はじめに
はじめまして。
tit_BTCQASH と申します。(https://twitter.com/tit_BTCQASH
Numeraiというプロジェクトでわかりにくい点とその解説、予測結果のサブミットまでを一気通貫して紹介します。(https://numer.ai/tournament
Numeraiは株価の予測結果をもとに運用するヘッジファンドの手伝いをするプロジェクトです。
私たちは自分でデータを用意する必要はなく、チームから与えられたデータを最適化し、その予測結果を提出することが求められます。
(日本ではblog_UKIさんの記事 機械学習による株価予測 はじめようNumerai
https://qiita.com/blog_UKI/items/fb401725288e58c92bd6
が有名ですので、詳細はそちらをご一読ください。)
さて、本記事ではNumeraiのホームページの見方から、Google Colaboratoryを用いた予測結果の提出方法まで、できるだけ丁寧に解説します。
わからない点、加筆した方がよい点は遠慮なくtwitter等までご連絡ください。
本記事の目次
①Numeraiのホームページの見方
②Numeraiチームから与えられた特徴量(説明変数)と株価データを最適化し、予測を提出する方法
③numerai関連の便利リンク集(追記予定 コメントください)
④DIAGNOSTICSの見方
⑤Numeraiに望むこと
⑥さいごに
①Numeraiのホームページの見方
NumeraiのホームページのURLは https://numer.ai/tournament
です。色々とコンテンツがありますが、一つ一つ解説していきます。
頻出する用語について
NMRトークン:Numeraiで使用する掛け金に相当するERC-20ベースの仮想通貨のことです。
NMRはNumeraiのペイアウトや、Numeraiへの技術的貢献をすることで発行されます。最初にNMRトークンを手に入れるためには取引所で購入するのが手っ取り早いです。
ただし、日本の取引所では取り扱いがないため購入は不可能です。NMRトークンを取り扱っている取引所はこちらのリンクに一覧があります。
https://coinmarketcap.com/ja/currencies/numeraire/
DEX系の取引所では、UniswapやCoinlistを使用することもできます。
Uniswap:https://uniswap.org/
Coinlist:https://coinlist.co/dashboard
NMRトークンはNumerai以外にもerasureで使用することができます。https://erasure.world/
correlation:提出した株価の予測結果と、解答の相関係数のこと 大きければ大きいほど報酬が増えます。
Reputation:correlationの20ラウンド平均値
MMC:Meta Model Contributionの略。自分のモデルから、MMCモデル(Numeraiに提出されている予測結果を加重平均したモデル)の寄与を除いたものが、どれだけ解答との相関があるかを表す相関係数。MMCモデルに比べて優位な結果では+のMMCとなります。
ステーク:NMRを預け入れること
Payouts:賭けたNMRに応じて貰える報酬のこと
HP上部

DOCS:Numeraiのドキュメントへのリンク(英語版)ドキュメント内にはNumeraiのルールなどが解説されています。日本語への翻訳も進んでおり、https://jp.docs.numer.ai/
に翻訳版がありますが、翻訳は途中のようです。
CHAT:Numeraiに関する情報や、雑談、フィードバック等のチャットスペースです。英語のみ対応(日本語版はなし。)
FORUM:Numeraiに関する議論をするスペース コミュニティとの情報共有化がメイン。英語のみ対応(日本語版はなし)
LEADERBOARD:Numeraiに提出した株価の予測結果のランキング
ACCOUNT:WALLET MODELS SETTINGS LOGOUT の4つのリンクがあります。
WALLET:NMRトークンの入出金に関するページです。Wallet addressにあるアドレスにBinance等で入手したNMRトークンを送付すると、預入ができます。withdrawタブでは、NMRトークンに引き出しができます。
