目的
- TenorFlow の eager execution に慣れる。
- 不均衡データ (imbalanced data) に対し、focal loss を試す。
参照
Focal Loss for Dense Object Detection
コード (Jupyter Notebook)
ライブラリー
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn import metrics
import tensorflow as tf
import tensorflow.contrib.eager as tfe
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
np.random.seed(0)
Eager execution (TF 1.x の時)
tf.enable_eager_execution()
print ("TensorFlow version: {}".format(tf.VERSION))
print ("Eager execution: {}".format(tf.executing_eagerly()))

データ
Fraud detection dataset on Kaggle
df_data = pd.read_csv(os.path.join(path, file))
df_data = df_data.drop('nameDest', axis=1)
df_data = df_data.drop('nameOrig', axis=1)
df_data = df_data.drop('type', axis=1)
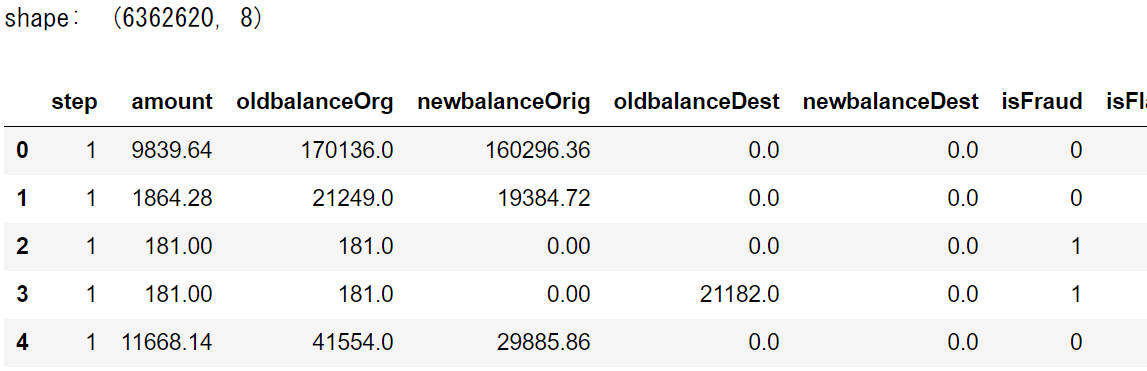
print ('shape: ', df_data.shape)
df_data.head()
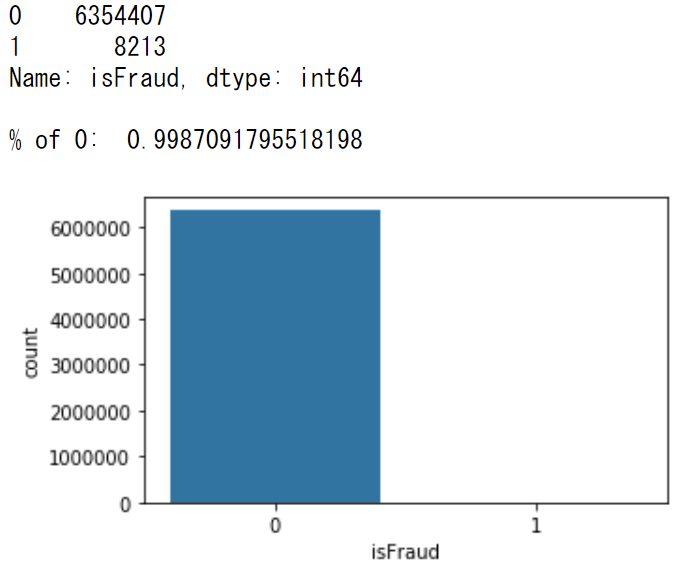
print (df_data['isFraud'].value_counts())
print ()
print ('% of 0: ', np.sum(df_data['isFraud']==0)/len(df_data))
plt.figure(figsize=(5, 3))
sns.countplot(df_data['isFraud'])
plt.show()
def feature_normalize(dataset):
mu = np.mean(dataset, axis=0)
sigma = np.std(dataset, axis=0)
return (dataset - mu) / sigma
X, y = df_data.iloc[:,:-2], df_data.iloc[:, -2]
y = tf.keras.utils.to_categorical(y, num_classes=2)
X = feature_normalize(X.values)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
X_train_tf = tf.convert_to_tensor(X_train, dtype=tf.float32)
y_train_tf = tf.convert_to_tensor(y_train, dtype=tf.float32)
X_test_tf = tf.convert_to_tensor(X_test, dtype=tf.float32)
y_test_tf = tf.convert_to_tensor(y_test, dtype=tf.float32)
Model の書き方の例
同一のアーキテクチャを3パターンのやり方で実装。
パターン1
class Pattern1():
def __init__(self):
input_size = X_train.shape[1]
hidden_size1 = 10
hidden_size2 = 20
hidden_size3 = 10
output_size = y_train.shape[1]
self.fc1_w = tfe.Variable(tf.truncated_normal([input_size, hidden_size1],
stddev=0.1), dtype=tf.float32)
self.fc1_b = tfe.Variable(tf.constant(0.1, shape=[hidden_size1]),
dtype=tf.float32)
self.fc2_w = tfe.Variable(tf.truncated_normal([hidden_size1, hidden_size2],
stddev=0.1), dtype=tf.float32)
self.fc2_b = tfe.Variable(tf.constant(0.1, shape=[hidden_size2]),
dtype=tf.float32)
self.fc3_w = tfe.Variable(tf.truncated_normal([hidden_size2, hidden_size3],
stddev=0.1), dtype=tf.float32)
self.fc3_b = tfe.Variable(tf.constant(0.1, shape=[hidden_size3]),
dtype=tf.float32)
self.fc4_w = tfe.Variable(tf.truncated_normal([hidden_size3, output_size],
stddev=0.1), dtype=tf.float32)
self.fc4_b = tfe.Variable(tf.constant(0.1, shape=[output_size]),
dtype=tf.float32)
self.variables = [
self.fc1_w, self.fc1_b,
self.fc2_w, self.fc2_b,
self.fc3_w, self.fc3_b,
self.fc4_w, self.fc4_b,
]
def __call__(self, x):
