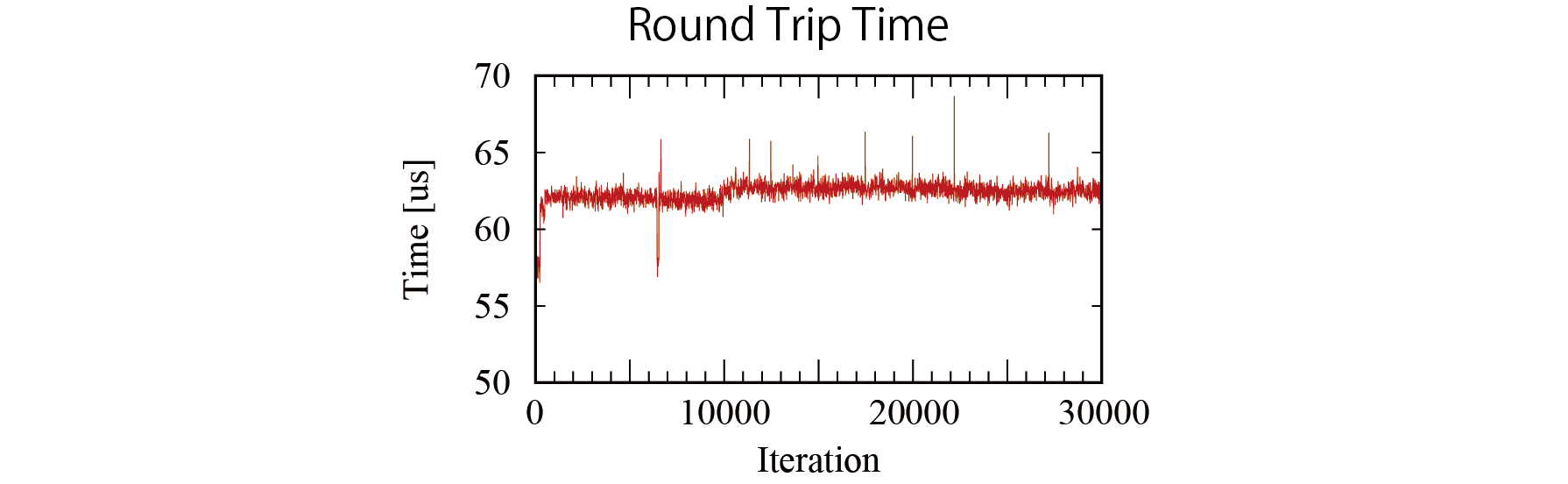
AXI4の速度とARM演算時間を考慮すると,かなり長い時間かかっていました。ラウンドトリップ時間からAXI4通信時間とARM演算時間を差し引いて,プロセッサを使用するための手続き処理にかかる時間は次のようになりました。
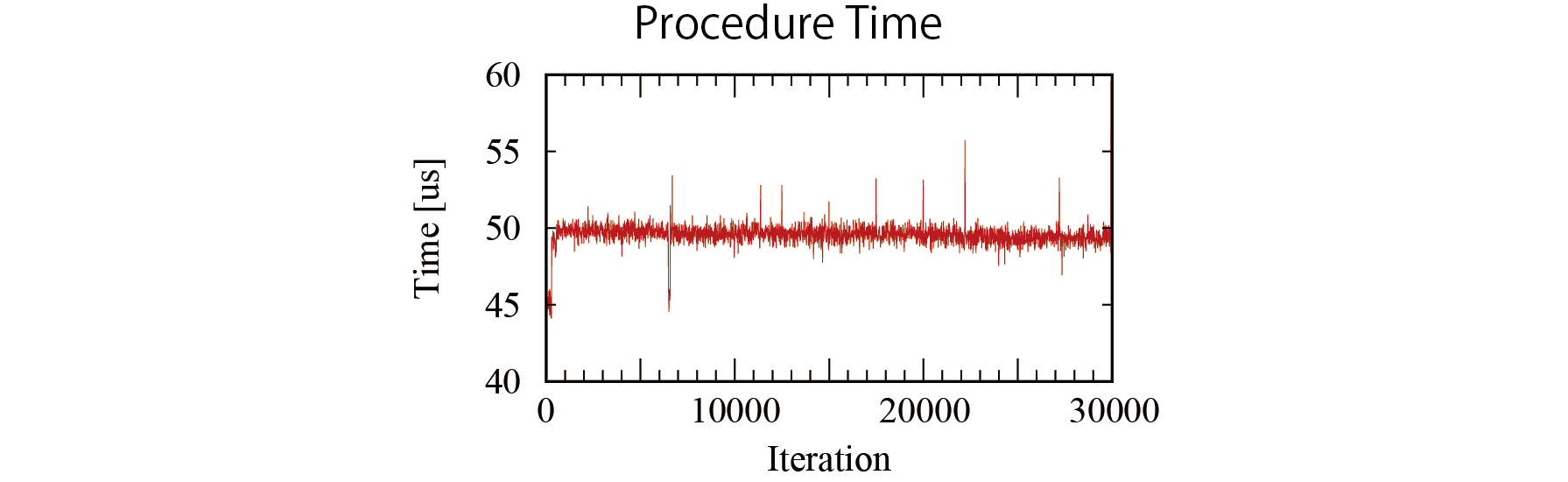
割り込みに関する処理に遅れがあると思うのですが,UIOを使った割り込みが遅い気がします。Kernel内で処理した時の応答速度はもっと早いと思います。
まとめると次のようになりました。
