内容
- PyTorch で Graph Convolutional Networks を実装する。
- 簡単な具体例で動作確認をする。
参照論文
SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS
ライブラリー
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
import math
import networkx as nx
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
データ
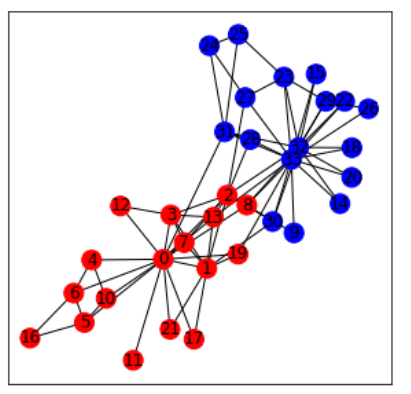
G = nx.karate_club_graph()
pos = nx.spring_layout(G)
color = []
for node in G.nodes:
if G.node[node]['club'] == 'Mr. Hi':
color.append('r')
elif G.node[node]['club'] == 'Officer':
color.append('b')
plt.figure(figsize=(5, 5))
#nx.draw(G, pos=pos, node_size=200, node_color=color, with_labels=True)
nx.draw_networkx(G, pos=pos, node_size=200, node_color=color, with_labels=True)
前処理
A = nx.adjacency_matrix(G).todense()
L = nx.laplacian_matrix(G).todense()
D = L + A
A_tilde = np.array(A).astype(np.float) + np.identity(G.number_of_nodes(), dtype=np.float)
D_temp = np.array(D).astype(np.float) # <-- change to D_tilde = D + I
for i in range(G.number_of_nodes()):
D_temp[i][i] = 1.0 / math.sqrt(D_temp[i][i])
A_hat = np.matmul(np.matmul(D_temp, A_tilde), D_temp)
X = np.identity(G.number_of_nodes(), dtype=np.float)
# (*)
y = []
for node in G.nodes:
if G.node[node]['club'] == 'Mr. Hi':
y.append(0)
elif G.node[node]['club'] == 'Officer':
y.append(1)
(*) 定義の確認と他の定式化との比較をすること。

学習
参照論文より引用。
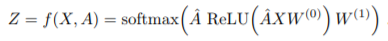
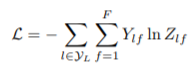
class GCN(nn.Module):
def __init__(self, A_hat, num_feat, num_hidden, num_class):
super(GCN, self).__init__()
self.num_feat = num_feat
self.num_hidden = num_hidden
self.num_class = num_class
self.A_hat = A_hat
self.W_0 = nn.Parameter(torch.Tensor(num_feat, num_hidden))
self.W_1 = nn.Parameter(torch.Tensor(num_hidden, num_class))
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.W_0.size(1))
self.W_0.data.uniform_(-stdv, stdv)
stdv = 1. / math.sqrt(self.W_1.size(1))
self.W_1.data.uniform_(-stdv, stdv)
def forward(self, X, A_hat):
H = torch.mm(torch.mm(A_hat, X), self.W_0)
H = F.relu(H)
H = torch.mm(torch.mm(A_hat, H),self.W_1)
return F.log_softmax(H, dim=1)
num_feat = len(G.nodes())
num_hidden = 10
num_class = 2
model = GCN(A_hat, num_feat, num_hidden, num_class).to(device)
#for p in model.parameters():
# print(p.shape) # 形の確認
# print(p) # 初期値の確認
loss_fun = nn.NLLLoss()
optimizer = optim.Adam(model.parameters())
#print(optimizer) # デフォルト値の確認
A_hat_tensor = torch.Tensor(A_hat).to(device)
X_tensor = torch.Tensor(X).to(device)
y_tensor = torch.LongTensor(y).to(device)
loss_hist = []
acc_hist = []
for epoch in range(500):
model.train()
model.zero_grad()
output = model(X_tensor, A_hat_tensor)
loss = loss_fun(output, y_tensor)
loss_hist.append(loss.item())
preds = torch.argmax(output, dim=1)
acc = torch.mean(torch.eq(preds, y_tensor).type(torch.DoubleTensor)).numpy()
acc_hist.append(acc)
if (epoch+1)%100 == 0:
print('{} Loss: {:.4f} Acc: {:.4f}'.format(epoch+1, loss.item(), acc))
loss.backward()
optimizer.step()
#for p in model.parameters():
# print(p) # 学習後の値の確認

結果の可視化
損失の推移
plt.figure(figsize=(5, 3))
plt.plot(loss_hist)
plt.grid(True)
plt.show()
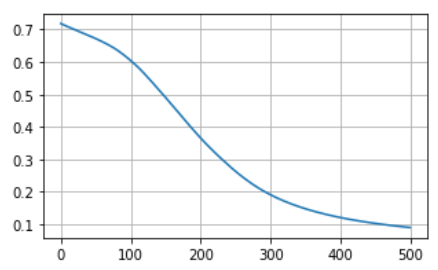
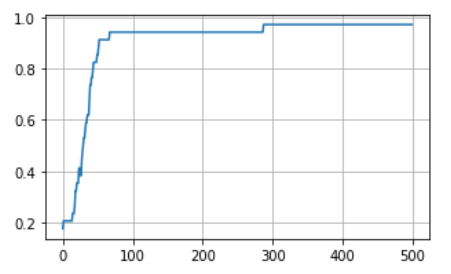
正解率の推移
plt.figure(figsize=(5, 3))
plt.plot(acc_hist)
plt.grid(True)
plt.show()