先週(2021/09/25)にテレビ放送された「劇場版 鬼滅の刃 無限列車編」に関するツイートをその日のうちに取得し、最近ぼちぼちといじり始めました。

TwitterAPIを利用:twitteR
#TwitterAPI認証情報設定
consumerKey <- "************"
consumerSecret <- "*****************"
accessToken <- "*****************"
accessSecret <- "*********************"
##TwitterAPIにログイン
library("twitteR")
options(httr_oauth_cache = TRUE)
setup_twitter_oauth(consumerKey, consumerSecret, accessToken, accessSecret)
#「上弦」を含む日本語ツイートを15000件取得。2021年9月25日から
tweets2 <- searchTwitter('上弦', n = 15000, since = "2021-09-25" , lang="ja" , locale="ja")#日本語とロケールを指定(日本なら"ja")# 目的に応じて"popular","recent","mixed"を指定 #◼️
#データフレームに変換
tweetsdf2 <- twListToDF(tweets2)
#型を確認
class(tweets2)
[1] "list"
class(tweetsdf2)
[1] "data.frame"
#取得できたか確認
library(dplyr)
tweetsdf2 %>% head()
リツイートのみ使用:table
#リツイートされたもの(TRUE)、そうでないもの(FALSE)の数を確認
table(tweetsdf2$isRetweet)
FALSE TRUE
1367 13633
#今回リツイートのみ使ってみる
tweetsdf3 <- tweetsdf2 %>% filter(isRetweet %in% c("TRUE"))
head(tweetsdf3) #確認
nrow(tweetsdf3) #確認
[1] 13633
#一応csvに出力しておく
write.csv(tweetsdf3, "tweetsdf3_jougen.csv", fileEncoding = "CP932")
#データフレームのテキスト列だけ抽出
texts <- tweetsdf3$text
#後々使うのでテキスト処理のためのライブラリを呼び出す
library(stringr)
library(magrittr)
#複数の(リスト型)テキストを結合。テキストとテキストの間にはブランクを入れる
texts3 <- paste(texts, collapse = "")
形態素解析をかける:RMeCab
#一時ファイルを作り、xfileという名前で保存
xfile <- tempfile()
write(texts3, xfile)
##形態素解析のライブラリー
library(RMeCab)
#形態素解析。頻度を集計
frq_Tw2 <- RMeCabFreq(xfile)
#上位50を確認
frq_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq
2897 放送 名詞 サ変接続 7696
2898 5 名詞 数 7713
2899 が 助詞 格助詞 7843
2900 て 助詞 接続助詞 8380
2901 off 名詞 一般 8740
2902 映像 名詞 一般 8740
2903 最新 名詞 一般 8742
2904 PV 名詞 一般 8743
2905 公開 名詞 サ変接続 8745
2906 決定 名詞 サ変接続 8753
2907 kimetsu 名詞 一般 8756
2908 する 動詞 自立 8764
2909 テレビ 名詞 一般 8829
アルファベット、記号を外す:str_match
#見やすいように整形するために、「アルファベット」「記号」を削除
#termが英語を削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
frq3_Tw2 <- frq_Tw2
frq4_Tw2 <- frq3_Tw2 %>% mutate(noun=str_match((Term), '[^a-zA-Z]+')) #◼️
frq4_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq noun
9721 「 記号 括弧開 302 「
9722 思う 動詞 自立 303 思う
9723 _ 名詞 サ変接続 320 _
9724 # 名詞 サ変接続 331 #
9725 から 助詞 接続助詞 349 から
9726 れる 動詞 接尾 350 れる
9727 無限 名詞 一般 360 無限
9728 編 名詞 接尾 367 編
9729 な 助詞 終助詞 394 な
9730 列車 名詞 一般 428 列車
9731 :// 名詞 サ変接続 429 ://
9732 co 名詞 一般 429 <NA>
9733 t 名詞 一般 437 <NA>
9734 . 名詞 サ変接続 448 .
9735 / 名詞 サ変接続 452 /
9736 って 助詞 格助詞 463 って
#削除。na.omitでNA含む行を削除。
frq5_Tw2 <- na.omit(frq4_Tw2) #◼️
frq5_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq noun
7908 「 記号 括弧開 302 「
7909 思う 動詞 自立 303 思う
7910 _ 名詞 サ変接続 320 _
7911 # 名詞 サ変接続 331 #
7912 から 助詞 接続助詞 349 から
7913 れる 動詞 接尾 350 れる
7914 無限 名詞 一般 360 無限
7915 編 名詞 接尾 367 編
7916 な 助詞 終助詞 394 な
7917 列車 名詞 一般 428 列車
7918 :// 名詞 サ変接続 429 ://
7919 . 名詞 サ変接続 448 .
