ポイント
- Gumbel-Gate LSTM を実装し、具体的な数値で確認。
- 今後、パフォーマンス検証を実施。
レファレンス
1. Towards Binary-Valued Gates for Robust LSTM Training

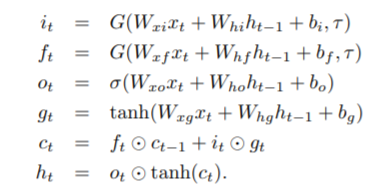
(参照論文より引用)
データ
- Sequential MNIST。
サンプルコード
class G2_LSTM():
def __init__(self):
pass
def weight_variable(self, name, shape):
initializer = tf.truncated_normal_initializer(mean = 0.0, stddev = 0.01, dtype = tf.float32)
return tf.get_variable(name, shape, initializer = initializer)
def bias_variable(self, name, shape):
initializer = tf.constant_initializer(value = 0.0, dtype = tf.float32)
return tf.get_variable(name, shape, initializer = initializer)
def get_dropout_mask(self, keep_prob, shape):
keep_prob = tf.convert_to_tensor(keep_prob)
random_tensor = keep_prob + tf.random_uniform(shape)
binary_tensor = tf.floor(random_tensor)
dropout_mask = binary_tensor / keep_prob
return dropout_mask
# Gumbel-Gate LSTM
def inference(self, x, length, n_in, n_units, n_fc_units, n_out, batch_size, keep_prob, tau):
x = tf.reshape(x, [-1, length, n_in])
h = tf.zeros(shape = [batch_size, n_units], dtype = tf.float32)
c = tf.zeros(shape = [batch_size, n_units], dtype = tf.float32)
list_h = []
list_c = []
with tf.variable_scope('lstm'):
w_x = self.weight_variable('w_x', [n_in, n_units * 4])
w_h = self.weight_variable('w_h', [n_units, n_units * 4])
b = self.bias_variable('b', [n_units * 4])
for t in range(length):
i, f, o, g = tf.split(tf.add(tf.add(tf.matmul(x[:, t, :], w_x), tf.matmul(h, w_h)), b), 4, axis = 1)
u_i = tf.random_uniform(shape = [batch_size, n_units])
u_f = tf.random_uniform(shape = [batch_size, n_units])
i = i + tf.log(u_i) - tf.log(1- u_i)
f = f + tf.log(u_f) - tf.log(1- u_f)
i = tf.nn.sigmoid(i / tau)
f = tf.nn.sigmoid(f / tau)
o = tf.nn.sigmoid(o)
g = tf.nn.tanh(g)
c = tf.add(tf.multiply(f, c), tf.multiply(i, g))
h = tf.multiply(o, tf.nn.tanh(c))
list_h.append(h)
list_c.append(c)
with tf.variable_scope('fc'):
w_fc_1 = self.weight_variable('w_fc_1', [n_units, n_fc_units])
b_fc_1 = self.bias_variable('b_fc_1', [n_fc_units])
w_fc_2 = self.weight_variable('w_fc_2', [n_fc_units, n_out])
b_fc_2 = self.bias_variable('b_fc_2', [n_out])
fc_1 = tf.nn.relu(tf.matmul(list_h[-1], w_fc_1) + b_fc_1)
fc_1_dropout = tf.nn.dropout(fc_1, keep_prob)
fc_2 = tf.nn.relu(tf.matmul(fc_1_dropout, w_fc_2) + b_fc_2)
return tf.nn.softmax(fc_2, axis = 1)
# Regular LSTM
def inference_2(self, x, length, n_in, n_units, n_fc_units, n_out, batch_size, keep_prob):
