本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
著者: Daniel Liden, Senior Developer Advocate
イントロダクション: MLflow MCPサーバー
MLflow 3.4では、ClaudeのようなAIアシスタントがあなたのMLflowトレースと直接やり取りをできるようにする公式のMCPサーバーが導入されました。この記事では、仮想環境にMLflowをインストールした際にどのようにセットアップするのかを探索し、ClaudeデスクトップとClaude Codeの両方で生成AIアプリケーションのトレースをデバッグ、分析する実践的な使い方を説明します。
MLflowトレーシングは、AIモデルやエージェント実行チェーンのすべてのステップに関連づけられる、すべての入力、出力、メタデータをキャプチャできるようにするパワフルなAI可観測性のツールです。1行のコードでOpenAI、Anthropic、LangChain、LlamaIndexのような様々なプロバイダーと連携します。トレーシングは、ツールの呼び出し、収集、AIのレスポンス、あなたが含めたいと思うすべてのもの含めて、AIアプリケーションの全体の実行チェーンに対するきめ細かい洞察を提供します。
ず1: MLflow UIにおいてネストされたスパンを表示するMLflowトレースの例
しかし、トレースのキャプチャは第一歩に過ぎません: すべてのトレースデータを入手したら、我々のAIアプリケーションを改善するために活用する必要があります。トレースに対して、人間、AI、プログラムによる評価を可能にする既存の洗練された評価機機能に加えて、MLflow 3.4ではClaudeデスクトップのようなAIアプリケーションや、Cursorのようなコードアシスタントに、トレースとやり取りを行う機能を提供するMCPサーバーが導入されました。
初めてMCPサーバーについて学んでいるのであれば、私のModel Context Protocol入門時記事をご覧ください: パート1、パート2。
MCPサーバーによって、これらのツールはトレースデータ、フィードバックの記録、メタデータの管理、トレースや評価結果の削除が可能になります。
この記事の残りの部分では、MCPサーバーの設定と使用法を見ていくことになります。
MLflowトレーシングのセットアップ
MLflowのセットアップ
この例では、uvパッケージマネージャを用いてMLflowをインストールします。ローカルの仮想環境にインストールを行い、我々のローカルMLflowサーバーに保存されたトレースを検索、分析するためにMCPサーバーを活用します。
はじめに、この例のために新規ディレクトリを作成し、MLflowをインストールします。また、いくつかのその他のプロジェクト依存関係もインストールします。
uv add mlflow openai beautifulsoup4 requests python-dotenv 'click>=7.0,<8.3.0'
MLflow 3.4時点では、MLflow MCPサーバーはclickバージョン8.3.0ではうまく動かないので、別のバージョンを使用するように手動で指定する必要があります。これは既知の問題であり、今後のMLflowリリースでは解決されるでしょう。
いくつかのサンプルトレースデータを作成するためにOpenAIモデルにクエリーするので、OpenAIクライアントがOpenAI APIキーにアクセスできることを確認する必要があります。このためには、以下のように.envファイルを作成します:
#.env
OPENAI_API_KEY=<your_openai_key>
これで、MLflowトラッキングサーバーを起動し、MLflow UIでトレースを確認できるUIにアクセスすることができます。ここでは、MLflowトラッキングサーバーの設定について詳細を学ぶことができます。
探索のためのいくつかのトレースデータを作成
あなたがすでに探索用のトレースデータを持っているのであれば、このセクションはスキップできます。
MLflow MCPサーバーによってAIツールがどのようにトレースデータを操作するのかをデモンストレーションするために、はじめにいくつかのトレースデータを作成する必要があります。ここでは3つの異なるサンプルトレースを作成します: OpenAIモデルに対するシンプルなクエリーが失敗するケース、成功するケース、Webページからのテキスト収集を行う追加ステップを含むケースです。
はじめに、依存関係をインポートし、いくつかのセットアップのステップに対応します:
import mlflow
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
import os
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Set up an MLflow experiment
experiment_name = "mcp-server-demo"
mlflow.set_experiment(experiment_name)
# Enable OpenAI autologging to capture traces
mlflow.openai.autolog()
# Initialize OpenAI client
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
上のコードブロックを実行することで、トレースが記録されるmcp-server-demoという新規のMLflowエクスペリメントが作成されます。また、上で作成した.envファイルからOpenAI APIキーをロードし、OpenAIクライアントをセットアップします。これで、OpenAIモデルにクエリーを行っていくつかのトレースを記録する準備ができました!