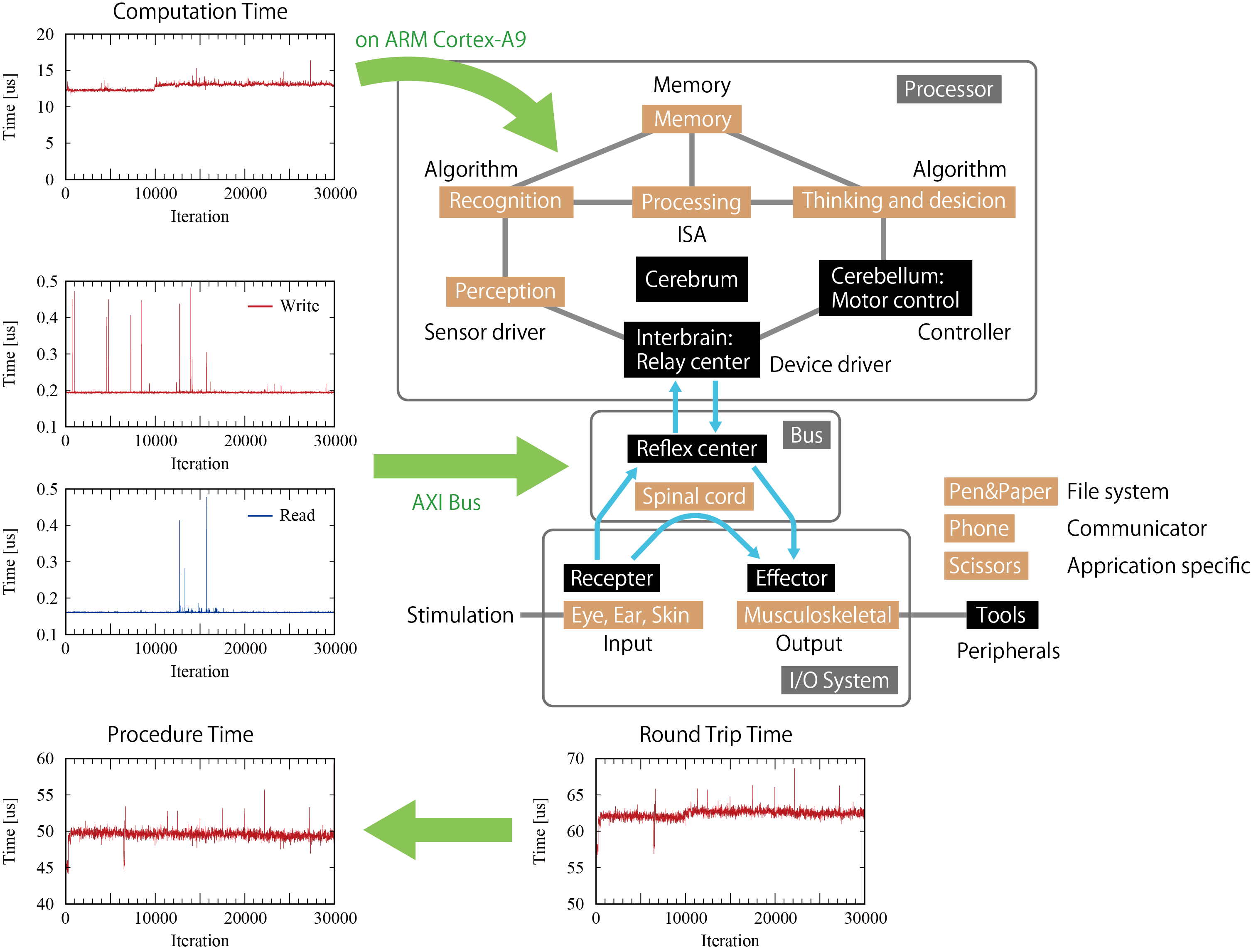
ARMプロセッサで短時間サンプリングを行いたかったらこの手続き時間をどうにかしないといけないらしい。
その他
制御では時間軸方向のゆらぎ(ジッタ)の影響で信号処理系が狂うので,厳密時間一様サンプルができるだけでもFPGAの良さはあると思っていて,やはりFPGAの導入は非常に有効だと思います。また,FPGAの細粒度性を活用すればコンピュータプログラムで言う所のスレッド,しかも各自が時計を持ってて時間厳密かつ無駄が少ない,がたくさん作れるので,様々な種類の演算を行うロボット制御系では実装上非常に便利だと思います。