こんにちわ!OCEAN'Sの大庭です。
今回は、本番環境でRDSのスケールアップを行いましたのでその手順とログを紹介していきます
概要
まず、RDSがSingle-AZ構成のままスケールアップを行うと、
- インスタンス停止
- インスタンスタイプの変更(スケールアップ)
- インスタンス起動
となってしまい、DBサイズにもよるがサービスダウンタイムが10分弱はかかってしまいます。
そのため、今回は以下の方法でスケールアップを行います
- RDSをMulti-AZ構成に変更
- RDSのスケールアップ
- プライマリにフェイルバック
RDSをMulti−AZに変更
まず、RDSをMulti−AZ構成に変更する。
Multi-AZ構成への変更はダウンタイムが発生しませんが、
シングル AZ からマルチ AZ への変換時のダウンタイムを回避できますが、マルチ AZ への最初の変換時にパフォーマンスに大きな影響が出ることがあります。この影響は、大容量の DB インスタンスや書き込み重視の DB インスタンスでより大きくなります
参考:https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/Concepts.MultiAZ.html
とのことなので、念の為DBのCPU負荷が少ない時間を狙って行うほうが無難です。
ちなみに既存のインスタンスと新しいインスタンスの間では同期レプリケーションが走るので、データの整合性は担保されるということになります。
マルチAZを選択します

「次へ」を押し、確認画面へ
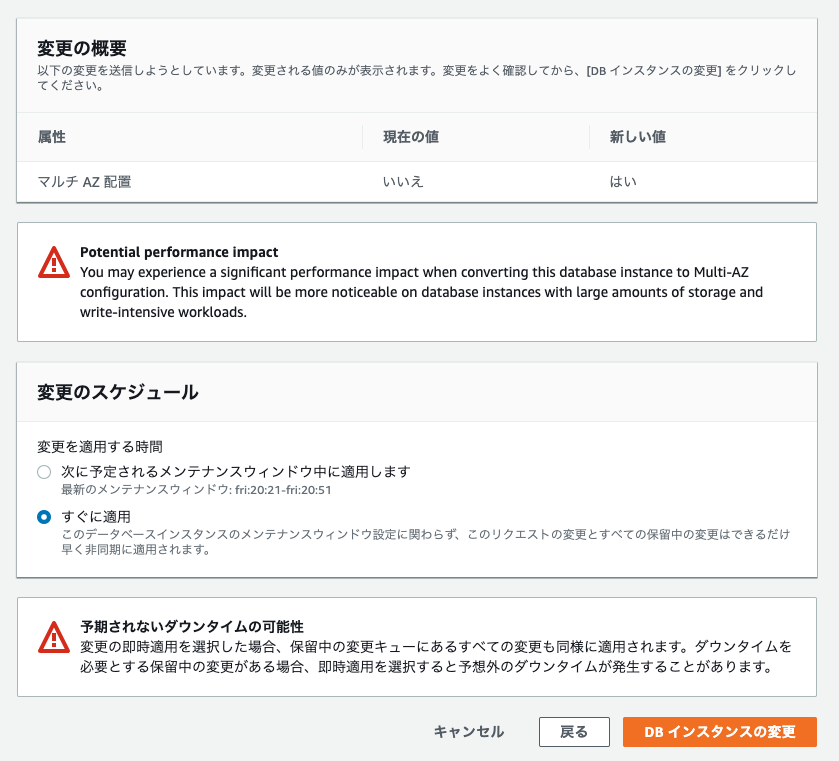
中央付近の英語の警告で、パフォーマンスへの影響があるという警告がでます。
「すぐに適用」をクリックし、、たら、「予期されないダウンタイムの可能性」と表示されました。いきなり想定外。でも今は深夜なのですぐに適用したい。。
「ダウンタイムを必要とする保留中の変更」は無いので、大丈夫なはず!GO!
はじまりました。データベース→ログとイベント→最近のイベントで状況が確認できます