トレース例1: APIコールの失敗
MLflowトレーシングは、AIアプリケーションの失敗のデバッグに非常に有用になる詳細なエラー情報をキャプチャいます。ここでは、エラーになるように存在しないOpenAIモデルをコールしてみようとします:
response = client.chat.completions.create(
model="gpt-nonexistent-model", # Invalid model name
messages=[{"role": "user", "content": "Hello, world!"}],
max_tokens=50
)
トレース例2: シンプルなAPIコールの成功
2つ目の例は同様にOpenAIモデルに対する単一の呼び出しとなります - 今回は実際に存在するモデルです。
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": "Explain what MLflow is in one sentence."}]
)
トレース例3: マルチステップの収集プロセス
3つ目の例はさらに大規模なものになります。Webページからテキストを抽出し、要約のためにGPT-5に引き渡すワークフローを定義する小さなスクリプトを作成します。Webページをスクレイピングする関数を手動でトレースするために@mlflow.trace()デコレーターを使用し、WebスクレイピングとOpenAIのコンプリーションの両方が単一の親スパンにキャプチャされるように、親のスパンで全体のプロセスをラッピングします。
@mlflow.trace(name="scrape_webpage", span_type="RETRIEVER")
def scrape_webpage(url: str) -> dict:
"""Scrape content from a webpage - creates a nested span."""
response = requests.get(url, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
# Extract title and paragraphs
title = soup.find('title')
title_text = title.get_text().strip() if title else "No title found"
paragraphs = soup.find_all('p')
content = ' '.join([p.get_text().strip() for p in paragraphs[:5]]) # First 5 paragraphs
return {
"title": title_text,
"content": content[:1000], # Limit content length
"url": url,
"status_code": response.status_code
}
def summarize_content(content: str) -> str:
