解決したいこと
機械学習の初学者です。Keras上でCNNを用いた6クラスの分類に取り組んでいます。
CNNのクラス分類として他で見たことのない問題に直面しており、調べ方も分からないので質問させていただきます。
次の2点についてご意見をお聞きしたいです。よろしくお願いします。
- 以下のような問題は起こりうるのか(見たこと、聞いたことがあるか)
- 問題の原因の特定、解消
発生している問題
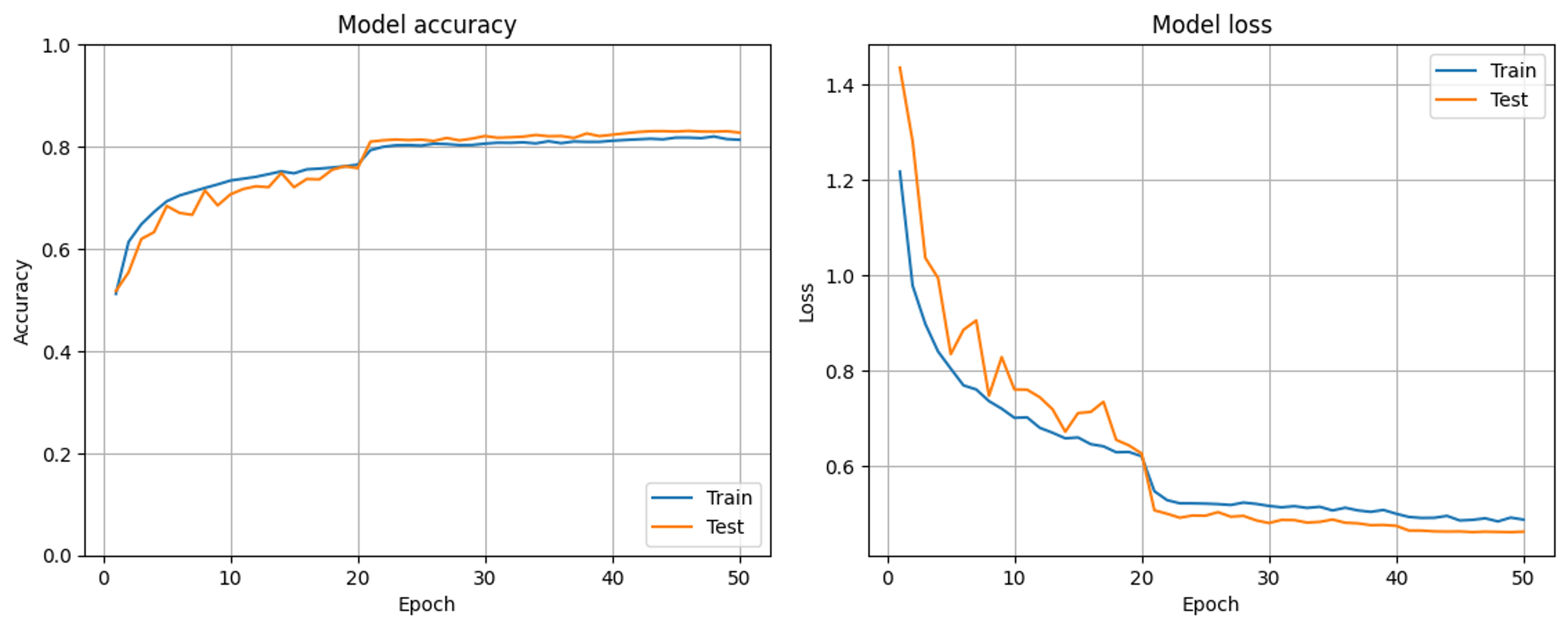
学習曲線においてtrainの正解率がvalidの正解率を下回ります(train:valid:test=6:1:3の割合でデータを分割しています)。
画像ではグラフの凡例がtestとなっていますが、これはvalidのことだと思ってください。testは学習に使用していません。
このようなことは起きても問題ないのでしょうか。それともやはり何か様子がおかしいでしょうか。
該当するソースコード
Kerasで記述しているCNNモデルの実装部分について載せさせていただきます。
BATCH_SIZE = 128