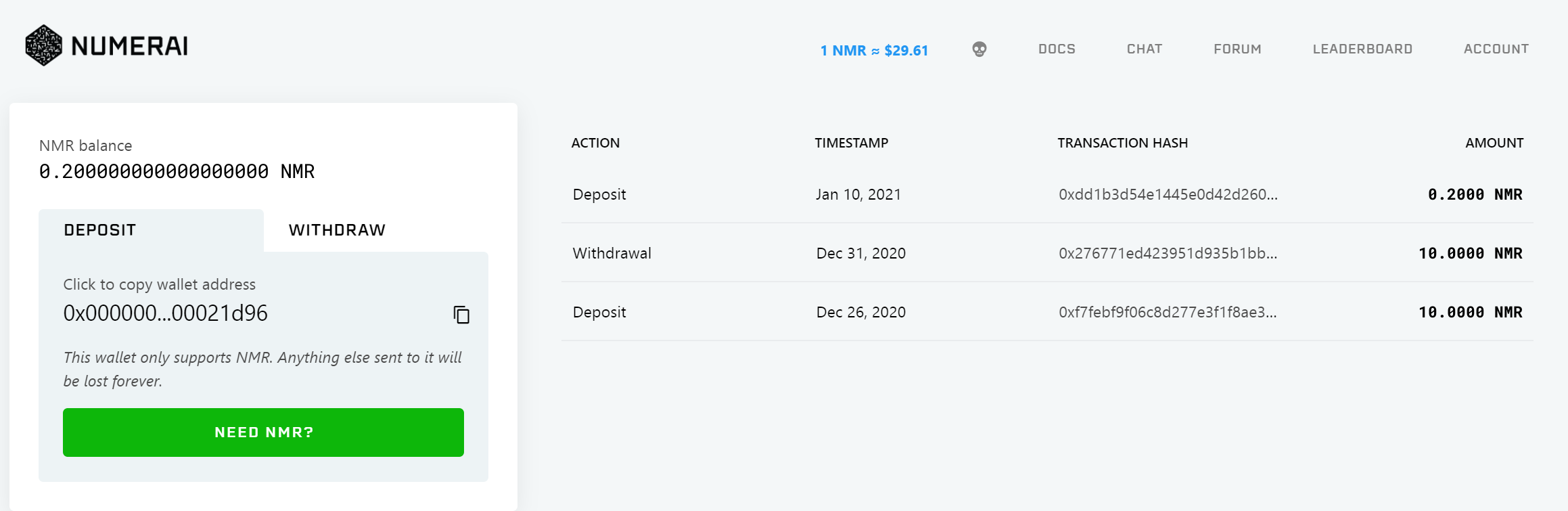
MODELS:Numeraiに提出するモデルの追加・削除をするページです。ADD NEW MODEL/ABSORB EXISTING ACCOUNTを押すことで、モデルの追加/削除ができます。
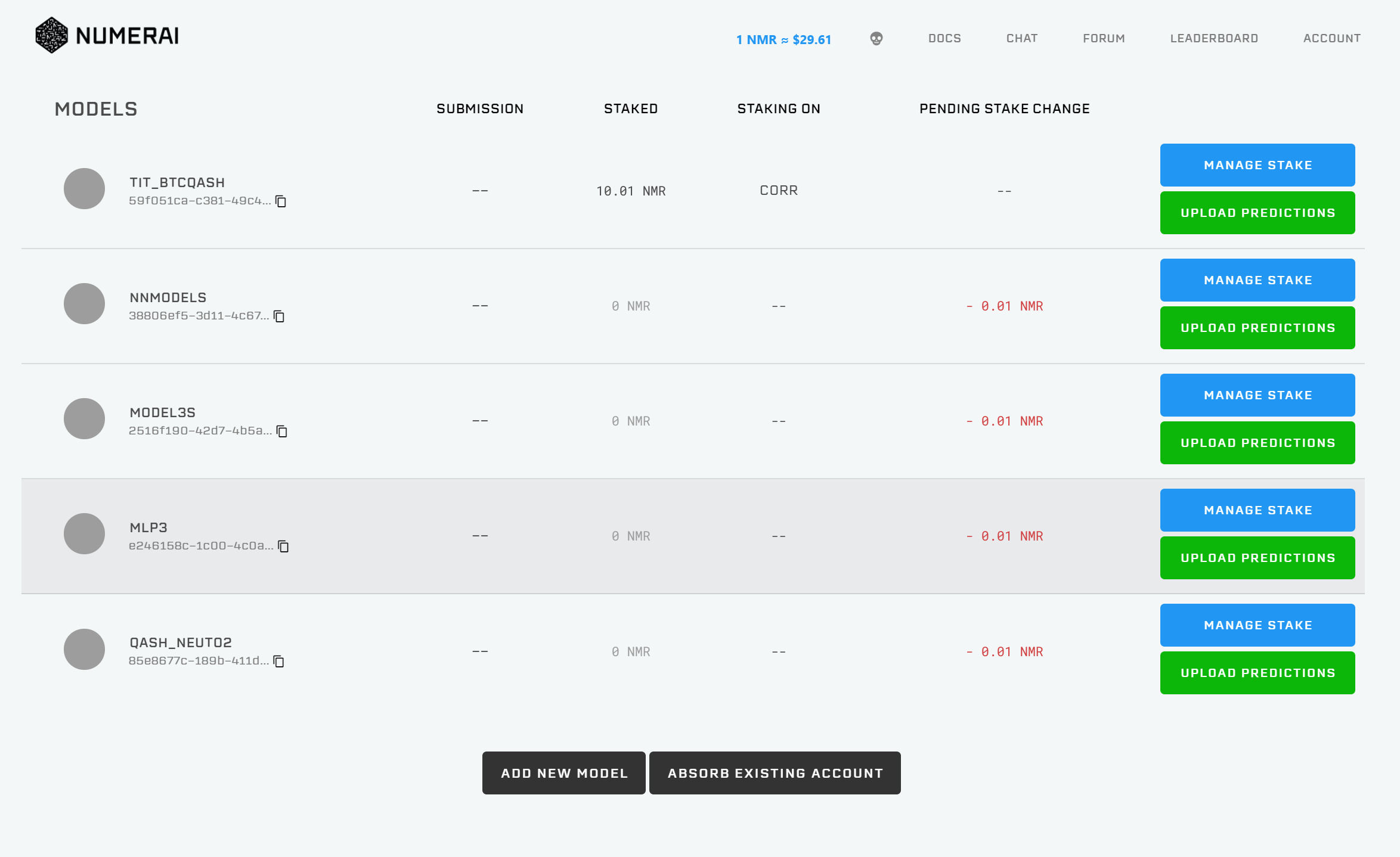
SETTINGS:E-mail,Password,2段階認証の設定や、APIキーの設定に関するページです。
HP下部
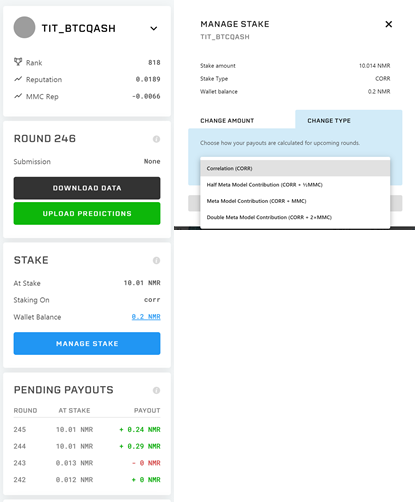
モデル情報:モデル(今回はTIT_BTCQASH)のランキング、Reputation、MMC Repに関するページです。↓ボタンを押すとモデルの切り替えができます。
データ情報:最新のラウンドのデータダウンロードリンクと、予測結果のアップロードリンク。
ステークNMRトークンの預け入れに関する設定 Manage Stakeから、今回のラウンドに賭けるNMRの量を設定することができます。
CorrやCorr+MMCなど、異なる種類のステーク方法が用意されており、例えばCorrではcorrelationにのみNMRを賭け、Corr+MMCではcorrelationとMMCにNMRを賭けることができます。
Pending Payouts ラウンド毎の払い出し予測値の表。貰える予定の報酬量についてのまとめです。
②Numeraiチームから与えられた特徴量(説明変数)と株価データを最適化する方法
何もわからない状態で、Numeraiのデータを提出する場合、katsu1110さんの記事
https://www.kaggle.com/code1110/numerai-tournament
や、Carlo Lepelaarsさんの記事
https://www.kaggle.com/carlolepelaars/how-to-get-started-with-numerai
が非常に参考になります。
今回、私が紹介する記事では、上記の記事や公式が出しているExample modelから一歩踏み込んだ解説(コードでどこを改良するか、など)と、ボタンを押せば予測データが手に入るサンプルコードの提供をしたいと思います。
本記事を読んで、少しでもモデルの提出数が増えるといいなあ、と思っています。
(良いcorrの上げ方などを見つけたら、こっそり教えてください)
今回紹介したコードは、Google colaboratory上で動かせます。Runボタンを押せば、提出ファイルができるようにしてあるので、
使用してみてください。
https://colab.research.google.com/drive/1u5Cc3NlJQZJwJNmOrPjjqBchk928gT4C?usp=sharing
コードを解説する前の基礎編
i)Numeraiデータセットの構造
データセットは最新のラウンドのデータダウンロードリンクからダウンロードできます。(本記事上部参照)
前述したUKIさんの記事(https://qiita.com/blog_UKI/items/fb401725288e58c92bd6
に詳しい解説がのっていますので、簡単に中身について記述しておきます。
numerai_training_data.csvはトレーニング用のデータが入っているcsvファイルです。
numerai_tournament_data.csvはバリデーション(検証)用のデータが入っているcsvファイルです。
(csvファイルの中身)
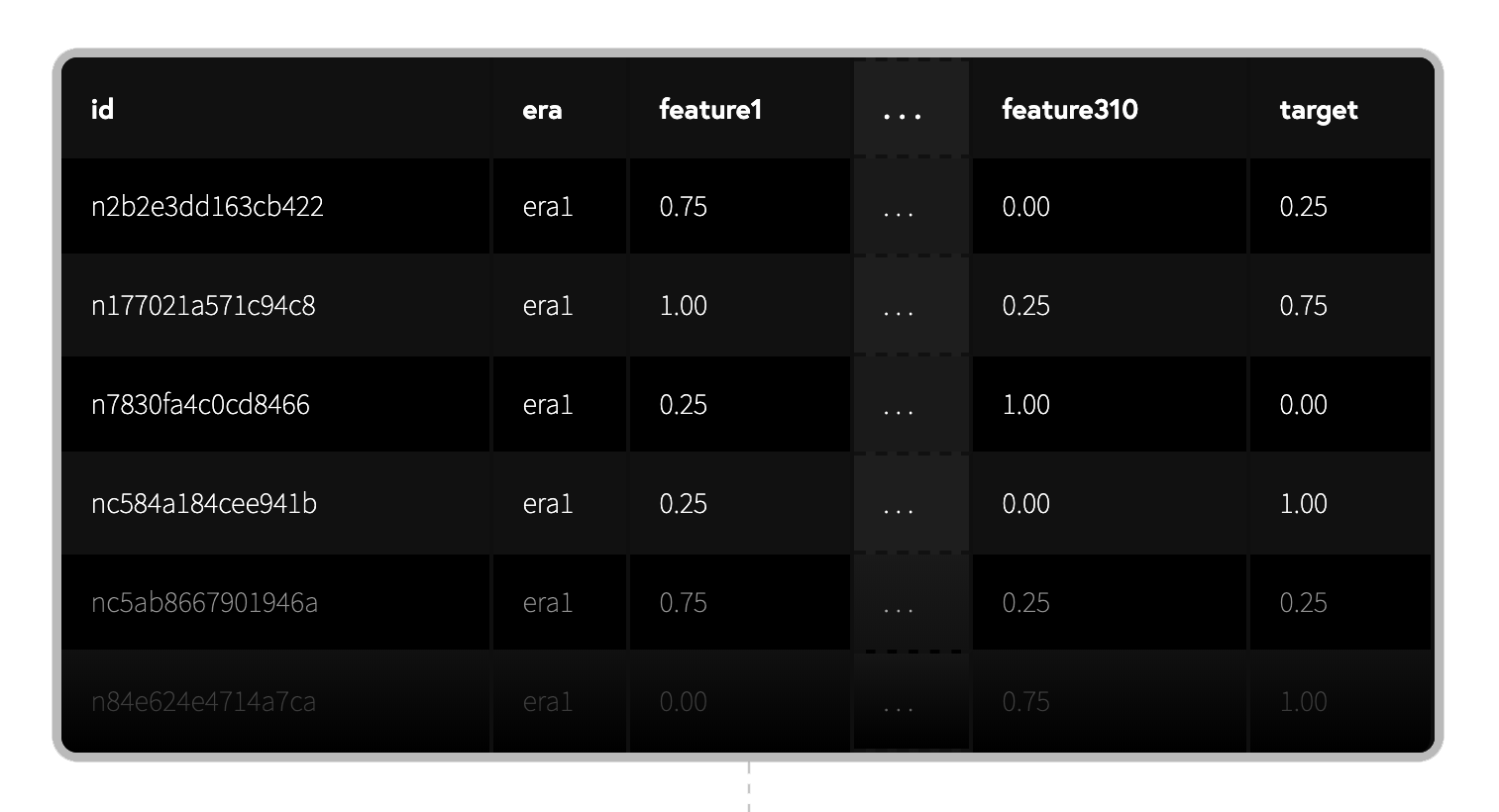
id:暗号化された株に関するラベル。
era:データが収集された期間に関するラベル。eraが同じなら、同じ期間に収集されたデータであることを表します。
data_type:train,validation,test,liveの4つの値があります。trainはトレーニング用のデータ、validationは検証用のデータ、testはNumeraiがテストする用のデータ、liveは現ラウンドのデータとなっています。
