この論文は、CNNで抽出されたFeatureを他のタスクに使用した時のPerformanceについて調べた論文です。
CNNは、OverFeat Networkを使用しています。
taskは、下記の通りです。
下記Taskは、OverFeatのOriginal TaskとDataからどんどん離れるようになっています。
- image classification
- scene recognition
- fine grained recognition
- attribute detection
- image retrieval
CNN
CNNはOverFeat Networkを使用している。
2つあるうちのこちらの方を使用。
Architectureはここを参照した。
'accurate' network (table 2 in http://arxiv.org/abs/1312.6229):
input 3x221x221
stage 1: convo: 7×7 stride 2×2; ReLU; maxpool: 3×3 stride 3×3; output (layer 3): 96x36x36
stage 2: convo: 7×7 stride 1×1; ReLU; maxpool: 2×2 stride 2×2; output (layer 6): 256x15x15
stage 3: convo: 3×3 stride 1×1 0-padded; ReLU; output (layer 9) 512x15x15
stage 4: convo: 3×3 stride 1×1 0-padded; ReLU; output (layer 12) 512x15x15
stage 5: convo: 3×3 stride 1×1 0-padded; ReLU; output (layer 15) 1024x15x15
stage 6: convo: 3×3 stride 1×1 0-padded; ReLU; maxpool: 3×3 stride 3×3; output (layer 19) 1024x5x5
stage 7: convo: 5×5 stride 1×1; ReLU; output (layer 21) 4096x1x1
stage 8: full; ReLU; output (layer 23) 4096x1x1
stage 9: full; output (layer 24) 1000x1x1
output stage: softmax; output (layer 25) 1000x1x1
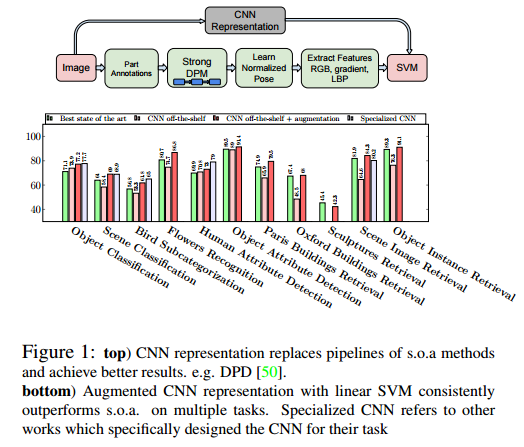
Visual Classification
・Featureは、CNNの最初のfully connected layer(layer 22)の出力を使用
・入力画像は、221x221にresizeかcrop
・Featureはl2 normalizationする
・4096次元のFeatureをSVMの入力とする(CNN-SVM)
・training dataのaugmentationをしたものをCNNaug+SVMとする