image_size_x = 25 #画像サイズ
image_size_y = 15
epochnumber = 50
L2weight = 0.001
#CNNアーキテクチャの設計
model = Sequential()
model.add(BatchNormalization(input_shape=(image_size_x, image_size_y, color_setting)))
model.add(Activation('relu'))
model.add(Conv2D(16, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(GlobalAveragePooling2D())
model.add(Dense(class_number, activation='softmax', kernel_regularizer=regularizers.l2(L2weight)))
model.summary()
#学習率減衰の設定
def step_decay(epoch):
x = 0.01
if epoch >= 20: x = 0.001
if epoch >= 40: x = 0.0001
return x
lr_decay = LearningRateScheduler(step_decay)
model.compile(loss='categorical_crossentropy', #損失関数の設定
optimizer=Adam(learning_rate=0.01), #最適化アルゴリズムの設定
metrics=['accuracy'] #評価関数の設定
)
start_time = time.time()
#可視化
# ここを変更。必要に応じて「batch_size=」「epochs=」の数字を変更してみてください。
history = model.fit(x_train,y_train,
batch_size=BATCH_SIZE,
epochs=epochnumber, verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[lr_decay] #学習率減衰の設定
)
自分で試したこと
まず、データセットに問題がないかは確認しました。ソフトを使ってデータセットに重複等の不備がないかを確認しました。
その結果、おそらくデータセットは問題なく用意できていそうだと結論づけています。
次に、上のグラフから20epochの学習率減衰の際に挙動が大きく変わっているように感じたので、学習率減衰の部分をコメントアウトして学習させてみました(上で示したCNNの実装コードでは20epochと40epochの段階で学習率減衰を導入しています)。
その結果が以下のグラフです。
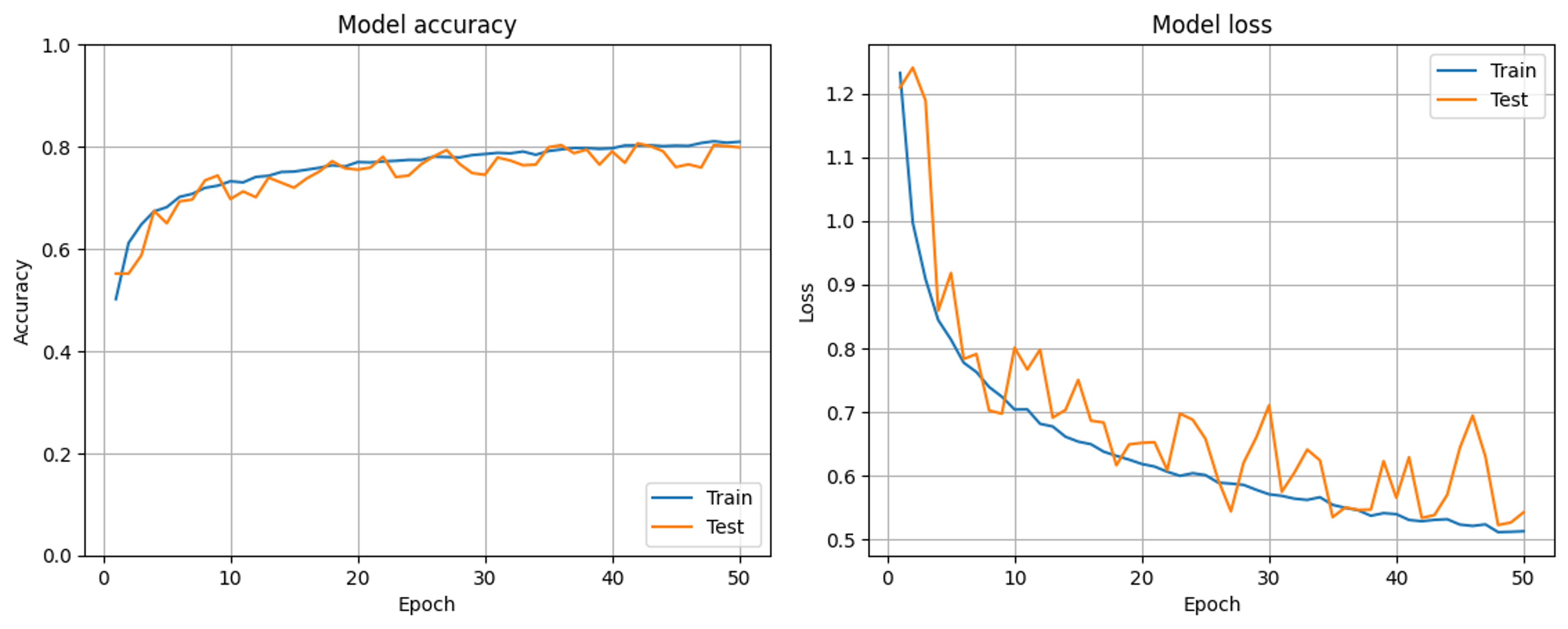
結果としては、最初に示したような露骨な結果にはなりませんでした。しかし、trainがvalidの正解率を下回るepochも多少みられることから問題の解消には至っていないんじゃないかと思っています。
また、ここでは原因究明のためにコメントアウトしたデータを用意しましたが、学習率減衰は最終的には実装したいと考えています。
余談