"""Summarize content using OpenAI - creates nested span within main trace."""
prompt = f"Summarize the following content:\n\n{content}"
# This OpenAI call will be automatically traced due to autologging
response = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": prompt}],
)
return response.choices[0].message.content
def multi_step_retrieval_process(url: str) -> dict:
"""Complete retrieval and summarization pipeline with nested spans."""
with mlflow.start_span(name="summarize_content", span_type="CHAIN") as parent_span:
parent_span.set_inputs(url)
scraped_data = scrape_webpage(url)
summary = summarize_content(scraped_data["content"])
parent_span.set_outputs(summary)
return {
"url": url,
"title": scraped_data["title"],
"content_length": len(scraped_data["content"]),
"summary": summary
}
url = "https://mlflow.org/docs/latest/genai/mcp/"
result = multi_step_retrieval_process(url)
# Print experiment ID for use with Claude
experiment = mlflow.get_experiment_by_name(experiment_name)
print(f"\nSuccessfully generated traces in experiment: {experiment.name}")
print(f"Use this Experiment ID with Claude: {experiment.experiment_id}")
このセクションのすべてのPythonコードをファイル(generate_traces.pyなど)に保存し、uv run python generate_traces.pyで実行する、あるいはJupyterノートブックでコードセルを実行します。このスクリプトは、以下のClaudeの例で必要となるあなたのエクスペリメントのIDをプリントします。
MLflow MCPサーバーの活用
