初めに
この記事は昨年開催された「NFL Health & Safety - Helmet Assignment」の内容を振り返るために書いています。最後の約1カ月間だけ参加し、私の結果は、61 / 825 (Solo bronze medal, Leaderboard
) でした。個人的には Re-ID の実装を完全に終えることが出来ず、悔しい思いをしたコンペです。手元のテストデータではかなり出来ていたのですが、最終日に Submit するとエラーになりました。あと1日あれば結果はかなり変わっていたと信じています。
Kaggle に コード を公開しています。ご興味のある方は是非。

(この映像はコンペの Top Page に掲載されているものですが、おそらく去年のコンペの映像と思います。去年は、選手同士のヘルメットが衝突したタイミングを検知するというものだったため、緑の点が衝突を意味していると思います。)
NFLコンペについて
概要
毎年開催されているNFL(The National Football League)コンペです。今年のお題は、映像データからアメフト選手のヘルメットを検出し、一意なIDを振り、トラッキングすることでした。私自身は今年が初めての NFL コンペでした。
各選手は Wearable device を身に着けているため、各選手に選手IDが割り振られており、GPSによってある程度の位置は特定出来ていました。そのため、選手ID、選手の位置(会場を真上から見たときのX, Y)等がコンペ主催者から与えられていましたが、映像データとは紐づいていない状態でした。また、Wearable device から取得されているデータの時間間隔より、映像データの間隔の方が短かった(FPSが大きい)ため、Wearable device のデータをうまく映像データ側に紐づける必要性がありました。
実際のアメフトを見てみると分かりますが、選手は試合中に色々な体勢をとり、また、選手同士が重なることも多いです。さらに、サイドラインの外側には観客や控え選手がいるため、過検知対策が必要になる等、実際の映像を見てみるとアプローチすべき課題が多かった印象でした。映像は、会場の2方向から撮影されており、撮影方向によっては選手が非常に小さいというのも難しいポイントでした。
データと評価方法
与えられたデータは、画像データ(9,947枚)、映像データ(学習:120ファイル, テスト:6ファイル)、CSVデータ(3種類)です。テストデータの一部が手元にありましたが、Code competition のため、Submit 後に別のテストデータで精度が検証されることになります。
Metricsは IoU ≧ 0.35 の WeightedAccuracy でした。Weighted の部分で、選手同士が衝突した瞬間を当てれたことと、当てれなかったことに1000倍の差が出るように設計されていました。アメフトにおける人間同士の衝突は非常に危険なため、ここを正確にトラッキングしたいという思いが伺えます。
以下にデータの詳細を記載します。
- 画像データ
過去の色々な試合映像から集められた試合中画像です。このデータはコンペの最終提出物に直接関係なく、使っても使わなくてもOKでした。 - 映像データ
学習用とテスト用の映像データです。1つの映像は数十秒程度から出来ており、ボールが動く(スナップ)10フレーム前から、1つのプレイの終了までに統一されています。映像終了のタイミングは開始ほど厳密には決まっていませんでした。 - CSVデータ
- ラベル情報(画像データのラベル一覧、学習用映像データのラベル一覧)
- Wearable Device情報(学習・テスト用の選手ID、位置情報等)
- Baseline情報
- NFL側で作成したヘルメット検出モデルの推論結果です。このCSVが提供されているのは特殊でした。学習・テストの両方のBaselineが手元にあり、これを使っても使わなくても良いという状態でした。
実施したこと