昨日もQiitaで別の質問をさせていただき色々とご回答いただいたのですが、Qiitaに不慣れなために質問を誤って削除してしまいました。昨日ご助言くださった方々が見ているはずもありませんが、ここで謝罪させていただきます(その後問題は解決しました)。
追記(12月13日)
cross validationしたらどうかというご助言をいただいたので、train:test=7:3で分割した後trainデータを7等分してcross validationしました。7回分の学習結果を平均した学習曲線を載せさせていただきます。
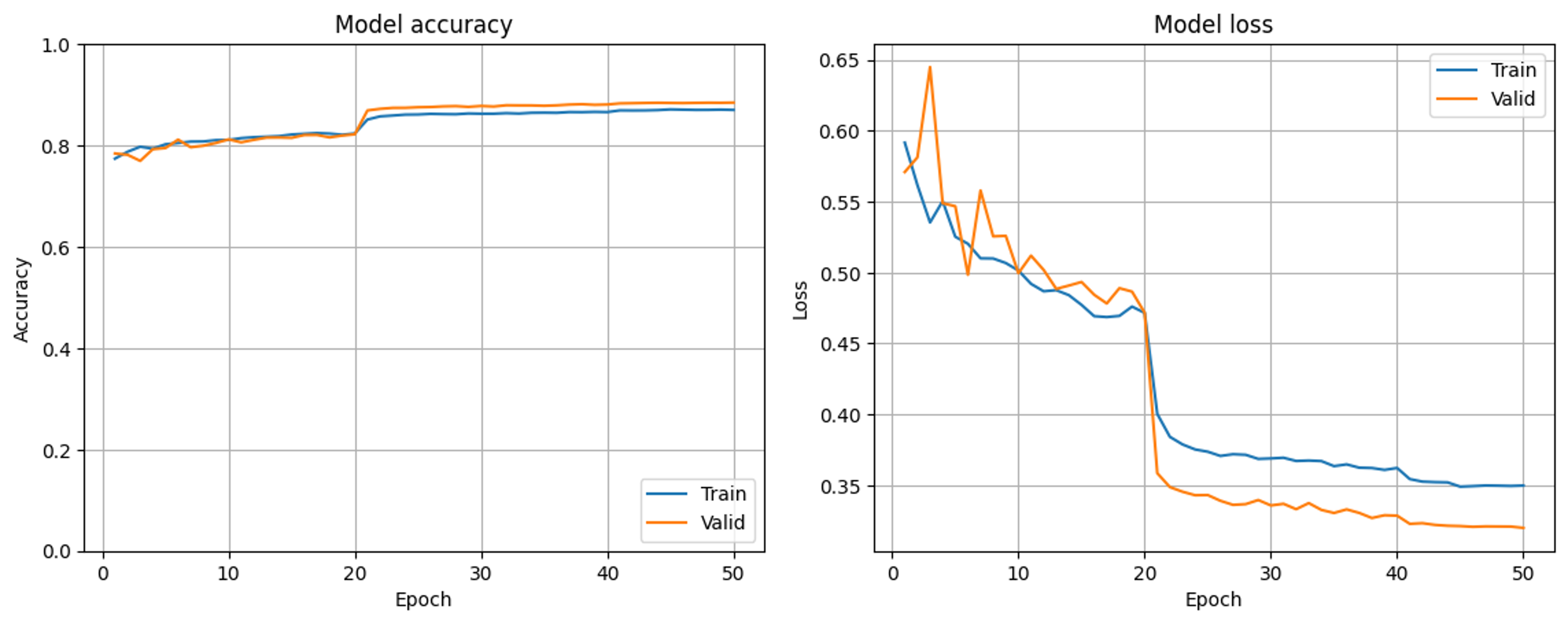
結果としてはやはり平均してvalidデータのほうが正解率が高くなりました(問題は解決しませんでした)。
追記(12月17日)
BNや入力データの正規化に関するご助言をもとに、2つの実験を行いました。
まず、入力直後のBN層を省いてご助言の通りに最初の2層を
model.add(Input(shape = (image_size_x, image_size_y, color_setting)))
に書き換えてみた結果が以下の通りです。
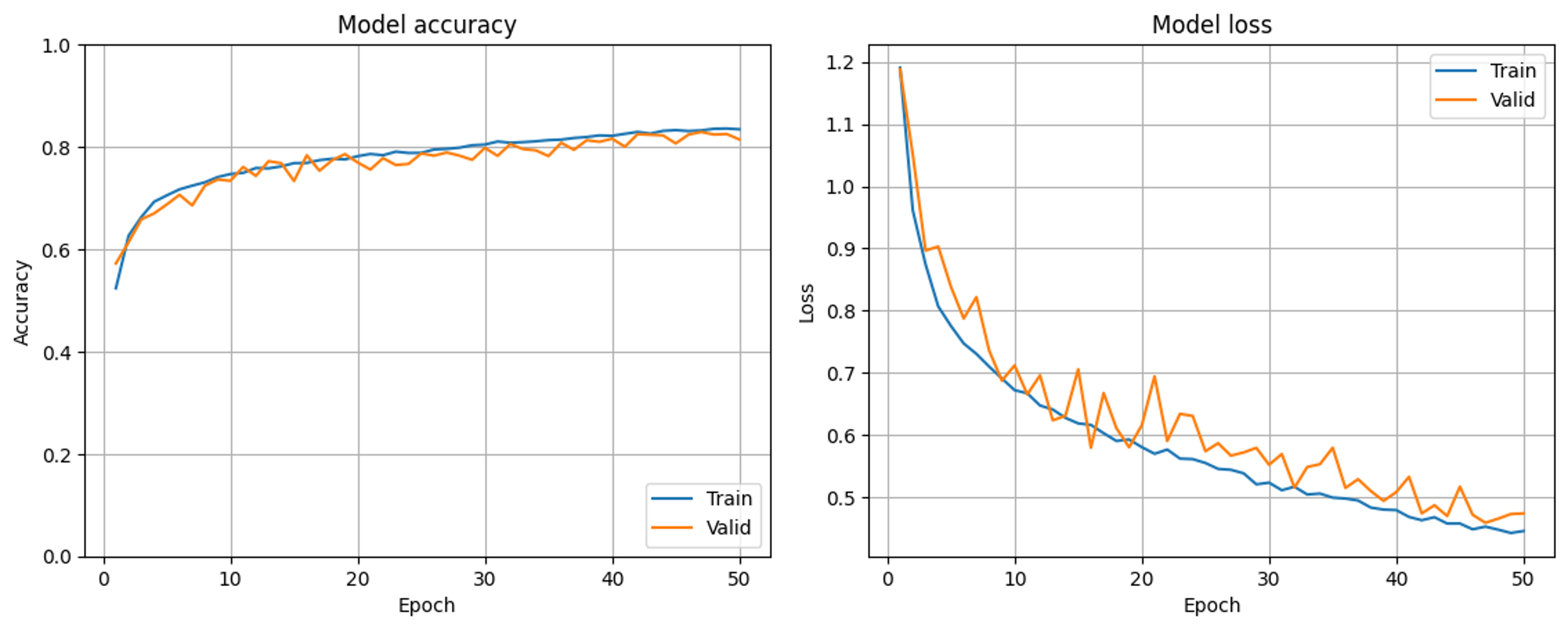