7920 / 名詞 サ変接続 452 /
7921 って 助詞 格助詞 463 って
#termが記号を識別。noun列が作られ「<NA>」が表示。「\\W」は記号
frq6_Tw2 <- frq5_Tw2 %>% mutate(noun=str_match((Term), '[^\\W]+'))
frq6_Tw2 %>% arrange(Freq) %>% tail(50)
7908 「 記号 括弧開 302 <NA>
7909 思う 動詞 自立 303 思う
7910 _ 名詞 サ変接続 320 _
7911 # 名詞 サ変接続 331 <NA>
7912 から 助詞 接続助詞 349 から
7913 れる 動詞 接尾 350 れる
7914 無限 名詞 一般 360 無限
7915 編 名詞 接尾 367 編
7916 な 助詞 終助詞 394 な
7917 列車 名詞 一般 428 列車
7918 :// 名詞 サ変接続 429 <NA>
7919 . 名詞 サ変接続 448 <NA>
7920 / 名詞 サ変接続 452 <NA>
7921 って 助詞 格助詞 463 って
#削除。na.omitでNA含む行を削除。
frq7_Tw2 <- na.omit(frq6_Tw2)
frq7_Tw2 %>% arrange(Freq) %>% tail(50)
7180 思う 動詞 自立 303 思う
7181 _ 名詞 サ変接続 320 _
7182 から 助詞 接続助詞 349 から
7183 れる 動詞 接尾 350 れる
7184 無限 名詞 一般 360 無限
7185 編 名詞 接尾 367 編
7186 な 助詞 終助詞 394 な
7187 列車 名詞 一般 428 列車
7188 って 助詞 格助詞 463 って
1文字のワードも外す:grep
#Termが1文字の行を削除。まず、1文字ワードの行番号を抽出
index <- grep('..', frq7_Tw2[,1])
head(index)
[1] 4 5 6 8 9 10
frq7_Tw2[index,] %>% arrange(Freq) %>% tail(50) #確認
6139 思う 動詞 自立 303 思う
6140 から 助詞 接続助詞 349 から
6141 れる 動詞 接尾 350 れる
6142 無限 名詞 一般 360 無限
6143 列車 名詞 一般 428 列車
6144 って 助詞 格助詞 463 って
frq8_Tw2 <- frq7_Tw2[index,]
frq8_Tw2 %>% arrange(Freq) %>% tail(50)
6139 思う 動詞 自立 303 思う
6140 から 助詞 接続助詞 349 から
6141 れる 動詞 接尾 350 れる
6142 無限 名詞 一般 360 無限
6143 列車 名詞 一般 428 列車
6144 って 助詞 格助詞 463 って
#ここまで行って、目につくワードが外れることがわかり、1文字のTermを外すのをやめる
#1文字はず目に戻す
frq8_Tw2 <- frq7_Tw2
frq8_Tw2 %>% arrange(Freq) %>% tail(50)
品詞を指定して抽出:filter
#「名詞」を抽出
frq9_Tw2 <- frq8_Tw2
frq10_Tw2 <- frq9_Tw2 %>% filter(Info1 %in% c("名詞"))
frq10_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq noun
1459 発表 名詞 サ変接続 1572 発表
1460 壱 名詞 一般 1710 壱
1461 だき 名詞 サ変接続 1843 だき
1462 ご覧 名詞 動詞非自立的 1843 ご覧
1463 内 名詞 接尾 1843 内
1464 是非 名詞 サ変接続 1844 是非
1465 対峙 名詞 サ変接続 1845 対峙
1466 22 名詞 数 1845 22
