はじめに
GCP上にMLパイプラインを構築していく方法を記載します.
本記事のサンプルコードは以下のリポジトリにあります.
https://github.com/tonouchi510/dataflow-sample
必要なGCPプロダクト
- Google Cloud Storage(GCS)
- Cloud Pub/Sub (Pub/Sub Notifications for Cloud Storage)
- Cloud Dataflow
- Cloud ML Engine
機械学習を使ったサービスの場合,新しいデータが追加されるたびに,機械学習による予測や再学習を行い,その結果を保存したい,ということがあると思います.
ここで,機械学習モデルへの入出力だけでは完結しない,前処理や後処理が必要な予測処理を行う場合は,Cloud ML Engineだけでは不十分であり,Dataflowなどを組み合わせていく必要があります.
今回は,dataflowを利用した機械学習の予測処理全体のパイプラインを作って行きます.ただし分量が多くなるので2回に分けます.
※学習のパイプラインに関してはまた別の機会に記事にします.
※GCPのアカウント作成やSDKのインストールなどは既に済ませていることを前提として書きます.
構成
GCPのプロダクトを組み合わせれば,以下の図のようなパイプラインを構築することができます.
今回は「Pub/Sub」→「Dataflow(前処理)」→「ML Engine」→「Dataflow(後処理)」→「GCS」というフローを作成することを目指します.
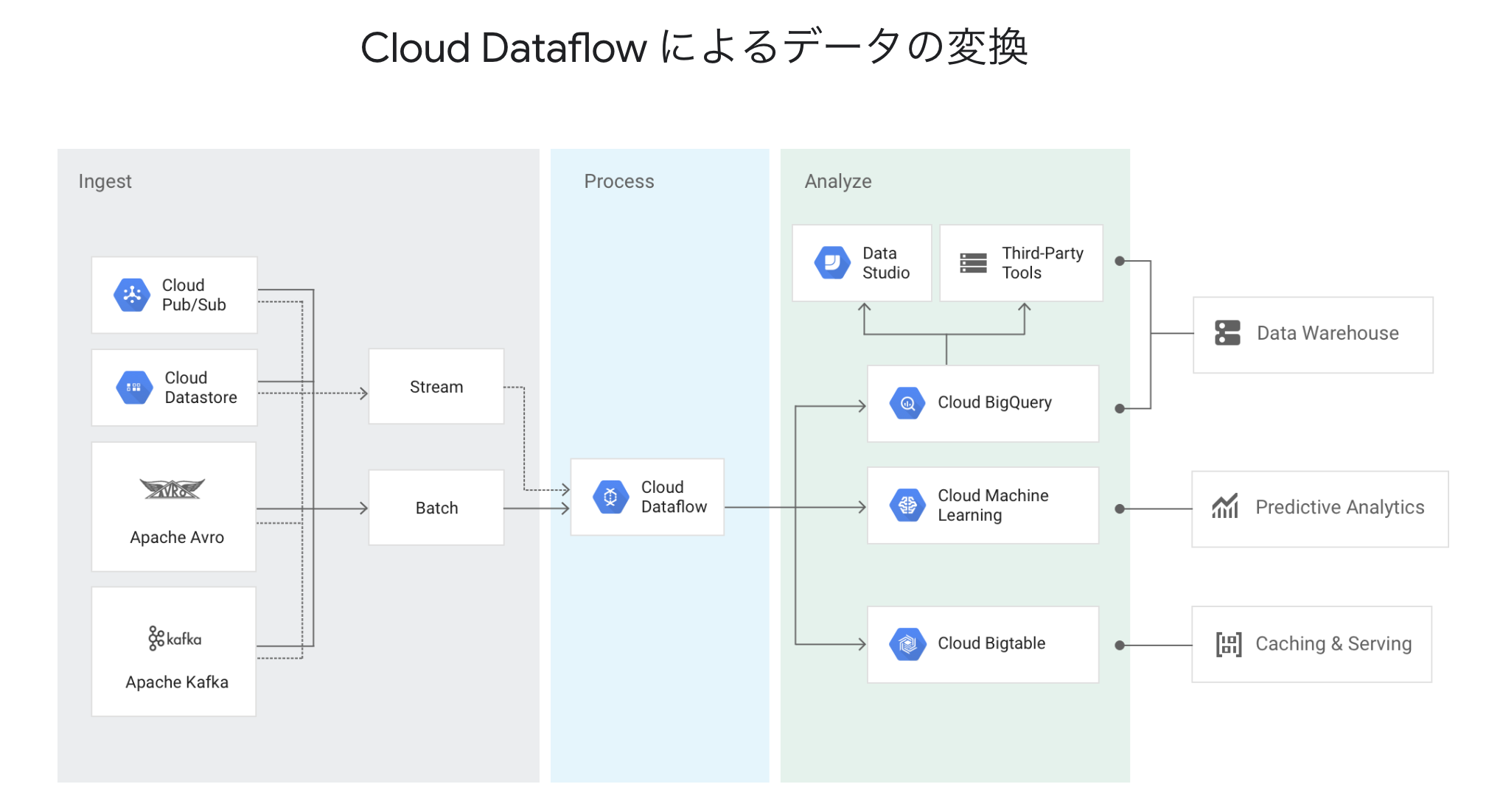
以下のフローのパイプラインを構築します.