10~20epochではvalidの正解率が上回っているものの、問題の解消に大きくつながる結果となりました。
次に、そもそも私がデータの準備の段階で正規化を怠っていたことに気づいたため、入力データを0~1の範囲になるよう正規化してみることにしました(追記分と比較しやすいように-1~1で正規化した結果のグラフと差し替えました。差し替える前と結果はほとんど変わりありません)。
こちらの実験ではBN層はいじらずに上に示しているコードで学習しています。
元々の想定に最も近い結果が得られました。BN層についてのご助言も大変納得いくものでしたが、入力データの正規化が直面している問題の解決には最も重要だったと感じています。
結論としてはかなり初歩的なミスでしたが、ご助言いただかないと解決できなかったと思います。皆さんありがとうございました。
追記(12月18日)
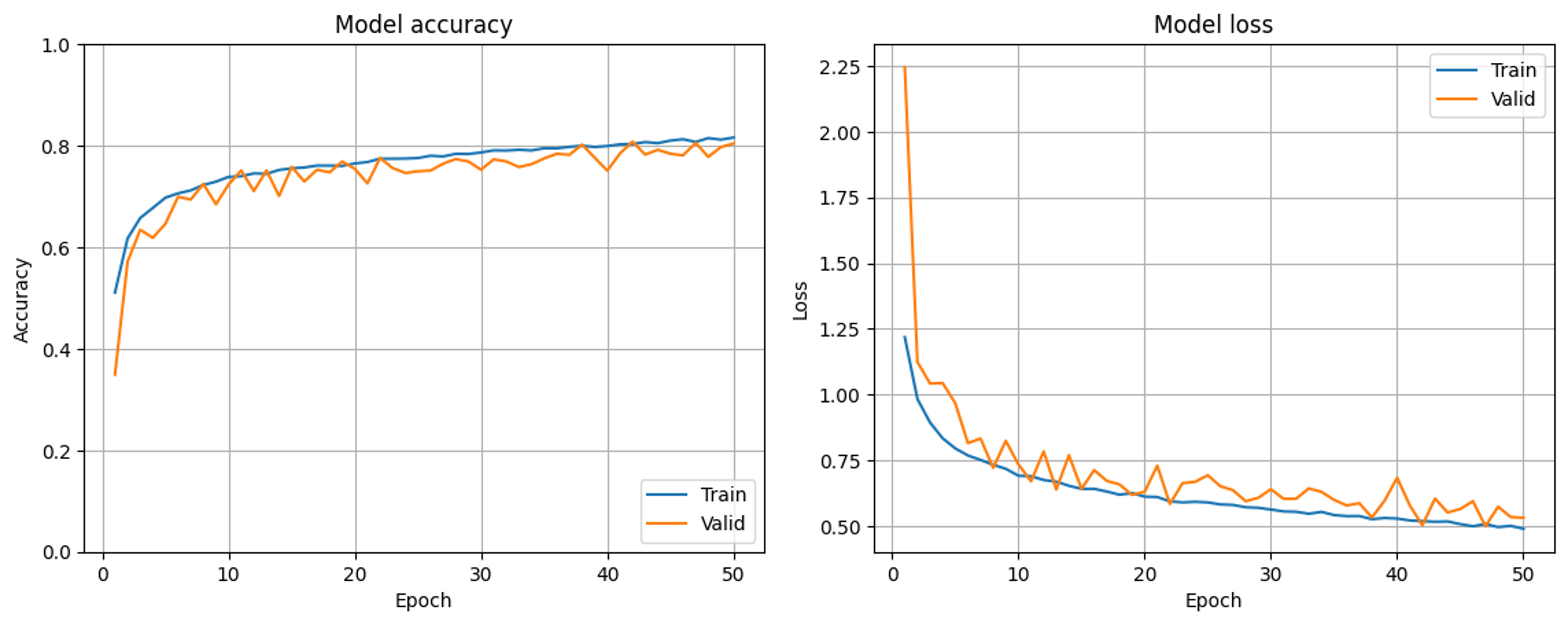