1467 汽車 名詞 一般 1863 汽車
1468 たち 名詞 接尾 2002 たち
1469 1 名詞 数 2007 1
1470 さん 名詞 接尾 2251 さん
1471 の 名詞 非自立 2267 の
1472 カナ 名詞 一般 2678 カナ
1473 9 名詞 数 2699 9
1474 治郎 名詞 固有名詞 4700 治郎
#ざっと見た感じで、品詞の小分類の「一般","固有名詞","サ変接続"」を取り出す
frq11_Tw2 <- frq10_Tw2 %>% filter(Info2 %in% c("一般","固有名詞","サ変接続"))
frq11_Tw2 %>% arrange(Freq) %>% tail(50)
Term Info1 Info2 Freq noun
1052 恐怖 名詞 サ変接続 1339 恐怖
1053 退治 名詞 サ変接続 1339 退治
1054 禰 名詞 一般 1339 禰
1055 親戚 名詞 一般 1339 親戚
1056 豆 名詞 一般 1339 豆
1057 遠縁 名詞 一般 1339 遠縁
1058 間際 名詞 一般 1339 間際
1059 ヲ 名詞 固有名詞 1339 ヲ
1060 富岡 名詞 固有名詞 1339 富岡
1061 竈門 名詞 固有名詞 1339 竈門
1062 死 名詞 一般 1340 死
1063 全滅 名詞 サ変接続 1364 全滅
1064 隊 名詞 一般 1455 隊
1065 猗窩 名詞 一般 1524 猗窩
1066 発表 名詞 サ変接続 1572 発表
1067 壱 名詞 一般 1710 壱
1068 だき 名詞 サ変接続 1843 だき
1069 是非 名詞 サ変接続 1844 是非
1070 対峙 名詞 サ変接続 1845 対峙
1071 汽車 名詞 一般 1863 汽車
1072 カナ 名詞 一般 2678 カナ
1073 治郎 名詞 固有名詞 4700 治郎
#ノイズになるなど外したいワードがある場合。行を削除
frq11_Tw2 <- frq11_Tw2 %>% filter(Term != "外したいワード")
frq11_Tw2 %>% arrange(Freq) %>% tail(50)
ワードクラウド作成:wordcloud2
#wordcloud2で描画準備
frq12_Tw2 <- frq11_Tw2 #下記の作業でミスをした場合元のデータフレームに戻せるようにする
#Freqが100以上にする
frq13_Tw2 <- frq12_Tw2$Freq >= 1340
tail(frq13_Tw2) #確認
[1] TRUE FALSE FALSE FALSE FALSE FALSE
frq14_Tw2 <- frq12_Tw2[frq13_Tw2,]
frq14_Tw2 %>% arrange(Freq) %>% tail(60)
Term Info1 Info2 Freq noun
1 死 名詞 一般 1340 死
2 全滅 名詞 サ変接続 1364 全滅
3 隊 名詞 一般 1455 隊
4 猗窩 名詞 一般 1524 猗窩
5 発表 名詞 サ変接続 1572 発表
6 壱 名詞 一般 1710 壱
7 だき 名詞 サ変接続 1843 だき
8 是非 名詞 サ変接続 1844 是非
9 対峙 名詞 サ変接続 1845 対峙
10 汽車 名詞 一般 1863 汽車
11 カナ 名詞 一般 2678 カナ
12 治郎 名詞 固有名詞 4700 治郎
#wordcloud2で描画。frq13_Tw2の1列目(Term)と4列目(Freq)を使う
library(wordcloud2)
#frq14_Tw2[,c(1,4)] %>% wordcloud2(size=2,minSize=1) #sise=2では全体が大きすぎるので下記利用
frq14_Tw2[,c(1,4)] %>% wordcloud2(size=1.3,minSize=1,gridSize=10) #gridSizeは文字間隔

