Hypercolumn
認識処理などに使われるCNNの最終Layerの出力は、位置精度が必要なAlgorithmにとっては粗すぎるし、かといって最初のLayerは位置精度はいいけど、Semanticな情報がない。なのでPyramid Imageみたいに、CNNの各Layerの同じ位置の出力をまとめて一つのFeature(Hypercolumn)として使うというのが大まかな内容です。その時に各Layerの出力サイズが異なるので、入力サイズと合わせるように拡大します。
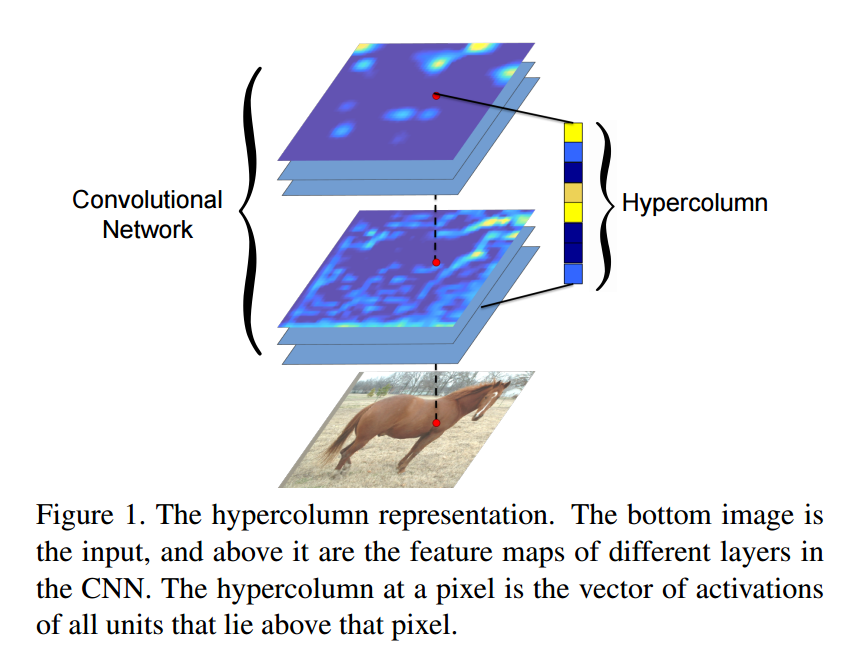
この論文ではHypercolumnとしてまとめるLayerは全Layerではなく、適当な層を選んでいます。
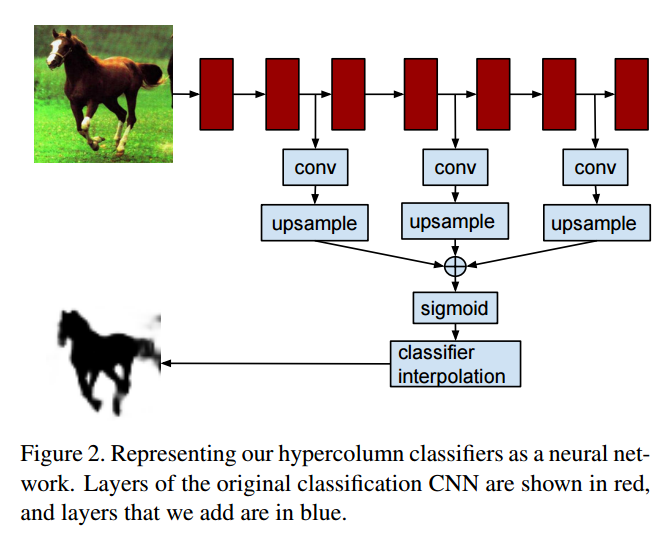
論文中では、fc7とconv4とpool2を使うと書いてあったのですが、上の図しかなくどこのことだかさっぱりわからないです。
著者の前の論文"Simultaneous detection and segmentation"を見ると下記の図があります。
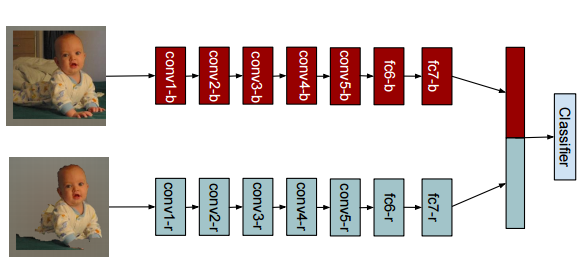
これと一致した場所のFeatureを取り出しているようです。そもそも実験の目的は、この前の論文の結果をRefinementしたいということなので。
ただし、馬の絵の図の最後のFeatureを抜き出している位置がfc6になっていて、論文中はfc7って書いてあるから、図が間違っているのか何なのかよくわからないです。細かいことは気にするなということかな?