11分後、Multi−AZが終わりました。以外に時間がかかりましたが、ダウンタイムもありませんでした。

気にしていたCPU使用率等も特に大きな動きはありませんでした
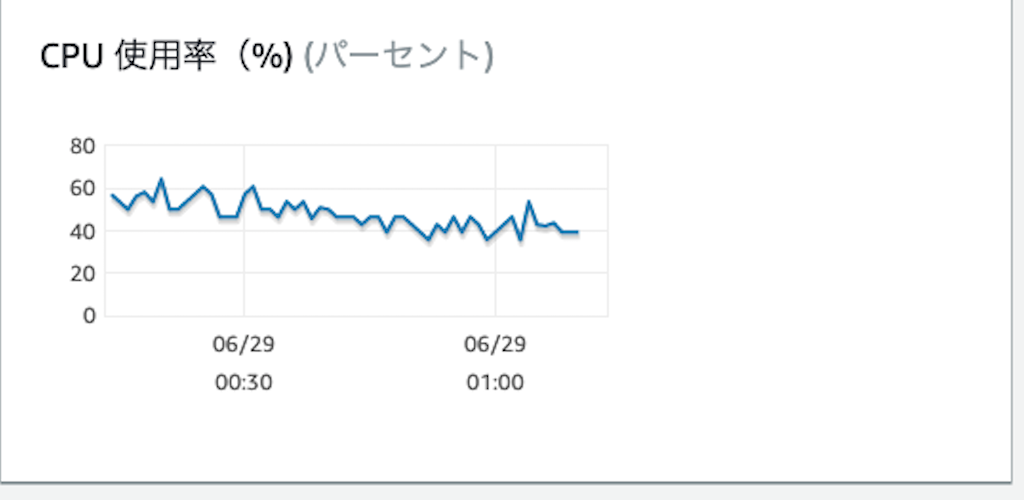
※1時前後が該当の作業時間です↑
データベース→設定→マルチAZの部分も無事「あり」に変わりました