feature:ビン化された特徴量。0,0.25,0.5,0.75,1の5分位となっている。featureは"feature_intelligence", "feature_wisdom", "feature_charisma", "feature_dexterity", "feature_strength", "feature_constitution"とタグ付けされたものがあり、グループ化されています。
target:ビン化された教師データ。0,0.25,0.5,0.75,1の5分位となっています。numerai_training_data.csvではtargetデータがあたえられているが、numerai_tournament_data.csvのliveデータではNANになっています。
ii)データ提出までの流れ
①データの読み込み
②特徴量エンジニアリング
③機械学習
④モデルの強さについて
⑤予測結果を書きこんだcsvファイルの用意
⑥neutrizeの方法
①データの読み込み
Carlo Lepelaarsさんの記事からデータ読み込み部分を引用(一部編集)させていただきます。
download_current_data(DIR)を呼び出すと、DIRで指定したディレクトリに最新ラウンドのデータをダウンロードします。
train, val, test = load_data(DIR, reduce_memory=True)を呼び出すと、train, val, testデータに分けてデータを格納します。
!pip install numerapi
import numerapi
NAPI = numerapi.NumerAPI(verbosity="info")
import numpy as np
import random as rn
import pandas as pd
import seaborn as sns
import lightgbm as lgb
import matplotlib.pyplot as plt
from scipy.stats import spearmanr, pearsonr
from sklearn.metrics import mean_absolute_error
import os
DIR = "/kaggle/working"
def download_current_data(directory: str):
"""
Downloads the data for the current round
:param directory: The path to the directory where the data needs to be saved
"""
current_round = NAPI.get_current_round()
if os.path.isdir(f'{directory}/numerai_dataset_{current_round}/'):
print(f"You already have the newest data! Current round is: {current_round}")
else:
print(f"Downloading new data for round: {current_round}!")
NAPI.download_current_dataset(dest_path=directory, unzip=True)
def load_data(directory: str, reduce_memory: bool=True) -> tuple:
"""
Get data for current round
:param directory: The path to the directory where the data needs to be saved
:return: A tuple containing the datasets
"""
print('Loading the data')
full_path = f'{directory}/numerai_dataset_{NAPI.get_current_round()}/'
train_path = full_path + 'numerai_training_data.csv'
test_path = full_path + 'numerai_tournament_data.csv'
train = pd.read_csv(train_path)