ラベル付き棒グラフも作成:geom_text
#次に、ワードの出現回数順に棒グラフ作成
#そのための準備
#扱いやすいようにTerm(ワード)とFreq(出現回数)の2列のデータフレームに
frq15_Tw2 <- frq14_Tw2
frq16_Tw2 <- data.frame(frq15_Tw2$Term, frq15_Tw2$Freq)
frq16_Tw2 #確認
frq15_Tw2.Term frq15_Tw2.Freq
1 _ 9582
2 だき 1843
3 全滅 1364
4 公開 8745
5 対峙 1845
6 放送 7696
7 是非 1844
8 決定 8753
9 満載 6897
10 発表 1572
#Freq(frq15_Tw2.Freq)の降順に並び替え
frq17_Tw2 <- frq16_Tw2[order(frq16_Tw2$frq15_Tw2.Freq, decreasing=T), ] #◼️
frq17_Tw2 #確認
> frq17_Tw2 #確認
frq15_Tw2.Term frq15_Tw2.Freq
35 鬼 20326
32 遊郭 16575
26 月 14530
15 上弦 14507
18 列車 14407
30 無限 14386
29 滅 13833
23 日 13800
17 刃 13408
19 堕姫 11652
#列名が元のデータフレーム から変わっているので、わかりやすい名称に変更
#列名を変更
colnames(frq17_Tw2) <- c("Word","Freq")
head(frq17_Tw2)
Word Freq
35 鬼 20326
32 遊郭 16575
26 月 14530
15 上弦 14507
18 列車 14407
30 無限 14386
#ggplot2で棒グラフを描く
#reorderは並び順指定
#stat="identity"はデータラベルつけるときに必要
#fill=ーFreqにすると値が大きいほど色が濃くなる
#coord_flip()を追加すると、x軸とy軸が入れ替わる
#geom_textとlabelで棒グラフにラベル(Freq)を追加。hjustはラベルの位置
library(ggplot2)
par(family = "HiraKakuProN-W3")
ggplot(frq17_Tw2, aes(x=reorder(Word, Freq), y=Freq))+
geom_bar(aes(y=Freq,fill=-Freq),stat="identity") +
xlab("")+
theme_gray (base_family = "HiraKakuPro-W3") +
geom_text(aes(x=reorder(Word,Freq),y=Freq,label = Freq), hjust=-0.1,colour = " blue", size = 2.5) +
coord_flip()
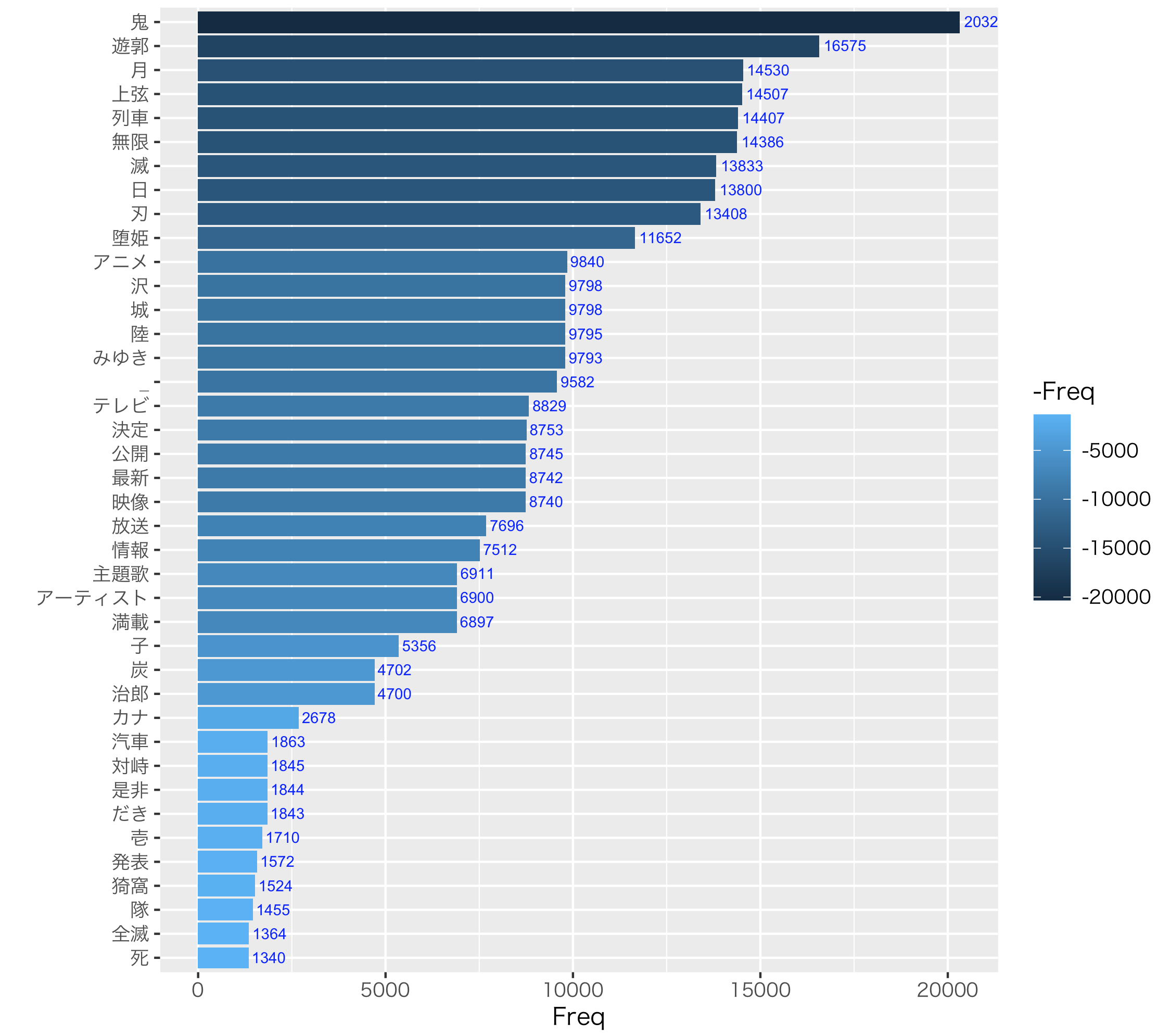
ネットワークグラフ(図)作成
ネットワークグラフも作成してみます。
(適切な解析方法をわかってないので、以下は正しいやり方ではないかもしれません)
最初の段階で用意したデータフレーム 「tweetsdf3」を使います。
Nグラム(今回N=2)用データを用意します。
head(tweetsdf3) #内容確認
#バイグラムデータの作成。column = 1はツイートテキストの列
#type = 1はターム(単語)のNグラム。N = 2なので2グラム。nDF = TRUEでおそらくタームごとの列作成
tw_res <- docDF(tweetsdf3, column = 1, type = 1, N = 2, nDF = TRUE)
number of extracted terms = 8290
now making a data frame. wait a while!