- GCSに新規データをアップロード(今回)
- Cloud Pub/Subに通知が行く(今回)
- デプロイ済みのdataflowジョブが一定間隔でPub/SubトピックをPull(今回)
- dataflowパイプラインによる前処理
- ML Engineへのリクエスト
- dataflowパイプラインによる後処理
- GCSへの結果の保存(今回)
パイプライン構築
それでは構築の手順を書いていきます.
1. GCSバケットの準備
入力データをアップロードするためのバケットを用意します[1].
ここでは,dataflow-sampleというバケットを作成します.
作成されたバケットのURL:gs://dataflow-sample
2. Pub/Subの設定
イベント通知を受け取るためにPub/Subトピックを作成します[2].GCPコンソールのナビゲーションバーから作れるので,例えばgcs-notifyという名前でトピックを作成します.
今回はサブスクライバは使用しないので設定しなくても構いません.
3. Pub/Sub Notifications for GCSの設定
新しいデータがアップロードされた時にイベントを通知するように,先ほど作成したバケットに「Cloud Pub/Sub Notifications for Cloud Storage」を設定します[3].
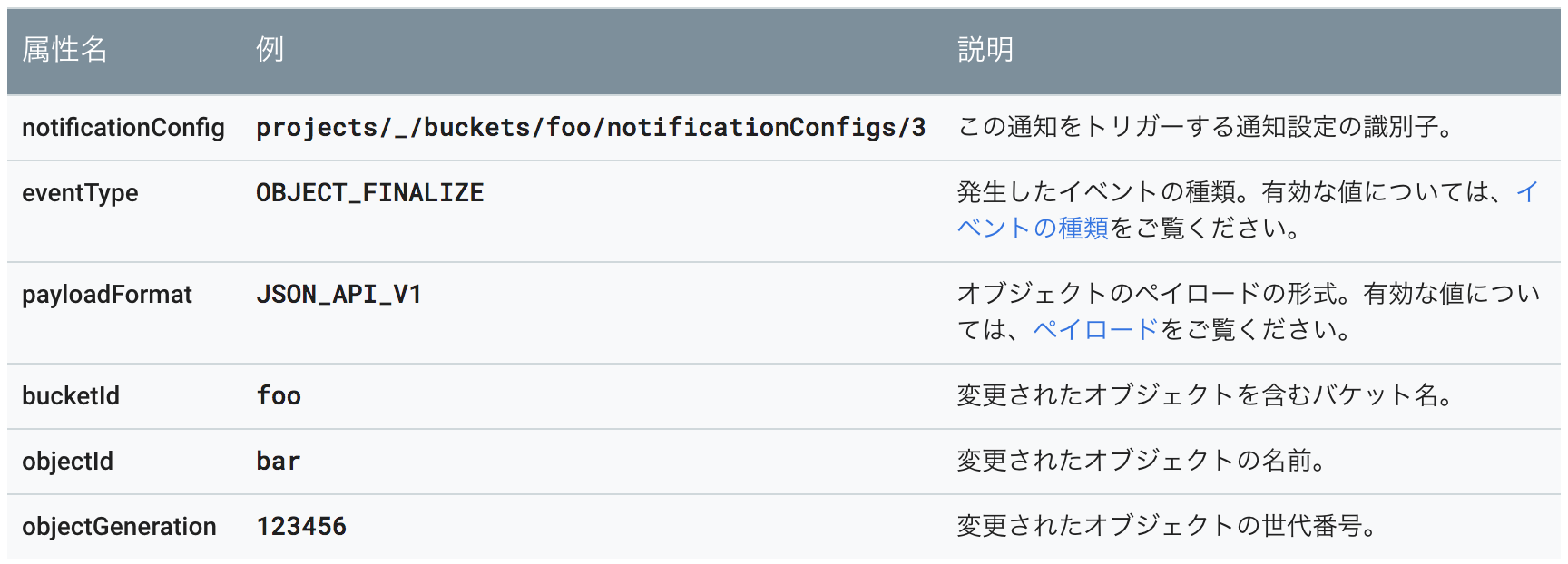
なお,本記事の執筆時点では以下の図ような種類のイベントを受信できますが,今回は新規ファイル作成のみをトリガーとしたいため,OBJECT_FINALIZEだけに設定するオプションも指定します.