これで、MLflowをセットアップして幾つかのサンプルトレースを生成したので、AIモデルの助けを借りてこれらを探索しましょう!ClaudeデスクトップとClaude Codeでの活用法を説明します。
Claudeデスクトップ
以下のようにClaudeデスクトップでMLFlow MCPサーバーに接続できます:
-
Claudeデスクトップアプリのダウンロード。
-
設定メニューでDeveloperをクリックし、Edit Configをクリック:
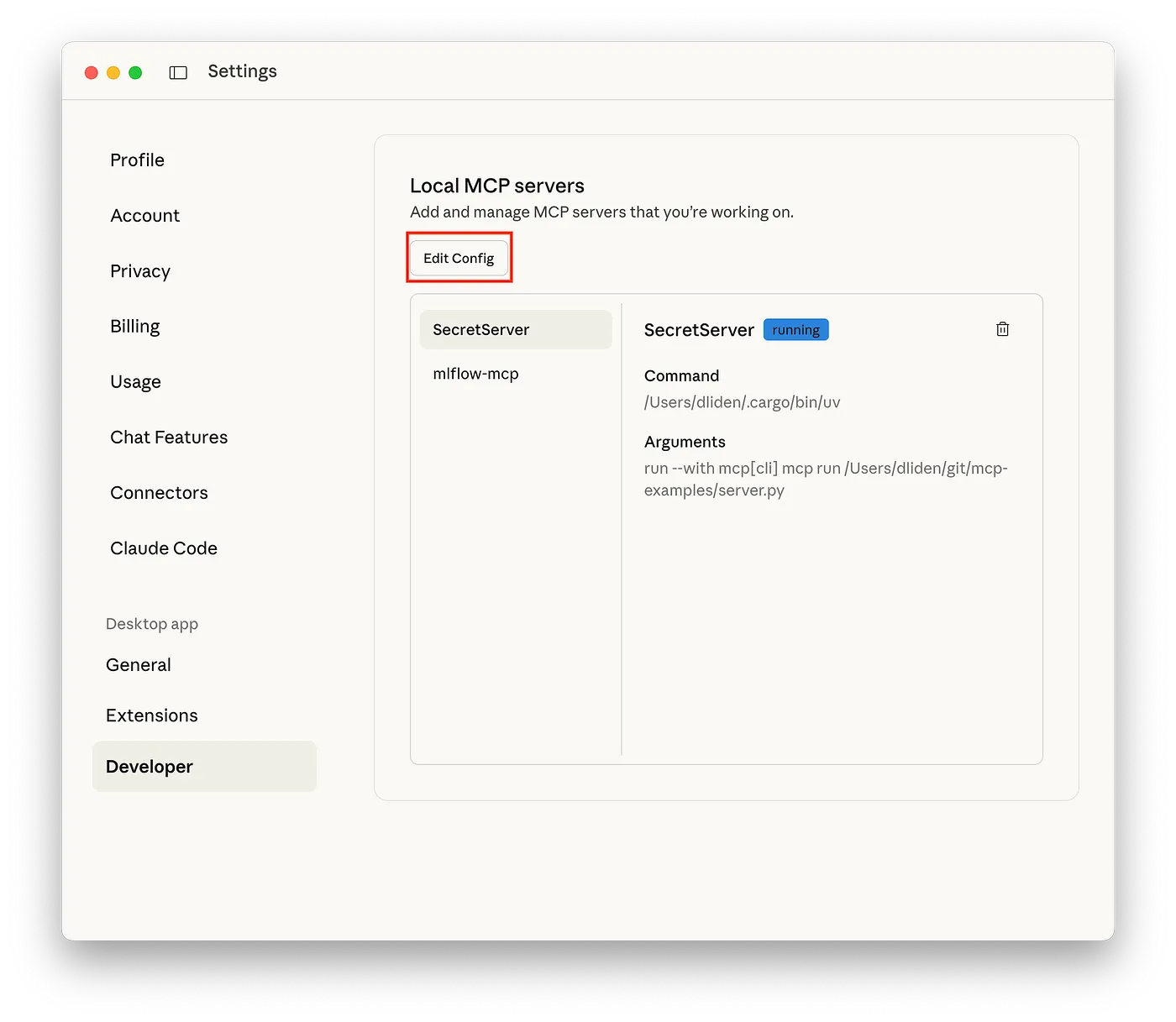
図2: Developerメニューを表示するClaudeデスクトップの設定画面
これによって、様々なClaudeアプリケーションと設定ファイルを含むディレクトリが開きます。claude_desktop_config.jsonというファイルをオープン(あるいは作成)します。 -
以下を
laude_desktop_config.jsonに貼り付けて、プロジェクトディレクトリとトラッキングURIをあなたのプロジェクトに合わせて変更します:{ "mcpServers": { "mlflow-mcp": { "command": "uv", "args": ["run", "--directory", "<path-to-your-project-directory>", "mlflow", "mcp", "run"], "env": { "MLFLOW_TRACKING_URI": "http://127.0.0.1:5000" } } } }MCPサーバーが接続に失敗した場合には、コマンドの値で単なる「uv」ではなく、uvの実行ファイルに対するフルパスを使う必要があるかもしれません。この条件は、システム設定によって変動します。フルパスを見つけるには、ターミナルで
which uvを実行します(例: /Users/username/.cargo/bin/uv)。公式のドキュメントの設定と異なる主要な違いを含むいくつかの注意点があります:
- uvの仮想環境にMLflowをインストールしたので、適切なMLflowインストレーションを用いてMLflow MCPサーバーを呼び出すようにする必要があります。uvが我々のプロジェクトディレクトリの仮想環境にインストールされたMLflow実行ファイルを実行すべきであることを指示するためにdirectoryフラグを使用しています。グローバルにMLflowをインストールしている場合、代わりに公式ドキュメントの設定を参照してください。
- MLflowトラッキングURIがデフォルト以外のホスト/ポートで稼働している場合、
MLFLOW_TRACKING_URIの値を変更する必要があります。
-
Claudeデスクトップを再起動します。再起動後に、Claudeデスクトップの接続メニューに
mlflow-mcpが表示されるはずです:
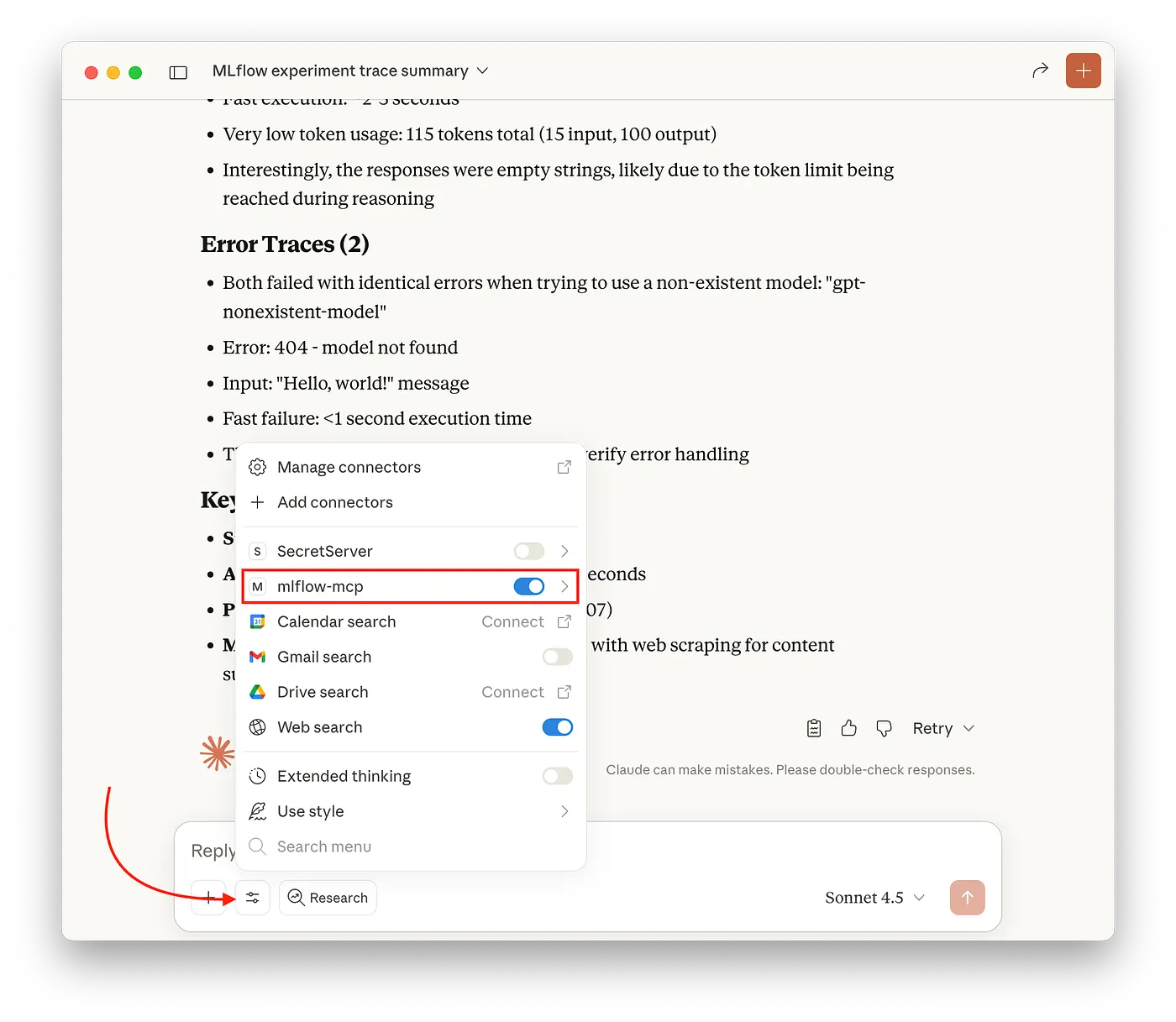
図3: Claudeデスクトップの接続に表示されるMLflow MCPサーバー
試してみましょう!
