概要
-
openBLAS の行列演算に用いる Thread数 によって、演算の所要時間がどう変わるか手元のPCで測定を行いました。
- openBLAS の行列演算は、CPUのコア数までは openBLASのThread数を増やした方が (比例とならず鈍りがあっても)演算時間が短くなっていくと思い込んでいました。
- ↑だと説明つかない現象を見聞きしたので、手元の環境で確認しました。
- 手元の環境では、gemm も gemv も コア数未満のThread 数で、最小の演算時間になりました。
-
参考になれば幸いです。
関連記事
行列の積演算で openBLAS cuBLAS を体感する
測定環境は、↑の記事を参照ください。(変わってません…)
gemm()
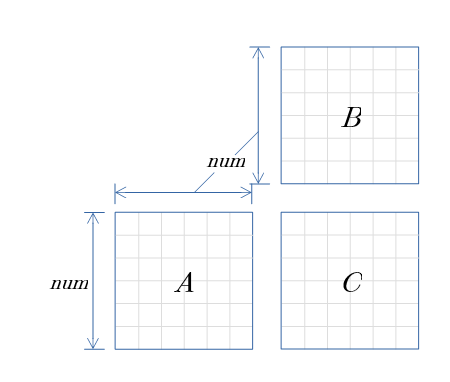
- 一辺 num の正方行列 の 積 ↓ の演算時間を測定する。
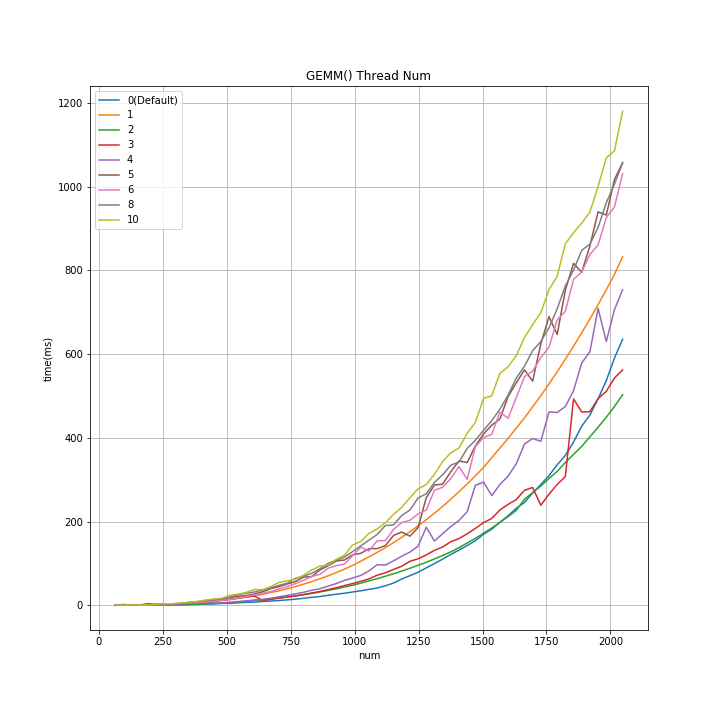
- ↓のグラフの横軸は↑のnum 数、縦軸は測定した行列演算の所要時間(試行10回の平均値)。
- num の初期値は 64 で 32 毎に刻んでいる。
- Thread数 毎の測定結果を重畳している。
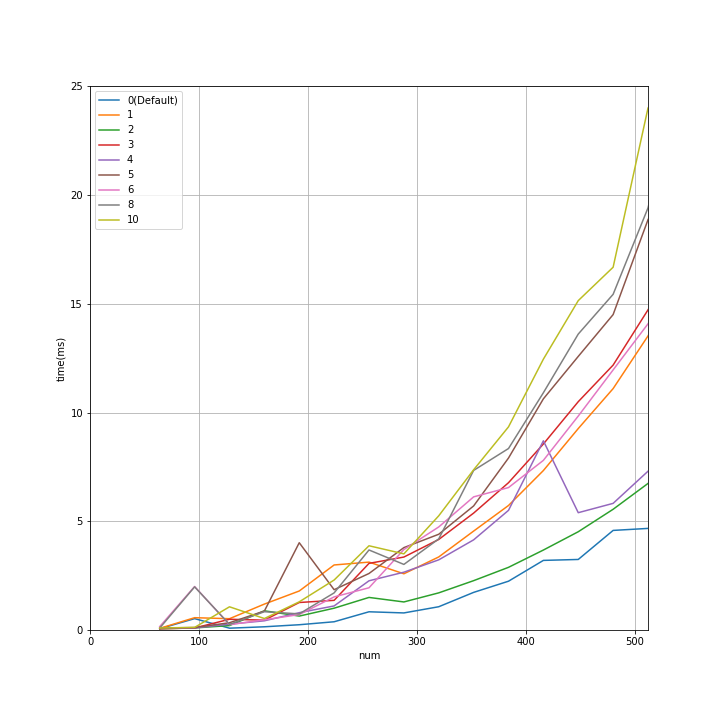
- ↓のグラフは、↑のグラフの num < 512 での拡大
グラフから読み取った事
- 2 thread は 1thread の 約半分の演算時間。ここは予想通り。
- 予想では、3 thread は 2 thread より 全般的に演算時間は短くなる、と想像していたが、そうはならなかった。
- コア数以上のthread数を指定した場合には、1threadより悪化=演算時間が長くなっている。
- num が 1500位までは openblas_set_num_threads(0) が 最小演算時間。
- openblas_set_num_threads(0) だと 何threadを割り当てるのだろう?