x = tf.reshape(x, [-1, length, n_in])
h = tf.zeros(shape = [batch_size, n_units], dtype = tf.float32)
c = tf.zeros(shape = [batch_size, n_units], dtype = tf.float32)
list_h = []
list_c = []
with tf.variable_scope('lstm'):
w_x = self.weight_variable('w_x', [n_in, n_units * 4])
w_h = self.weight_variable('w_h', [n_units, n_units * 4])
b = self.bias_variable('b', [n_units * 4])
for t in range(length):
i, f, o, g = tf.split(tf.add(tf.add(tf.matmul(x[:, t, :], w_x), tf.matmul(h, w_h)), b), 4, axis = 1)
i = tf.nn.sigmoid(i)
f = tf.nn.sigmoid(f + 1.0)
o = tf.nn.sigmoid(o)
g = tf.nn.tanh(g)
c = tf.add(tf.multiply(f, c), tf.multiply(i, g))
h = tf.multiply(o, tf.nn.tanh(c))
list_h.append(h)
list_c.append(c)
with tf.variable_scope('fc'):
w_fc_1 = self.weight_variable('w_fc_1', [n_units, n_fc_units])
b_fc_1 = self.bias_variable('b_fc_1', [n_fc_units])
w_fc_2 = self.weight_variable('w_fc_2', [n_fc_units, n_out])
b_fc_2 = self.bias_variable('b_fc_2', [n_out])
fc_1 = tf.nn.relu(tf.matmul(list_h[-1], w_fc_1) + b_fc_1)
fc_1_dropout = tf.nn.dropout(fc_1, keep_prob)
fc_2 = tf.nn.relu(tf.matmul(fc_1_dropout, w_fc_2) + b_fc_2)
return tf.nn.softmax(fc_2, axis = 1)
def loss(self, y, t):
cross_entropy = - tf.reduce_mean(tf.reduce_sum(t * tf.log(tf.clip_by_value(y, 1e-10, 1.0)), axis = 1))
return cross_entropy
def accuracy(self, y, t):
correct_preds = tf.equal(tf.argmax(y, axis = 1), tf.argmax(t, axis = 1))
return tf.reduce_mean(tf.cast(correct_preds, tf.float32))
def training(self, loss, learning_rate):
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate)
train_step = optimizer.minimize(loss)
return train_step
def training_clipped(self, loss, learning_rate, clip_norm):
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
clipped_grads_and_vars = [(tf.clip_by_norm(grad, clip_norm = clip_norm), \
var) for grad, var in grads_and_vars]
train_step = optimizer.apply_gradients(clipped_grads_and_vars)
return train_step
def fit(self, images_train, labels_train, images_test, labels_test, \
length, n_in, n_units, n_fc_units, n_out, learning_rate, \
n_iter, batch_size, show_step, is_saving, model_path):
tf.reset_default_graph()
x = tf.placeholder(shape = [None, 28 * 28], dtype = tf.float32)
t = tf.placeholder(shape = [None, 10], dtype = tf.float32)
keep_prob = tf.placeholder(dtype = tf.float32)
tau = tf.placeholder(dtype = tf.float32)