ちなみに、セカンダリのRDSのCPUなどは、「拡張モニタリング」というところで確認できます。
RDSのスケールアップ
いよいよスケールアップ作業に取り掛かりますが、
作業開始時間まで20分あるので一旦ここでコンビニにビールを買いに行きます。
次にDBインスタンスのクラスを、db.m4.xlargeから、db.m4.2xlargeへ変更し、「次へ」をクリック
以下確認画面
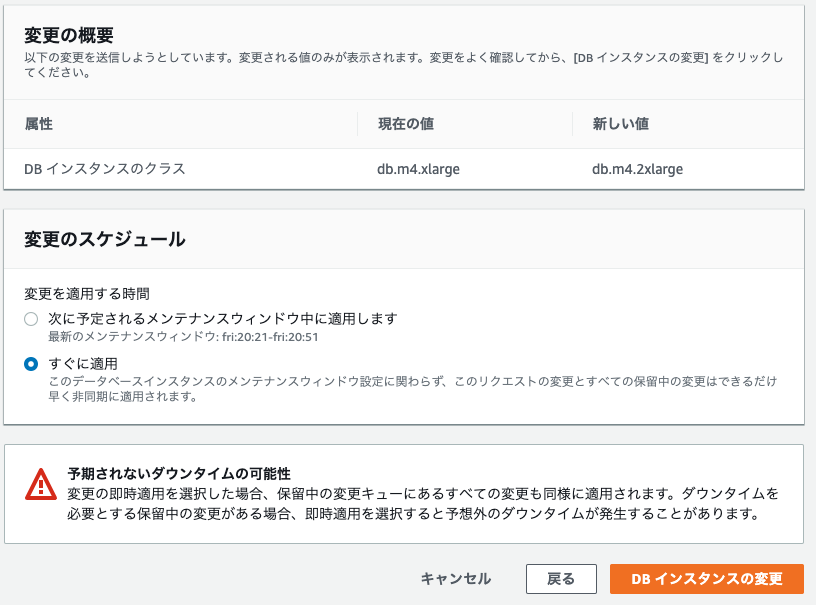
データベース→ログとイベント→最近のイベントで、挙動を見守ります。まだビールを開けてはいけません。
以下途中経過
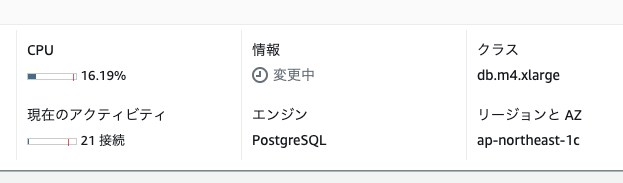
情報が「変更中」
リージョンとAZが「ap-northeast-1c」。お、フェイルオーバーした模様
クラスが「db.m4.xlarge」。まだここは2xlargeになっていない。
約19分後、無事にすべての工程が終わりました!。イベントの記録は以下の通り。
| 時間 | システムノート |
|---|---|
| Fri, 28 Jun 2019 16:59:31 GMT | Applying modification to database instance class |
| Fri, 28 Jun 2019 17:06:11 GMT | DB instance shutdown |
| Fri, 28 Jun 2019 17:07:00 GMT | Multi-AZ instance failover started. |
| Fri, 28 Jun 2019 17:07:08 GMT | DB instance restarted |
| Fri, 28 Jun 2019 17:07:30 GMT | Multi-AZ instance failover completed |
| Fri, 28 Jun 2019 17:18:40 GMT | Finished applying modification to DB instance class |
ダウンタイムは
DB instance shutdown
〜
Multi-AZ instance failover completed
の間なので、1分19秒。早い
確認したところクラスもきちんと「db.m4.2xlarge」に変わりました。
プライマリにフェイルバック
現在セカンダリRDSのアベイラビリティーゾーンは「ap-northeast-1c」の方で動いている状態です。
EC2やその他のサーバーは「ap-northeast-1a」で動作しているため、このままではパフォーマンスが気になります。
実際フェイルオーバー後、サーバー監視ツールNewRelicを確認したところパフォーマンスが著しく低下していました。
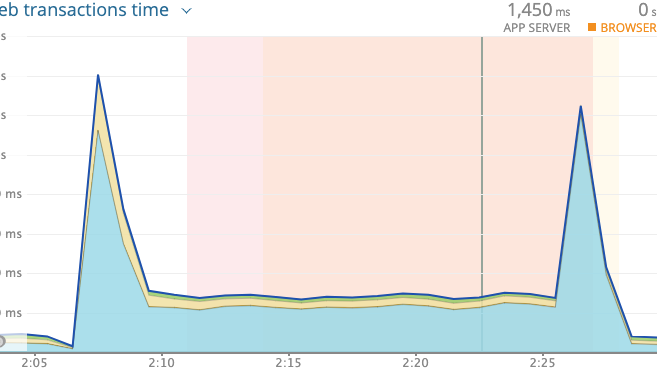
※1つ目の大きな山の後がセカンダリのRDSで動いている期間です。2つ目の大きな山はフェイルバックしたところ
このままだとパフォーマンス的にOUTなので、元のプライマリRDSにフェイルバックします。DBインスタンスを再起動させる際、「フェイルオーバーし再起動しますか?」にチェックをつけ再起動すればもとのプライマリRDSに戻ります。ただしダウンタイムが発生するので注意してください
以下実行ログ。
25秒でフェイルバックが完了しました
| 時間 | システムノート |
|---|---|
| Fri, 28 Jun 2019 17:26:05 GMT | Multi-AZ instance failover started. |
| Fri, 28 Jun 2019 17:26:12 GMT | DB instance restarted |
| Fri, 28 Jun 2019 17:26:30 GMT | Multi-AZ instance failover completed |
NewRelicのパフォーマンスも元に戻りました
後はサービスの動作確認を行い問題なければ終了です。

お疲れさまでした![]()