h = tf.nn.relu(tf.matmul(x, self.fc1_w) + self.fc1_b)
h = tf.nn.relu(tf.matmul(h, self.fc2_w) + self.fc2_b)
h = tf.nn.relu(tf.matmul(h, self.fc3_w) + self.fc3_b)
y_pred = tf.matmul(h, self.fc4_w) + self.fc4_b
return y_pred
パターン2
class Pattern2(tf.keras.Model):
def __init__(self):
super(Pattern2, self).__init__()
input_shape = X_train.shape[1:]
hidden_size1 = 10
hidden_size2 = 20
hidden_size3 = 10
output_size = y_train.shape[1]
self.dense1 = tf.keras.layers.Dense(hidden_size1, activation='relu',
input_shape=input_shape)
self.dense2 = tf.keras.layers.Dense(hidden_size2, activation='relu')
self.dense3 = tf.keras.layers.Dense(hidden_size3, activation='relu')
self.dense4 = tf.keras.layers.Dense(output_size, activation='softmax')
def __call__(self, x):
h = self.dense1(x)
h = self.dense2(h)
h = self.dense3(h)
h = self.dense4(h)
return h
パターン3
input_shape = X_train.shape[1:]
hidden_size1 = 10
hidden_size2 = 20
hidden_size3 = 10
output_size = y_train.shape[1]
Pattern3 = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=input_shape),
tf.keras.layers.Dense(hidden_size1, activation='relu'),
tf.keras.layers.Dense(hidden_size2, activation='relu'),
tf.keras.layers.Dense(hidden_size3, activation='relu'),
tf.keras.layers.Dense(output_size, activation='softmax'),
])
Training のやり方の例
パターン4と5が focal loss を使用。
パターン1
model = Pattern3
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', mode='min',
patience=5, verbose=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', mode='min',
factor=0.1, patience=5, min_lr=0.00001, verbose=1)
epochs = 3
batch_size = 1000
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
callbacks=[early_stopping, reduce_lr],
verbose=2,
)
plt.figure(figsize=(5, 3))
plt.plot(history.epoch, history.history["loss"], label="Train loss")
plt.plot(history.epoch, history.history["val_loss"], label="Validation loss")
plt.title('Loss')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
plt.figure(figsize=(5, 3))
plt.plot(history.epoch, history.history["acc"], label="Train accuracy")
plt.plot(history.epoch, history.history["val_acc"], label="Validation accuracy")
plt.title('Accuracy')
plt.xlabel('epoch')
plt.legend(loc='best')
plt.show()
preds = model.predict(X_test, batch_size=1000)
LABELS = ['Normal','Fraud']
truth = np.argmax(y_test, axis=1)
predictions = np.argmax(preds, axis=1)
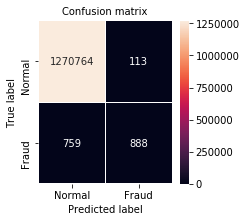
confusion_matrix = metrics.confusion_matrix(truth, predictions)
plt.figure(figsize=(3, 3))
sns.heatmap(confusion_matrix, xticklabels=LABELS, yticklabels=LABELS,
annot=True, fmt="d", linewidth=0.1, linecolor='white',
annot_kws={"size": 10});
plt.title("Confusion matrix", fontsize=10)
plt.ylabel('True label', fontsize=10)
plt.xlabel('Predicted label', fontsize=10)
plt.show()