今回のコンペは大きく2つの問題(検出と紐づけ)で構成されており、それぞれに対して改善作業を実施していきました。実施したことを以下に簡単にまとめます。
-
ヘルメットを検出する
- YOLOv5の学習
- Baseline CSV とのアンサンブル
- 過検知ヘルメットの除外
- ヘルメット識別モデルによる過検知対策
- サイドラインヘルメットの削除
- 見逃したヘルメットの補完
-
Wearable device の情報と検出したヘルメットを紐づける
- 検出したヘルメットと位置情報の距離によるID割り当て
- Deep Sort アルゴリズムによるRe-ID
- 自作 Re-ID による選手IDの上書き
詳細
上記に記載した中には、精度向上に繋がったものと、繋がらなかったものの両方があります。また、Public Notebook からそのまま流用したものもあります。
YOLOv5の学習及び Baseline とのアンサンブル
これは精度向上に繋がりませんでした。YOLOv5 は別のコンペでも利用していたのでコード自体はすぐ完成しました。いくつかのパターンを試しましたが、Baseline そのままで Submit するより毎回精度が悪化するという結果となりました。アンサンブルは、複数のモデルで BBox を出力し、NMS で被っている Bbox を削除するという手法を取りました。
YOLOv5 を利用すること自体は容易になっており、著者の GitHub や、Kaggle でサンプルコードが多く見つかります。本記事の執筆時点でも YOLOv5 の論文は公開されていませんが、Kaggle 内では多くの利用実績が見られます。
過検知ヘルメットの除外
実施した2つの方法の内、サイドラインヘルメットの削除によって、Public LB でメダル圏内に入ることが出来ました。1つ目のヘルメット識別モデルの方は改善に寄与しませんでしたが、こちらも含めて簡単に内容を記載します。
-
ヘルメット識別モデルによる過検知対策
こちらのモチベーションは、Baseline モデルの Bbox を可視化してみると、選手の肩や足を間違ってヘルメットと認識しているケースが見られたため、ヘルメットかどうかに特化した CNN を作成し、過検出のヘルメットを減らすことにありました。
まずは、画像データを利用して、ヘルメットを中心として元々の Bbox サイズの数倍を切り出した画像と、ヘルメットの位置からランダムに左、右、下に移動して切り出した画像を作成しました。両者の画像が被る可能性があったので、IoU が大きいものは削除しました。これらの画像に対して、CNN を BCELoss で学習させました。このモデル自体の精度は良かったのですが、これを組み込んで Submit すると精度が悪化するという結果に終わりました。 -
サイドラインヘルメットの削除
Baseline の推論結果を映像として見てみると、映像開始直後は出場している選手だけにフォーカスしていたカメラが、選手の移動に伴ってサイドラインの観客や控えの選手を映すようになっていました。この際に、サイドラインの控え選手の多くを過検知していたため、これらの除外を検討することにしました。
方法としては、プレイの序盤は必ず選手にフォーカスしていることを利用し、最も外側の Bbox 座標を計算し、その座標をトラッキングしていきました。プレイ後半になると、サイドラインのヘルメットが出現し、トラッキングしていた座標が大きく変化します。この変化量が閾値以上だった場合に無視する、という処理を追加することで、ほとんど全てのサイドラインヘルメットを除外出来ました。
見逃したヘルメットの補完
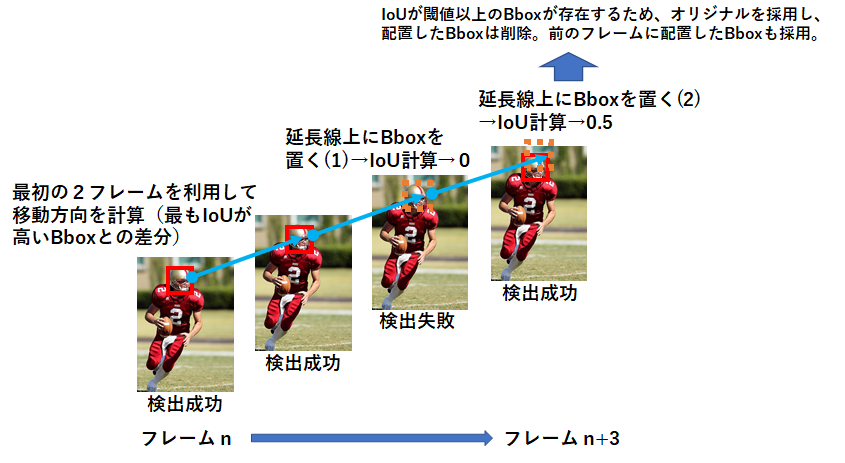
物体検出の特徴として、現在の技術では全てのフレームにおいて人間を正確に捉えることが出来ず、必ず検出したり、見逃したりを繰り返します。ただ、今回は映像のFPSが高かったため、ある選手におけるnフレーム目のヘルメットと、n+1フレーム目のヘルメットは高いIoUになることが期待できました。そのため、下図に示す処理によって見逃したヘルメットを補完しました。
