はじめに
- 自然言語処理の世界で様々なブレークスルーを起こしている「BERT」をpytorchで利用する方法を紹介します
- 特に実務上で利用するイメージの沸きやすい、手元のラベル付きデータでファインチューニングをして、分類問題を解くタスクを行ってみたいと思います
- 読み込むデータをpandasで少し整形してあげれば他データでも応用することはできるはずなので、是非、お手元の様々なデータで試して頂ければと考えています
環境
- Google Colaboratory(GPU環境)
- Google Colaboratoryの環境設定方法は様々な紹介記事があるので、それらをご参照ください
利用データ
- ライブドアニュースコーパス
- 「ITLife Hack(IT関連記事)」と「Sports Watch(スポーツ関連記事)」の記事を利用
- それぞれの記事内容(テキスト)から、どちらのメディアの記事なのかを推定する2クラス分類問題
- ここでは2クラス分類問題を取り上げていますが、学習済みモデルを読み込む際の引数(num_labels)を変更するだけで、多クラス分類問題へも対応可能
基本的な流れ
- 準備(ライブラリのインストール)
- データセットの準備
- データの前処理(BERTが受けとれる形式にデータを整形)
- 学習済みモデルのロード
- 訓練(Pre-trainedモデルのファインチューニング)
- 検証
NOTE:
- 前処理だけが特殊だが他は通常のニューラルネットワークの学習プロセスと同様
- 特殊な前処理プロセスも定型化できるので関数化しておけば簡単に使い回しが可能
0. 準備
- Hugging Face Library 'Transformer' のダウンロード
- transformers
- 最新のNLPモデルを利用できるライブラリ
- BERTの他にもGPT-2, RoBERTa, XLM, DistilBert, XLNet, T5, CTRL...などの最新モデルや100言語以上の学習済みモデル(Pre-trained model)を利用可能
!pip install transformers
- Mecabのダウンロード
- 日本語の形態素解析処理(文章を品詞ごとに分解する処理)用のライブラリのダウンロード
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3
- GPU設定
- pytorchの環境設定
- GPUが利用できる際はGPU環境、できない際はCPU環境を設定
import torch
# GPUが使えれば利用する設定
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
1. データセットの準備
- ライブドアニュースコーパスをダウンロードします
- ダウンロードしたファイルは圧縮(tar.gz形式)ファイルです
- 解凍すると様々なジャンル(IT,スポーツ,家電,映画など)のWEBメディアごとにフォルダが分かれており、それぞれの記事がテキストファイル形式で保存されています
- データセットの準備はライブドアニュースコーパスのダウンロードを参考にさせて頂きました
import os
import urllib.request
import re
import csv
import tarfile
# データのダウンロード(カレントディレクトリに圧縮ファイルがダウンロードされる)
urllib.request.urlretrieve("https://www.rondhuit.com/download/ldcc-20140209.tar.gz", "ldcc-20140209.tar.gz")
- 次に圧縮ファイルを解凍して、"it-life-hack"(IT関連), "sports-watch"(スポーツ関連)の記事だけ抽出して、それぞれのラベルを付与します
- 処理した結果を"all_text.tsv" というテキストで保存します
# ダウンロードした圧縮ファイルのパスを設定
tgz_fname = "ldcc-20140209.tar.gz"
# 2つをニュースメディアのジャンルを選定
target_genre = ["it-life-hack", "sports-watch"]
#処理をした結果を保存するファイル名
tsv_fname = "all_text.tsv"