head(tw_res) #N1-N2が取得した書くツイートに含まれるかをRow1以降に収納
N1 N2 POS1 POS2 Row1 Row2 Row3 Row4 Row5 Row6 Row7 Row8 Row9
1 !!! 切ない 名詞-形容詞 サ変接続-自立 0 0 0 0 0 0 0 0 0
2 !!「 # 名詞-名詞 サ変接続-サ変接続 0 0 0 0 0 0 0 0 0
3 !!」 という 名詞-助詞 サ変接続-格助詞 0 0 0 0 0 0 0 0 0
4 " の 名詞-名詞 サ変接続-非自立 0 0 0 0 0 0 0 0 0
5 " よく 名詞-副詞 サ変接続-一般 0 0 0 0 0 0 0 0 0
6 " 上弦 名詞-名詞 サ変接続-一般 0 0 0 0 0 0 0 0 0
ネットワークグラフ描画用に整形します。
#N1-N2の出現歌回数を集計
tw_res2 <- cbind(tw_res[, 1:2], rowSums(tw_res[, 5:ncol(tw_res)]))
head(tw_res2)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
1 !!! 切ない 2
2 !!「 # 6
3 !!」 という 68
4 " の 108
5 " よく 1
6 " 上弦 1
#出現数の降順で並び替え
tw_res3 <- tw_res2[order(tw_res2[,3], decreasing = TRUE),]
head(tw_res3)
N1 N2 rowSums(tw_res[, 5:ncol(tw_res)])
7830 遊郭 編 16550
7198 無限 列車 14386
5894 列車 編 14382
1906 、 遊郭 13877
8040 鬼 滅 13826
6776 日 ( 13800
class(tw_res3) #型の確認
[1] "data.frame"
#3列目の列名を「Freq」に変更
colnames(tw_res3)[3] <- "Freq"
head(tw_res3)
N1 N2 Freq
7830 遊郭 編 16550
7198 無限 列車 14386
5894 列車 編 14382
1906 、 遊郭 13877
8040 鬼 滅 13826
6776 日 ( 13800
文章と関係なさそうなタームを外します。
#N1がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res4 <- tw_res3 %>% mutate(noun=str_match((N1), '[^a-zA-Z]+')) #◼️
