ポイント
- Gated CNN において、Regular Convolution を Separable Convolution に置き換え。
- Sequential MNIST を使用。
- 今後、パラメータ数の削減効果、Dilation と Filter size のトレードオフを追加検証。
レファレンス
1. Language Modeling with Gated Convolutional Networks
2. Depthwise Separable Convolutions for Neural Machine Translation
3. Gated CNN に関するメモ
検証方法
- Sequential MNIST を [14*14, 1] に縮尺。
- パラメータ数 ( Regular : 約16,000、Separable : 約4,000 )
データ
MNIST handwritten digits
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('***/mnist', \
one_hot = True)
train_images = np.reshape(mnist.train.images, [-1, 28, 28])
train_images = skimage.measure.block_reduce(train_images, \
block_size = (1, 2, 2), func = np.max)
train_images = np.reshape(train_images, [-1, 14*14])
検証結果
数値計算例:
- n_in = 14*14
- filter_size = 5
- n_units = 32
- n_out = 10
- n_layers = 4
- residual_step = 2
- learning_rate = 0.01
- batch_size = 64
Regular Convolution
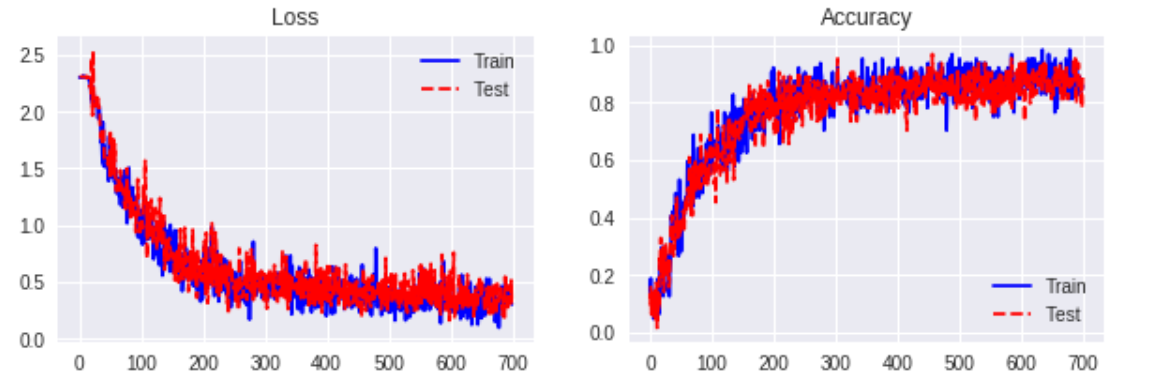
Separable Convolution
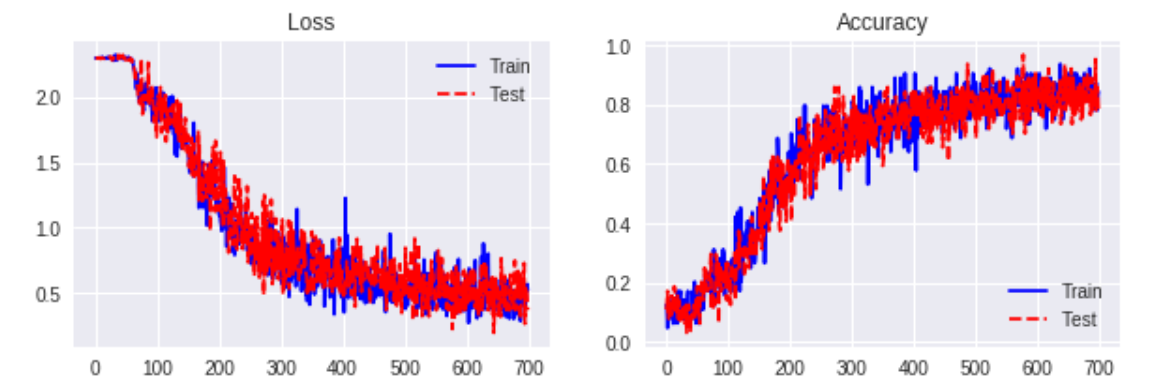
サンプルコード
def dilated_gated_separable_conv(self, x, shape_d, shape_p, rate):
w_d = self.weight_variable('w_d', shape_d)
w_p = self.weight_variable('w_p', shape_p)
b = self.weight_variable('b', shape_p[-1])
v_d = self.weight_variable('v_d', shape_d)
v_p = self.weight_variable('v_p', shape_p)
c = self.weight_variable('c', shape_p[-1])
f = tf.add(tf.nn.separable_conv2d(x, w_d, w_p, \
strides = [1, 1, 1, 1], padding = 'VALID', \
rate = [1, rate]), b)
g = tf.add(tf.nn.separable_conv2d(x, v_d, v_p, \
strides = [1, 1, 1, 1], padding = 'VALID', \
rate = [1, rate]), c)
output = tf.multiply(f, tf.sigmoid(g)) # GLU
#output = tf.multiply(tf.tanh(f), tf.sigmoid(g)) # GTU
#output = tf.nn.relu(f) # ReLU
#output = tf.tanh(f) # Tanh
return output
def inference_2(self, x, filter_size, n_in, n_units, \
n_out, n_layers, residual_step):
width = n_in
channel = 1
x = tf.reshape(x, [-1, 1, width, channel])
x = tf.nn.max_pool(x, ksize = [1, 1, 2, 1], \
strides = [1, 1, 2, 1], padding = 'SAME')
shape = [1, 1, channel, n_units]
with tf.variable_scope('initial'):
y = self.conv(x, shape)
inputs = y
# for regular convolution
#shape = [1, filter_size, n_units, n_units]
# for separable convolution
shape_d = [1, filter_size, n_units, 1]
shape_p = [1, 1, n_units, n_units]
for i in range(n_layers):
with tf.variable_scope('layer_{}'.format(i + 1)):
# Dilated
y = tf.pad(y, [[0, 0], [0, 0], \
[2**i * (filter_size - 1), 0], [0, 0]])
# Separable Convolution Without Weight Normalization
y = self.dilated_gated_separable_conv(y, \
shape_d, shape_p, 2**i)
if (i + 1) % residual_step == 0:
y += inputs
inputs = y
y = y[:, :, -1, :]
y = tf.squeeze(y, axis = 1)
with tf.variable_scope('final'):
w = self.weight_variable('w', [n_units, n_out])
b = self.bias_variable('b', [n_out])
y = tf.add(tf.matmul(y, w), b)
y = tf.nn.softmax(y, axis = 1)
return y