ツイートを取得
ワード「渋滞」を含むツイートを取得しました。
シルバーウイウーク三連休最終日2021年9月20日(月)以降、取得ツイート数は最大10,000としました。
前回同様の手順で取り込みました。
#TwitterAPI認証情報設定
consumerKey <- "************"
consumerSecret <- "*****************"
accessToken <- "*****************"
accessSecret <- "*********************"
##TwitterAPIにログイン
library("twitteR")
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#「渋滞」を含む日本語ツイートを10000件取得。2021年5月19日から
tweets2 <- searchTwitter('渋滞', n = 10000, since = "2021-09-20" , lang="ja" , locale="ja")
#データフレームに変換
tweetsdf2 <- twListToDF(tweets2)
#型を確認
class(tweets2)
[1] "data.frame"
#取得できたか確認
library(dplyr)
tweetsdf2 %>% head()
#csvに出力する場合
write.csv(tweetsdf2,file="tweets2.txt")
リツイートを使う
まず、リツイートされたもの(TRUE)、そうでないもの(FALSE)のを確認し。リツイートのみ取り出します。
#リツイートされたもの(TRUE)、そうでないもの(FALSE)の数を確認
table(tweetsdf2$isRetweet)
FALSE TRUE
6719 3281
#今回リツイートのみ使ってみる
tweetsdf3 <- tweetsdf2 %>% filter(isRetweet %in% c("TRUE"))
head(tweetsdf3) #確認
nrow(tweetsdf3) #行数確認
#テキスト処理のためのライブラリを呼び出す
library(stringr)
library(magrittr)
#データフレームのテキスト列だけ抽出
#今回はアルファベットや「記号をここで削除
texts <- tweetsdf3$text
head(texts) #確認
texts2 %<>% str_replace_all("\\p{ASCII}", "") #今回はここで記号やアルファベットを削除
head(texts2) #確認
形態素解析をかける
「RMeCab」を使い形態素解析をかけるために、テキストを結合します。
一時ファイルを作り、そのファイルに対し、形態素解析を実行します。
#複数の(リスト型)テキストを結合。テキストとテキストの間にはブランクを入れる
texts3 <- paste(texts, collapse = "")
#一時ファイルを作り、xfileという名前で保存
xfile2 <- tempfile()
write(texts3, xfile2)
#形態素解析のライブラリー
library(RMeCab)
#形態素解析。頻度を集計
frq_Tw2 <- RMeCabFreq(xfile2)
#上位50を確認
frq_Tw2 %>% arrange(Freq) %>% tail(50)
3690 高速 名詞 一般 982
3691 連休 名詞 一般 1015
3692 から 助詞 格助詞 1060
3693 する 動詞 自立 1125
3694 … 記号 一般 1298