この例だと、2回目の補完でモデル側が見つけたヘルメットと交差する(高いIoUになる)ことが出来ています。この何回補完を試みるか、と、IoUの閾値がパラメータになっています。今回は、前者は多め(10回)、後者は小さめ(0.2 or 0.3)で実施しました。
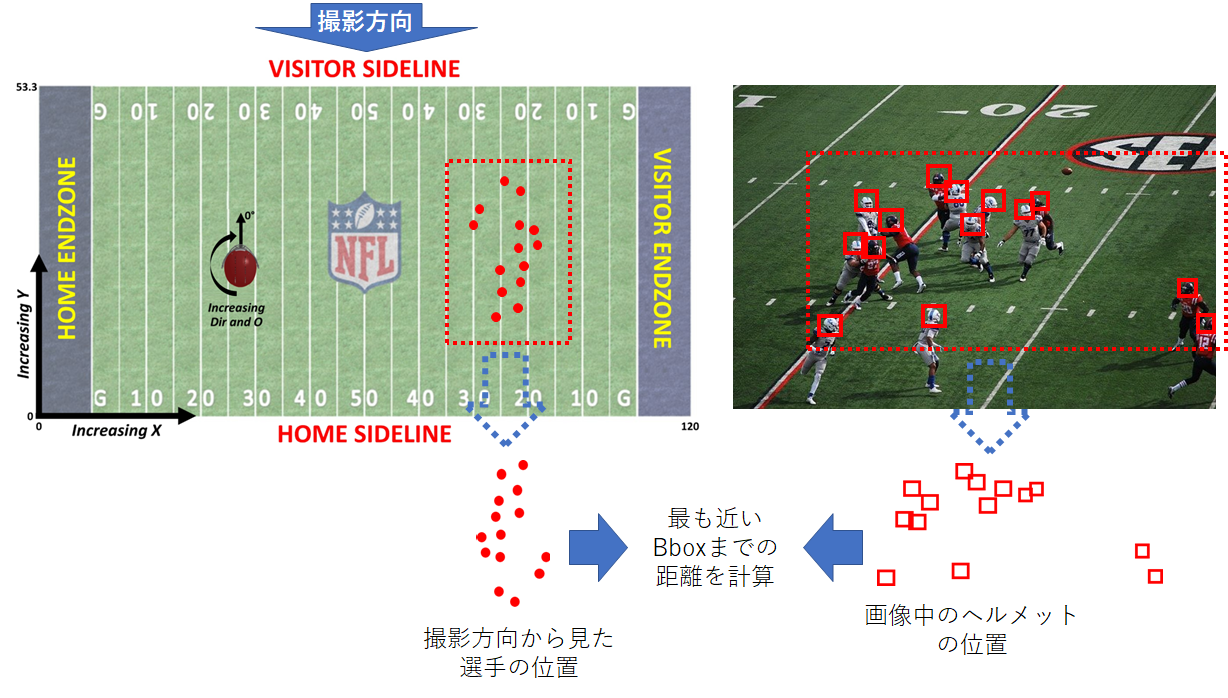
検出したヘルメットと位置情報の距離によるID割り当て
こちらは Public に公開されていた手法をそのまま利用しました。下図のように計算を行う手法です。左が Wearable device で取得されている情報、右が映像データです。距離を計算する際は、 Wearable device 側のデータを数パターン回転させて、最も合計距離が小さい割り当てを採用します。この手法で選手IDを割り当てることが出来ました。
ただし、ヘルメットの過検知や見逃しがあると大きく割り当て精度が悪くなります。サイドラインヘルメットの除外で精度改善出来たのは、このロジックによる割り当てがうまく挙動したからです。
Deep Sort アルゴリズムによるRe-ID
上記のロジックによって選手IDの割り当てを行いましたが、割り当て誤りが発生してしまうため、より正確になるよう Deep Sort で再割り当てを行いました。こちらも Public Notebook の手法をそのまま利用しました。
Deep Sort は、Re-ID(Person Re-Identification)のためのアルゴリズムです。Deep Sort によって、同一人物と思われる Bbox にGroup ID を振ることが可能です。この Group ID ごとに頻出の選手ID を計算し、上書きを行います。
アルゴリズムに関する解説は日本語記事1もいくつか見つかるので、詳細は割愛し、簡単な説明に留めたいと思います。Deep Sort は、ある人物をトラッキングするために「想定される次フレームでの Bbox の位置」と「同一人物かどうかを判断したい2つの Bbox の特徴量ベクトルの類似度」を基に、同一人物であるかを判定するアルゴリズムです。論文はこちら。利用したモデルはこちらのGitHub に公開されています。
GitHub で公開されている例

自作 Re-ID による選手IDの上書き
上記で使用した Deep Sort の中では同一人物であるかどうか、を学習したモデルを利用しています。しかし、今回の検出対象はヘルメットであったため、Deep Sort では正しく Re-ID 出来ない可能性がありました。再学習という手もありましたが、「見逃したヘルメットの補完」ロジックにおいて、IoUを計算していく過程で Group ID を振ることが出来ると気づき、こちらの実装を優先しました。ロジックを改良して Group ID を割り振り、Group ID ごとに頻出の ID を計算し、上書きを行いました。
テストデータでの結果を映像として見る限りは、Deep Sort の出力と比べて、かなりの改善が見られました。しかし、冒頭にも記載した通り、Submit するとエラーになってしまい、コンペの時間切れとなってしまいました。Code competition では、Submit 後に別のテストデータでの推論が行われるため、エラーが出るか出ないかは Submit してからでないと分からないという落とし穴があります。
終わりに
今回、私としては初めて映像コンペでした。結果的には、Beseline に後処理を追加する感じになり、なんとか銅メダルを獲得することが出来ました。コンペ終了後に公開された 1st place solution は素晴らしいもので、是非みなさん一度読んでみてください。今回も学びの多いコンペでした。参加された皆様、お疲れさまでした。
追伸
優勝したKmatさんの Qiita記事 を見つけました!私も2022年はSoloホームランを狙いたいと思います。