Learning to Segment Object Candidates
この論文の目的は、Objectを検出することです。
最近まで、物体に認識などのタスクでは、あらゆる位置、あらゆるサイズのWindowで、Classificationを行っていました。
それでは計算コストがかかるので、最近ではObjectの候補を検出して、その候補に対してClassificationを行うということがされています。
Object Proposal Algorithmにとって重要なことは、
1. High Recall(その画面にあるすべてのObject候補を検出すること。検出漏れがあると次の処理が行われない可能性があるから)
2. High Recallでかつ検出領域数は最小(無駄にたくさん検出しない)
3. 検出領域とObjectが可能な限り一致していること(はみ出したり、かけたりしていないこと)
この論文では、Convolutional Neural Networkに基づくObject Proposal Algorithmを提案しています。
この論文の共同著者のPiotr Dollarさんは、「Structured Forests for Fast Edge Detection」の著者です。
OpenCVにもアルゴリズムが入っています。
従来使われているEdge,Superpixel,Low Level Featureに頼らず、Raw image Dataから直接Segmentation領域を推定したところが新しいところです。ConvNetを使った関連研究としてはMultiBox、DeepBoxなどがありますが、Bounding Box候補を推定するものであり、本論文のようにSegmentation Maskとして推定しているものは初めてということです。
Algorithm
DeepMask
Object候補の推定は下記のように行います。

Training Data Set
1. RGB Input Patch $x_k$
2. $(i,j)$ が物体だったら$+1$,物体でなかったら$-1$をとるbinary Mask $m_k^{ij} \in {\pm 1}$
3. PatchにObjectが含まれているかを示したLabel $y_k \in {\pm 1}$
Label $y_k$に関しては、下記を満たすときに+1とする。
(i) Patchがの中心付近にObjectがいる
(ii) ObjectがPatchの中に完全に含まれている

緑枠が$y_k=+1$で赤枠が$y_k=-1$
Network Architecture
Networkの特徴
・Objectの位置を推定するSegmentation Network
・Patch内にObjectが含まれているかを推定するScoring Network
・Scoring Networkではimage patchが(i),(ii)の条件を満たしているか推定する
・Scoreの値は、image patchの中心にObjectが存在するかを示している
・物体認識用にTuningされたVGGを最終Layerだけ、Object Proposal用に特化させた
・2つのTaskを同時にTraining
ネットワーク構造
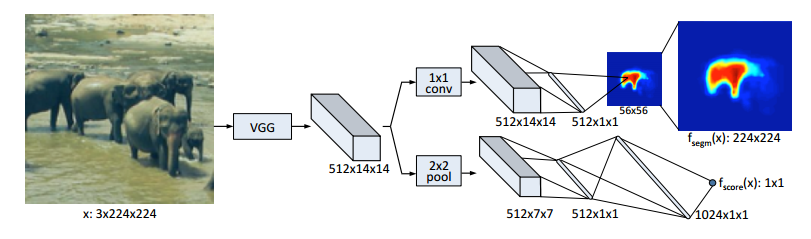
ネットワーク構造は下記の通り
・VGGを使用
・VGGの最後にあるFully Connected Layerを全部除去
・VGGの最後のmax pooling layerも除去
・残っている2x2のMax pooingが4つあるので、VGGの出力は1/16になっているから、入力が$3 \times h \times w$とすると出力のFeature Mapは $512 \times \frac{h}{16} \times \frac{w}{16}$になる
・VGGの入力は、$3\times224\times224$
Segmentation: 上の図の二股にわかれた上段
・1x1、Uint数512のConvolution layer
・512のFully Connected Layer(次が56x56なので直前で512次元のLow Rankに落としている)
・$56\times56$のあとは、bilinearで$224\times224$にUpsampling
Scoring: 上の図の二股にわかれた下段
・$512\times14\times14$のあと2x2 Max pooling。これでサイズが半分になる。
・512, 1024のFully Connected Layerを通って最後1個の値を出す
Joint Learning
Pixel-wiseなSegmentation maskとglobalなobject scoreを同時に推定するためのloss functionは下記の通り。
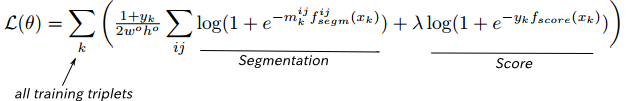
・binary logistic regressionの積算の形になっている
・左側がSegmentation、右側がScoreになっている。
・もし$y_k=-1$の時は0になる。これはRecallの値を高くするため。
Full Scene inference
・Full image の推定には、multiple locationとmultiple scaleでdenselyにmodelを適応する
・この手法は、PatchにObjectが含まれている必要があるので、multiple locationとscaleが必要になる
・下の結果は、Single Scaleでdenselyにmodelを適応した時のSegmentationの出力
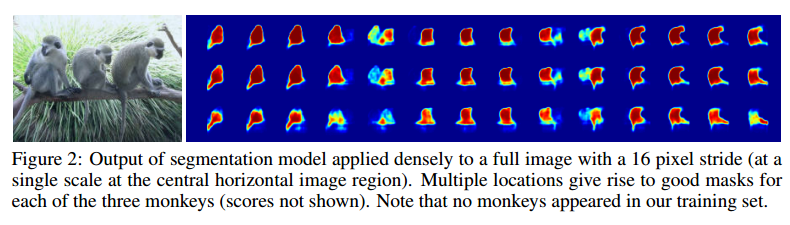
※結局最終的にどのように実装したのかわからない・・・
(we use exactly the implementation described in [26]).