3695 は 助詞 係助詞 1533
3696 だ 助動詞 * 1551
3697 東名 名詞 固有名詞 1558
3698 て 助詞 接続助詞 1573
3699 た 助動詞 * 1707
3700 に 助詞 格助詞 1959
3701 。 記号 句点 2414
3702 で 助詞 格助詞 2454
3703 が 助詞 格助詞 2614
3704 、 記号 読点 2821
3705 渋滞 名詞 サ変接続 4501
3706 の 助詞 連体化 4994
「固有名詞」を抽出
ざっと見たところ、「固有名詞」をピックアップすると整理がしやすそうです。
frq3_Tw2 <- frq_Tw2 %>% filter(Info2 %in% c("固有名詞"))
frq3_Tw2 %>% arrange(Freq) %>% tail(50)
378 スマート 名詞 固有名詞 309
379 軽井沢 名詞 固有名詞 318
380 東京 名詞 固有名詞 332
381 練馬 名詞 固有名詞 563
382 関越道 名詞 固有名詞 677
383 御殿場 名詞 固有名詞 678
384 綾瀬 名詞 固有名詞 976
385 東名 名詞 固有名詞 1558
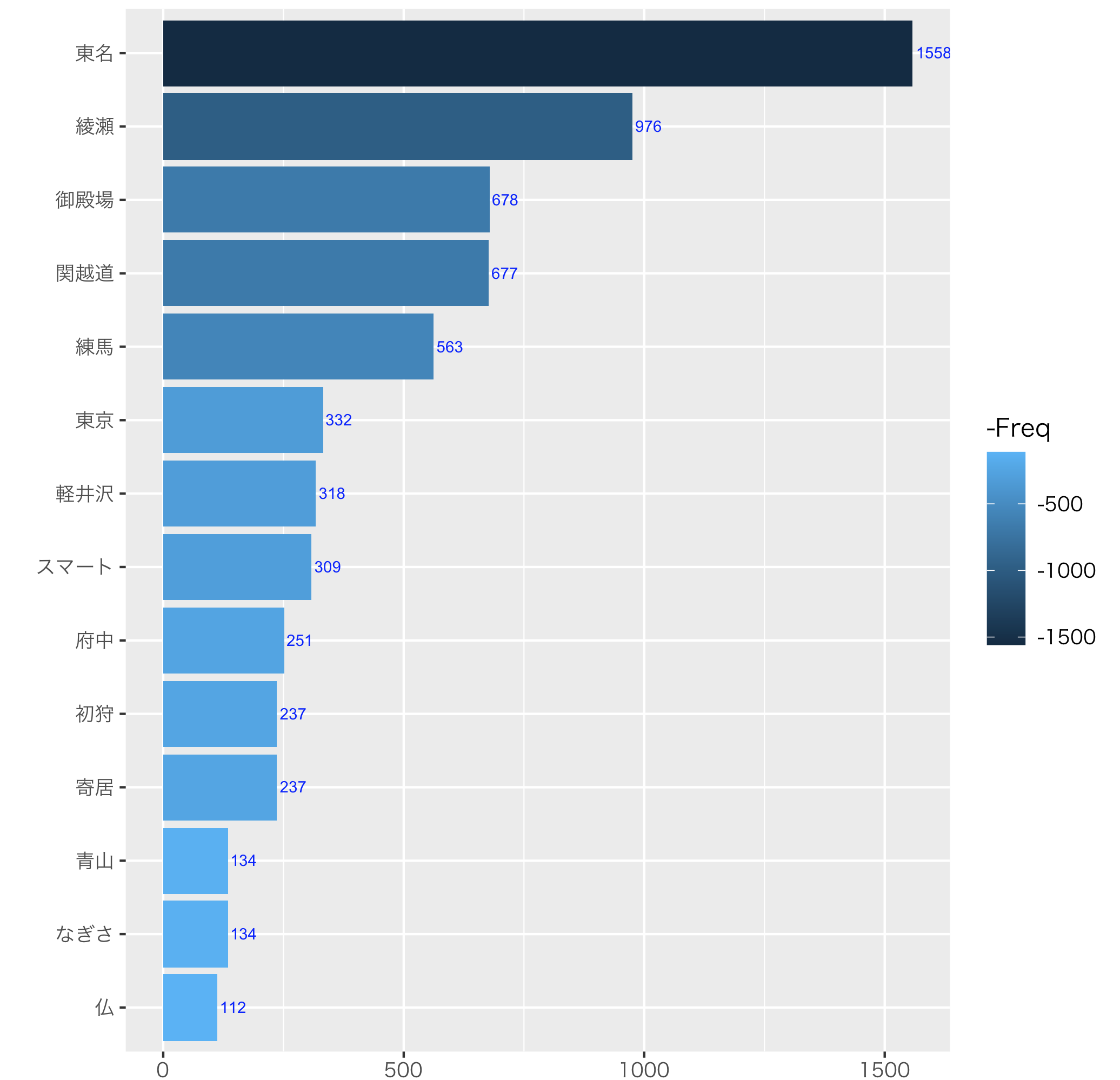
ラベル付き棒グラフを作成
高速道路名称や地名中心に整理します。
ワードクラウドでなく、棒グラフの方がわかりやすそうです
出現頻度数順の棒グラフを「ggplot2」で作成します
#次に、ワードの出現回数順に棒グラフ作成
#そのための準備
#扱いやすいようにTerm(ワード)とFreq(出現回数)の2列のデータフレームに
frq4_Tw2 <- frq3_Tw2
frq5_Tw2 <- data.frame(frq4_Tw2$Term, frq4_Tw2$Freq)
#列名変更
names(frq5_Tw2) <- c("Word", "Freq") #colnames(frq5_Tw2) <- c("Word","Freq")でも可能
frq5_Tw2 %>% arrange(Freq) %>% tail(50)
#出現回数(Freq)が100以上
frq6_Tw2 <- frq5_Tw2 %>% filter(Freq >=100)
frq6_Tw2 %>% arrange(Freq) %>% tail(50)
#ggplot2で棒グラフを描く
#reorderは並び順指定
#stat="identity"はデータラベルつけるときに必要
#fill=ーFreqにすると値が大きいほど色が濃くなる
#coord_flip()を追加すると、x軸とy軸が入れ替わる
#geom_textとlabelで棒グラフにラベル(Freq)を追加。hjustはラベルの位置
library(ggplot2)
par(family = "HiraKakuProN-W3")
ggplot(frq6_Tw2, aes(x=reorder(Word, Freq), y=Freq))+
geom_bar(aes(y=Freq,fill=-Freq),stat="identity") +
xlab("")+
theme_gray (base_family = "HiraKakuPro-W3") +
geom_text(aes(x=reorder(Word,Freq),y=Freq,label = Freq), hjust=-0.1,colour = " blue", size = 2.5) +
coord_flip()
ネットワークグラフ(図)作成
ネットワークグラフも作成してみます。
(適切な解析方法をわかってないので、以下は正しいやり方ではないかもしれません)