# 処理部分-------
brackets_tail = re.compile('【[^】]*】$')
brackets_head = re.compile('^【[^】]*】')
def remove_brackets(inp):
output = re.sub(brackets_head, '', re.sub(brackets_tail, '', inp))
return output
def read_title(f):
# 2行スキップ
next(f)
next(f)
title = next(f) # 3行目を返す
title = remove_brackets(title.decode('utf-8'))
return title[:-1]
zero_fnames = []
one_fnames = []
with tarfile.open(tgz_fname) as tf:
# 対象ファイルの選定
for ti in tf:
# ライセンスファイルはスキップ
if "LICENSE.txt" in ti.name:
continue
if target_genre[0] in ti.name and ti.name.endswith(".txt"):
zero_fnames.append(ti.name)
continue
if target_genre[1] in ti.name and ti.name.endswith(".txt"):
one_fnames.append(ti.name)
with open(tsv_fname, "w") as wf:
writer = csv.writer(wf, delimiter='\t')
# ラベル 0
for name in zero_fnames:
f = tf.extractfile(name)
title = read_title(f)
row = [target_genre[0], 0, '', title]
writer.writerow(row)
# ラベル 1
for name in one_fnames:
f = tf.extractfile(name)
title = read_title(f)
row = [target_genre[1], 1, '', title]
writer.writerow(row)
- 上記、長々とコードがありますが、ファイルを読み込んで、必要な部分を抽出しているだけなので、読み飛ばして頂いても問題ありません
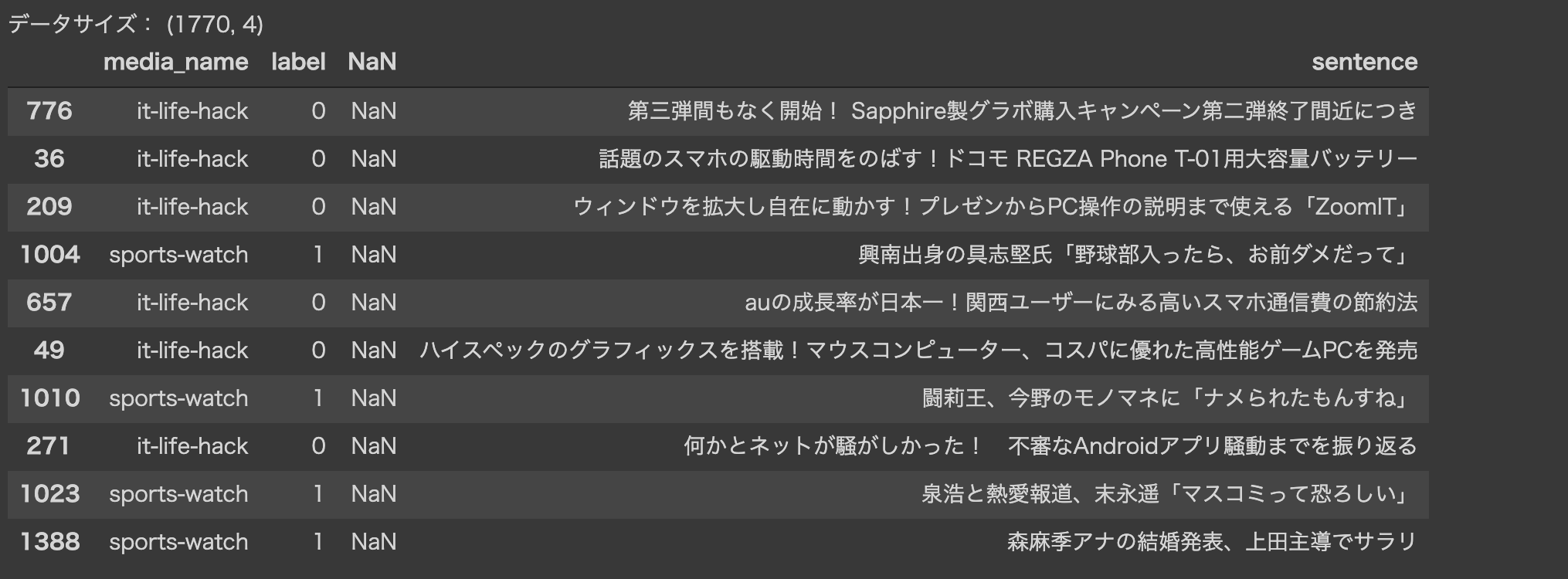
- 最終的に以下の様なpandasのdataframeのデータが作成されます
- そこから必要なデータ(文章とラベル)だけ抽出します
import pandas as pd
# データの読み込み
df = pd.read_csv("all_text.tsv",
delimiter='\t', header=None, names=['media_name', 'label', 'NaN', 'sentence'])
# データの確認
print(f'データサイズ: {df.shape}')
df.sample(10)
- 文章データをsentences、ラベルデータを labelsという変数に保存します
- 次パートからはこの2変数だけを利用します
# データの抽出
sentences = df.sentence.values
labels = df.label.values
2. データの前処理(BERTが受けとれる形式にデータを整形)
- BERTでは基本的に学習済みモデルを利用する為、そのモデルが読み込めるフォーマットにデータを変換する必要があります
-
具体的には、以下の4つ手続きが必要になります
- 1. BERT Tokenizerを用いて単語分割・IDへ変換
- 学習済みモデルの作成時と同じtokenizer(形態素解析器)を利用する必要がある
- 日本語ではMecabやJuman++を利用されることが多い
- 2. Special tokenの追加
- 文章の最後に[SEP]という単語する
- 文章のはじめに[CLS]という単語を追加する(分類問題に利用される)
- 3. 文章の長さの固定
- BERTでは全ての文書の長さ(単語の数)を同じにする必要がある(1文章あたりの最大の単語数は512単語)
- そこで、Padding/Truncatingを用いて固定長に変換する
