ポイント
- LSTMをベースに Variable Computation (VCLSTM) を実装。
- 今後、数値検証を行う。
- 今後、(広い意味で)Adaptive Computation Time について整理する。
レファレンス
1. Variable Computation in Recurrent Neural Networks
モデル・アーキテクチャ
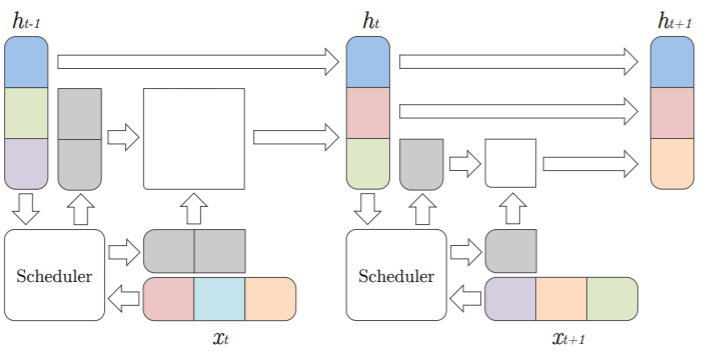
(参照論文より引用)
m_t = \sigma(W_m[x_t, h_{t-1}] + b_m) \\
∀i\in1, ..., D \quad (e_t)_i = Thres_\epsilon\Bigl(\sigma\Bigl(\lambda\bigl(m_tD - i\bigr)\Bigr)\Bigr) \\
\bar{h}_{t-1} = e_t \odot h_{t-1},\quad \bar{c}_{t-1} = e_t \odot c_{t-1},\quad \bar{x}_t = e_t \odot x_t \\
\quad \\
\begin{pmatrix}
i_t \\
f_t \\
o_t \\
g_t \\
\end{pmatrix}
=
\begin{pmatrix}
\sigma(W_i[\bar{x_t},\bar{h}_{t-1}]+b_i) \\
\sigma(W_f[\bar{x_t},\bar{h}_{t-1}]+b_f) \\
\sigma(W_o[\bar{x_t},\bar{h}_{t-1}]+b_o) \\
tanh(W_g[\bar{x_t},\bar{h}_{t-1}]+b_g) \\
\end{pmatrix} \\
\tilde{c}_t = f_t * \bar{c}_{t-1} + i_t * g_t \\
\tilde{h}_t = o_t * tanh(\tilde{c}_t) \\
\quad \\
c_t = e_t \odot \tilde{c}_t + (1-e_t) \odot c_{t-1} \\
h_t = e_t \odot \tilde{h}_t + (1-e_t) \odot h_{t-1}
サンプルコード
def VCLSTM(self, x, h, c, n_in, n_units, batch_size, \
lam, eps):
w_m_x = self.weight_variable('w_m_x', [n_in, 1])
w_m_h = self.weight_variable('w_m_h', [n_units, 1])
b_m = self.bias_variable('b_m', [1])
w_x = self.weight_variable('w_x', [n_in, n_units * 4])
w_h = self.weight_variable('w_h', [n_units, n_units * 4])
b = self.bias_variable('b', [n_units * 4])
m = tf.sigmoid(tf.add(tf.add(tf.matmul(x, w_m_x), \
tf.matmul(h, w_m_h)), b_m))
a_h = m * n_units
b_h = tf.convert_to_tensor(np.array(range(n_units)), \
dtype = tf.float32)
b_h = tf.tile(tf.expand_dims(b_h, axis = 0), \
[batch_size, 1])
e_h = tf.sigmoid(lam * (a_h - b_h)) - (1 - eps)
e_h = tf.nn.relu(tf.sign(e_h))
h_bar = h * e_h
c_bar = c * e_h
a_x = m * n_in
b_x = tf.convert_to_tensor(np.array(range(n_in)), \
dtype = tf.float32)
b_x = tf.tile(tf.expand_dims(b_x, axis = 0), \
[batch_size, 1])
e_x = tf.sigmoid(lam * (a_x - b_x)) - (1 - eps)
e_x = tf.nn.relu(tf.sign(e_x))
x_bar = x * e_x
i, f, o, g = tf.split(tf.add(tf.add(tf.matmul(x_bar, \
w_x), tf.matmul(h_bar, w_h)), b), 4, axis = 1)
i = tf.nn.sigmoid(i)
f = tf.nn.sigmoid(f)
o = tf.nn.sigmoid(o)
g = tf.nn.tanh(g)
c_tilde = tf.add(tf.multiply(f, c_bar), \
tf.multiply(i, g))
h_tilde = tf.multiply(o, tf.nn.tanh(c_tilde))
c = tf.add(tf.multiply(e_h, c_tilde), \
tf.multiply((1 - e_h), c))
h = tf.add(tf.multiply(e_h, h_tilde), \
tf.multiply((1 - e_h), h))
return h, c