values = confusion_matrix.view()
error_count = values.sum() - np.trace(values)
f1 = metrics.f1_score(truth, predictions)
precision = metrics.precision_score(truth, predictions)
recall = metrics.recall_score(truth, predictions)
print ('error count: ', error_count)
print ('f1: {:.3f}'.format(f1))
print ('precision: {:.3f}'.format(precision))
print ('recall: {:.3f}'.format(recall))

パターン2
model = Pattern3
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
class_weight = {0 : 1., 1: 20.}
epochs = 3
batch_size = 1000
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
class_weight=class_weight,
verbose=2,
)
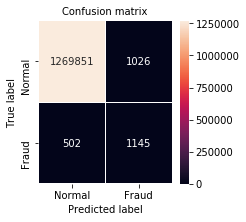
パターン3
def loss(model, x, y):
y_pred = model(x)
cross_entropy = - tf.reduce_mean(tf.reduce_sum(y*tf.log(tf.clip_by_value(y_pred, 1e-10, 1.0)),
axis=1))
return cross_entropy
def accuracy(y_true, y_pred):
correct_preds = tf.equal(tf.argmax(y_true, axis = 1),
tf.argmax(y_pred, axis = 1))
accuracy = tf.reduce_mean(tf.cast(correct_preds, tf.float32))
return accuracy
def grad(model, x, y):
with tf.GradientTape() as tape:
loss_value = loss(model, x, y)
return tape.gradient(loss_value, model.variables)
model = Pattern2()
epochs = 3
batch_size = 1000
optimizer = tf.train.AdamOptimizer()
for epoch in tqdm(range(epochs)):
n = tf.shape(X_train_tf).numpy()[0]
perm = np.random.permutation(n)
for i in range(0, n, batch_size):
batch_x = tf.gather(X_train_tf, perm[i:i+batch_size])
batch_y = tf.gather(y_train_tf, perm[i:i+batch_size])
grads = grad(model, batch_x, batch_y)
optimizer.apply_gradients(zip(grads, model.variables),
global_step=tf.train.get_or_create_global_step())
train_loss = loss(model, X_train_tf, y_train_tf)
train_acc = accuracy(y_train_tf, model(X_train_tf))
valid_loss = loss(model, X_test_tf, y_test_tf)
valid_acc = accuracy(y_test_tf, model(X_test_tf))
if (epoch+1)%1 == 0:
tqdm.write('epoch:\t{}\tloss:\t{:.5f}\tacc:\t{:.5f}\tval_loss:\t{:.5f}\tval_acc:\t{:.5f}'.format(
epoch+1, train_loss, train_acc, valid_loss, valid_acc)
)
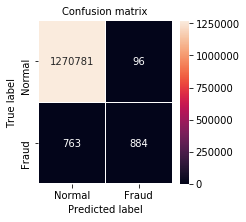
パターン4
def focal_loss(gamma=2., alpha=4.):
gamma = float(gamma)
alpha = float(alpha)
def focal_loss_fixed(y_true, y_pred):
"""Focal loss for multi-classification
FL(p_t)=-alpha(1-p_t)^{gamma}ln(p_t)
Notice: y_pred is probability after softmax
gradient is d(Fl)/d(p_t) not d(Fl)/d(x) as described in paper
d(Fl)/d(p_t) * [p_t(1-p_t)] = d(Fl)/d(x)
Focal Loss for Dense Object Detection
https://arxiv.org/abs/1708.02002
Arguments:
y_true {tensor} -- ground truth labels, shape of [batch_size, num_cls]
y_pred {tensor} -- model's output, shape of [batch_size, num_cls]
Keyword Arguments:
gamma {float} -- (default: {2.0})
alpha {float} -- (default: {4.0})
Returns:
[tensor] -- loss.