Data augmentation
・水平垂直Shift(Translation shift) $\pm 16$ pixels
・拡大、縮小 $\times2^{\pm 1/4}$
・horizontal flip
・Negative Sampleは、標準的なPositive Sampleを$\pm 32$ pixelsまたは$\times 2^{\pm 1}$
学習パラメータ
・batch size 32
・learning rate 0.001
・Momentum 0.9
・weight decay 0.00005
Experiments
・評価はPASCAL VOC 2007とMS COCO 2014を使用
・精度は、IoU(Intersection over Union)で測定
推定領域とGround TruthのIntersectionを面積(画素数)で割ったもの
・性能は、IoUが0.5から1.0の間の再現率の平均、いわゆるaverage recall(AR)で評価
・比較対象は、EdgeBoxes, SelectiveSearch, Geodesic, Rigor, MCG
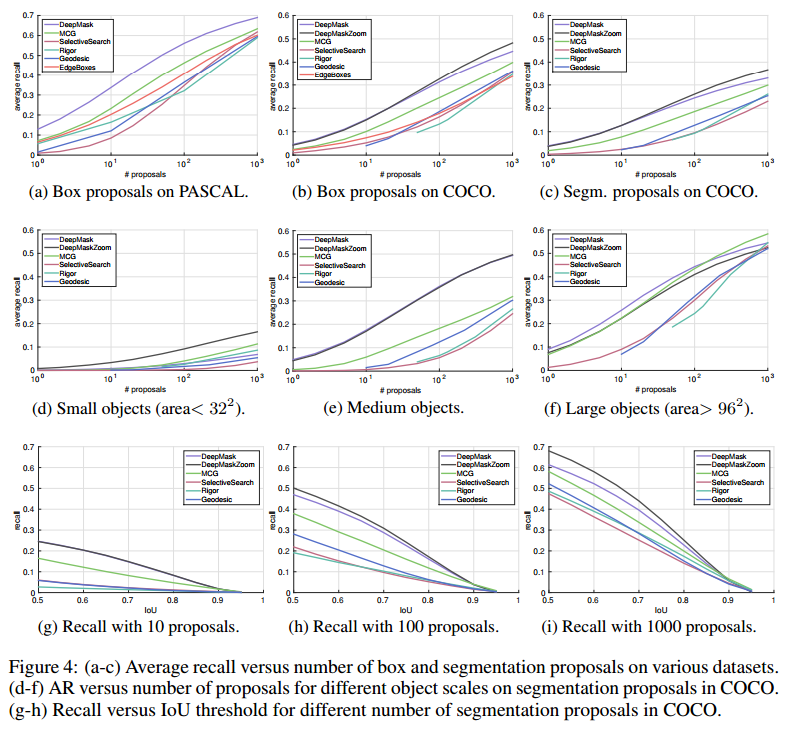
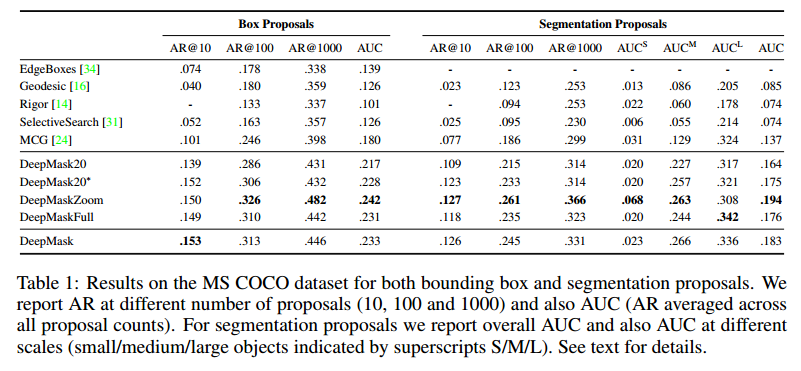
上段:
性能評価結果(横軸:Object数、縦軸:Average Recall)
左・・・Dataset PASCAL、Bounding Boxで評価
中央・・・Dataset COCO、Bounding Boxで評価
右・・・Dataset COCO、Segmentationで評価
・すべての領域でDeepMaskの性能が一番いい
・表は、MS COCOの結果(図の中央と右)
・AUCはすべてのObject数の平均
中段:
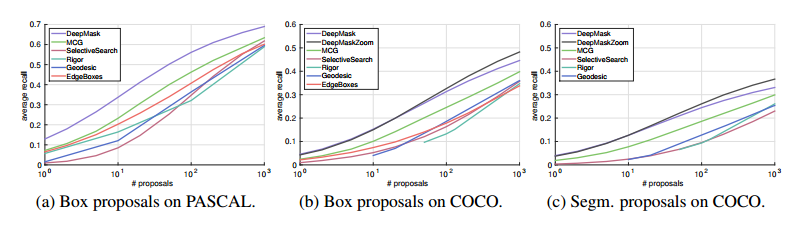
Objectの大きさ毎の比較結果(横軸:Object数、縦軸:Average Recall)
左 ・・・Dataset COCO、Segmentation、Small Object
中央・・・Dataset COCO、Segmentation、Medium Object
右 ・・・Dataset COCO、Segmentation、Large Object
・Small,Medium,Largeの基準はObjectのPixel数で下記の通り
Small ($a < 32^2$)
Medium ($32^2 \le a \le 96^2$)
Large ($a > 96^2$)
・Small Objectはみんな性能が良くない
下段:
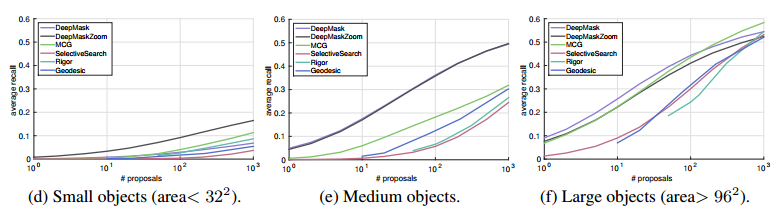
位置精度を評価した結果:(横軸:IoU、縦軸:Recall)
左 ・・・Dataset COCO、Segmentation、Object数が10
中央・・・Dataset COCO、Segmentation、Object数が100
右 ・・・Dataset COCO、Segmentation、Object数が1000