- Paddingとは、指定した長さに満たない文章を[Pad]という意味を持たない単語の埋める処理
- Truncatingとは、指定した長さを超える単語を切り捨てること
- 4. Attention mask arrayの作成
- [Padding]を0、それ以外のTokenを1とした配列
- 1. BERT Tokenizerを用いて単語分割・IDへ変換
一見ややこししそう見えますが、どれもTransformerのライブラリでサポートされているので、簡単に実行できます
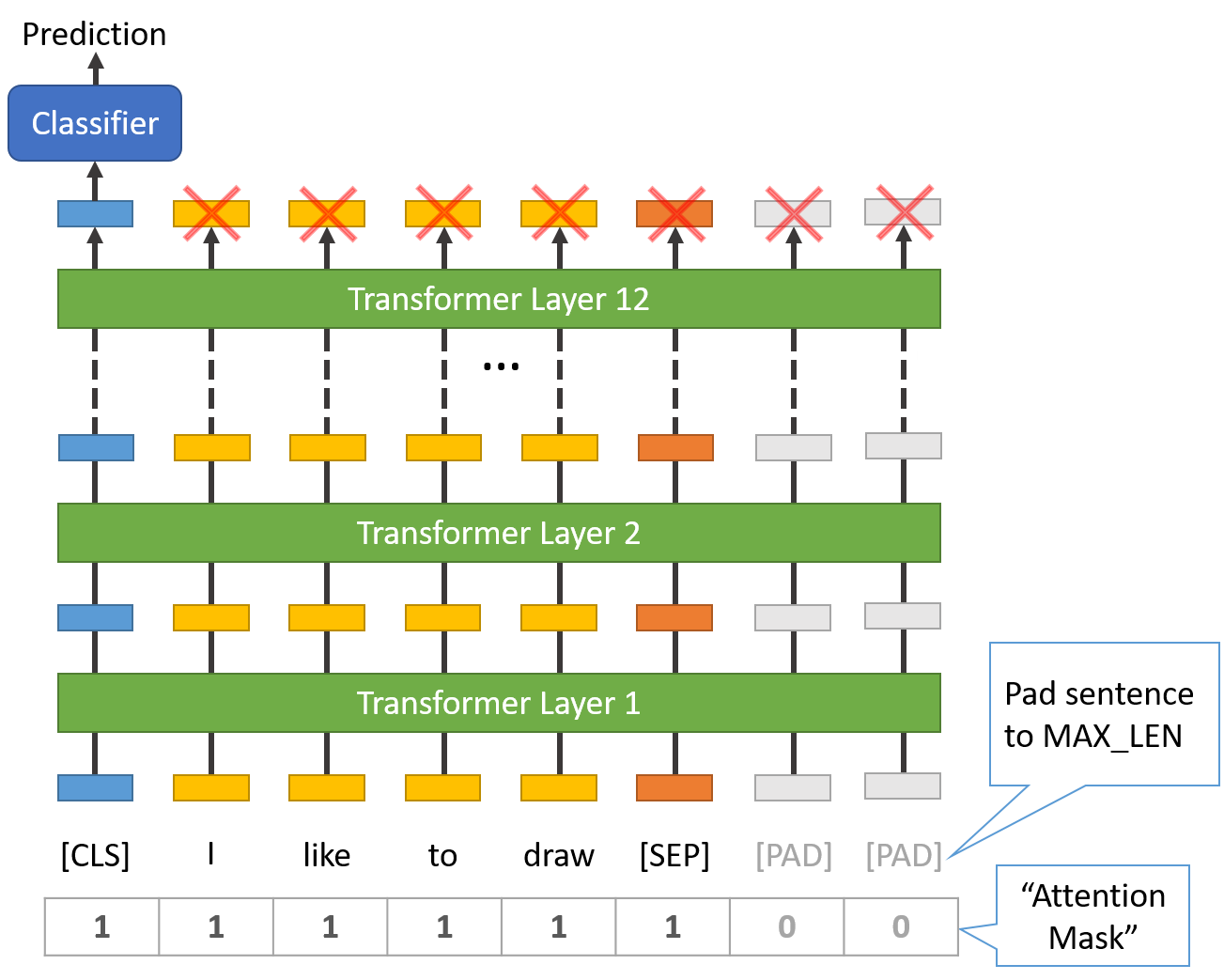
また、以下のイメージも参考にモデルの全体像と照らし合わせながら前処理内容をみるとイメージが沸きやすいかもしれません
参考)BERTのモデルイメージ
- BERTは12層のTransformerレイヤーで構成されている
- 学習済みモデルへ入力するために、上記に様な前処理を行う
- 最終的に冒頭のSpecial token[CLS]だけを分類器へ入力する
はじめに単語分割とIDへの変換から行っていきます
# 1. BERT Tokenizerを用いて単語分割・IDへ変換
## Tokenizerの準備
from transformers import BertJapaneseTokenizer
tokenizer = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking')
## テスト実行
# 元文章
print(' Original: ', sentences[0])
# Tokenizer
print('Tokenized: ', tokenizer.tokenize(sentences[0]))
# Token-id
print('Token IDs: ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(sentences[0])))
テスト実行の結果
- Original:元の文章
- Tokenized:単語単位で分割された文章
- Token IDs:単語をIDに置き換えた文章
Original: 旧式Macで禁断のパワーアップ!最新PCやソフトを一挙にチェック
Tokenized: ['旧式', 'Mac', 'で', '禁', '##断', 'の', 'パワーアップ', '!', '最新', 'PC', 'や', 'ソフト', 'を', '一挙', 'に', 'チェック']
Token IDs: [18718, 8653, 12, 1763, 29135, 5, 20734, 679, 6215, 3794, 49, 1604, 11, 24598, 7, 9398]
次に文章の長さを固定する為に、文章あたりの最大単語数を確認します
ここでは、以下の方法で最大単語数を確認していますが、最大単語数は決め打ちで設定することも可能です
# 最大単語数の確認
max_len = []
# 1文づつ処理
for sent in sentences:
# Tokenizeで分割
token_words = tokenizer.tokenize(sent)
# 文章数を取得してリストへ格納
max_len.append(len(token_words))
# 最大の値を確認
print('最大単語数: ', max(max_len))
print('上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数')
最大単語数: 35
上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数
今回の文章では1文章当たりの最大単語数が37ということが分かりました
Tokenizerと最大単語数の確認がとれたので、全ての文章に一括して処理を行います
tokenizer.encode_plusを利用するとまとめて処理が行えます
input_ids = []
attention_masks = []
# 1文づつ処理
for sent in sentences:
encoded_dict = tokenizer.encode_plus(
sent,
add_special_tokens = True, # Special Tokenの追加
max_length = 37, # 文章の長さを固定(Padding/Trancatinating)