test = pd.read_csv(test_path)
# Reduce all features to 32-bit floats
if reduce_memory:
num_features = [f for f in train.columns if f.startswith("feature")]
train[num_features] = train[num_features].astype(np.float32)
test[num_features] = test[num_features].astype(np.float32)
val = test[test['data_type'] == 'validation']
test = test[test['data_type'] != 'validation']
return train, val, test
# Download, unzip and load data
download_current_data(DIR)
train, val, test = load_data(DIR, reduce_memory=True)
②特徴量エンジニアリング
Numeraiデータセットの特徴量はそれぞれの相関が低く、特徴量エンジニアリングをしなくとも、ある程度の結果が出せます。
また、PDAなどの手法を用いて特徴量を削減すると、Corrが低くなる傾向があり、あまりよくありません。
(*あくまで、私が検証した結果です。Corrが良くなる可能性を否定しているわけではありません)
Numeraiにおいて効果的なことは、特徴量を増やしつつ、特徴量同士の相関を減らすことだと考えています。
公式曰く、特徴量を310個から3100個に増やす(https://twitter.com/numerai/status/1347361350205415425
らしいので、これからは特徴量エンジニアリングすら不要になるかもしれませんが、どうやって特徴量を扱うかを軽く紹介します。
まずは、trainデータを眺めていると、"feature_intelligence", "feature_wisdom", "feature_charisma", "feature_dexterity", "feature_strength", "feature_constitution"の6種類に大別されることがわかります。
Carlo Lepelaarsさんの記事からコードを引用しますが、これらのfeatureの平均値や偏差、歪度などは有用な特徴量になります。
そこで、train = get_group_stats(train)を呼び出し、trainデータなどにこれらの特徴量を追加します。
def get_group_stats(df: pd.DataFrame) -> pd.DataFrame:
for group in ["intelligence", "wisdom", "charisma", "dexterity", "strength", "constitution"]:
cols = [col for col in df.columns if group in col]
df[f"feature_{group}_mean"] = df[cols].mean(axis=1)
df[f"feature_{group}_std"] = df[cols].std(axis=1)
df[f"feature_{group}_skew"] = df[cols].skew(axis=1)
return df
train = get_group_stats(train)
val = get_group_stats(val)
test = get_group_stats(test)
メモリに余裕があるPCをお持ちの方は、featureの差分データや、交互作用特徴量、などを入れるとよい特徴量になります(20%くらいはcorrが上がります)。
Google colaboratoryでRunをかけるとクラッシュするので、コードのみを載せますが、
from sklearn import preprocessing
ft_corr_list=['feature_dexterity7', 'feature_charisma18', 'feature_charisma63', 'feature_dexterity14']#ft_corr_listは交互作用特徴量を作りたいものを入れる。