tw_res4 %>% head(10) #確認
> tw_res4 %>% head(20)
N1 N2 Freq noun
1 遊郭 編 16550 遊郭
2 無限 列車 14386 無限
3 列車 編 14382 列車
4 、 遊郭 13877 、
5 鬼 滅 13826 鬼
6 日 ( 13800 日
7 日 ) 13800 日
8 編 : 13800 編
9 ( 日 13800 (
10 ) より 13800 )
11 滅 の 13753 滅
12 RT @ 13628 <NA>
13 の 刃 13408 の
#削除。na.omitでNA含む行を削除。
tw_res5 <- na.omit(tw_res4) #◼️
tw_res5 %>% head(10) #確認
N1 N2 Freq noun
1 遊郭 編 16550 遊郭
2 無限 列車 14386 無限
3 列車 編 14382 列車
4 、 遊郭 13877 、
5 鬼 滅 13826 鬼
6 日 ( 13800 日
7 日 ) 13800 日
8 編 : 13800 編
9 ( 日 13800 (
10 ) より 13800 )
11 滅 の 13753 滅
13 の 刃 13408 の
14 上弦 の 12937 上弦
15 沢 城 9798 沢
16 城 みゆき 9793 城
17 の 陸 9498 の
#N2がアルファベットを削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res5a <- tw_res5 %>% mutate(noun=str_match((N2), '[^a-zA-Z]+')) #◼️
tw_res5a %>% head(10)
#確認#削除。na.omitでNA含む行を削除。
tw_res5b <- na.omit(tw_res5a) #◼️
tw_res5b %>% head(10) #確認
#N同様にN2、N!が記号を削除。noun列が作られ「<NA>」が表示。mutateは列を追加したり修正する
tw_res6 <- tw_res5b %>% mutate(noun=str_match((N2), '[^\\W]+')) #◼️
tw_res6 %>% head(10) #確認
#削除。na.omitでNA含む行を削除。
tw_res6 <- na.omit(tw_res6) #◼️