"""
epsilon = 1.e-9
y_true = tf.convert_to_tensor(y_true, tf.float32)
y_pred = tf.convert_to_tensor(y_pred, tf.float32)
model_out = tf.add(y_pred, epsilon)
ce = tf.multiply(y_true, -tf.log(model_out))
weight = tf.multiply(y_true, tf.pow(tf.subtract(1., model_out), gamma))
fl = tf.multiply(alpha, tf.multiply(weight, ce))
reduced_fl = tf.reduce_max(fl, axis=1)
return tf.reduce_mean(reduced_fl)
return focal_loss_fixed
model = Pattern3
model.compile(loss=focal_loss(alpha=1),
optimizer='adam',
metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', mode='min',
patience=5, verbose=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', mode='min',
factor=0.1, patience=5, min_lr=0.00001, verbose=1)
epochs = 3
batch_size = 1000
history = model.fit(X_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(X_test, y_test),
callbacks=[early_stopping, reduce_lr],
verbose=2,
)
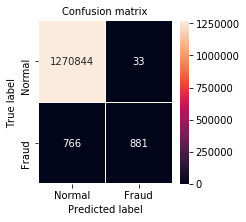
パターン5
def ce_loss(model, x, y):
y_pred = model(x)
cross_entropy = - tf.reduce_mean(tf.reduce_sum(y*tf.log(tf.clip_by_value(y_pred, 1e-10, 1.0)),
axis=1))
return cross_entropy
def focal_loss(model, x, y, gamma=2., alpha=4.):
epsilon = 1.e-9
y_true = tf.convert_to_tensor(y, tf.float32)
y_pred = tf.convert_to_tensor(model(x), tf.float32)
model_out = tf.add(y_pred, epsilon)
ce = tf.multiply(y_true, -tf.log(model_out))
weight = tf.multiply(y_true, tf.pow(tf.subtract(1., model_out), gamma))
fl = tf.multiply(alpha, tf.multiply(weight, ce))
reduced_fl = tf.reduce_max(fl, axis=1)
return tf.reduce_mean(reduced_fl)
def accuracy(y_true, y_pred):
correct_preds = tf.equal(tf.argmax(y_true, axis = 1),
tf.argmax(y_pred, axis = 1))
accuracy = tf.reduce_mean(tf.cast(correct_preds, tf.float32))
return accuracy
def grad(model, loss, x, y):
with tf.GradientTape() as tape:
loss_value = loss(model, x, y)
return tape.gradient(loss_value, model.variables)
model = Pattern2()
loss = focal_loss
epochs = 3
batch_size = 1000
optimizer = tf.train.AdamOptimizer()
for epoch in tqdm(range(epochs)):
n = tf.shape(X_train_tf).numpy()[0]
perm = np.random.permutation(n)
for i in range(0, n, batch_size):
batch_x = tf.gather(X_train_tf, perm[i:i+batch_size])
batch_y = tf.gather(y_train_tf, perm[i:i+batch_size])
grads = grad(model, loss, batch_x, batch_y)
optimizer.apply_gradients(zip(grads, model.variables),
global_step=tf.train.get_or_create_global_step())
train_loss = loss(model, X_train_tf, y_train_tf)
train_acc = accuracy(y_train_tf, model(X_train_tf))
valid_loss = loss(model, X_test_tf, y_test_tf)
valid_acc = accuracy(y_test_tf, model(X_test_tf))
if (epoch+1)%1 == 0:
tqdm.write('epoch:\t{}\tloss:\t{:.5f}\tacc:\t{:.5f}\tval_loss:\t{:.5f}\tval_acc:\t{:.5f}'.format(
epoch+1, train_loss, train_acc, valid_loss, valid_acc)
)
preds = model(X_test_tf)
LABELS = ['Normal','Fraud']
truth = np.argmax(y_test_tf, axis=1)
predictions = np.argmax(preds, axis=1)
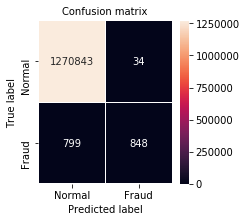
confusion_matrix = metrics.confusion_matrix(truth, predictions)
plt.figure(figsize=(3, 3))
sns.heatmap(confusion_matrix, xticklabels=LABELS, yticklabels=LABELS,
annot=True, fmt="d", linewidth=0.1, linecolor='white',
annot_kws={"size": 10});
plt.title("Confusion matrix", fontsize=10)
plt.ylabel('True label', fontsize=10)
plt.xlabel('Predicted label', fontsize=10)
plt.show()