# Gumbel-Gate LSTM
y = self.inference(x, length, n_in, n_units, n_fc_units, n_out, batch_size, keep_prob, tau)
# Regular LSTM
#y = self.inference_2(x, length, n_in, n_units, n_fc_units, n_out, batch_size, keep_prob)
loss = self.loss(y, t)
train_step = self.training(loss, learning_rate)
acc = self.accuracy(y, t)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
history_loss_train = []
history_acc_train = []
history_loss_test = []
history_acc_test = []
for i in range(n_iter):
# Train
rand_index = np.random.choice(len(images_train), size = batch_size)
x_batch = images_train[rand_index]
y_batch = labels_train[rand_index]
# Gumbel-Gate LSTM
feed_dict = {x: x_batch, t: y_batch, keep_prob: 0.7, tau: 1.0}
# Regular LSTM
#feed_dict = {x: x_batch, t: y_batch, keep_prob: 0.7}
sess.run(train_step, feed_dict = feed_dict)
temp_loss = sess.run(loss, feed_dict = feed_dict)
temp_acc = sess.run(acc, feed_dict = feed_dict)
history_loss_train.append(temp_loss)
history_acc_train.append(temp_acc)
if (i + 1) % show_step == 0:
print ('--------------------')
print ('Iteration: ' + str(i + 1) + ' Loss: ' + str(temp_loss) + \
' Accuracy: ' + str(temp_acc))
# Test
rand_index = np.random.choice(len(images_test), size = batch_size)
x_batch = images_test[rand_index]
y_batch = labels_test[rand_index]
# Gumbel-Gate LSTM
feed_dict = {x: x_batch, t: y_batch, keep_prob: 1.0, tau: 0.01}
# Regular LSTM
#feed_dict = {x: x_batch, t: y_batch, keep_prob: 1.0}
temp_loss = sess.run(loss, feed_dict = feed_dict)
temp_acc = sess.run(acc, feed_dict = feed_dict)
history_loss_test.append(temp_loss)
history_acc_test.append(temp_acc)
if is_saving:
model_path = saver.save(sess, model_path)
print ('done saving at ', model_path)
fig = plt.figure(figsize = (10, 3))
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(range(n_iter), history_loss_train, 'b-', label = 'Train')
ax1.plot(range(n_iter), history_loss_test, 'r--', label = 'Test')
ax1.set_title('Loss')
ax1.legend(loc = 'upper right')
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(range(n_iter), history_acc_train, 'b-', label = 'Train')
ax2.plot(range(n_iter), history_acc_test, 'r--', label = 'Test')
ax2.set_title('Accuracy')
ax2.legend(loc = 'lower right')
plt.show()
パラメータ
length = 28
n_in = 28
n_units = 512
n_fc_units = 256
n_out = 10
learning_rate = 0.001
batch_size = 64
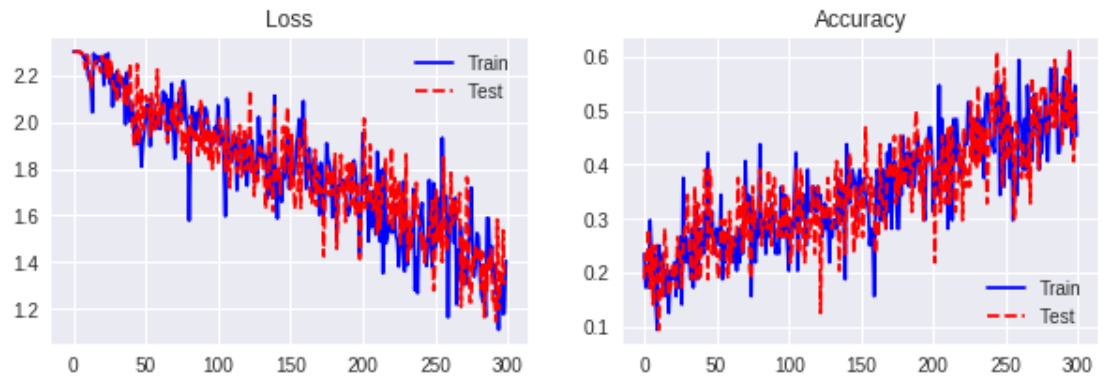
アウトプット
Gumbel-Gate LSTM
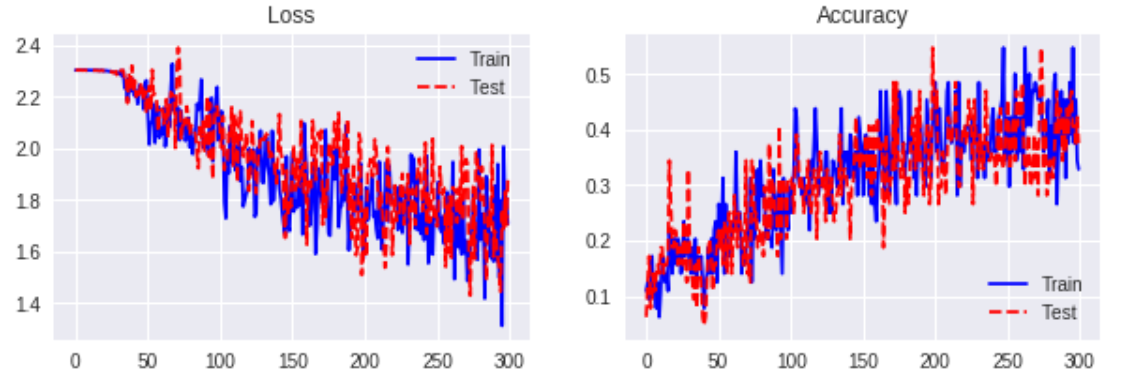
Regular LSTM