tw_res6 %>% head(10) #確認
tw_res7 <- tw_res6 %>% mutate(noun=str_match((N1), '[^\\W]+')) #◼️
tw_res7 %>% head(10) #確認
#削除。na.omitでNA含む行を削除。
tw_res7 <- na.omit(tw_res7) #◼️
tw_res7 %>% head(10) #確認
N1 N2 Freq noun
1 遊郭 編 16550 遊郭
2 無限 列車 14386 無限
3 列車 編 14382 列車
5 鬼 滅 13826 鬼
8 滅 の 13753 滅
9 の 刃 13408 の
10 上弦 の 12937 上弦
11 沢 城 9798 沢
12 城 みゆき 9793 城
13 の 陸 9498 の
ネットーワークグラフをプロットします。
#グラフのプロット
#とりあえず出現数を300以上に設定
Plot_Tw <- subset(tw_res7, tw_res7[, 3] > 300)
Plot_Tw %>% nrow() #確認
tail(Plot_Tw)
N1 N2 Freq noun
348 鬼 の 315 鬼
349 妓夫 太郎 308 妓夫
350 黒 死 305 黒
351 死 牟 304 死
352 真 守 304 真
353 宮野 真 303 宮野
#グラフのプロット
#データフレーム をネットワークグラフ形式に変換
library(igraph)
Plot_Tw1 <- graph_from_data_frame(Plot_Tw)
#ネットワークグラフをプロット
#MACでの文字化け防止
dev.new()
par(family = "HiraKakuProN-W3")
plot(Plot_Tw1,vertex.color="white",vertex.size=4,
#vertex.label.cex=1.5,
vertex.label.dist=1.1,
vertex.label.cex=0.8,
vertex.label.color="red",
vertex.label.family="HiraKakuProN-W3")
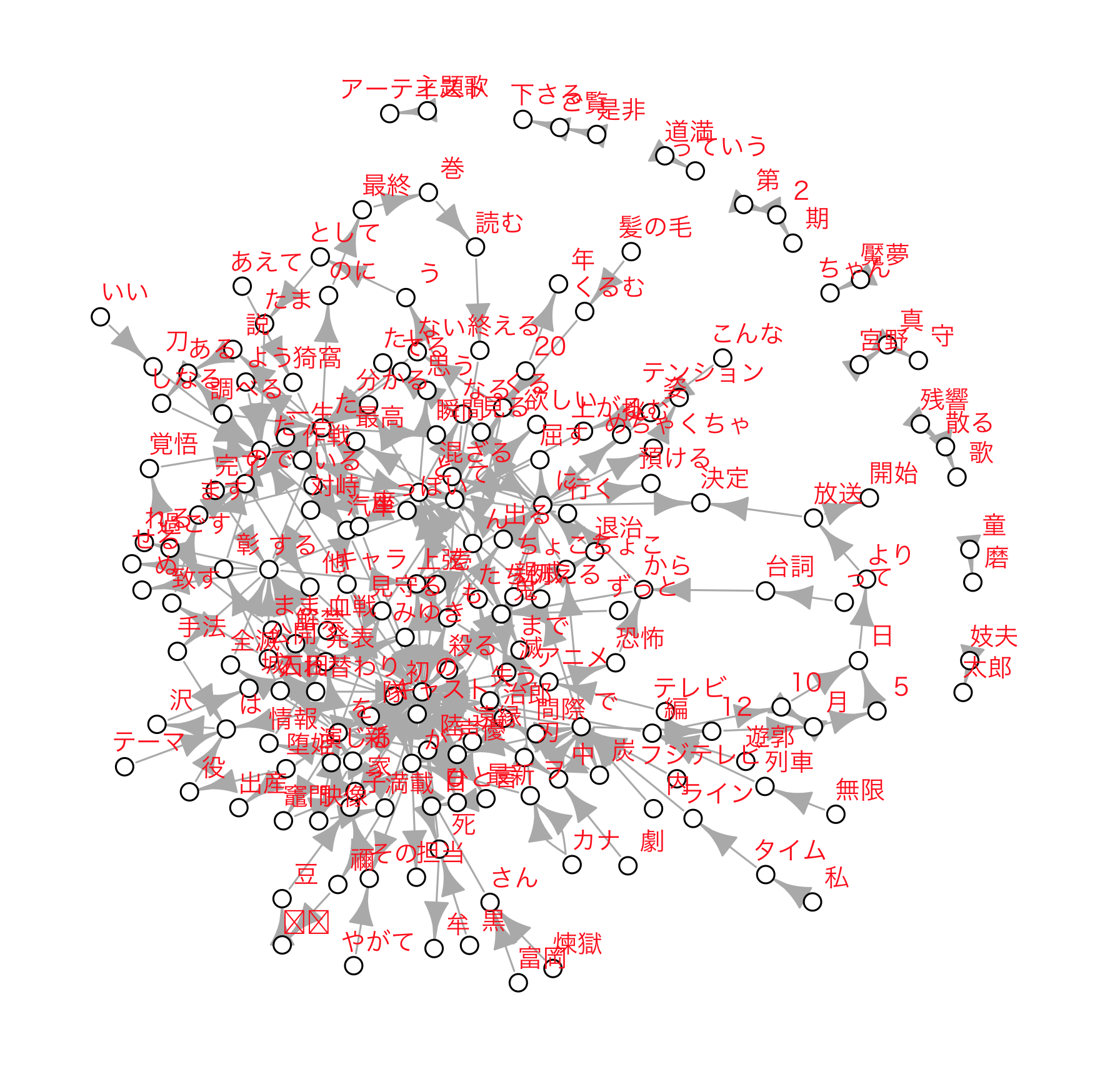
見やすく調整
混雑状態なのでtw_res7の出現頻度Freqで調整します。
Plot_Tw <- subset(tw_res7, tw_res7[, 3] > 800)
Plot_Tw %>% nrow() #確認