interactions = preprocessing.PolynomialFeatures(degree=2, interaction_only=True, include_bias=False)
interactions.fit(train[ft_corr_list], train["target"])
X_train_interact = pd.DataFrame(interactions.transform(train[ft_corr_list]))
X_best_val_inter =pd.DataFrame(interactions.transform(val[ft_corr_list]))
X_best_test_inter =pd.DataFrame(interactions.transform(test[ft_corr_list]))
train=pd.concat([train,X_train_interact],axis=1)
val=val.reset_index().drop(columns='index')
val=pd.concat([val,X_best_val_inter],axis=1)
test=test.reset_index().drop(columns='index')
test=pd.concat([test,X_best_test_inter],axis=1)
を追加すればよいです。
Kaggle等で使われるような特徴量エンジニアリングがそのままNumeraiでは使えるので、train,val,testのデータを弄ることで、良いCorr、シャープレシオが得られます。
Numeraiでよい結果を得るために必要な作業の一つが、特徴量エンジニアリングなので、この部分がやりこみ要素の一つです。
③機械学習
Numeraiデータセットを機械学習にかける上で検討する必要があるのは、
i)どんな機械学習の手法を用いるか(LightGBM,XGBoost,NLPなど)
ii)どんなハイパーパラメーターを使用するか
iii)予測結果のスタッキングをするか
などです。
今回は、計算時間を考えてLightGBMを使用します。trainデータの中でもidやera,data_typeは機械学習に必要がないので除き、
残りのfeature_○○を説明変数、targetを教師データとして学習させます。学習させたデータを用いて、valに含まれるValidationデータやLiveデータについても予測データを作ります。
i)~iii)について検討すればCorr等の値がよくなりますので、この部分もやりこみ要素の一つです。
dtrain = lgb.Dataset(train[train.columns.drop('id').drop('era').drop('data_type').drop('target')].fillna(0), label=train["target"])
dvalid = lgb.Dataset(val[train.columns.drop('id').drop('era').drop('data_type').drop('target')].fillna(0), label=val["target"])
best_config ={"objective":"regression", "num_leaves":31,"learning_rate":0.01,"n_estimators":2000,"max_depth":5,"metric":"mse","verbosity": 10, "random_state": 0}
model = lgb.train(best_config, dtrain)
train.loc[:, "prediction"] = model.predict(train[train.columns.drop('id').drop('era').drop('data_type').drop('target')])
val.loc[:,"prediction"]=val["target"]
val.loc[:,"prediction"] = model.predict(val[train.columns.drop('id').drop('era').drop('data_type').drop('target')])