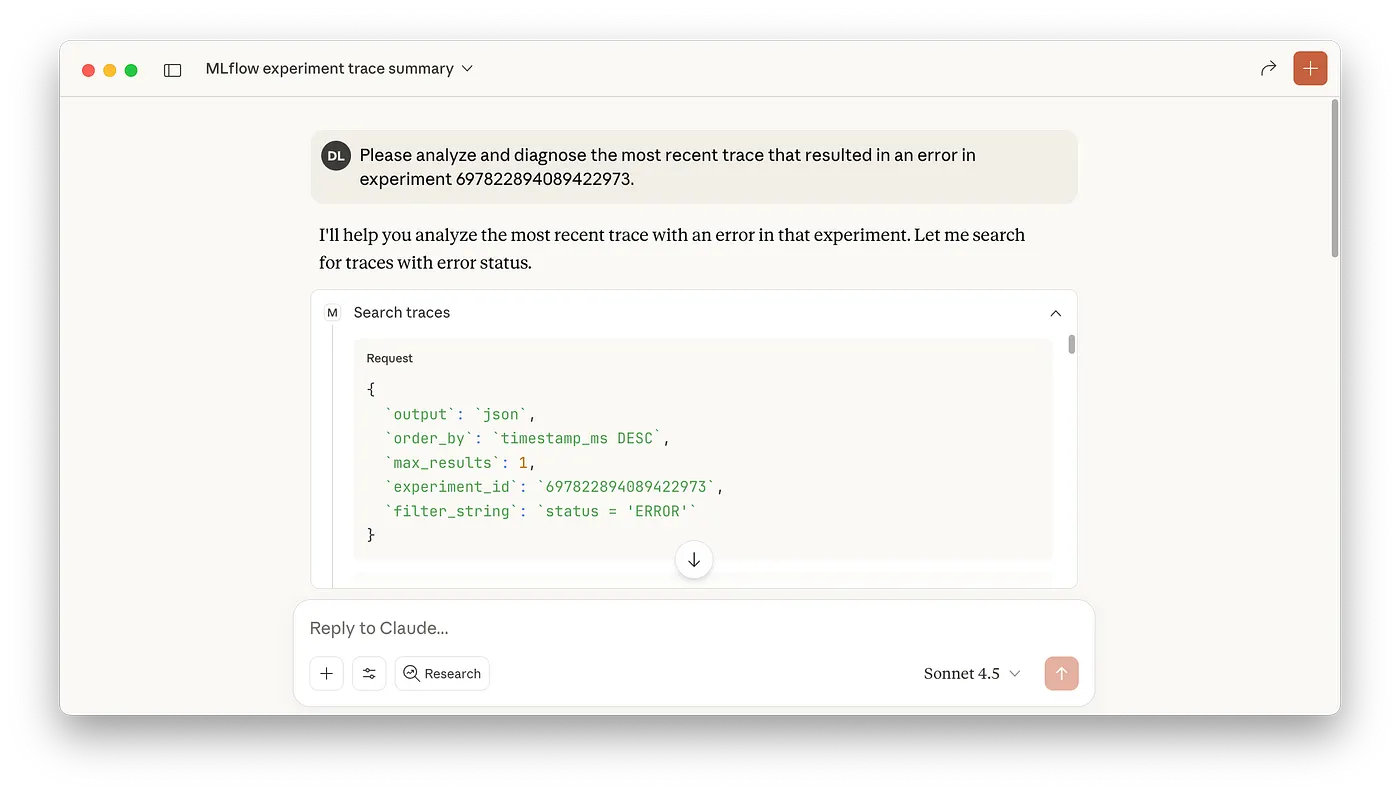
エラーが含まれるトレースの特定と診断をClaudeにお願いしましょう。
Claudeにトレースの操作をお願いする際、エクスペリメントIDを指定する必要があります。ClaudeはエクスペリメントIDを推定することができません。上のトレース生成コードを実行した場合、コンソールにエクスペリメントIDが表示されます。また、MLflowのUIでエクスペリメントタブにアクセスし、トレースを記録したエクスペリメントをクリックし、エクスペリメント名の隣にある情報アイコン(丸の中にiのマーク)をクリックすることでエクスペリメントIDを見つけることができます。あるいは、デフォルトのエクスペリメントを指定するために、MCPサーバーの設定に環境変数MLFLOW_EXPERIMENT_IDを追加することができます。
私は以下をお願いしました:
エクスペリメント697822894089422973のエラーを引き起こした最新のトレースを解析、診断してください。