最初の段階で用意したデータフレーム 「tweetsdf3」を使います。
Nグラム(今回N=2)用データを用意します。
head(tweetsdf3) #内容確認
#バイグラムデータの作成。column = 1はツイートテキストの列
#type = 1はターム(単語)のNグラム。N = 2なので2グラム。nDF = TRUEでおそらくタームごとの列作成
tw_res <- docDF(tweetsdf3, column = 1, type = 1, N = 2, nDF = TRUE)
head(tw_res) #N1-N2が取得した書くツイートに含まれるかをRow1以降に収納
N1 N2 POS1 POS2 Row1 Row2 Row3 Row4 Row5 Row6 Row7 Row8
1 ! ニュース 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0 0
2 ! リツイート 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0 0
3 ! \U0001f46e 名詞-記号 サ変接続-一般 0 0 0 0 0 0 0 0
4 ! \U0001f647 名詞-記号 サ変接続-一般 0 0 0 0 0 0 0 0
5 !! # 名詞-名詞 サ変接続-サ変接続 0 0 0 0 0 0 0 0
6 !! ハハハコロナ 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0 0
ネットワークグラフ描画用に整形します。
#N1-N2の出現歌回数を集計
tw_res2 <- cbind(tw_res[, 1:2], rowSums(tw_res[, 5:ncol(tw_res)]))
head(tw_res2)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
1 ! ニュース 6
2 ! リツイート 1
3 ! \U0001f46e 1
4 ! \U0001f647 1
5 !! # 1
6 !! ハハハコロナ 1
#出現数の降順で並び替え
tw_res3 <- tw_res2[order(tw_res2[,3], decreasing = TRUE),]
head(tw_res3)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
2548 RT @ 3235
1653 :// t 2717
3590 t . 2711
267 . co 2709
3042 co / 2709
3157 https :// 2069
class(tw_res3) #型の確認
[1] "data.frame"
#3列目の列名を「Freq」に変更
colnames(tw_res3)[3] <- "Freq"
head(tw_res3)
N1 N2 Freq
2548 RT @ 3235
1653 :// t 2717
3590 t . 2711
267 . co 2709
3042 co / 2709
3157 https :// 2069
文章と関係なさそうなタームを外します。
#N1がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res4 <- tw_res3 %>% mutate(noun=str_match((N1), '[^a-zA-Z]+')) #◼️
tw_res4 %>% head(10) #確認
N1 N2 Freq noun
1 RT @ 3235 <NA>
2 :// t 2717 ://