④モデルの強さについて
Validationデータにおける、モデルの強さを推定するために、spearman, payout, numerai_sharpe, maeを算出します。spearman, payout, numerai_sharpeは大きければ大きいほど良いです。
この中でも、まずはspearmanの値が大きい(0.025以上が目安)条件を見つけるといいモデルが作れます。
(*Corr重視だけだといろいろと問題が起きることもあります。
Numeraiになれている方には異論があると思いますが、あくまでも「はじめて」予測結果をサブミットする人向けの記事なので、このくらいの表現にさせてください)
用語の説明は以下です。
spearman:Correlationの平均値 高いほど良い(目安は0.022~0.04)
payout:平均リターン
numerai_sharpe:平均リターンを標準偏差で割った比率のこと。高いほど良い(目安は1以上)
mae:平均絶対誤差
def sharpe_ratio(corrs: pd.Series) -> np.float32:
"""
Calculate the Sharpe ratio for Numerai by using grouped per-era data
:param corrs: A Pandas Series containing the Spearman correlations for each era
:return: A float denoting the Sharpe ratio of your predictions.
"""
return corrs.mean() / corrs.std()
def evaluate(df: pd.DataFrame) -> tuple:
"""
Evaluate and display relevant metrics for Numerai
:param df: A Pandas DataFrame containing the columns "era", "target_kazutsugi" and a column for predictions
:param pred_col: The column where the predictions are stored
:return: A tuple of float containing the metrics
"""
def _score(sub_df: pd.DataFrame) -> np.float32:
"""Calculates Spearman correlation"""
return spearmanr(sub_df["target"], sub_df["prediction"])[0]
# Calculate metrics
corrs = df.groupby("era").apply(_score)
print(corrs)
payout_raw = (corrs / 0.2).clip(-1, 1)
spearman = round(corrs.mean(), 4)
payout = round(payout_raw.mean(), 4)
numerai_sharpe = round(sharpe_ratio(corrs), 4)
mae = mean_absolute_error(df["target"], df["prediction"]).round(4)
# Display metrics
print(f"Spearman Correlation: {spearman}")
print(f"Average Payout: {payout}")
print(f"Sharpe Ratio: {numerai_sharpe}")
print(f"Mean Absolute Error (MAE): {mae}")
return spearman, payout, numerai_sharpe, mae
feature_spearman_val = [spearmanr(val["prediction"], val[f])[0] for f in feature_list]
feature_exposure_val = np.std(feature_spearman_val).round(4)
