データベースのサブテーブルや分散キャッシュを実行するときには、必然的に問題が発生します。
ノード間でデータを均等に分散させ、できるだけノードを追加または削除するときに、影響を受けるデータを最小限に抑える方法。
ハッシュモジュロ
ランダムに配置されていないと言う、多くの問題をもたらすでしょう。考えられる最も簡単な方法は、ハッシュモデリングです。
入ってくるKeyは、index = hash(key)%Nとして計算できます。ハッシュ関数は、文字列を正の整数に変換するハッシュマッピング法です.Nはノードの数です。
これはデータの一様な分布を満たすことができますが、アルゴリズムはフォールトトレランスとスケーラビリティが劣ります。
例えば、ノードの追加や削除の際には、すべての鍵を再計算する必要があり、明らかにそのようなコストが高いため、一様な分布と耐障害性と拡張性を満たすアルゴリズムが求められる。
一貫したハッシュアルゴリズム
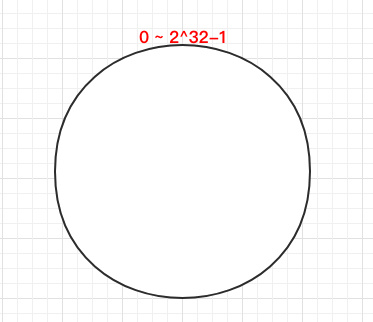
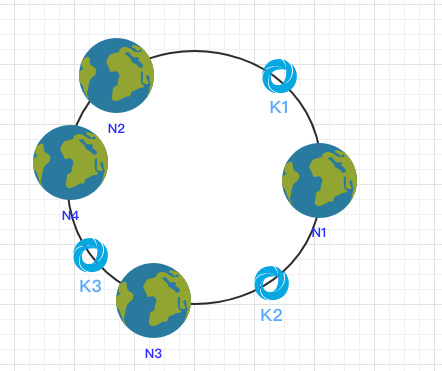
ハッシュアルゴリズムは、リングによって形成されるすべてのハッシュ値と一致し、その範囲は0〜2 ^ 32-1です。以下に示すように
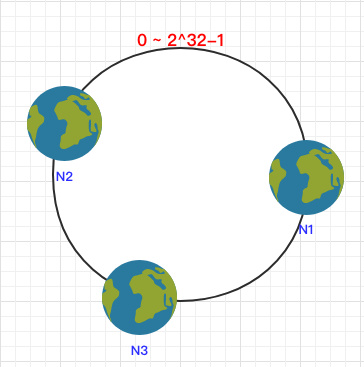
各ノードがこのリングにハッシュされた後、次のようにハッシュの後に、ノードのIPホスト名フィールドをキーハッシュ(キー)として使用できます。
同じハッシュ関数キーを使用して、対応するノードにデータを配置する必要がある場合、このリングにもマップされます。
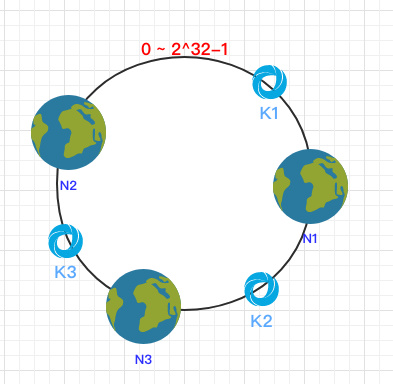
このようにして、k1をノードN1に、ノードk2をノードN3に、ノードk3をノードN2に時計回りに配置できます。
フォールトトレランス
N1のダウンタイムを想定しているこの時点で:
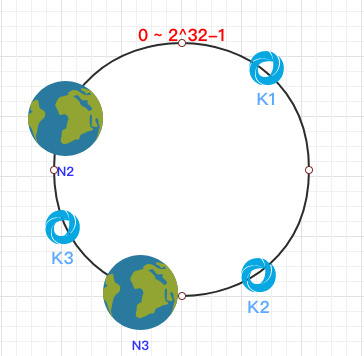
それでも時計回りの方向によれば、k2とk3は変わらず、k1だけがN3に再マッピングされる。これはフォールトトレランスの非常に良い保証です。ノードが停止している場合は、データの小さな部分にしか影響しません。
拡張可能
新しいノードを追加する場合:
N2とN3にノードN4が追加された場合、データの印象はk3になります。データの残りの部分も変更されていないため、スケーラビリティを確保するのにも非常に適しています。
仮想ノード
これまでのところ、アルゴリズムはまだまだ問題になります。
ノードが小さい場合、データの分布が不均一になります。
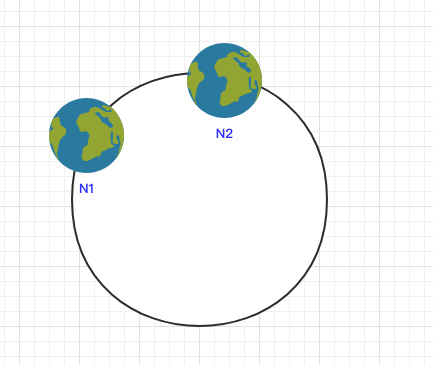
これにより、N1ノードのデータの大半がN2ノードの少量のデータになります。
この問題を解決するために、均一なハッシュアルゴリズムが仮想ノードに導入される。仮想ノードと呼ばれるリング上に配置された複数のノードを生成するために、各ノードを複数回ハッシュする:
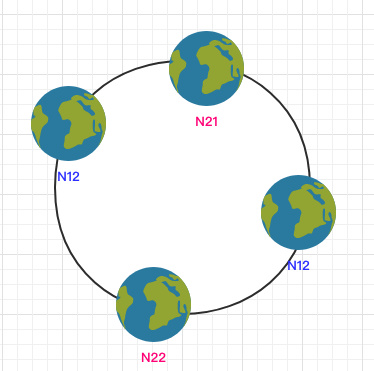
計算は、IP番号の後に追加して、ハッシュ値を生成することができます。
このようにして、仮想ノードを実際のノードにさらに元の基準でさらにマッピングするステップだけで、少数のノードが均一性を満たすことが可能になる