pad_to_max_length = True,# PADDINGで埋める
return_attention_mask = True, # Attention maksの作成
return_tensors = 'pt', # Pytorch tensorsで返す
)
# 単語IDを取得
input_ids.append(encoded_dict['input_ids'])
# Attention maskの取得
attention_masks.append(encoded_dict['attention_mask'])
# リストに入ったtensorを縦方向(dim=0)へ結合
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
# tenosor型に変換
labels = torch.tensor(labels)
# 確認
print('Original: ', sentences[0])
print('Token IDs:', input_ids[0])
1つ目の文章の前処理結果です
元々、日本語テキストだった文章がID化されています
Token IDsの最初に単語IDはSpecial tokenの[CLS]を表し、後半の0埋めが[Pad]を示しています
Original: 旧式Macで禁断のパワーアップ!最新PCやソフトを一挙にチェック
Token IDs: tensor([ 2, 18718, 8653, 12, 1763, 29135, 5, 20734, 679, 6215,
3794, 49, 1604, 11, 24598, 7, 9398, 3, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0])
ここまでで、前処理が完了したので、90%を訓練データ、10%をテストデータに分割して、pytorchで学習を行う為に、データローダーへ変換しておきます
データローダーの説明は、pytorchの基本的な操作なので本記事では割愛します(簡単に言うと、データをバッチごとに分割して、学習を上手くやってくれるデータ型です)
from torch.utils.data import TensorDataset, random_split
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
# データセットクラスの作成
dataset = TensorDataset(input_ids, attention_masks, labels)
# 90%地点のIDを取得
train_size = int(0.9 * len(dataset))
val_size = len(dataset) - train_size
# データセットを分割
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
print('訓練データ数:{}'.format(train_size))
print('検証データ数: {} '.format(val_size))
# データローダーの作成
batch_size = 32
# 訓練データローダー
train_dataloader = DataLoader(
train_dataset,
sampler = RandomSampler(train_dataset), # ランダムにデータを取得してバッチ化
batch_size = batch_size
)
# 検証データローダー
validation_dataloader = DataLoader(
val_dataset,
sampler = SequentialSampler(val_dataset), # 順番にデータを取得してバッチ化
batch_size = batch_size
)
3. 学習済みモデルのロード
- huggingface transformerのBERTファインチューニングでは以下のタスクをサポートしています
-
全てBERT Pre-trainedモデルをベースとして学習し、出力層のみそれぞれのタスクに適した構成になっています
- BertModel
- BertForPreTraining
- BertForMaskedLM
- BertForNextSentencePrediction
- BertForSequenceClassification