・論文中ではDeepMaskの性能が良くない。理由としてDownsamplingしているので位置精度が良くないと言っている。
※ただし、グラフの横軸が精度で、縦軸が性能なので、いまいち何がしたいのかよくわからない。
Generalization(汎化性能)
・学習のDatasetを小さく(カテゴリーを少なく)して学習させた時の性能を比較
・DatasetはPASCALの20Categoriesの中の一つだけを使用
・少ないDatasetで学習したModelは、DeepMask20,DeepMask20*
・DeepMask20*は、Scoring Networkだけを使用(Scoring Networkの貢献度合いを見る)
・DeepMaskと比べると、DeepMask20は性能が下がっている。
・DeepMask20*は、DeepMaskと同じぐらいなので、Scoring Networkは効いている
・Segmentation Networkの汎化性能は高い

DeepMaskFull
・Segmentation Networkは、$512\times 14\times 14$が一旦'low-rank'の512のFully Connected Layerに接続されてから最終的な$56\times 56$のOutputに結合されている
・low-rankをやめて$512\times 14\times 14$から直接$56\times 56$のOutputに結合させたものをDeepMaskFullとした
・結果は良くなかった
Detection
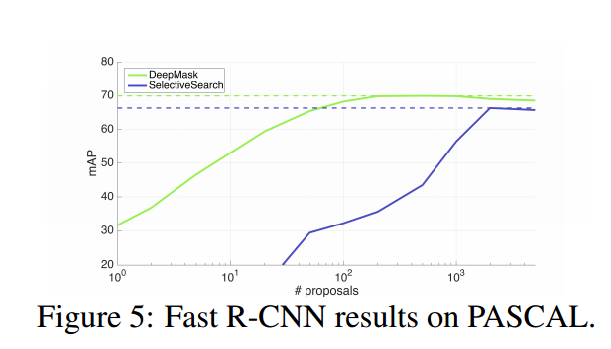
・Object Detestionの最新研究であるFast R-CNNにDeepMaskとSelectiveSearchを使った結果を比較した
・評価はmean average precision(mAP)で行いました
・すべてのObject数DeepMaskの性能が上回っている。object数が100でmAP 68.2%、object数が500でmAP 69.9%
処理速度
・COCO Datasetで1.6s/image
・PASCAL Datasetで1.2s/image
・一番速かったGeodesicがPASCAL Datasetで1s/image。これとそこそこいい勝負
最後に
Bounding BoxじゃなくSegmentationでObject候補を検出するというのはなかなかおもしろいです。
GlobalとLocalを一緒に学習するというアプローチはいいなと思いました。
その時に、全然違う問題だと一緒に学習する意味も無いし、かと言って同じような問題を同時に学習してもしょうがなそうだし、
似てるけど、ちょっと違うぐらいの問題を同時に学習するというのがいいのかなという気がします。
あと、CNNは特にObject Detectionなどの認識で成果が出ているようだし、構造がLayerを積み上げていく形になっているので、局所的な精度を出すのが得意ではなさそう。そのへんが位置精度で、他の手法が良かったという結果に出ているのかなという気がします。