やりたいことは、物体検出をBounding Boxではなく、Segmentationでやりたいと言うことのようです。
以降は、実験結果が書いてあるのですが、あんまりおもしろくないので飛ばします。
ただ、Hypercolumnというのは面白いですし、違う著者の別の論文ですが”Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks”の中でも各Layerの出力を一個にまとめて使ったりしています。Hypercolumnの論文とIONの論文の共著に同じ人(Ross Girshickさん)がいるので、そのへんの関係かもしれないです。
ただIONの論文では、各Layerの出力の大きさが異なるから、層ごとに正規化して結合するということをしているので、Hypercolumnでもしたほうがいいかもしれないです。試していないのでわかりませんが。
Hypercolumn可視化
Hypercolumnに関しては、下記のサイトでVGG-16を使ったHypercolumnの可視化をされている方がいます。
http://blog.christianperone.com/2016/01/convolutional-hypercolumns-in-python/
Automatic Colorization
Hypercolumnに興味を持ったのは、下記のサイトのAutomatic ColorizationでHypercolumnが使われていたからでした。
http://tinyclouds.org/colorize/
下記からYoutubeのColorization結果の動画が見られます。

このサイトのAutomatic Colorizationは白黒の映像を手がかりを全く使わないで(Non Reference)でColor化するというものです。
Colorization自体は以前からあって、この手法のようにNon Referenceでやる方法とマニュアルで何箇所か色を指定してもらって、あとは自然になるように全体の色をつけるというものがあります。
このサイトの著者が最初にやりたかったことは、
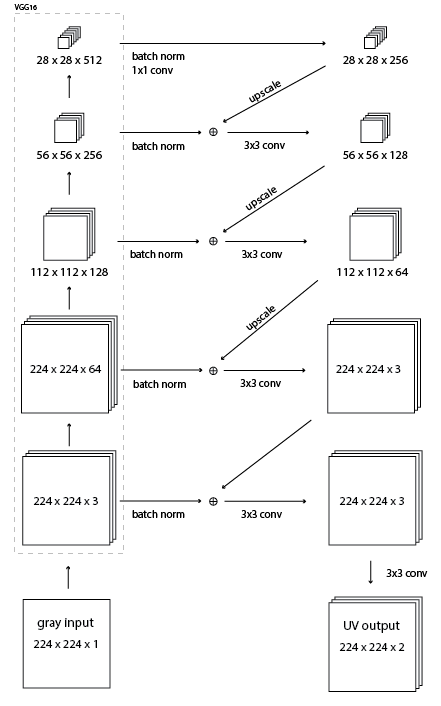
まず下記のような感じでHypercolumnを作成します。このときのネットワークはVGG-16です。
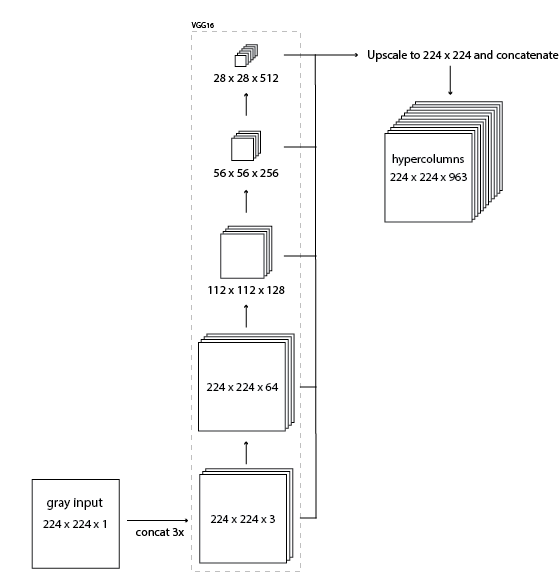
出来上がったHypercolumnをoperation?でUV Channelにして、入力のYと結合してColor画像を作ります。

Operation?は、963次元が2次元になるようなWeightとBiasで出てきた結果をSigmoidを通してユークリッド距離が小さくなるように学習します。
その他にこの著者は、 "residual encoder" も試したようです。これはHypercolumnではなくてMicrosoftがILSVRC 2015で1位になった時の手法Deep Residual Learning for Image Recognitionからヒントを得たと書いてあります。
Microsoftのresidual connectionは、入力からの差分を学習するようにしたものです。
このColorizationの場合は、入力というのがVGG-16のFeatureの出力で、差分というのがColor情報に対応しているという感じでしょうか?
ネットワークは以下のとおりです。
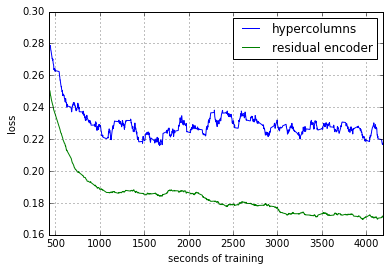
HypercolumnとResidual encoderの比較は下記の通りです。
Residual encoderの方が良さそうです。
結果はこんなかんじです。
右から白黒画像、auto colorization、manual colorization from Redditです。