Plot_Tw1 <- graph_from_data_frame(Plot_Tw)
#E(Plot_Tw1)$weight <- edge.betweenness(Plot_Tw1) #これを実行するとエッジ間の距離が重み値によって変化。見にくくなるので使わない
#Plot_Tw1_com <- leading.eigenvector.community(Plot_Tw1)
dev.new()
par(family = "HiraKakuProN-W3")
plot(Plot_Tw1,vertex.color="white",vertex.size=4,
#vertex.label.cex=1.5,
vertex.label.dist=0.5,
vertex.label.cex=0.8,
vertex.label.color="red",
vertex.frame.color="grey50",
#edge.width=E(Plot_Tw1)$width,
vertex.label.family="HiraKakuProN-W3")
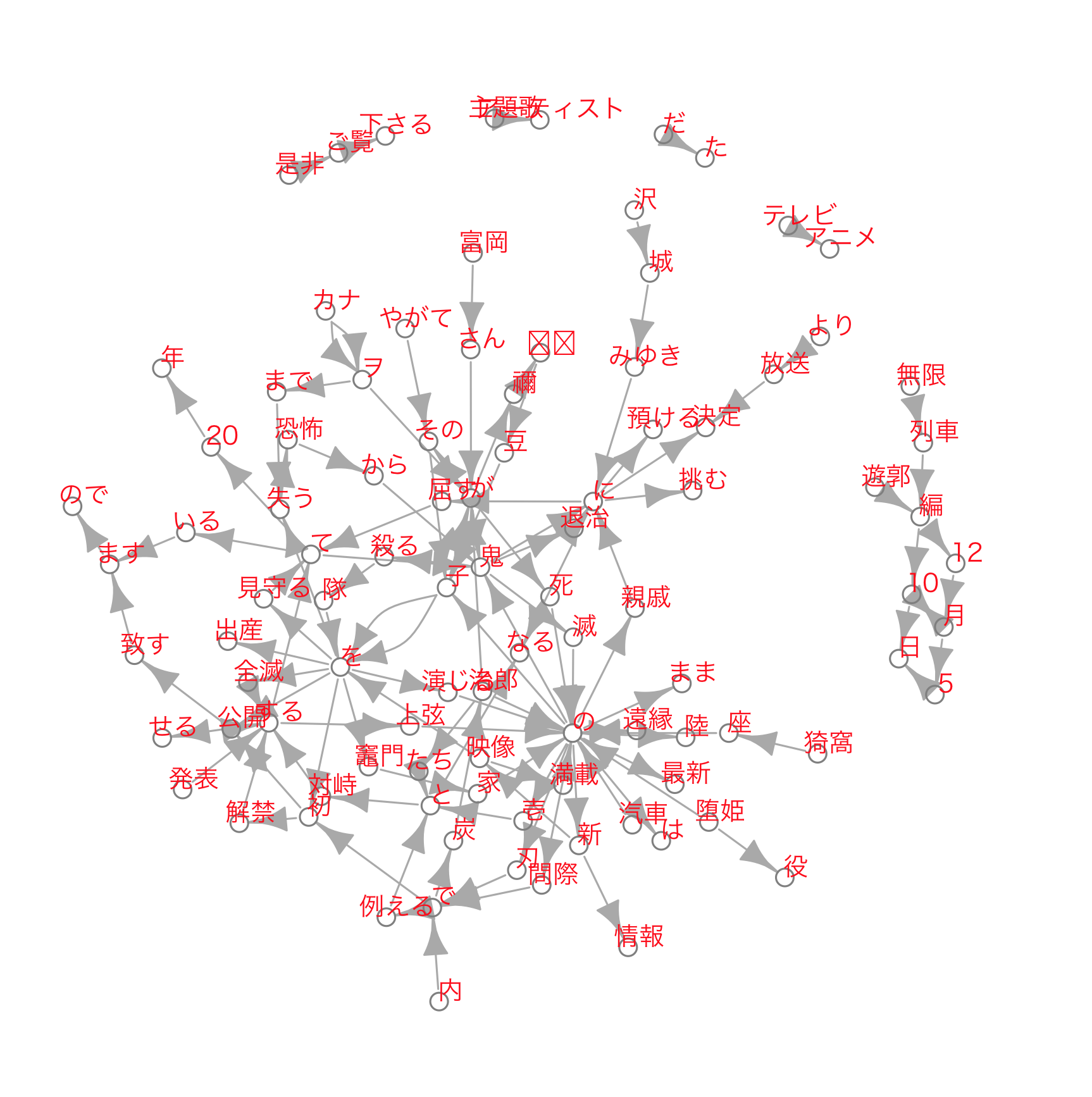
今回はここまでとし、次はネットワークグラフをもう少しいじってみる予定です。
最後に、今いじるための準備として、インタラクティブにネットワークグラフを操作できるtkplotを使ってみました。
#dev.new()
tkplot(Plot_Tw1,vertex.color="white",vertex.size=7,
#vertex.label.cex=1.5,
vertex.label.dist=0.5,
vertex.label.cex=1.2,
vertex.label.color="red",
vertex.frame.color="grey50",
#edge.width=E(Plot_Tw1)$width,
vertex.label.family="HiraKakuProN-W3")
#下記メッセージが出ましたが、主な表示はできたので今回は調べませんでした
#警告メッセージ:
# rm(list = cmd, envir = .tkplot.env) で:
# オブジェクト 'tkp.5' がありません
#Error in vids[[1]] : 添え字が許される範囲外です
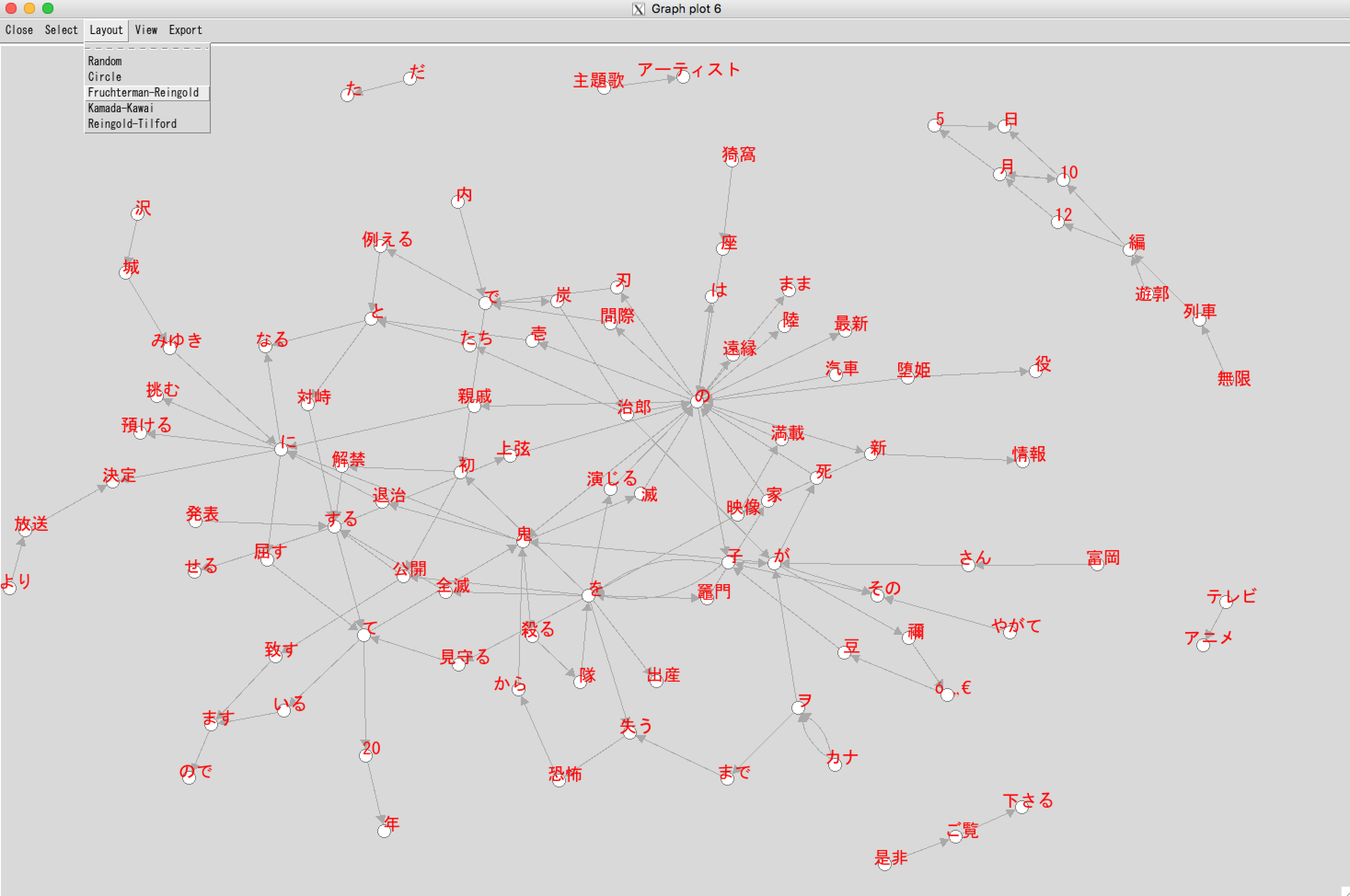
layoutはFruchterman.reingoldを選択しました。
了