spearman, payout, numerai_sharpe, mae = evaluate(val)
⑤予測結果を書きこんだcsvファイルの用意
neutrize用ファイルをsubmission_file.csvに書き込みます。このファイルは、id,predictionカラムが必須であり、idはValidationデータ、testデータ(+Liveデータ)の順番であることが求められます。順番が異なるとNumerai側ではじかれるので気を付けてください。
test.loc[:, "prediction"] =0
test.loc[:, "prediction"] = model.predict(test[feature_list])
test[['id', "prediction"]].to_csv("submission_test.csv", index=False)
val[['id', "prediction"]].to_csv("submission_val.csv", index=False)
test=0
val=0
directory = "/kaggle/working"
full_path = f'{directory}/numerai_dataset_{NAPI.get_current_round()}/'
test_path = full_path + 'numerai_tournament_data.csv'
tournament_data = pd.read_csv(test_path)
tournament_data_id=tournament_data['id']
tournament_data_id2=tournament_data['feature_dexterity7']
tournament_data_id=pd.concat([tournament_data_id,tournament_data_id2],axis=1)
val=pd.read_csv("submission_val.csv")
test=pd.read_csv("submission_test.csv")
test_val_concat=pd.concat([val[['id', "prediction"]],test[['id', "prediction"]]],axis=0).set_index('id')
tournament_data_id=tournament_data_id.set_index('id')
conc_submit=pd.concat([tournament_data_id,test_val_concat],axis=1).drop(columns='feature_dexterity7').reset_index()
conc_submit=conc_submit.rename(columns={'index': 'id'})
conc_submit.to_csv("submission_file"+".csv", index=False)
⑥neutrize
Example_model(Numeraiが公式に配布しているサンプルモデル)と自分のモデルを線形回帰することで、
単一の特徴量と予測結果の相関性を下げつつ、シャープレシオの改善ができます。ただ、やりすぎるとCorrが大幅に下がるので、0.3~0.5程度がよいと思います。
どんなモデルをneutrizeするか、どのくらいneutrizeするか、という部分がやりこみ要素の一つです。
def neutralize(series,by, proportion):
scores = series.values.reshape(-1, 1)
exposures = by.values.reshape(-1, 1)
exposures = np.hstack((exposures, np.array([np.mean(series)] * len(exposures)).reshape(-1, 1)))
correction = proportion * (exposures.dot(np.linalg.lstsq(exposures, scores)[0]))
corrected_scores = scores - correction