・VOC Object Classification, UIUC Object attributesの時は、one against allをそれ以外の時はone again one with votingを使用。
one against all は、あるClassとそれ以外という判別を行って、一番スコアーが高いものを分類Classとする手法
one against one votingは、1対1で判別を行って、投票していき最も得票が多かったものを分類Classとする手法
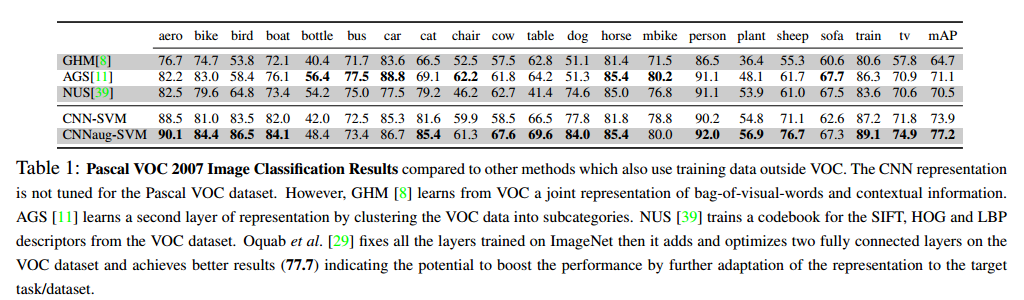
Image Classification
PASCALL VOC Object Classification
・AP(average precision)で評価
・すべてのCategoryで同等かそれ以上の性能が出ている
(a)FeatureのLayerを変えた時の性能の変化
・後段の出力ほど性能がよくなっている
・4,8,etcで性能が落ちているのは、ReLUの出力のところ
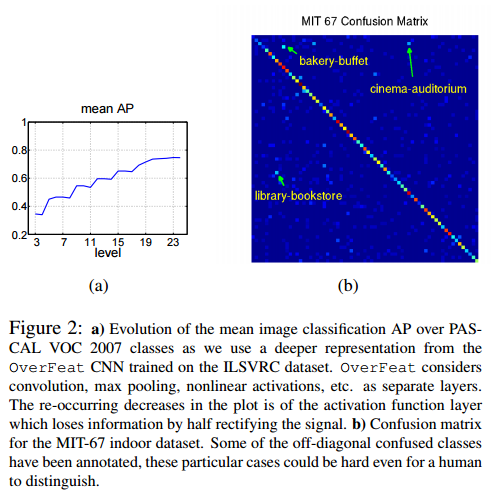
MIT 67 Scene Classification
・CNNは今までの最高レベルと同等の性能が出ている
・いくつかのSceneはbackery-buffet, cinema-auditorium, library-bookstoreは性能が悪いが人間でも難しいシーン
Object Detection
自分たちではやらなかったけど、Girshick et al.がすでに行った結果によると、mAPが46.2でこれまでより10%上回っている
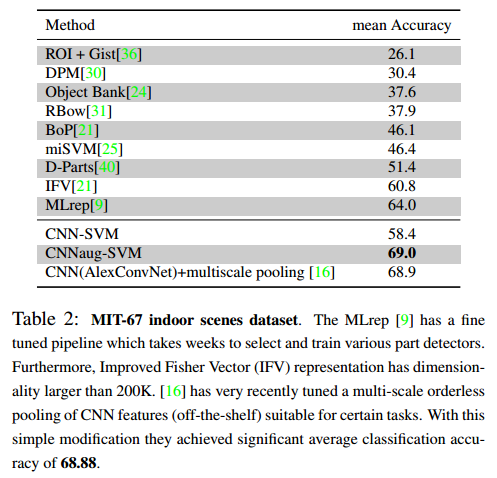
Fine grained Recognition
・花の種類とか犬の品種などの、subclassを認識するタスク
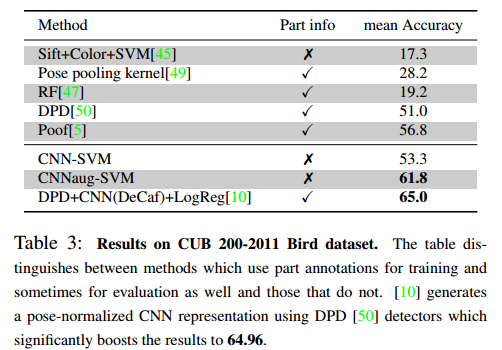
CUB 200-2011 Bird dataset
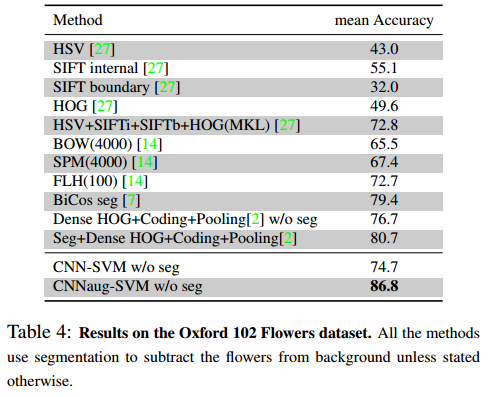
Oxford 102 Flowers dataset
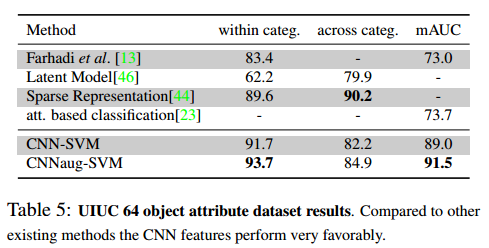
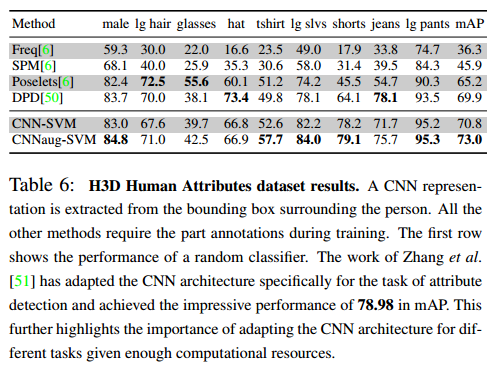
Attribute Detection
Visual Instance Retrieval
・query imageに写っているものと同じものが写っているreference imageを探すタスク
・query imageをsub patchに切り出す
・切り出したPatchのCNN representationを求める
・reference imageのsub patchとのL2 distanceを計算し、最小値のpatchを探す
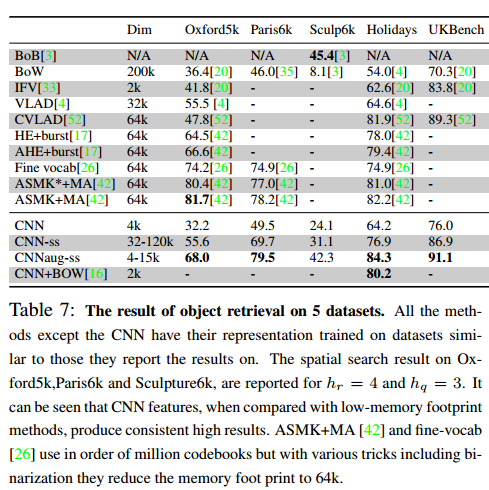
最後に
CNNの抽出したFeatureを別のタスクに使用しても性能が出ていることがわかる有意義な知見