ClaudeはSearch tracesをコールし、適切なトレースを特定するためにget trace関数を呼び出し、問題の診断結果と推奨の次のステップでレスポンスを返しました:
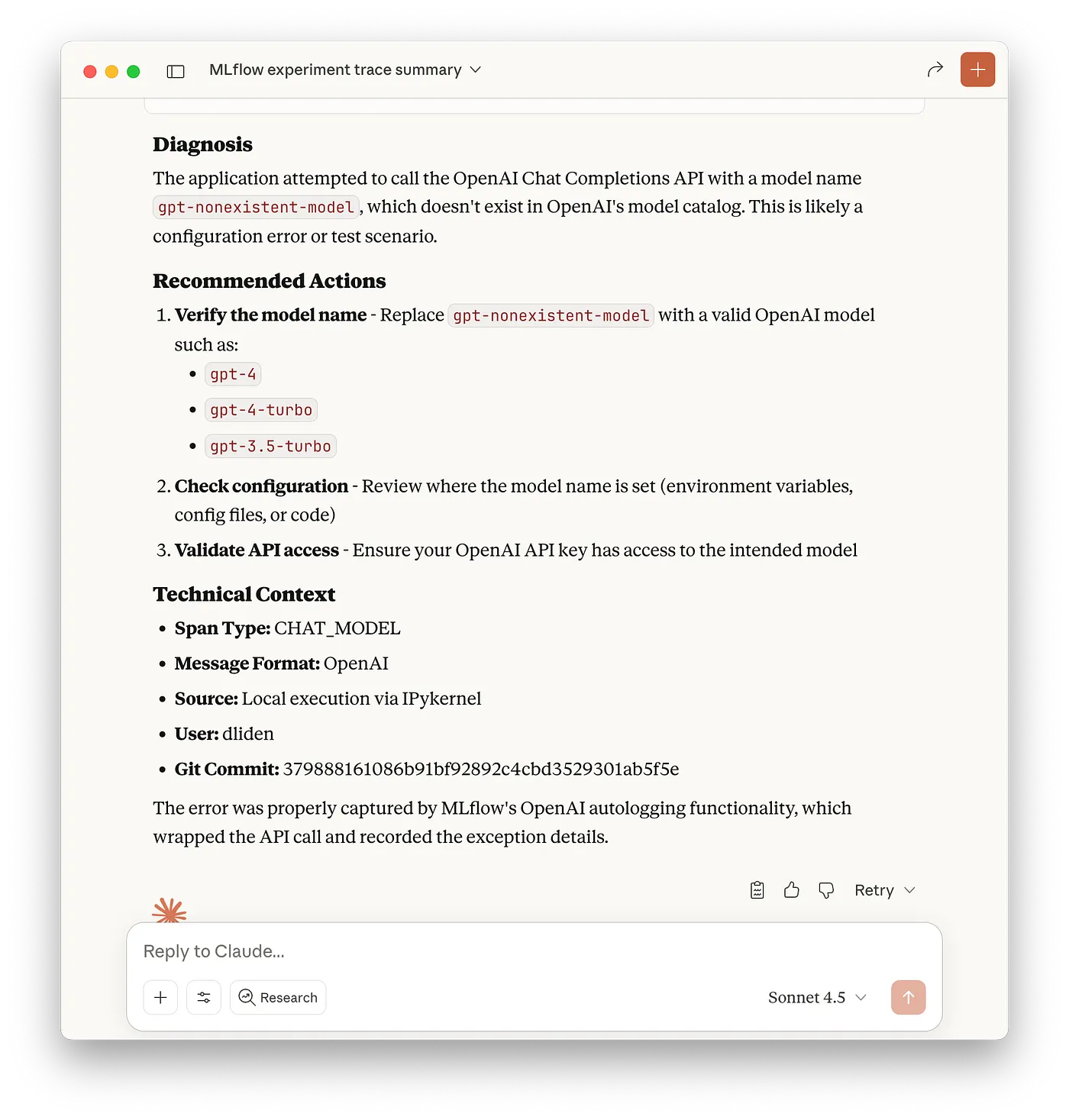
図4: 失敗したトレースを分析し、診断情報を提示するClaudeデスクトップ
Claude Code
Claude CodeとMLflow MCPサーバーが動作するようにする設定はClaudeデスクトップの設定とほとんど一緒です。別のファイル(あなたのプロジェクトルートディレクトリの.mcp.json)にJSON設定を追加する必要があるだけです。スタートするにはこれらのステップに従ってください:
-
Claude Codeのインストール。
-
以前のセクションの設定JSONスニペットをあなたのプロジェクトのルートディレクトリの
.mcp.jsonに追加します。ファイルがない場合には作成します。これはClaude CodeにMCPサーバーを追加する幾つかの方法のうちの一つです。他のオプションに関してはClaude Code docsをご覧ください。