neutralized = pd.Series(corrected_scores.ravel(), index=series.index)
return neutralized
by=pd.read_csv('/kaggle/working/numerai_dataset_'+str(NAPI.get_current_round())+'/example_predictions.csv')
neut=pd.read_csv("submission_file.csv")
neut=pd.DataFrame({'prediction':neutralize(neut['prediction'],by['prediction'], 0.3)})#ここを弄ると、Neutralizeの量を変化させることができる。
conc=pd.concat([by.drop(columns="prediction"),neut],axis=1)
conc.to_csv("neutralized_submission_file.csv", index=False)#提出ファイル
得られたneutralized_submission_file.csvをNumeraiホームページのUpload predictions から提出すれば完了です。
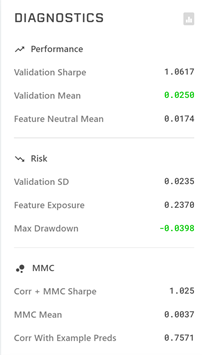
DIAGNOSTICSの見方
Validation Sharpe:Validationデータでのシャープレシオ 1以上だと良い
Validation Mean: ValidationデータでのCorr平均値 0.025~くらいあると良い
Feature Neutral Mean:全特徴量についてneutralizeした時のCorr平均値(あまり参考にしていない)
Validation SD:Validationデータと予測値のEra毎の相関性の標準偏差(あまり参考にしていない)
Feature Exposure:特徴量と予測結果がどれだけバランスがとれているかを表す指標 小さいほど良い
Max Drawdown 最大ドローダウン -0.05以下くらいが目安
Corr + MMC Sharpe:CorrとMMCを合わせたシャープレシオ
MMC Mean:MMCの平均値
Corr With Example Predsサンプルモデルとの相関 0.5~0.8程度が目安
numerai関連の便利リンク集(追記予定 コメントください)
自分がどのくらいの順位か簡易的にわかるツール
https://dashboard.numeraipayouts.com/
ペイアウトの合計を算出するツール
https://apps.apple.com/app/id1522158691
Numerai Advent Calendar 2020(Corrを上げる方法などの情報集 @kunigakuさん主催)
https://adventar.org/calendars/5031
numerati
https://github.com/woobe/numerati
Numeraiに望むこと
①NMRは草コインであるため、価格が安定しません。20~60USD程度で価格が振れるので、参入時期によってはNumeraiに提出したモデルが優秀でも、NMRトークンが値下がり、損失を出す可能性があります。トークン価格が安定してくれると嬉しいです。
②日本語文献が少ない。フォーラムを追っていないと、機能の変更があってもすぐに対応ができません。(例えば、パラメーターの計算方法が変更になった時 https://forum.numer.ai/t/model-diagnostics-update/902
日本語記事の拡充や、ホームページが日本語化されると嬉しいです。(現状、対応中らしいですが・・・。)
さいごに
私自身は800位程度と、そこまで上位ではないですが、+のリターンになっています。
https://numer.ai/tit_btcqash
今回載せたコードとはかなり異なりますが、Corrをある程度維持しつつ、Neutralizeを7種類かけたモデルを使用しています。
10NMRくらいくれたらコードの入った.ipynbファイルを渡すので、興味ある人がいればお声かけください。
チップ用
NMR:0x0000000000000000000000000000000000021d96