- BertForTokenClassification
- BertForQuestionAnswering
BertForSequenceClassification
- 今回は2クラス分類問題なのでBertForSequenceClassificationを利用します
- BertForSequenceClassificationはBERT学習済みモデルの最後の層に分類用のレイヤー追加したネットワーク構成です
- データを入力することで、学習済みモデル全体と未学習部分の分類機レイヤーの学習が行われます
- デフォルトでは、モデル全体のパラメーターがファインチューニングされますが、学習させるレイヤーの設定変更も可能です
- モデルロード時にnum_labelsを変更することで多クラス分類問題へも対応できます
from transformers import BertForSequenceClassification, AdamW, BertConfig
# BertForSequenceClassification 学習済みモデルのロード
model = BertForSequenceClassification.from_pretrained(
"bert-base-japanese-whole-word-masking", # 日本語Pre trainedモデルの指定
num_labels = 2, # ラベル数(今回はBinayなので2、数値を増やせばマルチラベルも対応可)
output_attentions = False, # アテンションベクトルを出力するか
output_hidden_states = False, # 隠れ層を出力するか
)
# モデルをGPUへ転送
model.cuda()
学習済みモデルのロードが完了しました
次にこのモデルを手元のデータに合うようにファインチューニングを行います
4. 訓練(Pre-trainedモデルのファインチューニング)
- モデルのファインチューニングは通常のニューラルネットワークの学習と同様で、損失関数と最適化手法(Optimizer)を指定して、学習ループ(任意のバッチサイズとエポックを指定)を回します
- BERTでは損失関数はすでに定義されているので、ハイパーパラメーターとして、最適化手法とバッチサイズをエポック数だけ指定します
- ここでは、論文(BERT paper, Appendix A.3)に従って、最適化関数はAdamW(Adam Weight Decay fix)を利用し、ハイパーパラメーターは下記のように設定します
- Batch size: 32
- Learning rate: 2e-5
- Epochs: 4
# 最適化手法の設定
optimizer = AdamW(model.parameters(), lr=2e-5)
# 訓練パートの定義
def train(model):
model.train() # 訓練モードで実行
train_loss = 0
for batch in train_dataloader:# train_dataloaderはword_id, mask, labelを出力する点に注意
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
optimizer.zero_grad()
loss, logits = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
train_loss += loss.item()
return train_loss
# テストパートの定義
def validation(model):
model.eval()# 訓練モードをオフ
val_loss = 0
with torch.no_grad(): # 勾配を計算しない
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
with torch.no_grad():
(loss, logits) = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask,
labels=b_labels)
val_loss += loss.item()
return val_loss
学習に必要な関数が定義できたので、学習を行います
# 学習の実行
max_epoch = 4