またもや初歩的なミスでお恥ずかしいですが、学習率減衰を除いていたことをすっかり忘れていたため学習率減衰を改めて加えたうえで学習したところ、20epochの学習率減衰後では元々の問題が表れる結果となりました。そのため、一度は解決したと早とちりしましたが追記で質問させてください。なお、入力データの正規化についてもご助言の通り-1~1でやり直してみました。
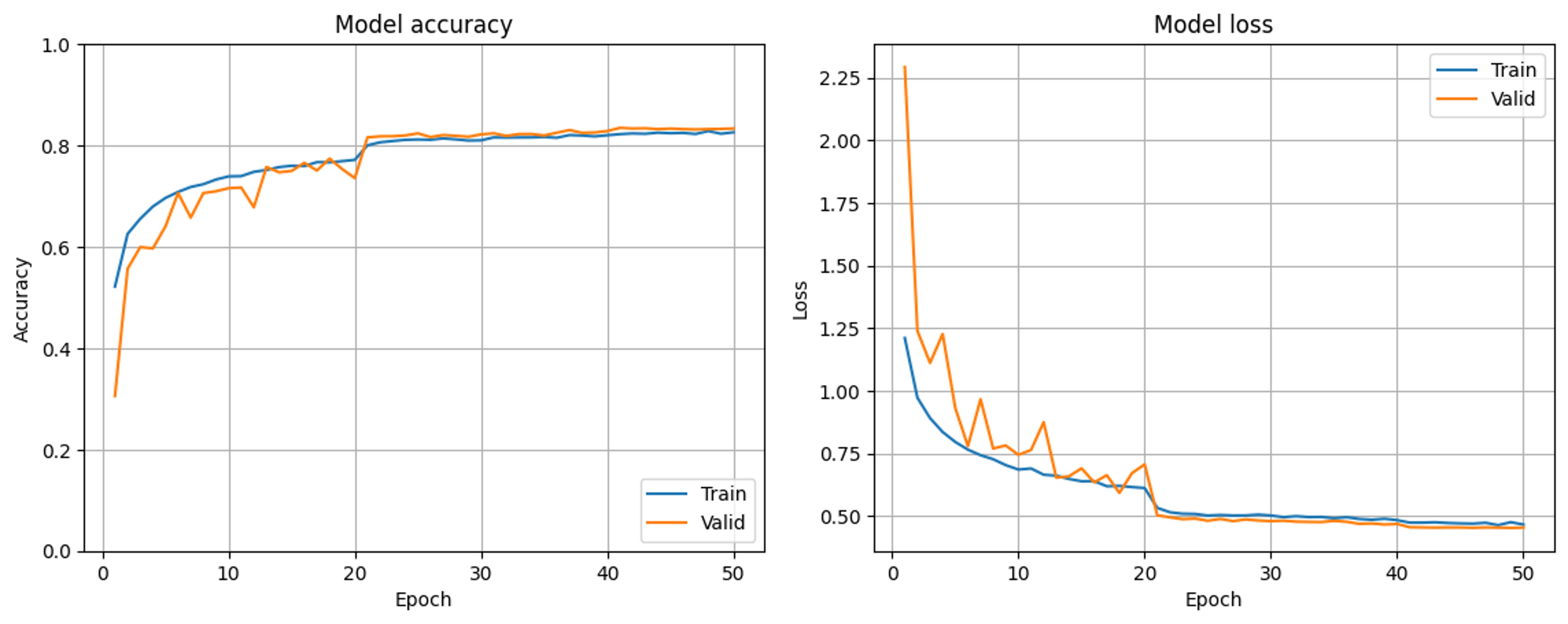
また、ご助言いただいた通り最初のBN層を除いた場合の学習曲線が以下の通りです。こちらは以前も確認した通り問題の解消に向かっているように思います。
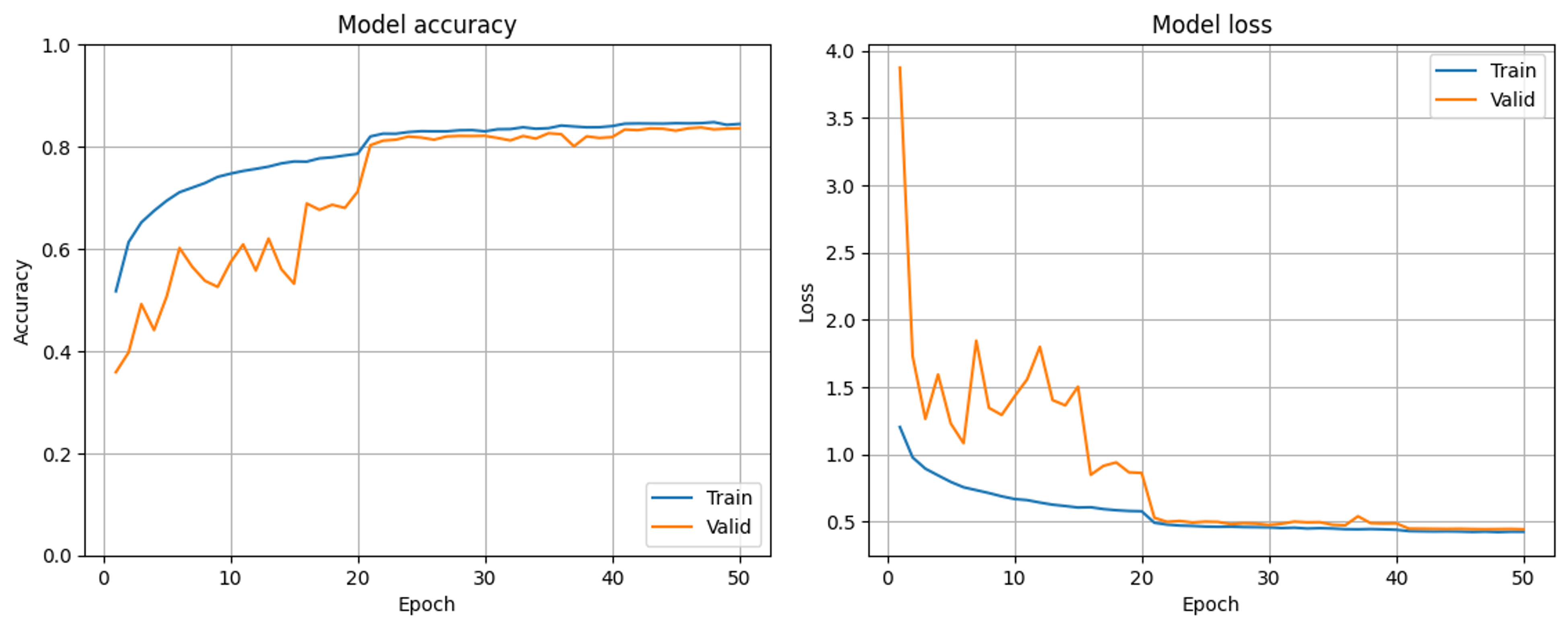
実は現在取り組んでいる学習はある先行研究の追実験なので、できるだけCNNモデルをいじりたくないという事情があります。しかしご指摘いただいている通りBN層が入力の直後に来るのは不自然な気がしてきたので、他に問題の原因が見つからなければ最初のBN層は除こうと考えています。
今回の追記分で特にお伺いしたい点は、学習率減衰が質問させていただいている問題の原因になっていないかという点です。何かご存じの方がいらっしゃればぜひご助言いただきたいです。