また,同一バケット内に結果も保存したいため,イベント監視を行うフォルダの指定も行います.
以上の設定を含めたコマンドは以下の通りになります.
$ gsutil notification create -t [TOPIC_NAME] -f json -p [folder] -e OBJECT_FINALIZE gs://[BUCKET_NAME]
// 今回だと
$ gsutil notification create -t gcs-notify -f json -p data/ -e OBJECT_FINALIZE gs://dataflow-sample
設定を確認したいときは以下のコマンドを打ちます.
$ gsutil notification list gs://[BUCKET_NAME]
これで,設定したバケットに対してファイルがアップロードされると,Pub/Subにその情報が送信され,メッセージの形式でgcs-notifyトピックに追加されます.
4. dataflowテンプレートの作成
Pub/Subのイベント発生をトリガーとしてdataflowジョブを実行したいわけですが,これには色々な方法があると思います.
- dataflowジョブの実行をハンドルしたサーバ(GAEなど)をPub/Subのサブスクライバとして設定し,起動しておく方法
- Pub/SubからのPush通知をトリガーにジョブが走る.
- ストリーミング処理のdataflowテンプレートからジョブを作成し,一定間隔でPub/Subトピックをpullして実行する方法
- ジョブは常に起動状態になる
今回はdataflowテンプレートからストリーミング処理のジョブを起動する方法をとります.
dataflowについて [4]
パイプライン実装はGoogleが開発を進めているapache beamを使って行い,そのRunnerとしてGCP上で指定できるのが,dataflowです.apache beam自体はMapReduceの考え方を改善して書きやすくなっており,色々なrunnerで実行できます.dataflow自体もスケーラブルで分散処理の性能に優れており,使い方さえ覚えたらすごい便利なんじゃないでしょうか.
※とは言え,分散処理初心者にとっては結構学習コストが高いと思います.
python SDK
執筆時点では,pythonはバージョン2.7にしか対応しておらず,またPub/Subからの入力がうまくいかなかったり,色々と問題が多かったのでpythonでやるのはあまりお勧めできません.
筆者も最初はpythonで実装していましたが,分散処理初学者にとってdataflow自体の学習コストが高い上に,解決されてないissueに何度も遭遇するので,諦めて安定しているJavaに切り替えたら,ほぼ問題が起こらず開発できました.
Java SDK
javaの場合は比較的安定していてドキュメントも多いと思います。
公式ドキュメントはmavenを使っていますが,使いにくいのでgradleでビルドするようにします参考文献.
build.gradleのdependenciesに以下を追加すればいいです.
compile group: 'com.google.cloud.dataflow', name: 'google-cloud-dataflow-java-sdk-all', version: '2.5.0'
パイプラインの実装
本記事では,Pub/Subトピックから30秒ごとにメッセージをPullして,メッセージの中身から新規作成された画像ファイルのパスを取り出し,クロップしてGCSに保存するところまで実装します.apache beam自体の説明についてはドキュメント(参考文献[5][6])を参考にしてください.
コードは以下のようになります.
public class PubsubToText {
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.create();
DataflowPipelineOptions dataflowOptions = options.as(DataflowPipelineOptions.class);
dataflowOptions.setRunner(DataflowRunner.class);
dataflowOptions.setProject("dataflow-sample");
dataflowOptions.setStagingLocation("gs://dataflow-sample-bucket/staging");
dataflowOptions.setTemplateLocation("gs://dataflow-sample-bucket/templates/MyTemplate");
dataflowOptions.setStreaming(true);
dataflowOptions.setNumWorkers(1);
run(dataflowOptions);
}
public static PipelineResult run(DataflowPipelineOptions options) {
String topic = "projects/dataflow-sample/topics/gcs-notify";
String output = "gs://dataflow-sample-result/output.txt";
Pipeline p = Pipeline.create(options);
/*
* Steps:
* 1) Read string messages from PubSub
* 2) Window the messages into minute intervals specified by the executor.