- 動的に割り当てる? とはいえ 2 Thread より効率よくするのってどうやってるのだろう?
- openblas_set_num_threads(0) だと 何threadを割り当てるのだろう?
gemv()
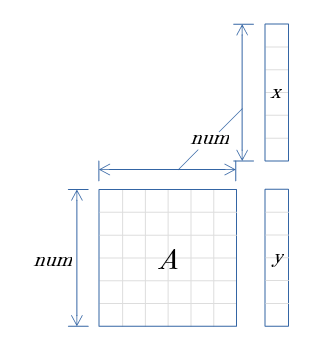
- 行列Aを1辺 num の正方行列とした、行列とベクトルの積
- ↓のグラフの横軸は↑のnum 数、縦軸は測定した行列演算の所要時間(試行10回の平均値)。
- num の初期値は 64 で 32 毎に刻んでいる。
- Thread数 毎の測定結果を重畳している。
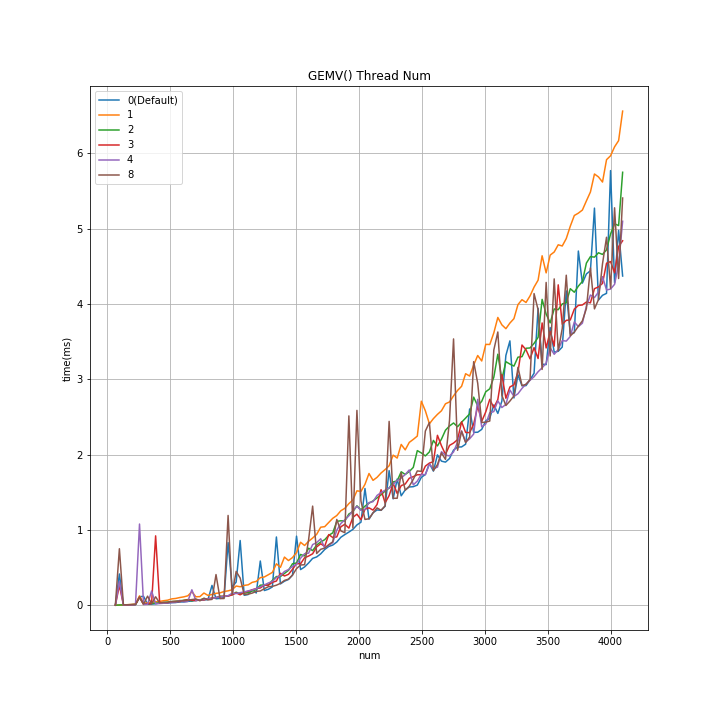
グラフから読み取った事
- 1 thread を 2 thread にしても、演算時間の短縮は20% 位。
- thread 数を増やしても、1 thread に比べての演算時間短縮は 30% 位。
-
GEMV() の演算は、GEMM()に比べたら 1次元分計算量は軽い。
- thread 毎に計算を分配する所の処理の比が、相対的に大きくなっている?
-
GEMV() 中心の演算であれば、openBLAS の Thread 数は 1 にしておいて、利用するアプリ側をマルチスレッド構成にして、openBLAS 関数を複数並列に動かした方が、トータルの演算時間は短くできそう。
- ↑思い込みの可能性もあるので、後で確認する。 (追記)確認した。↓
追記: 実験用プロセスを並列させて 計算所要時間
- 実験用に並列に走らせるプロセス数をP 、その際のopenBLASのThread数をTとする。
- 同じ計算量を、PとT の値を変えて実施し、所要時間を測定した。
- 計算は、↑の正方行列のGEMV() num 64~4096 step 32 が各num での試行回数が合計80 回 (P が2以上の場合、全プロセスでの試行回数の合計が80になるように、各プロセスの試行回数を調整)
結果
| P | T | 所要時間(秒) |
|---|---|---|
| 1 | Default | 33 |
| 1 | 1 | 37 |
| 1 | 2 | 34 |
| 1 | 4 | 34 |
| 1 | 8 | 34 |
| 2 | 1 | 31 |
| 4 | 1 | 36 |
| 8 | 1 | 50 |
結果から読み取った事
- openBLAS の Thread数を 1として、openBLASを呼び出す側のProcess(thread)数を多くした方が、トータルの演算時間は有利になるとの仮説もまた思い込みだった様だ…。