train_loss_ = []
test_loss_ = []
for epoch in range(max_epoch):
train_ = train(model)
test_ = train(model)
train_loss_.append(train_)
test_loss_.append(test_)
5. 検証
- モデルの学習(ファインチューニング)が完了したので、結果を確認します
- modelという変数に学習済みのモデルが入っているので、ID化した単語とAttention mask(Paddingをマスクした配列)を入力すると、ラベルごとの予測値を出力します
# 検証方法の確認(1バッチ分で計算ロジックに確認)
model.eval()# 訓練モードをオフ
for batch in validation_dataloader:
b_input_ids = batch[0].to(device)
b_input_mask = batch[1].to(device)
b_labels = batch[2].to(device)
with torch.no_grad():
# 学習済みモデルによる予測結果をpredsで取得
preds = model(b_input_ids,
token_type_ids=None,
attention_mask=b_input_mask)
以下の様な結果が出力されます
この確率の様な値(厳密には、この値ををソフトマックス関数に入力すると確率になる)が大きい方のラベルをモデルは分類結果とし予測としています
## 予測結果の確認
print(f'出力:{preds}')
出力:(tensor([[-5.0226, 5.0193],
[-5.0390, 4.9736],
[ 4.7941, -4.7459],
[-4.9395, 4.6827], device='cuda:0'),)
左からラベルの[0, 1]に対応しており、1つ目のデータであれば、右側の値が大きいのでモデルはラベル1を予測している
# 比較しやすい様にpd.dataframeへ整形
import pandas as pd
# pd.dataframeへ変換(GPUに乗っているTensorはgpu->cpu->numpy->dataframeと変換)
logits_df = pd.DataFrame(preds[0].cpu().numpy(), columns=['logit_0', 'logit_1'])
## np.argmaxで大き方の値を取得
pred_df = pd.DataFrame(np.argmax(preds[0].cpu().numpy(), axis=1), columns=['pred_label'])
label_df = pd.DataFrame(b_labels.cpu().numpy(), columns=['true_label'])
accuracy_df = pd.concat([logits_df, pred_df, label_df], axis=1)
accuracy_df.head()
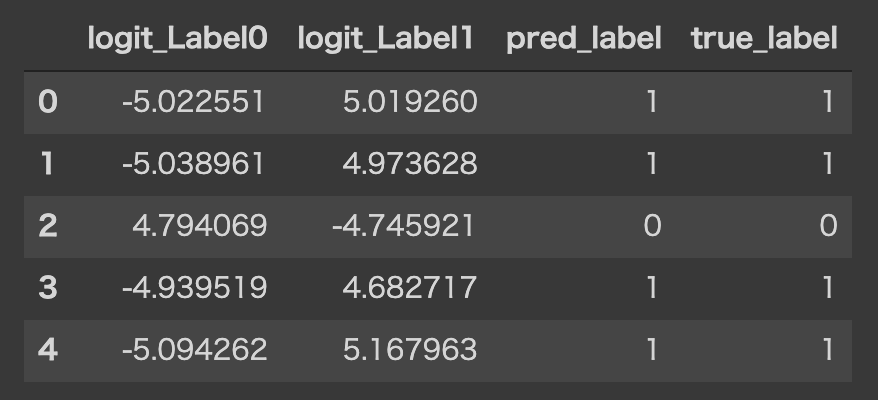
- 上記の様に予測ラベルと正解ラベルを取得して、dataframeへ保存することができました
- あとは、シンプルに正解率を計算するなり、sklearnを用いて混合行列を作成するなり、好きな様に分類モデルの評価を行うことができます
補足
- 本記事では、BERTの学習済みモデルをファインチューニングして利用することに重きをおいたので背景となるBERTの理論面やBERTを基礎となっているAttention mechanismやTransformerの説明は割愛しました
-
理論面もより深く理解したい方へは、下記の様な分かりやすい解説記事でポイントを抑えたうえで、原論文を読むことをお勧めします
-
また本記事を作成するにあたり、コーディング部分は下記のリンクを参考とさせて頂きました
最後に
- 身近な環境(GoogleColab)とライブラリ(pytorch,transformer)を用いて、なるべく簡単かつ無料で最新アルゴリズムを利用する方法をまとめてみました
- 正解ラベル付きのテキストデータさえあれば気軽に(データクレンジングは大変ですが...)試すことができるかと思いますので、是非まずはお試し頂き、長い目で新たな技術の社会実装の一助となれば幸いです