* 3) Output the windowed files to GCS
*/
p.apply("Read PubSub Events", PubsubIO.readMessagesWithAttributes().fromTopic(topic))
.apply( "30s Window",
Window.into(FixedWindows.of(Duration.standardSeconds(60))))
.apply("Load Image", ParDo.of(new LoadImageFn()))
.apply("Write File(s)", TextIO.write()
.withWindowedWrites()
.withNumShards(1)
.to(output));
return p.run();
}
}
重要な点は,ストリーミング処理にするためにdataflowOptions.setStreaming(true)でオプションを指定する点と,パイプライン実装の際に時間間隔のwindowを設定していることです.
Cloud Pub/Sub Notifications for Cloud Storageで通知されるメッセージは以下のようなフォーマットになっています.自作のメソッドで,ここから必要な情報を取り出し,取得したGCS上のパスから画像を読み込んでクロップし,resultディレクトリ以下に保存する処理を書いています.
public class LoadImageFn extends DoFn<PubsubMessage, String> {
@ProcessElement
public void processElement(@Element PubsubMessage m, OutputReceiver<String> out) {
Map<String, String> attr = m.getAttributeMap();
Storage storage = StorageOptions.getDefaultInstance().getService();
BlobId blob = BlobId.of(attr.get("bucketId"), attr.get("objectId"));
byte[] content = storage.readAllBytes(blob);
InputStream is = new ByteArrayInputStream(content);
BufferedImage img = null;
try {
img = ImageIO.read(is);
} catch (IOException e) {
e.printStackTrace();
}
// 切り取り始める座標
int X = 50;
int Y = 50;
// 切り取るサイズ
int W = 100;
int H = 100;
BufferedImage subimg; // 切り出し画像格納クラス
try {
assert img != null;
subimg = img.getSubimage(X, Y, W, H);
}
catch ( RasterFormatException re ) {
System.out.println( "指定した範囲が画像の範囲外です" );
return;
}
BlobId blobId = BlobId.of(attr.get("bucketId"), "result/cropped_image.jpg");
BlobInfo blobInfo = BlobInfo.newBuilder(blobId).setContentType("image/jpeg").build();
ByteArrayOutputStream bos = new ByteArrayOutputStream();
BufferedOutputStream os = new BufferedOutputStream( bos );
try {
ImageIO.write(subimg, "jpeg", os);
} catch (IOException e) {
e.printStackTrace();
}
storage.create(blobInfo, bos.toByteArray());
out.output(String.valueOf(img.getHeight()));
}
}
ちなみに,動画の場合もGCSクライアントとJavaCVを使えばできます(ffmpegの処理をdataflowに含めたい,という場面は多いと思うので),
これでローカルでプログラムを実行すると,dataflowOptions.setTemplateLocation("gs://dataflow-sample-bucket/templates/MyTemplate")で指定したGCSのバケットにテンプレートのファイルが作成されます.