-
プロジェクトルートディレクトリからclaudeを呼び出してClaude Codeを起動します。
-
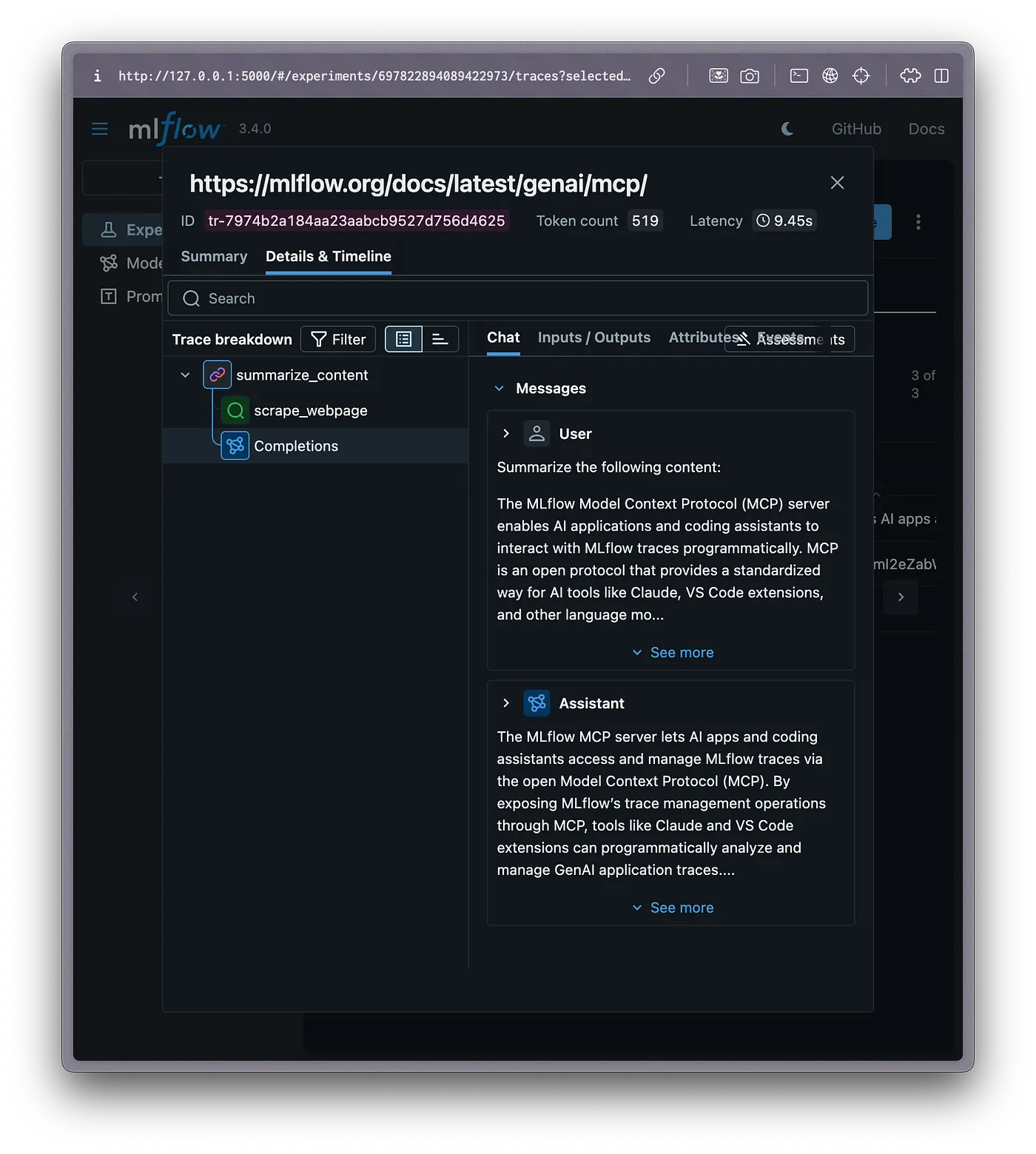
試してみましょう!収集ステップを伴うトレースを見つけて、動作しているかどうかを評価するようにClaudeにお願いしましょう。
エクスペリメント697822894089422973のトレースを参照ください。収集コンポーネントを持つ最新のトレースを特定し、何が収集され、収集がうまく行ったかどうかを教えてください。
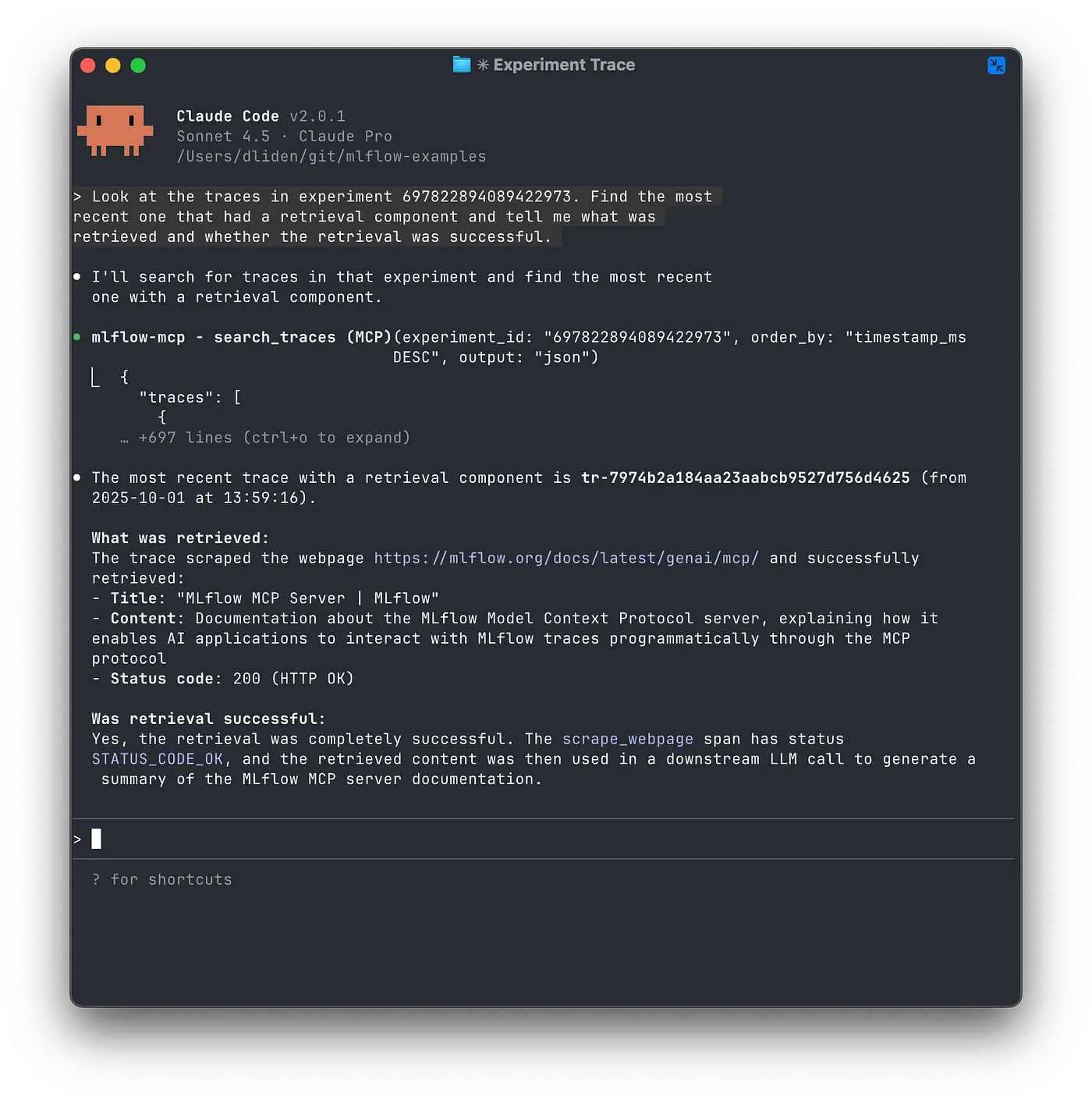
図5: 収集を行うトレースを分析し、結果を報告するClaude Code
Claude Coadeは、MCPサーバーを通じて利用可能なツールを用いて適切なトレースを特定し、質問に回答することができました。
次のステップと観測結果
AIをデバッグするためにAIを用いることを満足させるための何かがあります。MLflow MCPサーバーは、トレースのキャプチャと実際にそれらを活用するループをクローズさせます: あなたのAIアシスタントはあなたの他のAIアシスタントが失敗した理由を理解する助けとなってくれます。
MLflowのドキュメントではいくつかのユースケースを提示していますが、真の価値はあなた自身のパターンを探索することで得られます:
- 一般的な失敗モードを特定するために、成功 vs. 失敗のトレースを比較するようにClaudeに依頼する
- コストを最適化する際に、特定のトークン利用パターンを持つトレースを検索させる
- 収集が不適切なコンテンツを返却した際のトレースを特定し、あなたのチャンク戦略を試行錯誤する際に活用する
- 特定のモデル設定が定常的に優れた結果を生み出しているタイミングを特定させる
- Claude Codeがあなたのエージェントのコードとトレースにアクセスできるようにし、エディタを離れることなしに、失敗のレビュー、修正案の提示、試行錯誤を可能にする
セットアップは5分で終わりますが、設定さえすれば、トレースデータはUIを通じて検索クエリーを手作りしたり深掘りするものではなく、会話をおこなうことのできる何かに変化するのです。