3 t . 2711 <NA>
4 . co 2709 .
5 co / 2709 <NA>
6 https :// 2069 <NA>
7 の 渋滞 1692 の
8 渋滞 が 1283 渋滞
9 最終 日 938 最終
10 連休 最終 938 連休
#削除。na.omitでNA含む行を削除。
tw_res5 <- na.omit(tw_res4) #◼️
tw_res5 %>% head(10) #確認
N1 N2 Freq noun
2 :// t 2717 ://
4 . co 2709 .
7 の 渋滞 1692 の
8 渋滞 が 1283 渋滞
9 最終 日 938 最終
10 連休 最終 938 連休
11 中央 道 890 中央
12 : 東名 733 :
14 59 km 644 59
15 で は 609 で
#N同様にN2がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res6 <- tw_res5 %>% mutate(noun=str_match((N2), '[^a-zA-Z]+')) #◼️
tw_res6 %>% head(10) #確認
#削除。na.omitでNA含む行を削除。
tw_res7 <- na.omit(tw_res6) #◼️
tw_res7 %>% head(10) #確認
N1 N2 Freq noun
3 の 渋滞 1692 渋滞
4 渋滞 が 1283 が
5 最終 日 938 日
6 連休 最終 938 最終
7 中央 道 890 道
8 : 東名 733 東名
10 で は 609 は
11 渋滞 。 544 。
13 で 渋滞 515 渋滞
14 日 、 508 、
ネットーワークグラフをプロットします。
#グラフのプロット
#出現数を300以上に設定
Plot_Tw <- subset(tw_res7, tw_res7[, 3] > 300)
tail(Plot_Tw)
N1 N2 Freq noun
111 東京 方面 315 方面
112 車 で 313 で
113 綾瀬 スマート 309 スマート
114 向かう 車 307 車
115 を 先頭 304 先頭
116 先頭 に 304 に
#MACでの文字化け防止
par(family = "HiraKakuProN-W3")
#グラフのプロット
#データフレーム をネットワークグラフ形式に変換
library(igraph)
Plot_Tw1 <- graph_from_data_frame(Plot_Tw)
#ネットワークグラフをプロット
dev.new()
par(family = "HiraKakuProN-W3")
plot(Plot_Tw1,vertex.color="white",vertex.size=4,
#vertex.label.cex=1.5,
vertex.label.dist=1.1,
edge.width=E(Plot_Tw1)$weight,
vertex.label.cex=0.8,
vertex.label.color="red",
vertex.label.family="HiraKakuProN-W3")
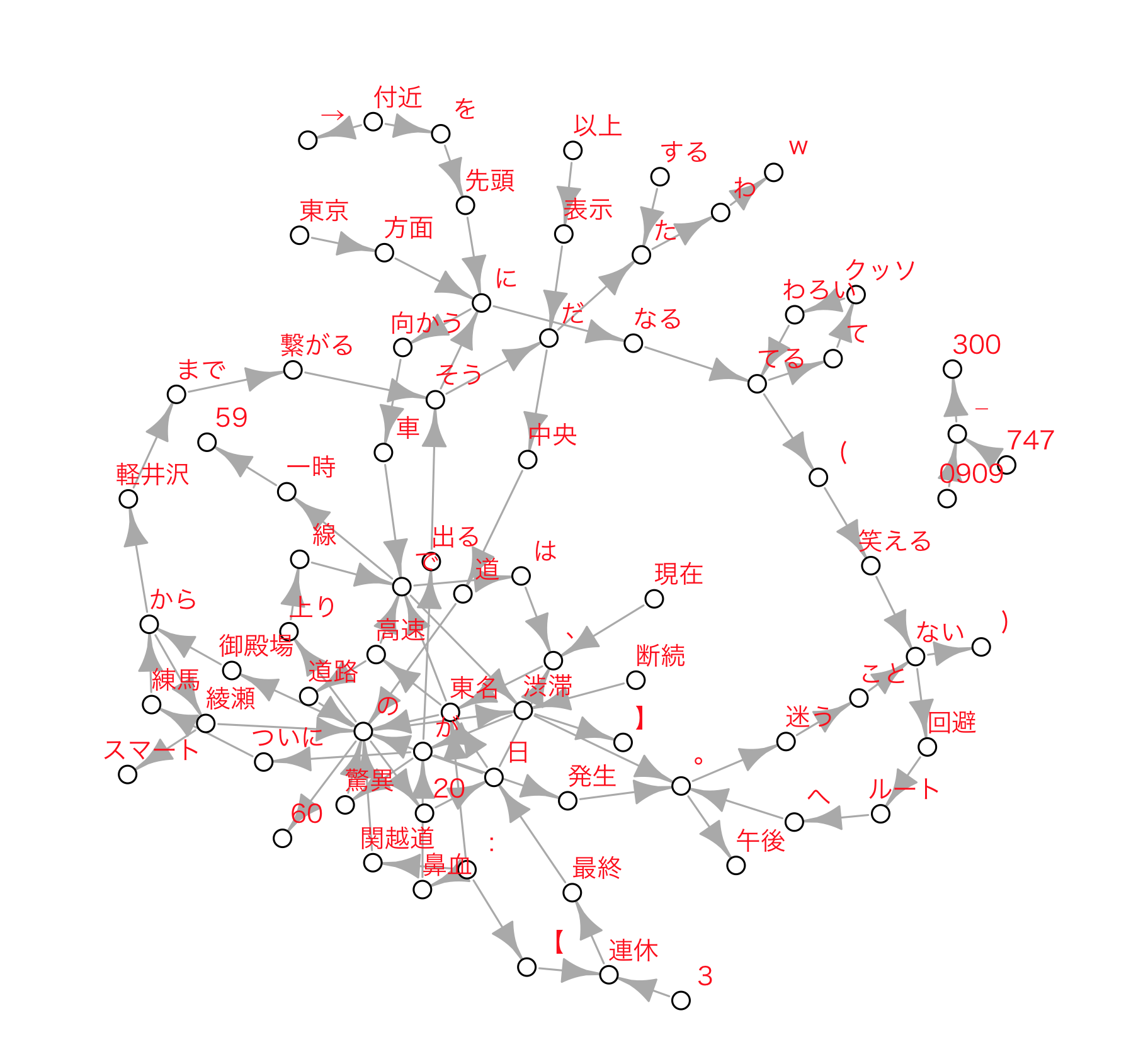
渋滞区間が読み取れるかも
同じようなパターンのネットワーククグラフを連休最終日毎に作成すし比較ると、もう少し読み取れるような気がします。
後付けになりますが、Twitterで検索することで、「御殿場から綾瀬」「練馬から軽井沢」という渋滞、もしくは渋滞になりそうな区間が発生したことは読み取ることはできそうです。
了