$ gradle run
5. テンプレートからdataflowジョブの作成
手順
- GCPのコンソールへ行き,ナビゲーションメニューからDataflowを選択します
- 「テンプレートからジョブを作成」を選択します
- テンプレートのタイプとしてカスタムテンプレートを選び,先ほど作成したdataflowテンプレートファイルのGCSパスを入力します
- ジョブ名も入力してジョブの実行をする
- パイプラインが正しくビルドされて以下の図のように表示されたら完了
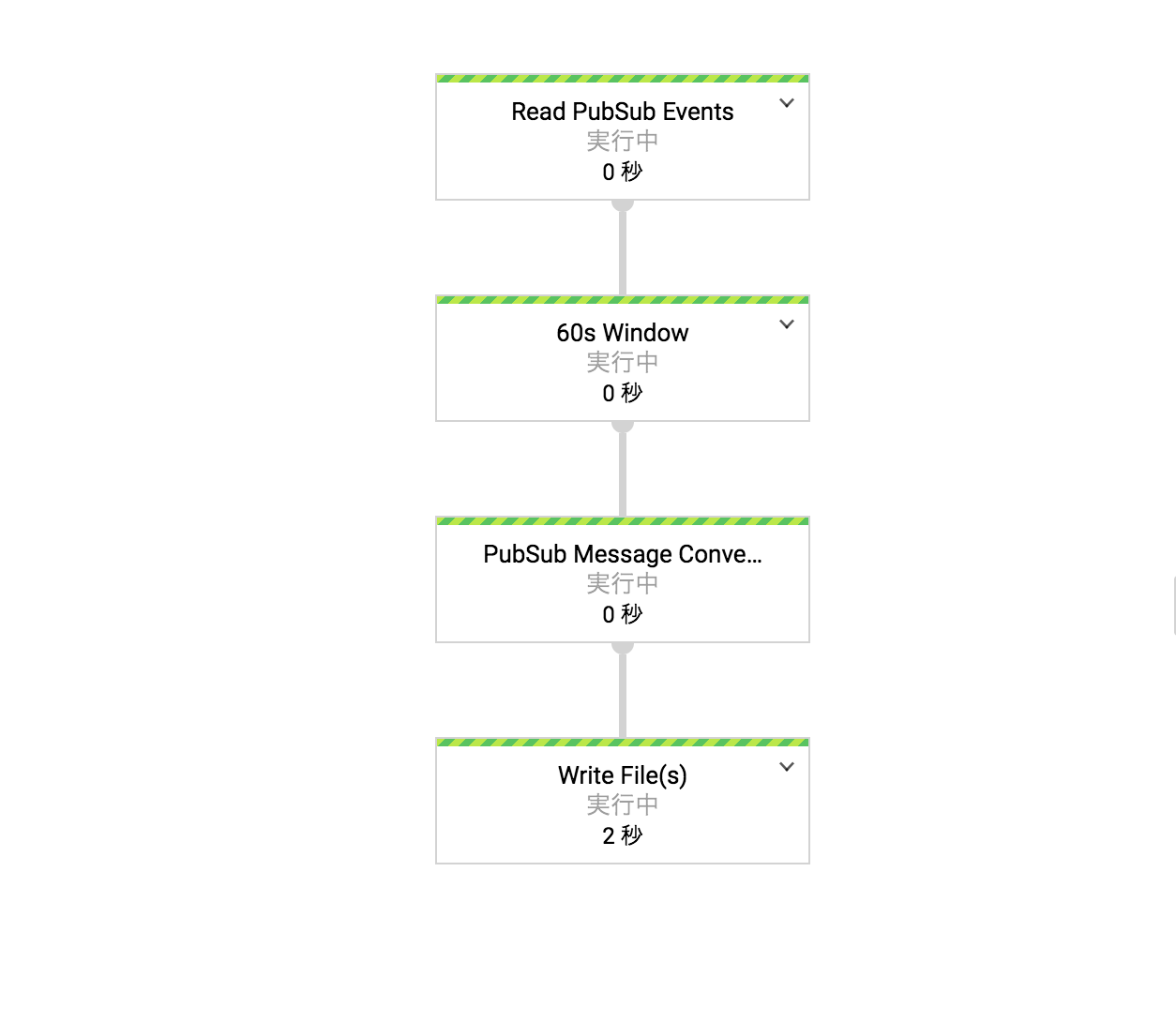
GCSに新しいファイルをアップロードした時に,ジョブが走るか確認します.ストリーミング処理で30秒ごとにトピックをPullするようにしているので,少し待つ必要があります.
ジョブの実行が完了したらGCSにクロップした画像ができていればOKです.ストリーミング処理のdataflowジョブなので,一つのジョブが完了しても閉じず,再度ファイルアップロードを行ったらジョブが走ります.動作を確認してみてください.
まとめ
GCSへ新規ファイルがアップロードされてからPubSubに通知され,Dataflowジョブが走ってGCSに結果を保存するところまでを行いました.
「Cloud Pub/Sub Notifications for Cloud Storage」からのメッセージに書かれたパスから画像を読み取り,GCSに保存するところまでの処理をdataflowパイプラインで書いたので,あとは前処理,予測,後処理を行うパイプラインを追加すれば,ML全体のパイプラインの完成になります.ML Engine等の使用も必要になるので,これらの構築はまた別の機会に記事にしようと思います.
参考文献
[1] https://cloud.google.com/storage/docs/
[2] https://cloud.google.com/pubsub/docs/
[3] https://cloud.google.com/storage/docs/pubsub-notifications
[4] https://cloud.google.com/dataflow/docs/
[5] https://beam.apache.org/documentation/
[6] https://beam.apache.org/documentation/programming-guide/